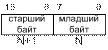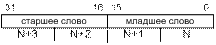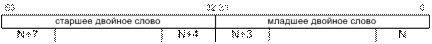Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Типы и форматы данных в ассемблере
Данные – числа и закодированные символы, используемые в качестве операндов команд. Основными типами данных процессора с архитектурой IA-32 являются байт, слово, двойное слово, четырехбайтное слово и восьмибайтное слово.
Данные, обрабатываемые вычислительной машиной, можно разделить на 4 группы: · целочисленные; · вещественные. · символьные; · логические; Целочисленные данные могут представляться в знаковой и беззнаковой форме. Беззнаковые целые числа представляются в виде последовательности битов в диапазоне от 0 до 2n, где n-количество занимаемых битов. Знаковые целые числа представляются в диапазоне -2n-1 … +2n-1. При этом старший бит данного отводится под знак числа (0 соответствует положительному числу, 1 – отрицательному).
Тип DT может быть только вещественным. Вещественные данные обрабатываются сопроцессором и будут рассмотрены ниже. Логические данные представляют собой бит информации и могут записываться в виде последовательности битов. Каждый бит может принимать значение 0 или 1 (ЛОЖЬ или ИСТИНА). Логические данные могут начинаться с любой позиции в байте. Символьные данные задаются в кодах. Кодировка символов (часто называемая также кодовой страницей) – это набор числовых значений, которые ставятся в соответствие группе алфавитно-цифровых символов, знаков пунктуации и специальных символов. В Windows первые 128 символов всех кодовых страниц состоят из базовой таблицы символов ASCII (American Standard Code for Interchange of Information). Первые 32 кода базовой таблицы, начиная с нулевого, размещают управляющие коды. Символы с номерами от 128 до 255 представляют дополнительные символы и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Основные таблицы кодировки представлены в приложении 1.
Для того чтобы полноценно поддерживать помимо английского и другие языки, фирма IBM ввела в употребление несколько кодовых таблиц, ориентированных на конкретные страны. Так для скандинавских стран была предложена таблица 865 (Nordic), для арабских стран - таблица 864 (Arabic), для Израиля - таблица 862 (Israel) и так далее. В этих таблицах часть кодов из второй половины кодовой таблицы использовалась для представления символов национальных а лфавитов (за счет исключения некоторых символов псевдографики). С русским языком ситуация развивалась особым образом. Очевидно, что замену символов во второй половине кодовой таблицы можно произвести разными способами. Вот и появились для русского языка несколько разных таблиц кодировки символов кириллицы: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Все они одинаково изображают символы первой половины таблицы (от 0 до 127) и различаются представлением символов русского алфавита и псевдографики. Для таких же языков, как китайский или японский, вообще 256 символов недостаточно. Кроме того, всегда существует проблема вывода или сохранения в одном файле одновременно текстов на разных языках (например, при цитировании). Поэтому была разработана универсальная кодовая таблица UNICODE, содержащая символы, применяемые в языках всех народов мира, а также различные служебные и вспомогательные символы (знаки препинания, математические и технические символы, стрелки, диакритические знаки и т.д.). Очевидно, что одного байта недостаточно для кодирования такого большого множества символов. Поэтому в UNICODE используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов. К настоящему времени задействовано около 49000 кодов (последнее значительное изменение - введение символа валюты EURO в сентябре 1998 г.). Для совместимости с предыдущими кодировками первые 256 кодов совпадают со стандартом ASCII. Для перекодировки символов и русскоязычного вывода в окно консоли можно использовать функцию Windows API BOOL CharToOem(LPCTSTR lpszSrc, LPSTR lpszDst); lpszSrc – указатель на строку-источник
lpszDst – указатель на строку-приемник.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-12-09; просмотров: 208; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.212.199 (0.007 с.) |