
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Двоичная, восьмеричная и шестнадцатеричная системы счисленияСодержание книги
Поиск на нашем сайте
Введение Основные определения Программирование — процесс создания компьютерных программ с помощью языков программирования. В узком смысле слова, программирование рассматривается как кодирование — реализация одного или нескольких взаимосвязанных алгоритмов на некотором языке программирования. Под программированием также может пониматься разработка логической схемы для ПЛИС, а также процесс записи информации в ПЗУ. В более широком смысле программирование — процесс создания программ, то есть разработка программного обеспечения. Процессор (центральное процессорное устройство, ЦПУ) – устройство, непосредственно предназначенное для выполнения вычислительных операций. Процессор работает под управлением программы, выполняя вычисления или принимая логические решения, необходимые для обработки информации. Он имеет сложную внутреннюю структуру, состоящую из арифметических устройств, схем управления, регулирующих выполнение различных операций, а также регистров, предназначенных для временного хранения данных. Язык программирования — формальная знаковая система, предназначенная для описания алгоритмов в форме программы, которая удобна для исполнителя (например, компьютера). Компьютерные программы применяются для передачи компьютеру инструкций по выполнению того или иного вычислительного процесса и организации управления отдельными устройствами. Язык программирования определяет набор лексических, синтаксических и семантических правил, используемых при составлении компьютерной программы. Он позволяет программисту точно определить то, на какие события будет реагировать компьютер, как будут храниться и передаваться данные, а также какие именно действия следует выполнять над этими данными при различных обстоятельствах. Со времени создания первых программируемых машин человечество придумало уже более двух с половиной тысяч языков программирования. Некоторыми языками умеет пользоваться только небольшое число их собственных разработчиков, другие становятся известны миллионам людей. Профессиональные программисты иногда применяют в своей работе более десятка разнообразных языков программирования. Языки программирования обычно делятся на машинно-независимые и машинно-ориентированные. К машинно-независимым относятся Си, Си++, Паскаль и др. Они позволяют быстро писать довольно сложные программы. В тех случаях, когда необходимо построить наиболее компактный машинный код и создать самые быстродействующие программы, используют машинно-ориентированные языки. Они оперируют непосредственно ячейками памяти и программно-доступными элементами микропроцессора.
Различные языки программирования поддерживают различные стили программирования. Отчасти искусство программирования состоит в том, чтобы выбрать один из языков, наиболее полно подходящий для решения имеющейся задачи. Разные языки требуют от программиста различного уровня внимания к деталям при реализации алгоритма, результатом чего часто бывает компромисс между простотой и производительностью (или между временем программиста и временем пользователя). Единственный язык, напрямую выполняемый процессором — это машинный язык (также называемый машинным кодом). Изначально все программисты прорабатывали каждую мелочь в машинном коде, но сейчас эта трудная работа уже не делается. Вместо этого программисты пишут исходный код, и компьютер (используя компилятор, интерпретатор или ассемблер) транслирует его, в один или несколько этапов, уточняя все детали, в машинный код, готовый к исполнению на целевом процессоре. Даже если требуется полный низкоуровневый контроль над системой, программисты пишут на языке ассемблера, мнемонические инструкции которого преобразуются один к одному в соответствующие инструкции машинного языка целевого процессора. Язык ассемблера — тип языка программирования низкого уровня, представляющий собой формат записи машинных команд, удобный для восприятия человеком.
На языке ассемблера пишут: · программы, требующие максимальной скорости выполнения: основные компоненты компьютерных игр, ядра операционных систем реального времени и просто критичные по времени куски программ; · программы, взаимодействующие с внешними устройствами: драйверы, программы, работающие напрямую с портами, звуковыми и видеоплатами; · программы, использующие полностью возможности процессора: ядра многозадачных операционных систем, серверы;
· программы, полностью использующие возможности операционной системы: вирусы, антивирусы, защита от несанкционированного доступа, программы обхода защиты от несанкционированного доступа. Достоинства языка ассемблера · Максимальная оптимизация программ, как по скорости выполнения, так и по размеру · Максимальная адаптация под соответствующий процессор Недостатки · Трудоемкость написания программы больше, чем языке высокого уровня · Трудоемкость чтения · Непереносимость на другие платформы, кроме совместимых · Ассемблер малопригоден для совместных проектов Алгоритм — это точный набор инструкций, описывающих порядок действий некоторого исполнителя для достижения результата, решения некоторой задачи за конечное число шагов. Основные свойства алгоритмов следующие: 1. Понятность для исполнителя — исполнитель алгоритма должен понимать, как его выполнять. Иными словами, имея алгоритм и произвольный вариант исходных данных, исполнитель должен знать, как надо действовать для выполнения этого алгоритма. 2. Дискретность (прерывность, раздельность) — алгоритм должен представлять процесс решения задачи как последовательное выполнение простых (или ранее определенных) шагов (этапов). 3. Определенность — каждое правило алгоритма должно быть четким, однозначным и не оставлять места для произвола. Благодаря этому свойству выполнение алгоритма носит механический характер и не требует никаких дополнительных указаний или сведений о решаемой задаче. 4. Результативность (или конечность) состоит в том, что за конечное число шагов алгоритм либо должен приводить к решению задачи, либо после конечного числа шагов останавливаться из-за невозможности получить решение с выдачей соответствующего сообщения, либо неограниченно продолжаться в течение времени, отведенного для исполнения алгоритма, с выдачей промежуточных результатов. 5. Массовость означает, что алгоритм решения задачи разрабатывается в общем виде, т.е. он должен быть применим для некоторого класса задач, различающихся лишь исходными данными. При этом исходные данные могут выбираться из некоторой области, которая называется областью применимости алгоритма.
Системы счисления Основные определения Системой счисления называется совокупность приемов наименования и записи чисел. Каждое число изображается в виде последовательности цифр, а для изображения каждой цифры используется какой-либо физический элемент, который может находиться в одном из нескольких устойчивых состояний. Для проведения расчетов в повседневной жизни общепринятой является десятичная система счисления. В этой системе для записи любых чисел используются только десять различных знаков (цифр): 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Эти цифры введены для обозначения десяти последовательных целых чисел от 0 до 9. Обозначая число «ДЕСЯТЬ», мы используем уже имеющиеся цифры «10». При этом значение каждой из цифр поставлено в зависимость от того места (позиции), где она стоит в изображении числа. Такая система счисления называется позиционной. При этом десять единиц каждого разряда объединяются в одну единицу соседнего, более старшего разряда. Так, число 252,2 можно записать в виде выражения
Аналогично десятичная запись произвольного числа x в виде последовательности цифр
основана на представлении этого числа в виде полинома
где Число P единиц какого-либо разряда, объединяемых в единицу более старшего разряда, называется основанием системы счисления, а сама система счисления называется P -ичной. Так, в десятичной системе счисления основанием системы является число 10. Для записи произвольного числа в P -ичной системе счисления достаточно иметь P различных цифр. Цифры, служащие для обозначения чисел в заданной системе счисления называются базисными. Запись произвольного числа x в позиционной системе счисления с основанием P в виде полинома
Каждый коэффициент
В качестве базисных чисел обычно берутся числа от 0 до P -1 включительно. Для указания того, в какой системе счисления записано число, основание системы указывается в виде нижнего индекса в десятичной записи, например 12,438. Смешанные системы счисления Смешанной называется такая система счисления, в которой числа, заданные в некоторой системе счисления с основанием P изображаются с помощью цифр другой системы счисления с основанием Q, где Q < P. В такой системе P называется старшим основанием, Q — младшим основанием, а сама система счисления называется Q - P -ичной. Для того, чтобы запись числа в смешанной системе счисления была однозначной, для представления любой P -ичной цифры отводится одно и то же количество Q -ичных разрядов, достаточное для представления любого базисного числа P -ичной системы. Так, в двоично-десятичной системе для изображения каждой цифры отводится 4 двоичных разряда. Например, число 92510 запишется в двоично-десятичной системе как 1001 0010 0101. Здесь последовательные четверки (тетрады) двоичных разрядов изображают цифры 9, 2 и 5 десятичной записи соответственно. Следует отметить, что, хотя в двоично-десятичной записи используются только цифры «0» и «1», эта запись отличается от двоичного изображения данного числа. Например, двоичный код 1001 0010 0101 соответствует десятичному числу 2341, а не 925. Особого внимания заслуживает случай, когда P = Q l (l – целое положительное число). В этом случае запись какого-либо числа в смешанной системе счисления тождественно совпадает с изображением этого числа в системе счисления с основанием Q: A216 = 1010 00102.
Перевод чисел из одной системы счисления в другую Задача перевода заключается в следующем: Пусть известна запись числа x в системе счисления с каким-либо основанием P:
где pi – цифры P -ичной системы
где qi – искомые цифры Q -ичной системы Для перевода любого числа достаточно отдельно перевести его целую и дробную части. Перевод целых чисел. Представим число x в Q -ичной системе в виде полинома Для определения в поставленной задаче Таким образом, младший коэффициент а Этот процесс продолжается до тех пор, пока не получено xs +1 =0. Для записи числа x в Q -ичной системе счисления запишем каждый из полученных коэффициентов Пример 1: Перевести число 4710 в двоичную систему счисления (Q = 2).
Искомое число 4710 = 1011112. Пример 2: Перевести число 306010 в шестнадцатеричную систему счисления (Q = 16).
Таким образом, Перевод дробных чисел Пусть необходимо перевести в Q -ичную систему правильную дробь x (0< x <1), заданную в P -ичной системе счисления. Поскольку x <1, то в Q -ичной системе запись числа x будет иметь вид Умножив обе части выражения (4) на Q, получим
где
где [ ] – целая часть. Процесс продолжается до тех пор, пока не будет получено Пример 3: Перевести число 0,2510 в двоичную систему счисления
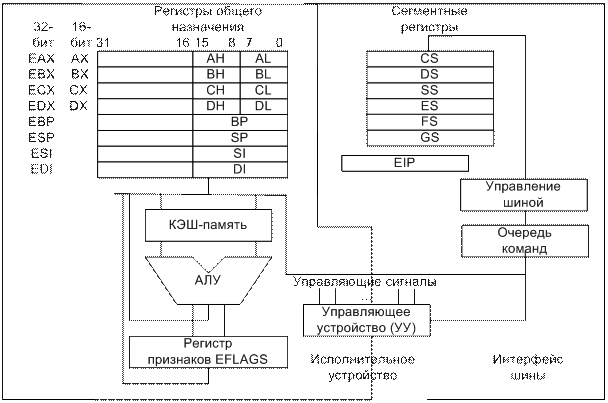
Искомое число x = 0,2510 = 0,012. Архитектура микропроцессора Все 32-разрядные процессоры Intel, начиная с i386, реализуются с использованием архитектуры IA-32 (Intel Architecture 32). Рисунок 2 Микропроцессор состоит из двух основных частей: операционного узла, выполняющего команды, и шинного интерфейса, который производит выборку команд, формирует очередь команд, производит считывание операндов и запись результата. Более полно структура микропроцессора показана на рис. 1.
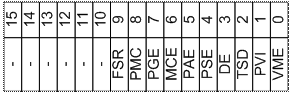
Управляющие регистры Регистр CR0.
Й бит, не используются. Й бит, не используется. Й бит, не используются. Й бит, запрет заполнения кэша (CD). Остальные биты. Й бит, запрет кэширование страницы (PCD). Регистр CR4
Й бит, превращение инструкции RDTSC в привилегированную (TSD). Системные адресные регистры Регистры отладки
DR0...DR3 - хранят 32-битные линейные адреса точек останова. Память компьютера Память – способность объекта обеспечивать хранение данных. Числовые и символьные операнды, равно как и команды, хранятся в памяти компьютера. Память состоит из ячеек, в каждой из которых содержится 1 бит информации, принимающий значения «0» или «1». Как правило, биты обрабатывают группами фиксированного размера. Для этого память организуется таким образом, что группы по n бит могут записываться и считываться за одну базовую операцию. Группа из n бит называется словом информации, а значение n – длиной слова. Слова последовательно располагаются в памяти компьютера. Длина слова современных компьютеров составляет 16‑64 бит. Восемь последовательных битов называются байтом. 1 килобайт (Кбайт) = 210 = 1 024 байт 1 мегабайт (Мбайт) = 210 Кбайт = 220 байт = 1 048 576 байт 1 гигабайт (Гбайт) = 210 Мбайт = 230 байт = 1 073 741 824 байт Для доступа к памяти с целью записи или чтения отдельных элементов информации, будь то слова или байты, необходимы имена, или адреса, определяющие их расположение в памяти. В качестве адресов используются числа из диапазона от 0 до Диапазон значений физических адресов зависит от разрядности шины адреса микропроцессора. Адресное пространство процессора i8086 составляет 1 Мбайт, для процессоров i486 и Pentium – 4 Гбайт (232 байт), для микропроцессоров семейства P6 (Pentium Pro/II/III) – 64 Гбайт (236). Чаще всего адреса назначаются байтам памяти. Память, в которой каждый байт имеет свой адрес, называется памятью с байтовой адресацией. При этом последовательные байты имеют адреса 0, 1, 2 и т. д. Существует прямой и обратный способы адресации байтов. При обратном способе адресации байты адресуются слева направо, так что самый старший (левый) байт слова имеет наименьший адрес. Прямым способом называется противоположная система адресации. Наряду с порядком следования байтов в слове необходимо определить порядок следования битов в байте. Типичный способ расположения битов в байте:
обратная адресация прямая адресация
Обычно число занимает целое слово. Поэтому для того, чтобы обратиться к нему в памяти, нужно указать адрес слова, по которому это число хранится. Компиляторы высокоуровневых языков поддерживают прямой способ адресации. Микропроцессор аппаратно поддерживает две модели памяти: сегментированную и страничную.
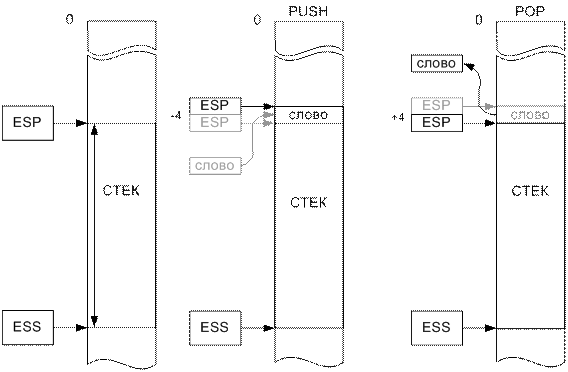
Организация стека Стек – это такая структура данных в памяти, которая используется для временного хранения информации. Программа может поместить слово в стек (команда PUSH) или извлечь его из стека (команда POP). Данные в стеке упорядочиваются специальным образом. Извлекаемый из стека элемент данных – это всегда тот элемент, который был записан туда последним. Такая организация хранения данных сокращенно обозначается LIFO (Last In, First Out – последний поступивший удаляется первым). Если мы поместим в стек два элемента: сначала A, а затем B, то при первом обращении к стеку извлекается элемент B, а при следующем – A. Информация выбирается из стека в обратном по отношению к записи порядке.
В ЭВМ за стеком резервируется блок памяти, адресуемый регистром SS и указатель, называемый указателем стека SP (Stack Pointer). Указатель стека используется программой для того, чтобы фиксировать самый последний записанный в стек элемент данных. При выполнении команды POP или PUSH значение указателя стека соответственно увеличивается или уменьшается на 4.
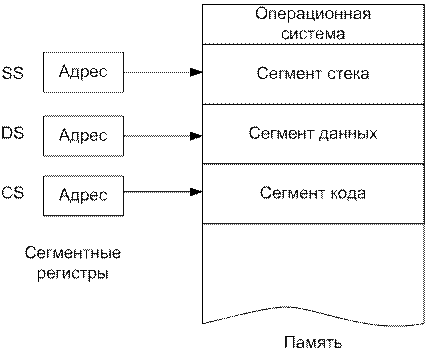
Организация памяти Физическая память, к которой микропроцессов имеет доступ по шине адреса, называется оперативной памятью ОП (или оперативным запоминающим устройством - ОЗУ). Механизм управления памятью полностью аппаратный, т.е. программа сама не может сформировать физический адрес памяти на адресной шине. Микропроцессор аппаратно поддерживает несколько моделей использования оперативной памяти: - сегментированную модель - страничную модель - плоскую модель В сегментированной модели память для программы делится на непрерывные области памяти, называемые сегментами. Сама программа может обращаться только к данным, которые находятся в этих сегментах. Сегменты - это логические элементы программы. Сегмент представляет собой независимый, поддерживаемый на аппаратном уровне блок памяти. Сегментация - механизм адресации, обеспечивающий существование нескольких независимых адресных пространств как в пределах одной задачи, так и в системе в целом для защиты задач от взаимного влияния. Программист может либо самостоятельно разбивать программу на фрагменты (сегменты), либо автоматизировать этот процесс и возложить его на систему программирования. Для микропроцессоров Intel принят особый подход к управлению памятью. Каждая программа в общем случае может состоять из любого количества сегментов, но непосредственный доступ она имеет только к 3 основным сегментам: кода, данных и стека и к 3 дополнительным сегментам данных. 1. Сегмент кодов (. CODE) – содержит машинные команды, которые будут выполняться. Обычно первая выполняемая команда находится в начале этого сегмента, и операционная система передает управление по адресу данного сегмента для выполнения программы. Регистр сегмента кодов (CS) адресует данный сегмент. 2. Сегмент данных (. DATA) – содержит определенные данные, константы и рабочие области, необходимые программе. Регистр сегмента данных (DS) адресует данный сегмент. 3. Сегмент стека (. STACK). Стек содержит адреса возврата как для программы (для возврата в операционную систему), так и для вызовов подпрограмм (для возврата в главную программу). Регистр сегмента стека (SS) адресует данный сегмент. Адрес текущей вершины стека задается регистрами SS:SP. Регистры дополнительных сегментов (ES, FS, GS), предназначены для специального использования. На рис. 3 графически представлены регистры SS, DS и CS. Последовательность регистров и сегментов на практике может быть иной. Три сегментных регистра содержат начальные адреса соответствующих сегментов, и каждый сегмент начинается на границе параграфа.
Рисунок 3 Операционная система размещает сегменты программы в ОП по определенным физическим адресам, а значения этих адресов записывает в определенные места, в зависимости от режима работы микропроцессора: - в реальном режиме адреса помещаются непосредственно в сегментные регистры (cs, ds, ss, es, gs, fs); - в защищенном режиме - в специальную системную дескрипторную таблицу (Элементом дескрипторной таблицы является дескриптор сегмента. Каждый сегмент имеет дескриптор сегмента -8 байт. Существует три дескрипторные таблицы. Адрес каждой таблицы записывается в специальный системный регистр). Для доступа к данным внутри сегмента обращение производится относительно начала сегмента линейно, т.е. начиная с 0 и заканчивая адресом, равным размеру сегмента. Этот адрес называется смещением (offset).
Таким образом, для обращения к конкретному физическому адресу ОП необходимо определить адрес начала сегмента и смещение внутри сегмента. Физический адрес принято записывать парой этих значений, разделенных двоеточием segment: offset Например, 0040:001Ch; 0000:041Ch; 0020:021Ch; 0041:000Ch. В качестве примера адресации допустим, что регистр сегмента данных содержит 045Fh, и некоторая команда обращается к ячейке памяти внутри сегмента данных со смещением 0032h. Несмотря на то, что регистр сегмента данных содержит 045Fh, он указывает на адрес 045F0, то есть на границу параграфа. Действительный адрес памяти поэтому будет следующий: Адрес в DS: 045F0 Смещение: 0032 Реальный адрес: 04622 Адрес указывается как DS:0032h ОС строит для каждого исполняемого процесса соответствующую таблицу дескрипторов сегментов и при размещении каждого из сегментов в ОП или внешней памяти в дескрипторе отмечает его текущее местоположение (бит присутствия). Дескриптор содержит поле адреса, с которого сегмент начинается и поле длины сегмента. Благодаря этому можно осуществлять контроль 1) размещения сегментов без наложения друг на друга 2) обращается ли код исполняющейся задачи за пределы текущего сегмента. В дескрипторе содержатся также данные о правах доступа к сегменту (запрет на модификацию, можно ли его предоставлять другой задаче) и защита. Достоинства сегментной организации памяти: 1) общий объем виртуальной памяти превосходит объем физической памяти 2) возможность размещать в памяти как можно больше задач (до определенного предела) увеличивает загрузку системы и более эффективно используются ресурсы системы Недостатки: 1) увеличивается время на доступ к искомой ячейке памяти, т.к. должны вначале прочитать дескриптор сегмента, а потом уже, используя его данные, можно вычислить физический адрес (для уменьшения этих потерь используется кэширование - дескрипторы, с которыми работа идет в данный момент размещаются в сверхоперативной памяти - в специальных регистрах процессора); 2) фрагментация; 3) потери памяти на размещение дескрипторных таблиц 4) потери процессорного времени на обработку дескрипторных таблиц.
Страничная модель памяти – это надстройка над сегментной моделью. ОП делится на блоки фиксированного размера 4 Кб (должно быть число, кратное степени двойки, чтобы операции сложения можно было бы заменить на операции конкатенации). Каждый такой блок называется страницей. Основное применение этой модели связано с организацией виртуальной памяти. Для того, чтобы использовать для работы программ пространство памяти большее, чем объем физической памяти используется механизм виртуальной памяти. Суть его заключается в том, что у микропроцессора существует возможность по обмену страницами памяти с жестким диском. В случае, если программа требует памяти больше, чем объем физической памяти, редко используемые страницы памяти записываются на жесткий диск в специальный файл виртуальной памяти (файл обмена, или страничный файл, или файл подкачки, чаще swap-файлом, подчеркивая, что страницы этого файла замещают друг друга в ОП). Файл подкачки может динамически изменять свой размер в зависимости от потребностей системы. Программа также разбивается на фрагменты - страницы. Все фрагменты программы одинаковой длины, кроме последней страницы. Говорят, что память разбивается на физические страницы, а программа - на виртуальные страницы. Трансляция (отображение) виртуального адресного пространства задачи на физическую память осуществляется с помощью таблицы страниц. Для каждой текущей задачи создается таблица страниц. Диспетчер памяти для каждой страницы формирует соответствующий дескриптор. Дескриптор содержит так называемый бит присутствия. Если он = 1, это означает, что данная страница сейчас размещена в ОП. Если он = 0, то страница расположена во внешней памяти. Защита страничной памяти основана на контроле уровня доступа к каждой странице. Каждая страница снабжается кодом уровня доступа (только чтение; чтение и запись; только выполнение). При работе со страницей сравнивается значение кода разрешенного уровня доступа с фактически требуемым. При несовпадении работа программы прерывается. Страничная модель памяти поддерживается только в защищенном режиме работы микропроцессора. Основное достоинство страничного способа распределения памяти - минимально возможная фрагментация (эффективное распределение памяти). Недостатки: 1) потери памяти на размещение таблиц страниц 2) потери процессорного времени на обработку таблиц страниц (диспетчер памяти). 3) программы разбиваются на страницы случайно, без учета логических взаимосвязей, имеющихся в коде (межстраничные переходы осуществляются чаще, чем межсегментные + трудности в организации разделения программных модулей между выполняющими процессами).
Сегментно-страничный способ распределения памяти Программа разбивается на сегменты. Адрес, по-прежнему, состоит из двух частей: сегмент + смещение. Но смещение относительно начала сегмента может состоять из двух полей: виртуальной страницы и индекса. Для доступа к памяти необходимо: 1) вычислить адрес дескриптора сегмента и причитать его; 2) вычислить адрес элемента таблицы страниц этого сегмента и извлечь из памяти необходимый элемент; 3) к номеру (адресу) физической страницы приписать номер (адрес) ячейки в странице. Задержка в доступе к памяти (в три раза больше, чем при прямой адресации). Чтобы избежать этого вводится кэширование (кэш строится по ассоциативному принципу).
Плоская модель памяти Если считать, что задача состоит из одного сегмента, который, в свою очередь, разбит на страницы, то фактически мы получаем только один страничный механизм работы с виртуальной памятью. Это подход называется плоской памятью. Достоинства: 1) При использовании плоской модели памяти упрощается создание и ОС, и систем программирования. 2) уменьшаются расходы памяти на поддержку системных информационных структур В абсолютном большинстве современных 32-разрядных ОС (для микропроцессоров Intel) используется плоская модель памяти.
Задание модели памяти Модели памяти задаются директивой.MODEL, которая определяет модель памяти, используемую программой. Директива должна находиться перед любой из директив объявления сегментов (.DATA,.STACK,.CODE, SEGMENT). Параметр модель_памяти является обязательным. .MODEL [модификатор] модель_памяти [,соглашение_о_вызовах] [,тип_ОС] [,параметр_стека] Основные модели памяти Ассемблера: Таблица 3
Модель small поддерживает один сегмент кода и один сегмент данных. Данные и код при использовании этой модели адресуются как near (ближние). Модель large поддерживает несколько сегментов кода и несколько сегментов данных. По умолчанию все ссылки на код и данные считаются дальними (far). Модель huge практически эквивалентна модели памяти large. Модель medium поддерживает несколько сегментов программного кода и один сегмент данных, при этом все ссылки в сегментах программного кода по умолчанию считаются дальними (far), а ссылки в сегменте данных — ближними (near). Модель compact поддерживает несколько сегментов данных, в которых используется дальняя адресация данных (far), и один сегмент кода с ближней адресацией (near). Модель tiny работает только в 16-разрядных приложениях MS-DOS. В этой модели все данные и код располагаются в одном физическом сегменте. Размер программного файла в этом случае не превышает 64 Кбайт. Модель flat предполагает несегментированную конфигурацию программы и используется только в 32-разрядных операционных системах. Эта модель подобна модели tiny в том смысле, что данные и код размещены в одном сегменте, только 32-разрядном. Для разработки программы для модели flat перед директивой.model flat следует разместить одну из директив:.386,.486,.586 или.686. Желательно указывать тот тип процессора, который используется в машине, хотя на машинах с Intel Pentium можно указывать директивы.386 и.486. Операционная система автоматически инициализирует сегментные регистры при загрузке программы, поэтому модифицировать их нужно, только если необходимо смешивать в одной программе 16- и 32-разрядный код. Адресация данных и кода является ближней (near), при этом все адреса и указатели являются 32-разрядными. Параметр модификатор используется для определения типов сегментов и может принимать значения use16 (сегменты выбранной модели используются как 16-битные) или use32 (сегменты выбранной модели используются как 32-битные). Параметр соглашение_о_вызовах используется для определения способа передачи параметров при вызове процедуры из других языков, в том числе и языков высокого уровня (C++, Pascal). Параметр может принимать следующие значения: C, BASIC, FORTRAN, PASCAL, SYSCALL, STDCALL. При разработке модулей на ассемблере, которые будут применяться в программах, написанных на языках высокого уровня, обращайте внимание на то, какие соглашения о вызовах поддерживает тот или иной язык. Более подробно соглашения о вызовах мы будем рассматривать при анализе интерфейса программ на ассемблере с программами на языках высокого уровня. Параметр тип_ОС равен OS_DOS по умолчанию, и на данный момент это единственное поддерживаемое значение этого параметра. Параметр параметр_стека устанавливается равным NEARSTACK (регистр SS равен DS, области данных и стека размещаются в одном и том же физическом сегменте) или FARSTACK (регистр SS не равен DS, области данных и стека размещаются в разных физических сегментах). По умолчанию принимается значение NEARSTACK. ОПЕРАНДЫ ЯЗЫКА АССЕМБЛЕР Операнды ассемблера описываются выражениями с числовыми и текстовыми константами, метками и идентификаторами переменных с использованием знаков операций и некоторых зарезервированных слов. Операнды могут комбинироваться с арифметическими, логическими, побитовыми и атрибутивными операторами для расчета некоторого значения или определения ячейки памяти, на которую будет воздействовать данная команда или директива. Под способами адресации понимаются существующие способы задания адреса хранения операндов. · Операнд задается на микропрограммном уровне: в этом случае команда явно не содержит операнда, алгоритм выполнения команды использует некоторые объекты по умолчанию (регистры, признаки и т.д.). mul bx; неявно использует регистр ax · Операнд задается в самой команде (непосредственный операнд): операнд является частью кода команды. Для хранения такого операнда в команде выделяется поле длиной до 32 бит. Непосредственный операнд может быть только вторым операндом (источником). Операнд-получатель может находиться либо в памяти, либо в регистре. mov ax,0ffffh ; пересылает в регистр ах константу ffff add sum,2 ; складывает содержимое поля по адресу sum ; с целым числом 2 и записывает результат в sum. · Операнд находится в одном из регистров (регистровый операнд): в коде команды указываются именами регистров. В качестве регистров могут использоваться: o 32-разрядные регистры ЕАХ, ЕВХ, ЕСХ, EDX, ESI, EDI, ESP, EBP; o 16-разрядные регистры АХ, ВХ, СХ, DX, SI, DI, SP, ВР; o 8-разрядные регистры АН, AL, BH, BL, CH, CL, DH, DL; o сегментные регистры CS, DS,,SS, ES, FS, GS. add ax,bx ; складывает содержимое регистров ах и bх ; и записывает результат в aх dec si ; уменьшает содержимое si на 1. · Операнд располага
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-12-09; просмотров: 249; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.133.136.95 (0.023 с.) |

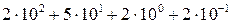 .
.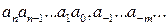
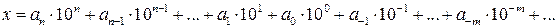 ,
,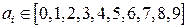 . При этом запятая, отделяющая целую часть от дробной и является, по существу, началом отсчета.
. При этом запятая, отделяющая целую часть от дробной и является, по существу, началом отсчета.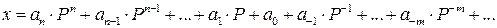 .
.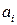 данной записи может быть одним из базисных чисел и изображается одной цифрой. Числа в P -ичной системе счисления записываются в виде перечисления всех коэффициентов полинома с указанием положения запятой:
данной записи может быть одним из базисных чисел и изображается одной цифрой. Числа в P -ичной системе счисления записываются в виде перечисления всех коэффициентов полинома с указанием положения запятой: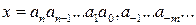
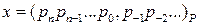 ,
,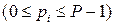 . Требуется найти запись этого числа x в системе счисления с основанием Q:
. Требуется найти запись этого числа x в системе счисления с основанием Q: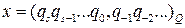 ,
,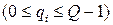 .
.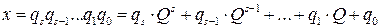 (1)
(1)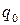 разделим обе части равенства (1) на Q, причем в левой части произведем фактическое деление, поскольку запись числа x в P -ичной системе нам известна, а в правой части деление выполним аналитически:
разделим обе части равенства (1) на Q, причем в левой части произведем фактическое деление, поскольку запись числа x в P -ичной системе нам известна, а в правой части деление выполним аналитически: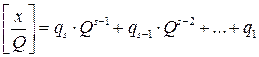 . (2)
. (2)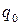 в разложении (1) является остатком от деления x на Q. Число
в разложении (1) является остатком от деления x на Q. Число 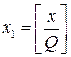 является целым, и к нему тоже можно применить описанную процедуру:
является целым, и к нему тоже можно применить описанную процедуру: , (3)
, (3)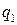 – остаток от деления (3).
– остаток от деления (3).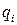 одной Q -ичной цифрой.
одной Q -ичной цифрой.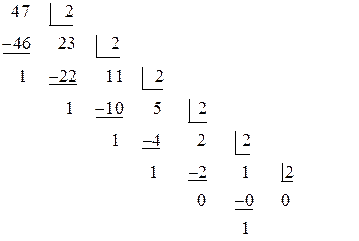
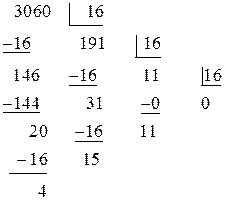
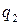 =1110 = B16. Искомое число
=1110 = B16. Искомое число 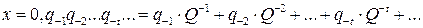 (4)
(4)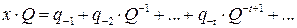 ,
,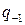 является целой частью, а
является целой частью, а 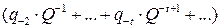 – правильная дробь. Искомые коэффициенты
– правильная дробь. Искомые коэффициенты 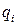 могут быть определены по формуле
могут быть определены по формуле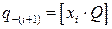 ,
,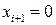 , либо не будет достигнута требуемая точность числа.
, либо не будет достигнута требуемая точность числа.

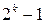 со значением k, достаточным для адресации всей памяти компьютера. Все 2 k адресов составляют адресное пространство компьютера.
со значением k, достаточным для адресации всей памяти компьютера. Все 2 k адресов составляют адресное пространство компьютера.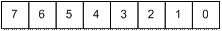


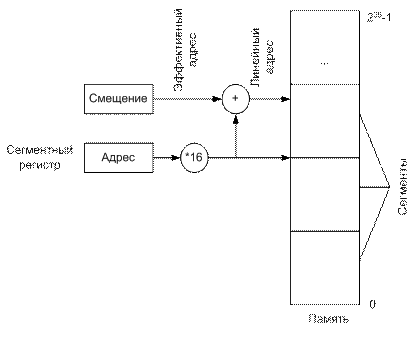 Двухбайтовое смещение (16-бит) может быть в пределах от 0000h до FFFFh или от 0 до 65535. Для обращения к любому адресу в программе, компьютер складывает адрес в регистре сегмента и смещение. Например, первый байт в сегменте кодов имеет смещение 0, второй байт – 01 и так далее.
Двухбайтовое смещение (16-бит) может быть в пределах от 0000h до FFFFh или от 0 до 65535. Для обращения к любому адресу в программе, компьютер складывает адрес в регистре сегмента и смещение. Например, первый байт в сегменте кодов имеет смещение 0, второй байт – 01 и так далее.


