
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Элементы технологии алгоритмов MPEG
Стандарт MPEG-2 Рассмотрим в качестве примера стандарт MPEG-2, который состоит из трех основных частей: системной, видео и звуковой. Системная часть описывает форматы кодирования для мультиплексирования звуковой, видео- и другой информации, рассматривает вопросы комбинирования одного или более потоков данных в один или множество потоков, пригодных для хранения или передачи. Системное кодирование в соответствии с синтаксическими и семантическими правилами, налагаемыми данным стандартом, обеспечивает необходимую и достаточную информацию, чтобы синхронизировать декодирование без переполнения или «недополнения» буферов декодера при различных условиях приема или восстановления потоков. Таким образом, системный уровень выполняет пять основных функций: • синхронизацию нескольких сжатых потоков при воспроизведении; • объединение нескольких сжатых потоков в единый поток; • инициализацию для начала воспроизведения; • обслуживание буфера; • определение временной шкалы. Видео часть стандарта описывает кодированный битовый поток для высококачественного цифрового видео. MPEG-2 является совместимым расширением MPEG-1, он поддерживает чересстрочный видеоформат и содержит средства для поддержки ТВЧ (телевидение высокой четкости). Стандарт MPEG-2 определяется в терминах расширяемых профилей, каждый из которых, являясь частным случаем стандарта, имеет черты, необходимые всем классам приложений. Иерархические масштабируемые профили могут поддерживать такие приложения, как совместимое наземное многопрограммное ТВ (ТВЧ), пакетные сетевые видеосистемы, обратную совместимость с другими стандартами (MPEG-1 и Н.261) и приложениями, использующими многоуровневое кодирование. Звуковая часть стандарта MPEG-2 определяет кодирование многоканального звука. MPEG-2 поддерживает до пяти полных широкополосных каналов плюс дополнительный низкочастотный канат и (или) до семи многоязычных комментаторских каналов. Он также расширяет возможности кодирования моно-и стереозвуковых сигнатов в MPEG-1 за счет использования половинных частот дискретизации (16; 22,05 и 24 кГц) для улучшения качества при скоростях передачи 64 кбит/с и ниже. JPEG-форматы (M-JPEG CinePack) основаны на сжатии каждого кадра из видеопоследовательности. Этот подход получил название intraframe compression (внутрикадровое сжатие). Стандарт MPEG использует как intraframe. так и interframe compression (межкадровое сжатие). При межкадровом сжатии задаются опорные кадры, а последующие и предыдущие вычисляются на их основе. Поэтому межкадровая схема позволяет достичь большего сжатия — не надо хранить каждый кадр, запоминаются только различия между кадрами.
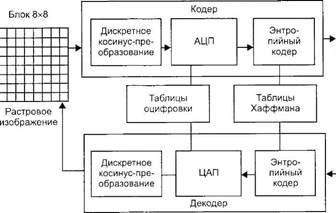
Стандарт MPEG-2 не регламентирует методы сжатия видеосигнала, а только определяет, как должен выглядеть битовый поток кодированного вилеосигната, поэтому конкретные алгоритмы являются коммерческой тайной фирм—производителей оборудования. Однако существуют общие принципы, и процесс сжатия цифрового видеосигнала может быть разбит на ряд последовательных операций (рис. 3.15): • преобразование анатогового сигнала в цифровую форму; • предварительная обработка; • дискретное косинусное преобразование: • квантование; • кодирование. После аналого-цифрового преобразователя (АЦП) производится предварительная обработка сигнала, которая включает в себя следующие преобразования. 1. Удаление избыточной информации. Например, если фон изображения состоит из идентичных символов (пикселей), то совершенно не обязательно их все передавать. Достаточно описать один пиксель и послать его с сообщением о том, как часто и где он повторяется в изображении. 2. Если исходное изображение передается в виде чересстрочных полей, то они преобразуются в кадры с прогрессивной разверткой. 3. Сигналы цветности (RGB) преобразуются в цветоразност- ные сигначы U и V и сигнал яркости Y. 4. Изображение достраивается до кратного 16 количества пикселей по строкам и столбцам, чтобы обеспечить разбиение изображения на целое число макроблоков.
5. Производится преобразование из формата цветности 4: 4: 4 в формат 4:2:2 (горизонтальная передискретизация цве- торазностных компонентов) или 4:2:0 (горизонтальная и вертикальная передискретизация цветоразностных компонентов). Квантование. Изображение разбивается на последовательность макроблоков, каждый из которых состоит из шести блоков по 8 х 8 пикселей:
• четыре образуют матрицу 16 х 16 и несут информацию о яркости; • по одному — определяют цветоразностные компоненты U и V, которые соответствуют области изображения, покрываемой матрицей 16x16 пикселей. Стандарт предусматривает два формата цветности, каждому из которых соответствует свой порядок блоков в макроблоке (рис. 3.16): • 4:2:0 — макроблок состоит из шести блоков — четыре блока яркости YD и два блока цветности CR И Св; • 4:4:4 — макроблок состоит из двенадцати блоков. Он содержит четыре блока YD, четыре CR и четыре Св. Производится разбиение потока кадров изображения по типам, для них находятся векторы движения, которые необходимы для повышения предсказуемости величин элементов изображения. Векторы движения обеспечивают компенсацию пере- yd
мещений в прошедших и последующих кадрах. Компенсация движения применяется при предсказании текущего кадра на основе предыдущих и интерполяционного предсказания на основе прошедших и последующих изображений. Векторы движения определяются для каждой зоны изображения с размерами 16 х 16 пикселей, т. е. для макроблоков. В большинстве случаев видеопоследовательности содержат избыточность в двух направлениях — временном и пространственном. Главное статистическое свойство, на котором основана аппаратура сжатия, — межэлементная корреляция, включающая предположение о коррелированное™ последовательных кадров видеоданных. Таким образом, значения отдельных пикселей изображения могут быть предсказаны либо по значениям ближайших пикселей внутри одного кадра (внутрикадровое кодирование), либо по значениям пикселей, расположенных в ближайших кадрах (межкадровое кодирование и компенсация перемещения). Кодирование. В некоторых случаях, например, при смене видеосцены в видеопоследовательности, временная корреляция между ближайшими кадрами очень низка. В таких случаях решающую роль в достижении эффективного сжатия видеоинформации играет внутрикадровая корреляция, т. е. пространственная корреляция пикселей изображения. Однако, если корреляция между последовательными кадрами видеоданных высока, то в случае, когда два последовательных кадра имеют схожее или одинаковое содержание, желательно применение межкадровой корреляции пикселей с временным предсказанием. На практике для достижения высокого коэффициента сжатия видеоинформации используется комбинация из двух подходов. Стандарт MPEG-2 определяет три типа кадров, для каждого из которых предусмотрен свой вид кодирования: • опорные кадры, так называемые 1-кадры (Intra Frames), которые являются основными и кодируются без обращения к другим кадрам, т. е. с использованием информации только этого кадра. Вид кодирования — внутрикадровый, обеспечивающий умеренное сжатие. Все остальные кадры анализируются процессором, который сравнивает их с опорными, а также между собой; • Р-кадры (Predicted) — закодированные относительно предыдущих I- или Р-кадров. Кодирование Р-кадров выполняют с использованием алгоритмов компенсации движения и предсказанием «вперед» по предшествующим I- и Р-кад- рам. Они сжаты в 3 раза сильнее, чем I-кадры, и служат опорными для последующих Р- и В-кадров. Компенсация движения, применяемая к макроблокам Р-кадров, вырабатывает два вида информации: векторы движения (разница между базовыми и кодированными макроблоками) и значения ошибок (разница между предсказанными величинами и действительными результатами). Если макроблок в Р-кадре не может быть описан с использованием компенсации движения, что случается при появлении некоторого неизвестного объекта, то он кодируется тем же способом, что и макроблок в 1-кадре;
• В-кадры (Bidirectionally Predicted) — закодированные относительно предыдущих и последующих кадров, т. е. с двунаправленным предсказанием и компенсацией движения. В-кадры имеют наибольшее сжатие. Таким образом, в стандарте MPEG-2 используются три вида кодирования: внутрикадровое. межкадровое «вперед» с компенсацией движения, межкадровое двунаправленное, также с компенсацией движения. Полученные кадры объединяются в группы последовательных кадров (GOP — group of pictures). Каждая последовательность начинается с I-кадра и состоит из переменного числа Р- и В-кадров. В описаниях алгоритмов кодирования MPEG и его реализаций не содержится никакой информации относительно методов выделения I-, Р- и В-кадров в видеопоследовательности. В начале сцены должен стоять I-кадр, в конце — Р-кадр. Увеличивать долю В-кадров можно только в рамках одной сцены, иначе возникнут большие ошибки предсказания и компенсации движения. Поскольку типичная длительность группы кадров (во временном представлении — примерно 0,5 с) значительно меньше характерного расстояния между границами сцен, то в большинстве случаев жесткое задание структуры группы кадров не приводит к существенным визуальным ошибкам из-за того, что смена сцен попадает внутрь группы кадров. На рис. 3.17 изображен порядок кодирования I-, Р- и В-кадров. Верхний ряд кадров демонстрирует исходную последовательность на входе кодера, нижний — после кодирования. Основными параметрами GOP являются длина последовательности N и порядок чередования Р-кадров. Например, в последовательности кадров, представленной на рис. 3.17, N= 7, М = 3, т. е. каждый третий кадр в последовательности — типа Р. Из применявшихся до сих пор форматов групп для частоты полей 30 Гц типичной была последовательность IBBPBBPBBPBBP/BBTBBP... с N= 13 (для первой группы) и М= 3, в которой группу составляют 1,5 кадров, начинающихся с двух В-кадров и одного I-кадра, и каждые два В-кадра перемежаются с Р-кадром. Для частоты 25 Гц типичной является такая же последовательность, но с N= 12 и Л/ = 3. Такой выбор сделан для того, чтобы обеспечить одновременное выполнение требований максимального сжатия и произвольного доступа к любому из кадров последовательности. Между тем именно В-кадры обеспечивают максимальное сжатие, и если бы удалось поднять долю В-кадров в группе, а I-кадрами обозначить границы сцен, то эффективность сжатия была бы увеличена.
Для блоков с использованием компенсации движения находятся разностные ошибки предсказания движения.
Следует упомянуть еще две возможности MPEG-алгоритмов. Это Motion Estimation (ME, в свободном переводе — оценка перемещений) и Spatial Redundancy (SR — пространственная избыточность). ME — метод, по которому реализуется вычисление Р- и В- кадров по опорным кадрам. Первым шагом в ME является На следующем этапе кодирования применяется метод пространственной избыточности, позволяющий еще более сократить объем данных, описывая разность между соответствующими блоками. Используя дискретное косинус-преобразование, блоки подразделяются на подблоки 8 \ 8 для отслеживания изменения цвета и яркости. Очевидно, что чем больше коэффициент сжатия, тем хуже качество. Коэффициент сжатия — это численное выражение соотношения между объемом сжатого и исходного видеоматериала. Для MPEG сейчас стандартом считается соотношение 200:1, при этом сохраняется неплохое качество видео. Различные варианты Motion-JPEG работают с коэффициентами от 5:1 до 100: 1, хотя даже при уровне в 20: 1 уже трудно добиться нормального качества изображения. Кроме того, качество видео зависит не только от алгоритма сжатия (MPEG или Motion-JPEG), но и от параметров цифровой видеоплаты, конфигурации компьютера, а также от программного обеспечения. Профили MPEG Как уже отмечалось выше, в стандарте применяется концепция профилей и уровней (табл. 3.8). Стандарт предусматривает пять профилей: • простой (simple) — для реализации видеопотока без В-кадров; • главный (main) — для реализации всех уровней, но без масштабируемости: • масштабируемый по отношению сигнал/шум (SNR scalable); • пространственно масштабируемый (spatiallvscalable); • профессиональный (professional 4:2:2). пространственно масштабируемый и масштабируемый по отношению сигнал/шум. Каждый из этих профилей можно подразделить на четыре уровня: • низкий (LL); • главный (ML):
. высокий 1440 (HI440);
• высокий (HL). Каждому профилю соответствуют определенные наборы операций по сжатию данных. В профиле простой используется наименьшее число операций: компенсация движения и гибридное дискретное косинусное преобразование (ДКП. DCT). Профиль главный содержит дополнительную операцию — предсказание по двум направлениям, что улучшает качество изображения. Профиль масштабируемый по отношению сигнал/шум предусматривает повышение устойчивости системы при снижении отношения сигнал/шум. Поток видеоданных разделяют на две части: базовый поток и расширенный поток. Первый несет наиболее значимую информацию, второй — дополнительную. Профиль пространственно масштабируемый содержит все операции предыдущего профиля и новую — разделение потока видеоданных по критерию четкости телевизионного изображения. Этот профиль обеспечивает переходы между ныне действующим стандартом и ТВЧ. В рассмотренных четырех профилях при кодировании сигналов яркости и цветности используют формат представления видеоданных 4:2:0, где число отсчетов сигналов цветности по сравнению с сигналом яркости снижено в 2 раза по горизонтальному и вертикальному направлениям. В профиле профессиональный используют формат 4: 2: 2, т. е. число отсчетов сигналов цветности в вертикальном направлении такое же, как и в яркостном сигнале. Кроме этого, предусматривается возможность масштабирования — пространственного и по отношению сигнал/шум. Уровню низкий соответствует недавно введенный класс качества телевизионного изображения — ТВ ограниченной четкости. Уровню главный соответствует ТВ обычной четкости. Уровни высокий 144 0 и высокий предусмотрены для ТВЧ, где использовано разложение на 1152 активные строки. Каждый из этих профилей и уровней определяет предельные значения основных параметров битового потока, как это показано в табл. 3.8. Сочетание профиля и уровня образует некоторое подмножество общего стандарта MPEG-2 применительно к различным задачам, для решения которых он предназначен. Такое сочетание принято обозначать аббревиатурой. Например, MP@ML означает главный профиль и главный уровень. Профессиональный профиль в сочетании с главным уровнем (422P@ML) послужил основой принятого в 1996 г. подмножества стандарта MPEG-2 для цифрового телевешания. Описательный мультимедиа-стандарт MPEG-7 Спецификация разработана на пути использования методов и достижений интеллектуальных информационных систем в мультимедийных приложениях. Попытки решения данной задачи известны уже давно — ситуационное моделирование (Ю. И. Клыков, 1974 г.). RX-коды (1969 г.), проект PIPS (Pattern information processing system), программная среда и язык распознавания и генерации сцен NALIG — Native language interprator of graphics (Япония, 1980 г.) и др. MPEG-7 формально называется «Мультимедиа-интерфейс для описания содержимого» (Multimedia Content Description Interface), он имеет целью стандартизовать описание мультимедийного материала, поддерживающего некоторый уровень интерпретации смысла информации, которая может быть передана для обработки ЭВМ. Стандарт MPEG-7 не ориентирован на какое-то конкретное приложение, он стандартизует некоторые элементы, которые рассчитаны на поддержку как можно более широкого круга приложений. Следовательно, средства MPEG-7 позволят формировать описания (т. е. наборы схем описания и соответствующих дескрипторов по желанию пользователя) материала, который может содержать: • информацию, описывающую процессы создания и производства материала (указатель, заголовок, короткометражный игровой фильм); • информацию, относящуюся к использованию материала (указатели авторского права, история использования, расписание вешания); • информацию о характеристиках записи материала (формат записи, кодирование); • структурную информацию о пространственных, временных или пространственно-временных компонентах материала (разрезы сцены, сегментация областей, отслеживание перемещения областей): • информацию о характеристиках материала нижнего уровня (цвета, текстуры, тембры звука, описание мелодии); • концептуальную информацию о реальном содержании материала (объекты и события, взаимодействие объектов); • информацию о том. как эффективно просматривать материал (конспекты, вариации, пространственные и частотные субдиапазоны и пр.); • информацию о собрании объектов; • информацию о взаимодействии пользователя с материалом (предпочтения пользователя, история использования). MPEG-7 сконструирован так. чтобы учесть все подходы, учитывающие требования основных стандартов, таких, как SMPTE Metadata Dictionary. Dublin Силис. EBU P/Meta и TV Anytime. Эти стандарты ориентированы на специфические приложения и области применения, в то время как MPEG-7 пытается быть как можно более универсальным. MPEG-7 использует также схему XML в качестве языка выбора текстуального представления описания материала. Главными элементами стандарта MPEG-7 являются (рис. 3.18): • дескрипторы (D) — представление характеристик, которые определяют синтаксис и семантику представления каждой из характеристик; • схемы описания DS (description scheme), которые специфицируют структуру и семантику взаимодействия между компонентами. Эти компоненты могут быть дескрипторами и схемами описания; • язык описания определений DDL (description definition language), позволяющий создавать новые схемы описания и, возможно, дескрипторы, и обеспечивающий расширение и модификацию существующих схем описания; • системные средства служат для поддержки мультиплексирования описаний, синхронизации описаний и материала, механизмов передачи, кодовых представлений (как текстуальных, так и двоичных форматов) для эффективной записи и передачи, управления и защиты интеллектуальной собственности в описаниях MPEG-7. Все области применения, базирующиеся на мультимедиа, выиграют от использования MPEG-7. Ниже предлагается список
возможных приложений MPEG-7. которые любой из читателей без труда сможет дополнить: • архитектура, недвижимость и интерьерный дизайн (например, поиск идей): • выбор широковещательного медийного канала (например, радио. TV); • услуги в сфере культуры (исторические музеи, картинные галереи и т. д.): • цифровые библиотеки (например, каталоги изображений, музыкальные словари, биомедицинские кататоги изображений. фильмы, видео- и радиоархивы); • е-коммерция (например, целевая реклама, каталоги реального времени, каталоги электронных магазинов); • образование (например, депозитарии мультимедийных курсов, мультимедийный поиск дополнительных материалов); • домашние развлечения (например, системы управления личной мультимедийной коллекцией, включая манипуляцию содержимым, например, редактирование домашнего видео, поиск игр. караоке); • исследовательские услуги (например, распознавание человеческих особенностей, экспертизы); • журнатизм (например, поиск речей определенного политика, используя его имя. его голос или его лицо); • мультимедийные службы каталогов (например, желтые страницы, туристская информация, географические информационные системы): • мультимедийное редактирование (например, персональная электронная служба новостей, персональная медийная среда для творческой деятельности): • удаленное опознавание (например, картография, экология, управление природными ресурсами); • осуществление покупок (например, поиск одежды, которая вам нравится): • надзор (например, управление движением, транспортом, неразрушаюший контроль в агрессивной среде). В принципе, любой тип аудиовизуального материала может быть получен с помощью любой разновидности материала в запросе. Это означает, например, что видеоматериал может быть запрошен с помощью видео, музыки, голоса и т. д. Ниже приведены примеры запросов: •проиграйте несколько нот на клавиатуре, и вы получите список музыкальных отрывков, сходных с проигранной мелодией, или изображений, соответствующих некоторым образом нотам, например, в эмоциональном плане; •нарисуйте несколько линий на экране, ивы найдете набор изображений, содержащих похожие графические образы, логотипы, идеограммы; •определите объекты, включая цветовые пятна или текстуры, и вы получите образцы, среди которых сможете выбрать интересующие вас объекты; • опишите действия и получите список сценариев, содержащих эти действия; • используя фрагмент голоса Паваротти, получите список его записей, видеоклипов, где Паваротти поет, и графический материал, имеющий отношение к этому певцу. Рассмотрим пример описания визуального материала (рис. 3.19, а) графовыми представлениями (рис. 3.19, б). Этот пример демонстрирует момент футбольного матча. Определены два видеосегмента, одна стационарная область и три движущиеся области. Граф. описывающий структуру материала, показан на рис. 3.19.
Video Segmm! ■
а
Видеосегмент Dribble&Kick (Обводка и удар) включает в себя мяч, вратаря и игрока. Мяч остается рядом с игроком, движущимся к вратарю. Игрок появляется справа от вратаря. Видеосегмент гол включает в себя те же подвижные области плюс стационарную область ворота. В этой части последовательности игрок находится слева от вратаря, а мяч движется к воротам. Этот простой пример иллюстрирует гибкость данного вида представления. Заметим, что это описание в основном представляется структурным, так как отношения, специфицированные ребрами графа, являются чисто физическими, а узлы представляют объекты, которые описываются данными о создании, информацией об использовании и медиаданными, а также дескрипторами низкого уровня, такими, как цвет, форма, движение. В семантически явном виде доступна только информация из текстовой аннотации (где могут быть специфицированы ключевые слова мяч, игрок или вратарь). Контрольные вопросы 1. Каковы характеристики аналогово-цифрового и цифро-аналогового преобразований аудиоданных? 2. Перечислите методы синтеза звука. 3. Какие характеристики имеют аудиоадаптеры? 4. Что такое ЧМ и WaveTable? 5. Перечислите возможности карты SoundBlaster. 6. Что такое LivelDrive? 7. Охарактеризуйте MIDI-интерфейс. 8. Перечислите основные характеристики форматов аудиосигнала. 9. Какие основные функции реализует программное обеспечение обработки аудиосигналов? 10. Охарактеризуйте методы оптической интерполяции. 11. Перечислите основные характеристики цифровых видеокамер (ЦВК). 12. Что такое схемы цветообразования? 13. Охарактеризуйте форматы графических файлов. 14. Что такое видеозахват? 15. Что такое цветоразностные компоненты? 16. Перечислите форматы записи цифрового видео. 17. В чем заключается сущность M-JPEG сжатия видеоданных? 18. Перечислите основные особенности алгоритмов MPEG-1—4. 19. Что такое GOP? 20. Что такое профили MPEG? 21. В чем сущность стандарта MPEG-7? Глава 4 ИНФОРМАЦИОННЫЕ КРОСС-ТЕХНОЛОГИИ К данному классу отнесены технологии пользователя, ориентированные на следующие (или аналогичные) виды преобразования информации: • распознавания символов: • звук—текст: • текст—звук; • автоматический перевод. 4.1. Оптическое распознавание символов (OCR) Когда страница текста отсканирована в ПК, она представлена в виде состоящего из пикселей растрового изображения. Такой формат не воспринимается компьютером как текст, а как изображение текста и текстовые редакторы не способны к обработке подобных изображений. Чтобы превратить группы пикселей в доступные для редактирования символы и слова, изображение должно пройти сложный процесс, известный как оптическое распознавание символов (optical character recognition — OCR). В то время как переход от символьной информации к графической (растровой) достаточно элементарен и без труда осуществляется, например при выводе текста на экран или печать, обратный переход (от печатного текста к текстовому файлу в машинном коде) весьма затруднителен. Именно в связи с этим для ввода информации в ЭВМ исстари использовались перфоленты, перфокарты и др. промежуточные носители, а не исходные «бумажные» документы, что было бы гораздо удобнее. ■ В защиту» перфокарт скажем здесь, что наиболее «продвинутые» устройства перфорации делали надпечатку на карте для проверки ее содержания. Первые шаги в области оптического распознавания символов были предприняты в конце 50-х гг. XX в. Принципы распознавания, заложенные в то время, используются в большинстве систем OCR: сравнить изображение с имеющимися эталонами и выбрать наиболее подходящий. В середине 70-х гг. была предложена технология для ввода информации в ЭВМ. заключающаяся в следующем: • исходный документ печатается на бланке с помощью пишущей машинки, оборудованной стилизованным шрифтом (каждый символ комбинируется из ограниченного числа вертикальных, горизонтальных, наклонных черточек, подобно тому, как это делаем мы и сейчас, нанося на почтовый конверт цифры индекса): • полученный «машинный документ» считывается оптоэлек- трическим устройством (собственно OCR), которое кодирует каждый символ и определяет его позицию на листе; • информация переносится в память ЭВМ, образуя электронный образ документа или документ во внутреннем представлении. Очевидно, что по сравнению с перфолентами (перфокартами) OCR-документ лучше хотя бы тем. что он без особого труда может быть прочитан и проверен человеком и, вообще, представляет собой «твердую копию» соответствующего введенного документа. Было разработано несколько модификаций подобных шрифтов, разной степени «удобочитаемости» (OCR A, OCR В и пр., рис. 4.1). OCR А 123 OCR В 123 а б Рис. 4.1. Стилизованные шрифты: а - OCR А; 6— OCR В Очевидно также, что считывающее устройство представляет собой сканер, хотя и специализированный (считывание стилизованных символов), но интеллектуальный (распознавание их). OCR-технология в данном виде просуществовала недолго и в настоящее время приобрела следующий вид: • считывание исходного документа осуществляется универсальным сканером, осуществляющим создание растрового образа и запись его в оперативную память и/или в файл; • функции распознавания полностью возлагаются на программные продукты, которые, естественно, получили название OCR-software. Исследования в этом направлении качались в конце 1950-х гг.. и с тех пор технологии непрерывно совершенствовались. В 1970-х гг. и в начале 1980-х гг. программное обеспечение оптического распознавания символов все еще обладало очень ограниченными возможностями и могло работать только с некоторыми типами и размерами шрифтов. В настоящее время программное обеспечение оптического распознавания символов намного более интеллектуально и может распознать фактически все шрифты, даже при невысоком качестве изображения документа. Основные методы оптического распознавания
Один из самых ранних методов оптического распознавания символов базировался на сопоставлении матриц или сравнении с образцом букв. Большинство шрифтов имеют формат Times, Courier или Helvetica и размер от 10 до 14 пунктов (точек). Программы оптического распознавания символов, которые используют метод сопоставления с образцом, имеют точечные рисунки для каждого символа каждого размера и шрифта (рис. 4.2, а). Сравнивая базу данных точечных рисунков с рисунками отсканированных символов, программа пытается их распознавать. Эта ранняя система успешно работала толь-
ко с непропорциональными шрифтами (подобно Courier), где символы в тексте хорошо отделены друг от друга. Сложные документы с различными шрифтами оказываются уже вне возможностей таких программ. Выделение признаков было следующим шагом в развитии оптического распознавания символов. При этом распознавание символов основывается на идентификации их универсальных особенностей, чтобы сделать распознавание символов независимым от шрифтов. Если бы все символы могли быть идентифицированы, используя правила, по которым элементы букв (например, окружности и линии) присоединяются друг к другу, то индивидуальные символы могли быть описаны независимо от их шрифта. Например: символ «а» может быть представлен как состоящий из окружности в центре снизу, прямой линии справа и дуги окружности сверху в центре (рис. 4.2, б). Если отсканированный символ имеет эти особенности, он может быть правильно идентифицирован как символ «а» программой оптического распознавания. Выделение признаков было шагом вперед сравнительно с соответствием матриц, но практические результаты оказались весьма чувствительными к качеству печати. Дополнительные пометки на странице или пятна на бумаге существенно снижали точность обработки. Устранение такого «шума» само по себе стало целой областью исследований, пытающейся определить, какие биты печати не являются частью индивидуальных символов. Если шум идентифицирован, достоверные символьные фрагменты могут тогда быть объединены в наиболее вероятные формы символа. Некоторые программы сначала используют сопоставление с образцом и/или метод выделения признаков для того, чтобы распознать столько символов, сколько возможно, а затем уточняют результат, используя грамматическую проверку правильности написания для восстановления нераспознанных символов. Например, если программа оптического распознавания символов неспособна распознать символ «е» в слове «th~ir», программа проверки грамматики может решить, что отсутствующий символ — «е». Современные технологии оптического распознавания намного совершеннее, чем более ранние методы. Вместо того чтобы только идентифицировать индивидуальные символы, современные методы способны идентифицировать целые слова. Эту технологию, предложенную Caere, называют прогнозирующим оптическим распознаванием слов (Predictive Optical Word Recognition — POWR). Используя более высокие уровни контекстного анализа, метод POWR способен устранить проблемы, вызванные шумом. Компьютер анализирует тысячи или миллионы различных способов, которыми точки изображения могут быть собраны в символы слова. Каждой возможной интерпретации приписывается некоторая вероятность, после чего используются нейронные сети и прогнозирующие методы моделирования, заимствованные от исследований в области искусственного интеллекта. Они предполагают использование «экспертов» — алгоритмов, разработанных специалистами в различных областях распознавания символов. Один «эксперт» может знать многое о начертаниях шрифта, другой — о словарной информации, третий — об ухудшении качества от «зашумленности» и пр. На каждой стадии исследования привлекается новый набор «экспертов» с учетом близости их «областей знаний* к специфической ситуации и статистики успеха в подобных ситуациях. Окончательный итог — то. что система POWR способна идентифицировать слова способом, который близко напоминает человеческое визуальное распознавание. Практически, методика значительно улучшает точность распознавания слов во всех типах документа. Все возможные интерпретации слова оцениваются, комбинируя все источники доказательства, от информации пикселя нижнего уровня до контекстных особенностей высокого уровня, в результате чего выбирается самая вероятная интерпретация. Технологии Finereader
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-22; просмотров: 1139; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.218.172.210 (0.108 с.) |
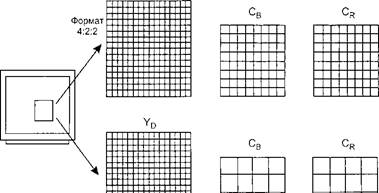 Формат 4:2:0
Рис. 3.16. Разбивка изображения на блоки в MPEG-2
Формат 4:2:0
Рис. 3.16. Разбивка изображения на блоки в MPEG-2

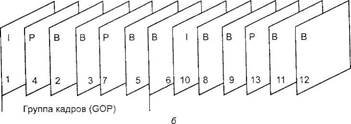 Рис. 3.17. Порядок кодирования I- Р- и В-кадров по стандарту MPEG-2: а — последовательность кадров на входе кодера; б — последовательность кадров
после кодирования
Рис. 3.17. Порядок кодирования I- Р- и В-кадров по стандарту MPEG-2: а — последовательность кадров на входе кодера; б — последовательность кадров
после кодирования
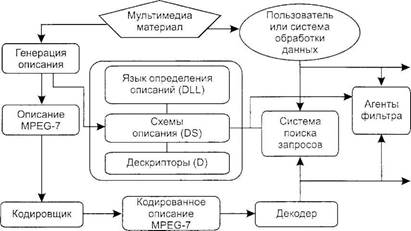 Рис. 3.18. Абстрактное представление возможных приложении на основе MPEG-7
Рис. 3.18. Абстрактное представление возможных приложении на основе MPEG-7

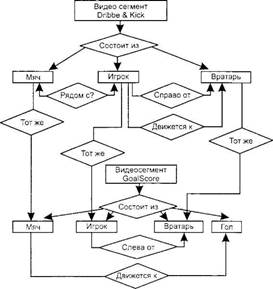 Рис. 3.19. Пример видеосегмента и областей ситуации (а); соответствующий граф (о)
Рис. 3.19. Пример видеосегмента и областей ситуации (а); соответствующий граф (о)




