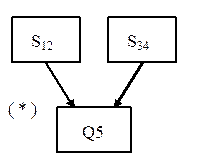Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Лекция 15. Концептуальные модели данныхСодержание книги
Поиск на нашем сайте
В отличие от инфологической модели предметной области, описывающей по некоторым правилам сведения об объектах материального мира и связи между ними, которые следует иметь в БД, концептуальная модель описывает хранимые в ЭВМ данные и связи. В силу этого каждая модель данных неразрывно связана с языком описания данных конкретной СУБД. По существу, модель данных — это совокупность трех составляющих: типов структур данных, операций над данными, ограничений целостности. Другими словами, модель данных представляет собой некоторое интеллектуальное средство проектировщика, позволяющее реализовать интерпретацию сведений о предметной области в виде формализованных данных в соответствии с определенными требованиями, т. е. средство абстракции, которое дает возможность увидеть «лес» (информационное содержание данных), а не отдельные «деревья» (конкретные значения данных). Типы структур данных Среди широкого множества определений, обозначающих типы структур данных, наиболее распространена терминология CODASYL (Conference of DAta SYstems Language) — международной ассоциации по языкам систем обработки данных, созданной в 1959 г. В соответствии с этой терминологией используют пять типовых структур (в порядке усложнения): 1. элемент данных; 2. агрегат данных; 3. запись; 4. набор; 5. база данных. Дадим краткие определения этих структур. Элемент данных — наименьшая поименованная единица данных, к которой СУБД может адресоваться непосредственно и с помощью которой выполняется построение всех остальных структур данных. Агрегат данных — поименованная совокупность элементов данных, которую можно рассматривать как единое целое. Агрегат может быть простым или составным (если он включает в себя другие агрегаты). Запись — поименованная совокупность элементов данных и (или) агрегатов. Таким образом, запись — это агрегат, не входящий в другие агрегаты. Запись может иметь сложную иерархическую структуру, поскольку допускает многократное применение агрегации. Набор — поименованная совокупность записей, образующих двухуровневую иерархическую структуру. Каждый тип набора представляет собой связь между двумя типами записей. Набор определяется путем объявления одного типа записи «записью-владельцем», а других типов записей — «записями-членами». При этом каждый экземпляр набора должен содержать один экземпляр «записи-владельца» и любое количество «записей-членов». Если запись представляет в модели данных сущность, то набор — связь между сущностями. Например, если рассматривать связь «учится» между сущностями «учебная группа» и «студент», то первая из сущностей объявляется «записью-владельцем» (она в экземпляре набора одна), а вторая — «записью-членом» (их в экземпляре набора может быть несколько).
База данных — поименованная совокупность экземпляров записей различного типа, содержащая ссылки между записями, представленные экземплярами наборов. Отметим, что структуры БД строятся на основании следующих основных композиционных правил: 1. БД может содержать любое количество типов записей и типов наборов; 2. между двумя типами записей может быть определено любое количество наборов; 3. тип записи может быть владельцем и одновременно членом нескольких типов наборов. Следование данным правилам позволяет моделировать данные о сколь угодно сложной предметной области с требуемым уровнем полноты и детализации. Рассмотренные типы структур данных могут быть представлены в различной форме — графовой; табличной; в виде исходного текста языка описания данных конкретной СУБД. Операции над данными Операции, реализуемые СУБД, включают селекцию (поиск) данных и действия над ними. Селекция данных выполняется с помощью критерия, основанного на использовании или логической позиции данного (элемента, агрегата, записи) или значения данного, либо связей между данными. Селекция на основе логической позиции данного базируется на упорядоченности данных в памяти системы. При этом критерии поиска могут формулироваться следующим образом: 1. найти следующее данное (запись); 2. найти предыдущее данное; 3. найти п- еданное; 4. найти первое (последнее) данное. Этот тип селекции называют селекцией посредством текущей селекции, в качестве которой используется индикатор текущего состояния, автоматически поддерживаемый СУБД и, как правило, указывающий на некоторый экземпляр записи БД. Критерий селекции по значениям данных формируется из простых или булевых условий отбора. Примерами простых условий поиска являются:
1. ВОЕННО-УЧЕТНАЯ СПЕЦИАЛЬНОСТЬ = 200100; 2. ВОЗРАСТ > 20; 3. ДАТА < 19.04.2002 и т.п. Булево условие отбора формируется путем объединения простых условий с применением логических операций, например: 1. (ДАТА_РОЖДЕНИЯ < 28.12.1963) И (СТАЖ > 10); 2. (УЧЕНОЕ_ЗВАНИЕ = ДОЦЕНТ) ИЛИ (УЧЕНОЕ ЗВАНИЕ = ПРОФЕССОР) и т.п. Если модель данных, поддерживаемая некоторой СУБД, позволяет выполнить селекцию данных по связям, то можно найти данные, связанные с текущим значением какого-либо данного. Например, если в модели данных реализована двунаправленная связь «учится» между сущностями «студент» и «учебная группа», можно выявить учебные группы, в которых учатся юноши (если в составе описания студента входит атрибут «пол»). Как правило, большинство современных СУБД позволяют осуществлять различные комбинации описанных выше видов селекции данных. Ограничения целостности. Эти логические ограничения на данные используются для обеспечения непротиворечивости данных некоторым заранее заданным условиям при выполнении операций над ними. По сути ограничения целостности — это набор правил, используемых при создании конкретной модели данных на базе выбранной СУБД. Различают внутренние и явные ограничения. Ограничения, обусловленные возможностями конкретной СУБД, называют внутренними ограничениями целостности. Эти ограничения касаются типов хранимых данных (например, «текстовый элемент данных может состоять не более чем из 256 символов» или «запись может содержать не более 100 полей») и допустимых типов связей (например, СУБД может поддерживать только так называемые функциональные связи, т.е. связи типа 1:1, 1: М или М: 1). Большинство существующих СУБД поддерживают прежде всего именно внутренние ограничения целостности, нарушения которых приводят к некорректности данных и достаточно легко контролируются. Ограничения, обусловленные особенностями хранимых данных о конкретной ПО, называют явными ограничениями целостности. Эти ограничения также поддерживаются средствами выбранной СУБД, но они формируются обязательно с участием разработчика БД путем определения (программирования) специальных процедур, обеспечивающих непротиворечивость данных. Например, если элемент данных «зачетная книжка» в записи «студент» определен как ключ, он должен быть уникальным, т.е. в БД не должно быть двух записей с одинаковыми значениями ключа. Другой пример: пусть в той же записи предусмотрен элемент «военно-учетная специальность» и для него отведено шесть десятичных цифр. Тогда другие представления этого элемента данных в БД невозможны. С помощью явных ограничений целостности можно организовать как «простой» контроль вводимых данных (прежде всего на предмет принадлежности элементов данных фиксированному и заранее заданному множеству значений: например, элемент «ученое звание» не должен принимать значение «почетный доцент», если речь идет о российских ученых), так и более сложные процедуры (например, введение значения «профессор» элемента данных «ученое звание» в запись о преподавателе, имеющем возраст 25 лет, должно требовать, по крайней мере, дополнительного подтверждения). Элементарная единица данных может быть реализована множеством способов, что, в частности, привело к многообразию известных моделей данных. Модель данных определяет правила, в соответствии с которыми структурируются данные. Обычно операции над данными соотносятся с их структурой.
Разнообразие существующих моделей данных соответствует разнообразию областей применения и предпочтений пользователей. В специальной литературе встречается описание довольно большого количества различных моделей данных. Хотя наибольшее распространение получили иерархическая, сетевая и, бесспорно, реляционная модели, вместе с ними следует упомянуть и некоторые другие. Используя в качестве классификационного признака особенности логической организации данных, можно привести следующий перечень известных моделей: 1. иерархическая модель данных; 2. сетевая модель данных; 3. реляционная модель данных; 4. бинарная модель данных; 5. семантическая сеть. Лекция 16. Модели данных Существуют 3 модели данных - реляционная, сетевая и иерархическая; у них разные множества допустимых информационных конструкций. Вообще можно говорить о наличии самостоятельной модели данных в каждой СУБД. Однако, при создании СУБД происходит модификация модели данных, исходя из удобства программной реализации системы. Внутреннее описание определяет организацию данных в памяти ЭВМ и организацию доступа к ним. Оно соответствует наиболее детальному представлению о процессах обработки данных в системе. Реляционная модель данных Модель данных - указание множества допустимых информационных конструкций, операций над данными и множества ограничений для хранимых значений данных. Концепция реляционной модели данных была предложена Е.Ф. Коддом в 1970 г. в связи с необходимостью обеспечить независимость представления и описания данных от прикладных программ. Основа реляционной модели - отношение (relation). Оно удобно представляется двумерной таблицей при соблюдении определенных ограничивающих условий. Таблица понятна, обозрима и привычна для человека (см. рис.15).
Рис.15 Пример таблицы реляционной модели данных
Набор отношений (таблиц) может быть использован для хранения данных об объектах реального мира и моделирования связей между ними. Ниже приведенная схема представляет термины реляционной модели. Схема отношения: СОТРУДНИКИ (Фамилия, Должность, Возраст). Число атрибутов - степень отношения, число кортежей - мощность отношения. Реляционная база данных - набор взаимосвязанных отношений. Каждое отношение (таблица) представляется в памяти компьютера в виде файла.
Существуют следующие соответствия понятий:
Оригинальность подхода Кодда состояла в том, что он предложил применять к отношениям стройную систему операций, позволяющих получать (выводить, вычислять подобно арифметическим операциям) одни отношения из других. Это дает возможность делить информацию на хранимую и нехранимую (вычисляемую) части, тем самым экономя память. Основных операций над отношениями насчитывается 8: - традиционные операции над множествами (объединение, пересечение, разность (вычитание), декартово произведение, деление); - специальные реляционные операции: проекция, соединение и выбор (селекция, ограничение). Языки для выполнения операций над отношениями делят на 2 класса: 1) языки реляционной алгебры, описывающие последовательность действий для получения желаемого результата; это процедурные языки. 2) языки реляционного исчисления, предоставляющие пользователю набор правил для записи “запросов” к базе данных, в которых содержится только информация о желаемом результате. Пример - языки запросов SQL (Structured Query Language). Реляционная база данных в целом соответствующая 3НФ, обладает рядом свойств, знание которых облегчает и упорядочивает процедуры обработки хранящейся в ней информации. Типичные процедуры, выполняемые с базой данных: выборка, корректировка и арифметические вычисления. Условия запросов второго типа могут комбинироваться с помощью логических операций И, ИЛИ, НЕ. Существуют правила реализации запросов к базе данных с помощью операторов реляционной алгебры: 1. В словесной формулировке запроса выделяются имена атрибутов, составляющие оболочку, вход и выход запроса, а такие условия выборки. 2. Зафиксировать множество атрибутов оболочки. Если все необходимые атрибуты находятся в одном отношении, то последующие операции выборки и проекции проводятся только с ним. Если они распределены по нескольким отношениям, то эти отношения необходимо соединить. Каждая пара отношений соединяется по условию равенства атрибутов с совпадающими именами (или определенных на общем домене). После каждого соединения с помощью проекции можно отсечь ненужные для последующих операций атрибуты. 3. Полученное единственное отношение далее обрабатывается операциями выборки и проекции. Выборка по значениям атрибута должна предшествовать проекции, в которой этот атрибут выводится из отношения. 4. Если запрос можно разделить на части (подзапросы), то его реализация также делится на части, где результатом подзапроса является отдельное отношение. 5. Указанная последовательность действий является стандартной, но, возможно, создает промежуточные отношения слишком большого размера. Этот недостаток можно компенсировать, выполняя некоторые выборки и проекции над исходными отношениями (до проведения соединения) и меняя взаимный порядок требуемых соединений.
Иерархическая модель данных
Структура данных называется иерархической, если ее схема представлена в виде дерева. Узлами дерева-схемы являются записи, дугами - иерархические связи между записями. Иерархическая связь предполагает, что одной «верхней» записи соответствует несколько реализаций «нижней», т.е. структура использует связи вида «один-ко-многим». Что представляет собой запись в иерархической структуре? Множество записей, относящихся к заданному узлу схемы, рассматриваемое вне связи с другими узлами, имеет сходство с нормализованным файлом и характеризуется уникальной совокупностью атрибутов. Совокупность иерархически организованных записей называется иерархической базой данных; отдельный тип записи, соответствующий узлу схемы, называется сегментом. Если два узла дерева соединены дугой, то узел более высокого уровня называется порождающим, а узел более низкого уровня - порожденным (или подчиненным). Всякий узел иерархической структуры (кроме корня дерева) имеет один порождающий узел. Ниже (см. рис.16) изображен пример схемы иерархической структуры.
Рис. 16. Пример иерархической модели данных По заданной иерархической схеме может быть построен файл в первой нормальной форме, иначе, иерархическая база данных может быть преобразована в один или несколько нормализованных файлов. Возможно обратное преобразование: построение иерархической базы данных по одному или совокупности нормализованных файлов. Для нормализации иерархического файла достаточно каждый узел дерева заменить нормализованным файлом со схемой, представляющей собой объединение атрибутов данного узла с ключами всех узлов, которые мы будем проходить при движении от данного узла по дугам в направлении снизу вверх. Результат операции объединения не изменится, если вместо ключей узлов будем писать дополнения до ключей (ключи только порожденных узлов без ключей порождающих).
Сетевая модель данных Рассмотрим табель учета рабочего времени
Таблица позволяет получать ответы на запросы двух типов: 1. По заданной фамилии сотрудника сообщить его рабочие часы на различные даты. 2. По заданной дате сообщить рабочие часы на эту дату для различных сотрудников. В нормализованном виде получим таблицу:
В составе нормализованного файла можно выделить СЕИ, которые располагаются то в ключе, то в результате запроса, и атрибут Q5, всегда относящийся к результату запроса. Запросы такого вида называются инверсными по отношению друг к другу, СЕИ S12 и S34 назовем инверсным условием поиска, атрибут Q5 - информацией связи. Этим запросам можно поставить в соответствие следующие иерархические структуры, изображенные на рис. 17.
Рис.17 В обоих случаях информация связи располагается в подчиненном сегменте. Структура, обеспечивающая ответы на запросы обоих типов, имеет вид, представленный на рис.18:
Рис.18 V-образная сетевая схема Такая структура называется V-образной сетевой схемой. Она содержит два порождающих сегмента и один подчиненный. Тип связей, соответствующий схеме - “один-ко-многим”. Подчиненный сегмент Q5 является информацией связи между S12 и S34.
Экземпляр рассматриваемой V-образной сетевой схемы называется сетевой БД. Его нормализованное представление - таблица ТАБЕЛЬ_1, а двухвходовое - ТАБЕЛЬ (двухвходовая таблица).
|
|||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-10; просмотров: 204; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.219.110.54 (0.012 с.) |



 Исходный документ не нормализован. В клетках указано количество рабочих часов данного сотрудника в данный день.
Исходный документ не нормализован. В клетках указано количество рабочих часов данного сотрудника в данный день.