Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Определение 11. Четвертая нормальная форма
Отношение R находится в четвертой нормальной форме (4NF) в том и только в том случае, если в случае существования многозначной зависимости A -> -> B все остальные атрибуты R функционально зависят от A.
В нашем примере можно произвести декомпозицию отношения ПРОЕКТЫ в два отношения ПРОЕКТЫ-СОТРУДНИКИ и ПРОЕКТЫ-ЗАДАНИЯ: ПРОЕКТЫ-СОТРУДНИКИ (ПРО_НОМЕР, ПРО_СОТР) ПРОЕКТЫ-ЗАДАНИЯ (ПРО_НОМЕР, ПРО_ЗАДАН) Оба эти отношения находятся в 4NF и свободны от отмеченных аномалий. Пятая нормальная форма Во всех рассмотренных до этого момента нормализациях производилась декомпозиция одного отношения в два. Иногда это сделать не удается, но возможна декомпозиция в большее число отношений, каждое из которых обладает лучшими свойствами. Рассмотрим, например, отношение СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ (СОТР_НОМЕР, ОТД_НОМЕР, ПРО_НОМЕР)
Предположим, что один и тот же сотрудник может работать в нескольких отделах и работать в каждом отделе над несколькими проектами. Первичным ключем этого отношения является полная совокупность его атрибутов, отсутствуют функциональные и многозначные зависимости. Поэтому отношение находится в 4NF. Однако в нем могут существовать аномалии, которые можно устранить путем декомпозиции в три отношения. Определение 12. Зависимость соединения Отношение R (X, Y,..., Z) удовлетворяет зависимости соединения * (X, Y,..., Z) в том и только в том случае, когда R восстанавливается без потерь путем соединения своих проекций на X, Y,..., Z. Определение 13. Пятая нормальная форма Отношение R находится в пятой нормальной форме (нормальной форме проекции-соединения - PJ/NF) в том и только в том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R.
Введем следующие имена составных атрибутов: СО = {СОТР_НОМЕР, ОТД_НОМЕР} СП = {СОТР_НОМЕР, ПРО_НОМЕР} ОП = {ОТД_НОМЕР, ПРО_НОМЕР}
Предположим, что в отношении СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ существует зависимость соединения: * (СО, СП, ОП)
На примерах легко показать, что при вставках и удалениях кортежей могут возникнуть проблемы. Их можно устранить путем декомпозиции исходного отношения в три новых отношения: СОТРУДНИКИ-ОТДЕЛЫ (СОТР_НОМЕР, ОТД_НОМЕР)
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР) ОТДЕЛЫ-ПРОЕКТЫ (ОТД_НОМЕР, ПРО_НОМЕР)
Пятая нормальная форма - это последняя нормальная форма, которую можно получить путем декомпозиции. Ее условия достаточно нетривиальны, и на практике 5NF не используется. Заметим, что зависимость соединения является обобщением как многозначной зависимости, так и функциональной зависимости.
Язык SQL Общие положения Стремительный рост популярности SQL является одной из самых важных тенденций в современной компьютерной промышленности. За два последних десятилетия SQL прошел эволюционный путь от небольшой коммерческой программы до компьютерного продукта, собирающего на рынке десятки миллиардов долларов в год, и стал единственным стандартным языком баз данных. На сегодняшний день SQL поддерживают свыше ста СУБД, работающих как на больших ЭВМ (мэйнфреймах), так и на персональных компьютерах. Был принят, а затем трижды дополнен официальный международный стандарт на SQL. Язык SQL является важным звеном в архитектуре систем управления базами данных, выпускаемых всеми ведущими поставщиками программных продуктов, и служит одним из стратегических направлений разработок компаний Microsoft, IBM и Oracle, трех крупнейших производителей программного обеспечения. Кроме того, SQL является открытым программным продуктом, что способствует росту популярности Linux и помогает в развитии движения за открытые программные средства. Зародившись в результате выполнения второстепенного исследовательского проекта компании IBM, SQL сегодня широко известен и в качестве важной компьютерной технологии, и в качестве мощного рыночного фактора. SQL является инструментом, предназначенным для выборки и обработки информации, содержащейся в компьютерной базе данных. SQL — это сокращенное название структурированного языка запросов (Structured Query Language). По историческим причинам аббревиатура SQL читается обычно как: «сиквел», но используется и альтернативное произношение «эскюэль». Как следует из названия, SQL является языком программирования, который применяется для организации взаимодействия пользователя с базой данных. На самом деле SQL работает только с базами данных одного определенного типа, называемыми реляционными.
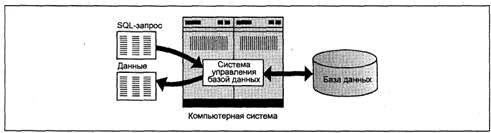
На рис. 6 изображена схема работы SQL. Согласно этой схеме, в вычислительной системе имеется база данных, в которой хранится важная информация. Компьютерная программа, которая управляет базой данных, называется системой управления базой данных, или СУБД. Если пользователю необходимо получить информацию из базы данных, он запрашивает ее у СУБД с помощью SQL. СУБД обрабатывает запрос, находит требуемые данные и посылает их пользователю. Процесс запрашивания данных и получения результата называется запросом к базе данных; отсюда и название — структурированный язык запросов.
Рис. 6. Использование SQL для доступа к базе данных Однако это название не совсем соответствует действительности. Во-первых, сегодня SQL представляет собой нечто большее, чем просто инструмент создания запросов, хотя именно для этого он и был первоначально разработан. Несмотря на то, что выборка данных по-прежнему остается одной из наиболее важных функций SQL, сейчас этот язык используется для реализации всех функциональных возможностей, которые СУБД предоставляет пользователю. К ним относятся: 1. Организация данных. SQL дает пользователю возможность определять структуру представления данных, а также устанавливать отношения между элементами базы данных. 2. Выборка данных. SQL дает пользователю или приложению возможность извлекать из базы данных содержащуюся в ней информацию и использовать ее. 3. Обработка данных. SQL дает пользователю или приложению возможность изменять базу данных, то есть добавлять в нее новые данные, а также удалять или обновлять уже имеющиеся. 4. Управление доступом. С помощью SQL можно ограничить возможности пользователя по выборке и изменению данных и защитить их от несанкционированного доступа. 5. Совместное использование данных. SQL координирует совместное использование данных пользователями, работающими параллельно, чтобы, они не мешали друг другу. 6. Целостность данных. SQL позволяет обеспечить целостность базы данных, защищая ее от разрушения из-за несогласованных изменений или отказа системы. Таким образом, SQL является достаточно мощным языком, обеспечивающим эффективное взаимодействие с СУБД. SQL — это слабо структурированный язык, особенно по сравнению с такими высокоструктурированными языками, как С++, Pascal или Java. Инструкции SQL напоминают английские предложения и содержат «слова-пустышки». не влияющие на смысл инструкции, но облегчающие ее чтение. В SQL почти нет нелогичностей и к тому же имеется ряд специальных правил, предотвращающих создание инструкций, которые выглядят как абсолютно правильные, но не имеют смысла. Несмотря на не совсем точное название, SQL на сегодняшний день является единственным стандартным языком для работы с реляционными базами данных. Сам по себе SQL не является ни системой управления базами данных, ни отдельным программным продуктом. Нельзя пойти в компьютерный магазин и «купить SQL». SQL — это неотъемлемая часть СУБД, инструмент, с помощью которого осуществляется связь пользователя с ней.
Стандарты SQL История SQL тесно связана с развитием реляционных баз данных. Понятие реляционной базы данных было введено доктором Э.Ф. Коддом, научным сотрудником компании IBM. В июне 1970 года доктор Кодд опубликовал в журнале Communications of the Association for Computing Machinery статью под названием «Реляционная модель для больших банков совместно используемых данных» («A Relational Model of Data for Large Shared Data Banks»), в которой в общих чертах была изложена математическая теория хранения данных в табличной форме и их обработки. От этой статьи ведут свое начало реляционные базы данных и SQL.
Одним из наиболее важных шагов на пути к признанию SQL на рынке стало появление стандартов этого языка. Обычно при упоминании стандарта SQL имеют в виду официальный стандарт, утвержденный Американским национальным институтом стандартов (American National Standards Institute — ANSI) и Международной организацией по стандартизации (International Standards Organization — ISO). Однако существуют и другие важные стандарты, включая стандарт де-факто, каковым является SQL, реализованный в СУБД DB2 компании IBM, и диалект SQL системы Oracle, доминирующей на рынке по количеству инсталляций программы. Работа над официальным стандартом SQL началась в 1982 году. Вначале обсуждались достоинства различных предложенных языков. Однако, поскольку к тому времени SQL уже стал фактическим стандартом, выбор был остановлен на нем и началась стандартизация SQL. Разработанный в результате стандарт в большой степени был основан на диалекте SQL системы DB2, хотя и содержал в себе ряд существенных отличий от этого диалекта. После нескольких доработок, в 1986 году стандарт был официально утвержден как стандарт ANSI номер Х3.135, а в 1987 году — в качестве стандарта ISO. Затем стандарт ANSI/ISO был принят правительством США как федеральный стандарт США в области обработки информации (FIPS — Federal Information Processing Standard). Этот стандарт, незначительно пересмотренный в 1989 году, обычно называют стандартом SQL-89 или SQL1. Многих из членов комитетов по стандартизации ANSI и ISO представляли фирмы-поставщики различных СУБД, в каждой из которых был реализован собственный диалект SQL. Как и диалекты человеческого языка, диалекты SQL были в основном похожи друг на друга, однако несовместимы в деталях. Во многих случаях комитет просто обошел существующие различия и не стандартизировал некоторые части языка, определив, что они реализуются по усмотрению разработчика. Этот подход позволил объявить большое число реализаций SQL совместимыми со стандартом, однако сделал сам стандарт относительно слабым.
Чтобы заполнить эти пробелы, комитет ANSI продолжил свою работу и создал проект нового, более жесткого стандарта SQL2. В отличие от стандарта 1989 года, проект SQL2 предусматривал возможности, выходящие за рамки таковых, уже реализованных в реальных коммерческих продуктах. А для следующего за ним стандарта SQL3 (1999 г.) были предложены еще более глубокие изменения. Кроме того, была предпринята попытка официально стандартизировать те части языка, на которые давно существовали «собственные» стандарты в различных СУБД. В результате предложенные стандарты SQL2 и SQL3 оказались более противоречивыми, чем исходный стандарт. Стандарт SQL2 прошел процесс утверждения в ANSI и был окончательно принят в октябре 1992 года. В то время как первый стандарт 1986 года занимает не более ста страниц, стандарт SQL2 (официально называемый SQL-92) содержит около шестисот. Существенным нововведением стало официальное закрепление трех уровней совместимости со стандартом SQL2. На самом нижнем, начальном уровне (Entry Level) от СУБД требуются лишь минимальные дополнительные возможности в сравнении со стандартом SQL-89. Промежуточный уровень (Intermediate Level) представляет собой значительный шаг вперед по отношению к стандарту SQL-89, хотя и не затрагивает наиболее сложных и системно-зависимых аспектов языка SQL. Третий, самый высокий уровень (Full Level) требует от СУБД реализации всех возможностей стандарта SQL2. В самом стандарте определение каждой возможности сопровождается описанием того, как она должна быть реализована на каждом из трех уровней. Вопреки стандарту SQL2, во всех существующих на сегодняшний день коммерческих СУБД поддерживаются собственные диалекты SQL, и ни один из них не реализует всех возможностей SQL2. Более того, поставщики СУБД включают в свои продукты новые возможности и расширяют собственные диалекты SQL, чем еще больше отдаляют их от стандарта. Однако ядро SQL стандартизировано довольно жестко. Там, где это можно было сделать, не ущемляя интересы клиентов, поставщики СУБД привели свои продукты в соответствие со стандартом SOL-89 и с наиболее полезными свойствами стандарта SQL2. Реальный стандарт языка SQL, конечно же, определяют диалекты SQL, реализованные в ведущих СУБД. Программисты и пользователи в основном сталкивается с теми частями языка, которые присутствуют во всех СУБД и реализованы примерно одинаково. Синтаксис языка SQL Инструкции В SQL существует несколько десятков (порядка 40) инструкция, каждая из которых указывает СУБД на выполнение определенного действия: SELECT, UPDATE, CREATE TABLE, DESCRIBE, REVOKE,.. Все инструкции SQL имеют одинаковую структуру. Каждая инструкция SQL начинается с команды, то есть ключевого слова, описывающего действие, выполняемое инструкцией. После команды идет одно или несколько предложений. Предложение описывает данные, с которыми работает инструкция, или содержит уточняющую информацию о действии, выполняемом инструкцией. Каждое предложение также начинается с ключевого слова, такого как WHERE, FROM, INTO, HAVING… Одни предложения в инструкции являются обязательными, а другие – нет.
Предложение может содержать имена таблиц, столбцов, константы, выражения, дополнительные ключевые слова. В стандарте ANSI/ISO определены ключевые слова, которые применяются в качестве команд и в предложениях инструкций. В соответствии со стандартом эти ключевые слова нельзя использовать для именования объектов базы данных, таких как таблицы, столбцы и пользователи. Во многих СУБД этот запрет ослаблен.
Имена Имя каждого объекта в базе данных есть уникальное имя. Имена используются в инструкциях SQL и указывают, над каким объектом базы данных инструкция должна выполнить действие. Основными именованными объектами в реляционной базе данных являются таблицы, столбцы и пользователи; правила их именования были определены еще в стандарте SQL1. В стандарте SQL2 этот список значительно расширен и включает схемы (коллекции таблиц), ограничения (ограничительные условия, накладываемые на содержимое таблиц и их отношения), домены (допустимые наборы значений, которые могут быть занесены в столбец) и ряд других объектов. Во многих СУБД существуют дополнительные виды именованных объектов, например хранимые процедуры (Sybase и SQL Server), отношения «первичный ключ — внешний ключ» (DB2), формы для ввода данных (Ingres) и схемы репликации данных. В соответствии со стандартом ANSI/ISO имена в SQL1 должны содержать от 1 до 18 символов, начинаться с буквы и не содержать пробелов или специальных символов пунктуации. В стандарте SQL2 максимальное число символов в имени увеличено до 128. На практике поддержка имен в различных СУБД реализована по-разному. В DB2, к примеру, имена пользователей не могут превышать 8 символов, но имена таблиц и столбцов могут быть более длинными. Зачастую более строгие ограничения налагаются на имена, связанные с программным обеспечением вне базы данных (например, имена пользователей, которые могут соответствовать регистрационным именам, использующимся операционной системой), и менее строгие — на имена, относящиеся к самой базе данных. Кроме того, в различных СУБД существуют разные подходы к использованию в именах таблиц специальных символов. Поэтому для повышения переносимости лучше делать имена сравнительно короткими и избегать употребления в них специальных символов. Имена таблиц Если в инструкции указано имя таблицы, СУБД предполагает, что происходит обращение к одной из ваших собственных таблиц. Обычно таблицам присваиваются короткие, но информативные имена. Большинство СУБД позволяют различным пользователям создавать таблицы с одинаковыми именами. Имея соответствующее разрешение, можно обращаться к таблицам, владельцами которых являются другие пользователи, с помощью полного имени таблицы. Оно состоит из имени владельца таблицы и собственно ее имени, разделенных точкой. Полное имя таблицы можно использовать вместо короткого имени во всех инструкциях SQL. Стандарт SQL2 еще больше обобщает понятие полного имени таблицы. Он разрешает создавать именованное множество таблиц, называемое схемой. Для доступа к таблице в схеме также применяется полное имя. Имена столбцов Если в инструкции задается имя столбца, СУБД сама определяет, в какой из указанных в этой же инструкции таблиц содержится данный столбец. Однако если в инструкцию требуется включить два столбца из различных таблиц, но с одинаковыми именами, необходимо указать полные имена столбцов, которые однозначно определяют их местонахождение. Полное имя столбца состоит из имени таблицы, содержащей столбец, и имени столбца (короткого имени), разделенных точкой. Если столбец находится в таблице, владельцем которой является другой пользователь, то в полном имени столбца следует указывать полное имя таблицы.
Типы данных В стандарте SQL1 был описан лишь минимальный набор типов данных, которые можно использовать для представления информации в реляционной базе данных. Они поддерживаются во всех коммерческих СУБД. Стандарт SQL2 добавил в этот список строки переменной длины, значения даты и времени и др. Современные СУБД позволяют обрабатывать данные самых разнообразных типов, среди которых наиболее распространенными являются: 1. Целые числа. 2. Десятичные числа. В столбцах данного типа хранятся числа, имеющие дробную часть, но которые необходимо вычислять точно, например курсы валют и проценты. Кроме того, в таких столбцах часто хранятся денежные величины. 3. Числа с плавающей запятой. Столбцы этого типа используются для хранения величин, которые можно вычислять приблизительно, например значения весов и расстояний. Числа с плавающей запятой могут представлять больший диапазон значений, чем десятичные числа, однако при вычислениях возможны погрешности округления. 4. Строки символов постоянной длины. 5. Строки символов переменной длины. Столбцы этого типа позволяют хранить строки символов, длина которых изменяется в некотором диапазоне. В стандарте SQL1 были определены только строки постоянной длины, которые проще обрабатывать, но они требуют больше места для хранения. 6. Денежные величины. Во многих СУБД поддерживается тип данных MONEY или CURRENCY, который обычно хранится в виде десятичного числа или числа с плавающей запятой. Наличие отдельного типа данных для представления денежных величин позволяет правильно форматировать их при выводе на экран. 7. Дата и время. Поддержка значений даты/времени также широко распространена в различных СУБД, хотя способы ее реализации довольно сильно отличаются друг от друга. Как правило, над значениями этого типа данных можно выполнять различные операции. Стандарт SQL2 включает определение типов данных DATE, TIME, TIMESTAMP и INTERVAL, а также поддержку часовых поясов и возможность указания точности представления времени (например, десятые или сотые доли секунды). 8. Булевы величины. Некоторые СУБД, например Informix Universal Server, явным образом поддерживают логические значения (TRUE или FALSE), а другие СУБД разрешают выполнять в инструкциях SQL логические операции (сравнение, логическое И/ИЛИ и др.) над данными. 9. Длинный текст. Многие СУБД поддерживают столбцы, в которых хранятся длинные текстовые строки (обычно длиной до 32000 или 65000 символов, а в некоторых случаях и больше). Это позволяет хранить в базе данных целые документы. Как правило, СУБД запрещает использовать эти столбцы в интерактивных запросах. 10. Неструктурированные потоки байтов. Современные СУБД позволяют хранить и извлекать неструктурированные потоки байтов переменной длины. Столбцы, имеющие этот тип данных, обычно используются для хранения графических и видеоизображений, исполняемых файлов и других неструктурированных данных. К примеру, тип данных IMAGE в SQL Server позволяет хранить потоки данных размером до 2 миллиардов байтов. 11. Нелатинские символы. В последнее время все больше поставщиков СУБД стали включать в свои продукты поддержку строк переменной и постоянной длины, содержащих символы азиатских и арабских алфавитов. Современные базы данных позволяют сохранять и извлекать такие символы, но степень поддержки их поиска и сортировки сильно отличается в различных СУБД. Различия в поддержке типов данных в разных СУБД существенно препятствуют переносимости приложений, в которых используется SQL. Причины подобных различий следует искать в самом пути, по которому развивались реляционные базы данных. Вот типичная схема: 1. Поставщик СУБД добавил в свой продукт поддержку нового типа данных, который обеспечивает новые полезные возможности для определенной группы пользователей. 2. Другой поставщик, оценив идею, ввел поддержку того же типа данных, но с небольшими модификациями, чтобы его нельзя было обвинить в слепом копировании. 3. Если идея оказалась удачной, то по прошествии нескольких лет рассматриваемый тип данных появляется в большинстве ведущих СУБД, став частью «джентльменского набора» базовых типов данных. 4. Далее этой идеей начинают интересоваться комитеты по стандартизации, чьей задачей является устранение произвольных различий в реализации идеи в ведущих СУБД. Но чем больше таких различий, тем труднее найти компромисс. Как правило, результатом деятельности комитета является вариант, который не соответствует ни одной из реализаций. 5. Поставщики СУБД начинают внедрять поддержку полученного стандартизированного типа данных, но поскольку они располагают обширной базой уже инсталлированных продуктов, то вынуждены сопровождать и старый вариант типа данных. По прошествии длительного периода времени (обычно включающего выпуск нескольких новых версий СУБД) пользователи, наконец, полностью переходят к использованию стандартного варианта рассматриваемого типа данных, и поставщик СУБД начинает процесс исключения поддержки старого варианта из своего продукта. Константы В стандарте ANSI/ISO определен формат числовых и строковых констант, или литералов, которые представляют конкретные значения данных. Этот формат используется в большинстве СУБД. Числовые константы Целые и десятичные константы (известные также под названием точных числовых литералов) в инструкциях SQL представляются в виде обычных десятичных чисел с необязательным знаком плюс (+) или минус (-) перед ними: 21 -375 2000.00 +497500.8778 В числовых константах нельзя ставить символы разделения разрядов между цифрами, и не все диалекты SQL разрешают ставить перед числом знак плюс, так что лучше избегать этого. В случае с данными, представляющими денежные величины, в большинстве СУБД просто используются целые или десятичные константы, хотя в некоторых из них можно перед константой указывать символ денежной единицы: $0.75 $5000.00 $-567.89 Константы с плавающей запятой (известные также под названием приблизительных числовых литералов) определяются с помощью символа Е и имеют такой же формат, как и в большинстве языков программирования. Ниже приведены примеры констант с плавающей запятой: 1.5Е3 -3.14159Е1 2.5Е-7 0.783926Е21 Символ Е читается как «умножить на десять в степени», так что первая константа представляет число «1,5 умножить на десять в степени 3», или 1500. Строковые константы В соответствии со стандартом ANSI/ISO строковые константы в SQL должны быть заключены в одинарные кавычки, как показано в следующих примерах: 'Jones, John J.' 'New York' 'Western' Если необходимо включить в строковую константу одинарную кавычку, вместе нее следует поставить две одинарные кавычки. Таким образом, следующая константа: 'I can''t' представляет строку I can't. В некоторых СУБД, например в SQL Server и Informix, строковые константы можно заключать в двойные кавычки: "Jones, John J." "New York" "Western" К сожалению, употребление двойных кавычек вызывает проблемы при переносе программ в другие СУБД. Константы даты и времени В реляционных СУБД значения даты, времени и интервалов времени представляются в виде строковых констант. Форматы этих констант в различных СУБД отличаются друг от друга. Кроме того, способы записи даты и времени меняются в зависимости от страны. СУБД DB2 поддерживает несколько различных международных форматов для записи даты/времени. Выбор формата осуществляется при инсталляции системы. Кроме того, в DB2 для представления интервалов времени используются специальные константы, как показано в следующем примере: HIRE_DATE + 30 DAYS Информацию о периоде времени нельзя сохранить в базе данных, поскольку в DB2 нет соответствующего типа данных. СУБД SQL Server также поддерживает различные форматы констант даты и времени. Ниже приведен ряд примеров констант даты, допустимых в SQL Server: March 15, 1990 Маг 15 1990 3/15/1990 3-15-90 1990 MAR 15 А вот примеры допустимых в этой СУБД констант времени: 15:30:25 3:30:25 РМ 3:30:25 рт 3 РМ Именованные константы Кроме пользовательских констант, в SQL существуют специальные именованное константы, возвращающие значения, хранимые в самой СУБД. Например, значение константы CURRENT_DATE, реализованной в ряде СУБД, всегда равно текущей дате. В стандарте SQL1 определена только одна именованная константа (константа -USER), но в большинстве СУБД их количество гораздо больше. В общем случае именованную константу можно применять в любом месте инструкции SQL, в котором разрешается применять обычную пользовательскую константу того же типа. В стандарт SQL2 вошли наиболее полезные именованные константы из СУБД, в частности константы CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP, а также USER, SESSION_USER и SYSTEM_USER. Выражения Выражения в SQL используются для выполнения операций над значениями, извлеченными из базы данных или используемыми для поиска в базе данных. В соответствии со стандартом ANSI/ISO в выражениях можно использовать четыре арифметические операции: сложение (X + Y), вычитание (X - Y), умножение (X * Y) и деление (X / Y). Для формирования сложных выражений можно использовать скобки. В соответствии со стандартом ANSI/ISO умножение и деление имеют более высокий приоритет, чем сложение и вычитание. В стандарте ANSI/ISO определено также, что преобразование целых чисел в десятичные и десятичных чисел в числа с плавающей запятой должно происходить автоматически. Таким образом, в одном выражении можно использовать числовые данные разных типов. Но чтобы сделать ваши выражения однозначными, скобки все же следует использовать, поскольку в диалектах SQL могут действовать различные правила. Кроме того, скобки делают инструкции более читабельными и упрощают их обработку. В большинстве СУБД допускается выполнение операций над датами и строками. Например, в СУБД DB2 реализован оператор конкатенации строк, записываемый в виде двух вертикальных черточек (||). СУБД DB2 также поддерживает операции сложения и вычитания значений типа DATE, TIME и TIMESTAMP, когда эти операции имеют смысл. Эта возможность включена и в стандарт SQL2. Встроенные функции Хотя встроенные функции не были определены в стандарте SQL1, в большинстве СУБД такие функции реализованы. Многие из них выполняют различные преобразования типов данных. Например, встроенные функции MONTH() и YEAR() из СУБД DB2 принимают в качестве аргумента значения DATE или TIMESTAMP и возвращают целое число, представляющее соответственно месяц или год из заданного аргумента. Кроме того, многие из встроенных функций выполняют форматирование данных. Например, встроенная функция TO_CHAR() из СУБД Oracle принимает в качестве аргументов значение типа DATE и спецификацию формата, а возвращает строку, содержащую значение даты, отформатированное в соответствии со спецификацией. Встроенную функцию разрешается использовать в любом месте инструкции SQL, в котором можно использовать константу того же типа данных. Здесь невозможно перечислить все встроенные функции, поддерживаемые распространенными диалектами SQL, поскольку их слишком много. В DB2 их порядка двух дюжин, в Oracle — столько же, в SQL Server — еще больше. В стандарт SQL2 вошли наиболее полезные функции из различных СУБД.
Инструкция SELECT Простые запросы Инструкция SELECT извлекает информацию из базы данных и возвращает ее в виде таблицы результатов запроса.
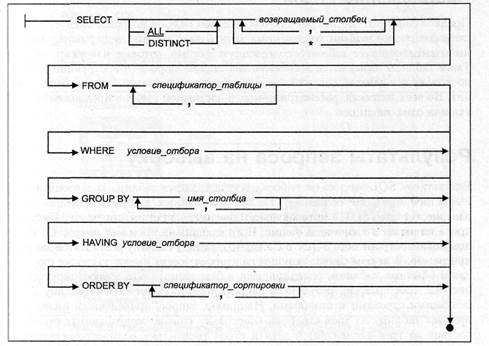
Инструкция SELECT является наиболее мощной из всех инструкций SQL. Она состоит из шести предложений. Обязательными являются предложения: SELECT FROM 1. В предложении SELECT указывается список столбцов, которые должны быть возвращены инструкцией SELECT. Возвращаемые столбцы могут содержать значения, извлекаемые из столбцов таблиц базы данных, или значения, вычисляемые во время выполнения запроса. 2. В предложении FROM указывается список таблиц, которые содержат элементы 3. Предложение WHERE показывает, что в результаты запроса следует включать 4. Предложение GROUP BY позволяет создать итоговый запрос. Обычный запрос 5. Предложение HAVING показывает, что в результаты запроса следует включать 6. Предложение ORDER BY сортирует результаты запроса на основании данных, содержащихся в одном или нескольких столбцах. Если это предложение не указано, результаты запроса не будут отсортированы. В предложении SELECT, с которого начинаются все инструкции SELECT, необходимо указать элементы данных, которые будут возвращены в результате запроса. Эти элементы задаются в виде списка возвращаемых столбцов, разделенных запятыми. Для каждого элемента из этого списка в таблице результатов запроса будет создан один столбец. Столбцы в таблице результатов будут расположены в том же порядке, что и элементы списка возвращаемых столбцов. Возвращаемый столбец может представлять собой:
Результатом SQL-запроса всегда является таблица, содержащая данные. В интерактивном SQL – результат выводится в виде таблицы на экран, в программном – передается в виде таблицы программе. То что запрос возвращается в виде таблицы очень важно. Это означает, что результаты запроса можно записать обратно в таблицу, что результаты двух запросов, имеющих похожую структуру можно объединить в одну таблицу и то, что результат одного запроса может быть предметом другого запроса. Рассмотрим таблицу абитуриентов, сдававших экзамен по математике exams. Наиболее простой запрос – запрос извлечения данных из одной таблицы: SELECT * FROM exams; +-------------+------+---------------+ | card_number | math | contest_value | +-------------+------+---------------+ | XXIV-001 | math | 4 | | XXIV-002 | math | 3 | | XXIV-003 | math | 3 | | XXIV-006 | math | 4 | | XXIV-007 | math | 5 | | XXIV-008 | math | 3 | | XXIV-010 | math | 3 | | XXIV-011 | math | 3 | | XXIV-014 | math | 3 | | XXIV-016 | math | 4 | | XXIV-017 | math | 4 | | XXIV-018 | math | 3 | | XXIV-019 | math | 3 | | XXIV-020 | math | 3 | | XXIV-021 | math | 5 | +-------------+------+---------------+ Инструкция SELECT для простых запросов содержит только два обязательных предложения: в предложении SELECT указывается имена требуемых столбцов, в предложении FROM - таблица, содержащая эти столбцы.. Вместо списка возвращаемых столбцов можно указать символ (*), указывающий на то, что необходимо вернуть все столбцы таблицы. Стандарт ANSI/ISO говорит, что одновременное использование символа (*) и имен столбцов в предложении SELECT запрещено. Однако во многих СУБД символ (*) считается одним из возвращаемых столбцов. select *, contest_value+1 from exams; +-------------+------+---------------+-----------------+ | card_number | math | contest_value | contest_value+1 | +-------------+------+---------------+-----------------+ | XXIV-001 | math | 4 | 5 | | XXIV-002 | math | 3 | 4 | | XXIV-003 | math | 3 | 4 | | XXIV-006 | math | 4 | 5 | | XXIV-007 | math | 5 | 6 | | XXIV-008 | math | 3 | 4 | | XXIV-010 | math | 3 | 4 | | XXIV-011 | math | 3 | 4 | | XXIV-014 | math | 3 | 4 | | XXIV-016 | math | 4 | 5 | | XXIV-017 | math | 4 | 5 | | XXIV-018 | math | 3 | 4 | | XXIV-019 | math | 3 | 4 | | XXIV-020 | math | 3 | 4 | | XXIV-021 | math | 5 | 6 | +-------------+------+---------------+-----------------+
Предикат DISTINCT указывает на то, что из результатов запроса надо удалить повторяющиеся строки. Противоположным значением является предикат ALL, но он используется по умолчанию.
Отбор строк. Условия отбора В SQL используется множество условий отбора, позволяющих эффективно и естественным образом создавать различные типы запросов. Ниже рассматриваются пять основных условий отбора (в стандарте ANSI/ISO они называются предикатами): 1. Сравнение. Значение одного выражения сравнивается со значением другого выражения. 2. Проверка на принадлежность диапазону. Проверяется, попадает ли указанное значение в определенный диапазон. 3. Проверка на членство в множестве. Проверяется, совпадает ли значение выражения с одним из значений заданного множества. 4. Проверка на соответствие шаблону. Проверяется, соответствует ли строковое значение, содержащееся в столбце, определенному шаблону. 5. Проверка на равенство значению NULL. Проверяется, содержится ли в столбце значение NULL. Сравнение Наиболее распространенным условием отбора в SQL является сравнение. При сравнении СУБД вычисляет и сравнивает значения двух выражений для каждой строки данных. Выражения могут быть как очень простыми, например, содержать одно имя столбца или константу, так и более сложными, например, содержат; арифметические операции. В SQL имеется шесть различных способов сравнения двух выражений.
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 117; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.179.186 (0.196 с.) |