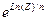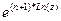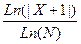Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Программирование на языках высокого уровняСодержание книги
Поиск на нашем сайте
Программирование на языках высокого уровня
1. ОСНОВНЫЕ ПОНЯТИЯ
1.1. Алфавит и словарь языка Программа формируется из предложений, состоящих из лексем и разделителей, которые в свою очередь формируются из конечного набора литер, образующих алфавит языка Pascal. Этот язык состоит из букв латинского алфавита (прописных – А, В, С, D... X, Y, Z, строчных – а, b, с... x, у, z), арабских цифр (0, 1, 2, 3,4, 5, 6, 7,8,9) и специальных символов. Использование строчных букв эквивалентно построению соответствующих конструкций из прописных букв и применяется для стилистического оформления программы. Иными словами, регистр при написании программ роли не играет. Разделителями являются: · пробел, · конец строки, ·; – точка с запятой (конец предложения) · комментарий, представляющий собой текст, ограниченный слева и справа фигурными скобками. Лексемы включают: зарезервированные слова, идентификаторы (стандартные и пользовательские), специальные символы (простые и составные), метки. Зарезервированные слова представляют собой составную часть языка, имеют фиксированное начертание и определенный смысл (например, зарезервированное слово VAR открывает раздел описания переменных). Стандартные идентификаторы служат для определения заранее зарезервированных идентификаторов предопределенных типов данных, констант, функций и процедур (например, стандартная функция ABS возвращает модуль своего аргумента). Идентификаторы пользователя применяются для обозначения констант, переменных, процедур и функций. Пользователь должен выбирать имя идентификатора отличное от зарезервированных слов и стандартных идентификаторов. Встроенные функции Наиболее часто встречающиеся операции над скалярными типами данных реализованы в языке Паскаль с помощью встроенных (иногда говорят — стандартных) функций и процедур. Наиболее известные функции над переменными целого, вещественного, логического и литерного типов приведены в таблицах 8 – 11. Таблица 8. Встроенные арифметические функции
В таблице 9 приведены примеры вычислений по функциям INT, ROUND, TRUNC пояснения особенностей их использования.
Таблица 9
Таблица 10. Встроенные логические (булевские) функции
Таблица 11. Встроенные функции над перечислимыми типами данных
1.4. Структура программы Программист вводит текст программы, произвольно располагая строки на экране. Отступ слева выбирает сам программист, чтобы программа была более читабельной. В одной строке допускается писать несколько операторов. Длинные операторы можно переносить на следующую строку. Перенос допускается в любом месте, где можно сделать пробел. Максимальная длина строки не должна превышать 127 символов. Из соображений наглядности, удобства просмотра и отладки программы рекомендуется длину строки ограничивать 80 символами. Программы имеют жесткую структуру, описанную в таблице 12. Таблица 12. Структура программы
Синтаксические правила построения предложений языка можно описывать следующими способами: • схемой (форматом предложения или раздела). В учебном процессе выбран именно этот способ, поскольку он наиболее понятен начинающему программисту; • синтаксической диаграммой. Этот способ детально формализует синтаксис предложения и используется разработчиками трансляторов с языка Паскаль; • порождающими правилами РАСШИРЕННЫХ БЭКУСА-НАУРА ФОРМ (РБНФ). Это весьма компактный и в то же самое время наглядный способ записи языковых конструкций. Этот способ используется в статьях и научных разработках. В данном курсе используются только пять элементов РБНФ (таблица 13). Таблица 13
Раздел описания модулей USES Раздел имеет структуру: USES Модуль 1, Модуль 2,... Модуль N, где за ключевым словом USES указывается список, в котором перечисляются все имена библиотек (модулей) стандартных и пользовательских, к процедурам и функциям которых есть обращение в программе. Если таких обращений нет, то раздел USES не нужен. Пример: USES CRT, GRAPH, HELP, MYLIB; В этом примере две стандартные библиотеки — CRT, GRAPH и две пользовательские библиотеки — HELP, MYLIB.
Раздел описания меток LABEL Раздел имеет структуру: LABEL Метка 1, Метка 2,Метка N, где за ключевым словом LABEL указывается список, в котором перечисляются все имена меток, встречающихся в программе. Пример: LABEL Ml, 12_BL, 9999; Метки позволяют менять естественный ход выполнения программы. Ссылка на метку осуществляется оператором GOTO <метка>. Если в программе меток нет, то раздел LABEL отсутствует. В теле программы (в разделе операторов) метка ставится перед требуемым оператором и отделяется от него двоеточием. Пример: М27: X:= А * В - С/2; Областью действия метки является блок, где она описана. Ниже приведена схема использования меток в тексте программы. BEGIN метка 1: <Оператор 1>; … метка 2: <Оператор 2>; … END. Раздел описания констант CONST Раздел существует, если в алгоритме используется по крайней мере одна константа, то есть величина, не изменяющая своего значения в процессе выполнения программы. Попытка изменить значение константы в теле программы будет обнаружена на этапе трансляции. В стандарте на Паскаль константы определяются следующим способом: CONST <Идентификатор 1> = <3начение 1>; <Идентификатор 2> = <3начение 2>; <Идентификатор N> = < Значение N>; CONST А = 15.7; BXZ = 'Серия N123/5'; MIN_IND = $15D; С_10 = -0.57Е-6; L125 = 695; FLAG = TRUE; Константа может иметь только предопределенный (стандартный) тип данных. Тип присваивается константе по внешнему виду значения и в соответствии с этим типом отводится память для хранения значения константы. В качестве расширения стандартного Паскаля разрешено использовать выражения, составленные из ранее определенных констант и некоторых стандартных функций (Abs, Chr, Hi, Length, Lo, Odd, Ord, Pred, Prt, Round, SizeOf, Succ, Swap, Trunc). Примеры использования константных выражений: CONST Min = 0; Max = 250; Centr = (Max-Min) div 2; Beta = Chr(225); NumChars = Ord('2') - Ord('A')+l; Message = 'не хватает памяти'; ErrStr = 'Ошибка:' + Message + '.'; Ln10 - 2.302585092994045884; Ln10R = 1/Ln10; Константные выражения вычисляются компилятором без выполнения программы на этапе ее создания.
Раздел описания типов TYPE Стандартные типы данных (REAL, INTEGER, BOOLEAN, CHAR) не требуют описаний в этом разделе. Описания требуют только типы, образованные пользователем. Концепция типов — одно из основных понятий в языке. С каждым данным связывается один и только один определенный тип. Тип — это множество значений + множество операций, которые можно выполнять над этими значениями, то есть правила манипулирования данными. Использование типов позволяет выявлять многочисленные ошибки, связанные с некорректным использованием значений или операций еще на этапе трансляции без выполнения программ. О Паскале говорят, что он строго типизирован, то есть программист должен описать все объекты, указывая их типы, и использовать в соответствии с объявленными типами. Программы становятся более надежными и качественными. При компиляции информация используется для уточнения вида операции. Так знаком + для данных типа REAL и INTEGER обозначается операция сложения, а для множеств (тип SET) — объединение. Структура раздела описания типов имеет вид: TYPE <имя типа 1> = <значение типа 1>; <имя типа 2> = <значение типа 2>; … <имя типа L> = <значение типа L>; Имя типа представляет собой идентификатор, который может употребляться в других типах, описанных вслед за данным типом. Раздел TYPE не является обязательным, так как тип можно описать и в разделе переменных VAR. Примеры описания пользовательских типов: TYPE DAY = 1..31; Year = 1900.. 2000; {Интервальный тип} LatBukv = ('А', 'С, 'D', 'G, 'Н'); {Перечисляемый тип} Matr = array[-1..12, 'А'.. 'F'] of real; {Регулярный тип}
Раздел описания переменных VAR Это обязательный раздел. Любая встречающаяся в программе переменная должна быть описана. В языке нет переменных, объявляемых по умолчанию. Основная цель этого раздела определить количество переменных в программе, какие у них имена (идентификаторы) и данные каких типов хранятся в этих переменных. Таким образом, переменная это черный ящик, а тип показывает, что мы в него можем положить. Структура раздела имеет вид: VAR <список 1 идентификаторов переменных>:<тип 1>; <список 2 идентификаторов переменных>:<тип 2>; … <список N идентификаторов переменных>:<тип N>; Тип переменных представляет собой имя (идентификатор), описанный в разделе TYPE при явном описании типа, или собственно описание типа в случае его неявного задания. Примеры описания переменных: TYPE DAY= 1..31; Matr = ARRAY[1..5,1..8] OF INTEGER; VAR A, B: DAY; X, Y: Matr; {явное описание типов } YEAR: 1900.. 2000; LES: (LPT, PRN); {неявное описание типов } А, В, CD, FER51: REAL; {описание переменных стан-} EQUAL: BOOLEAN; SH: CHAR; {дартных типов производится } I, J, К: INTEGER; {только в разделе VAR} Раздел описания процедур и функций Стандартные процедуры и функции, имена которых включены в список зарезервированных слов, в этом разделе не описываются. Описанию подлежат только процедуры и функции, определяемые пользователем. PROCEDURE <имя процедуры> (<параметры>); {заголовок процедуры} <разделы описаний> {тело процедуры } BEGIN <раздел операторов > END;
FUNCTION <имя функции>(<параметры>): <тип результата>; { заголовок } <разделы описаний > {тело функции} BEGIN <раздел операторов > END; Структура процедур и функций та же самая, что и у основной программы. Отличие описаний состоит в том, что идентификаторы констант, переменных, процедур и функций, описанных в соответствующих разделах описаний пользовательских процедур и функций, распространяются только на блоки, где они описаны и на блоки внутренние по отношению к ним. На внешние блоки, в том числе на тело основной программы, они не распространяются.
Раздел операторов Это основной раздел, именно в нем в соответствии с предварительным описанием переменных, констант, функций и процедур выполняются действия, позволяющие получать результаты, ради которых программа и писалась. Синтаксис раздела операторов основной программы: BEGIN <Оператор 1;> { Операторы выполняются} <Оператор 2;> { строго последовательно} … {друг за другом.} <Оператор N> END.
Комментарий Это пояснительный текст, который можно записать в любом месте программы, где разрешен пробел. Текст комментария ограничен: слева - '{', справа - '}', и может содержать любые символы. Комментарий игнорируется транслятором, и на программу влияния не оказывает. Пример использования комментария: PROGRAM PR; <Разделы описаний > BEGIN <Оператор 1; > <Оператор 2; > {< Оператор 3; > … <Оператор N > } END. Средства комментария часто используются для отладки. Так в приведенном выше примере, операторы — 3,... N, заключенные в фигурные скобки, временно не выполняются.
Правила пунктуации Основным средством пунктуации является символ точка с запятой – '; '. 1. Точка с запятой не ставится после слов LABEL, TYPE, CONST, VAR, а ставится 2. Точка с запятой не ставится после BEGIN и перед END, так как эти слова – операторные скобки. 3. Точка с запятой разделяет операторы, и ее отсутствие вызовет: А:= 333 {ошибка — нет ';'} В:= А/10;;;;; {четыре пустых оператора} 4. Возможна ситуация: END; следует писать END END; ------------------ > END END; END; 5. Допускается запись метки на пустом операторе — <Метка> :; 6. Точка с запятой не ставится после операторов WHILE, REPEAT, DO и перед UNTIL. 7. В условных операторах ';' не ставится после THEN и перед ELSE.
2. ПРОГРАММИРОВАНИЕ ВЫЧИСЛИТЕЛЬНЫХ ПРОЦЕССОВ
Решение задачи на ЭВМ — это сложный процесс, в ходе которого пользователю приходится выполнять целый ряд действий, прежде чем он получит интересующий его результат. Идеальная модель процесса решения задач на компьютере показана в таблице 14. Детальное рассмотрение этапов решения задачи на ЭВМ выходит за рамки данного курса. Напомним лишь некоторые существенные определения и понятия, которые будем использовать далее. Алгоритмизация — это процесс проектирования алгоритма, то есть выделение совокупности действий, используемых в математическом методе, и сведения их к совокупности действий, которые будет выполнять ЭВМ. Таблица 14
Алгоритм — совокупность точно описанных действий, приводящих от исходных данных к желаемому результату и удовлетворяющих следующим свойствам: • определенности — алгоритм должен однозначно, точно и понятно задавать выполняемые действия (для одних и тех же исходных данных должен получаться один и тот же результат); • дискретности — алгоритм должен представлять действие в виде последовательности составных частей; • результативности — алгоритм должен приводить к желаемому точному результату за конечное время; • массовости — алгоритм должен быть приемлем для решения всех задач определенного класса. Структурное проектирование — проектирование сверху вниз, это подход к разработке и реализации, который состоит в преобразовании алгоритма в такую последовательность все более конкретных алгоритмов, окончательный вариант которой представляет собой программу для вычислительной машины. Существуют различные способы записи алгоритмов (словесный, формульно-словесный, графический, аналитический). Каждый из способов имеет свои плюсы и минусы; В данном курсе в основном используется два способа графического представления алгоритма: блок-схема и структурограмма. Блок-схемы — это графическое представление алгоритма, дополняемое словесными записями. Каждый блок алгоритма отображается геометрической фигурой (блоком). Правила выполнения схем алгоритмов регламентируют ГОСТ 19.701-90. Графические фигуры соединяются линиями, потоками информации. Эти линии задают порядок переходов от блока к блоку. Блок-схемы наглядны для представления простых вычислительных алгоритмов и ориентированы для В ПАСКАЛЕ и ему подобных языках структурного программирования использовать блок-схемы в классическом виде стало неудобно. Это связано, во-первых, с громоздкостью алгоритма, реализованного в виде блок-схем, во-вторых, с нарушением основного принципа структурного проектирования программ сверху вниз. В соответствии с этим принципом рисуются укрупненные блоки алгоритма, которые потом уточняются. Этот процесс продолжается до тех пор, пока каждый алгоритмический блок не станет однозначно отражать одну или несколько языковых конструкций выбранного разработчиком языка программирования. Такие операторы
2.1. Линейные процессы вычислений Простейший алгоритм представляет собой цепочку блоков (операторов) от начального блока до конечного. Каждый блок должен быть выполнен один единственный раз. Это линейный алгоритм. Он отражает линейный вычислительный процесс. Основой линейных процессов является последовательность операторов, обеспечивающих ввод исходных данных, вычисление выражений, вывод результатов расчетов на экран или печать.
Операторы ввода (чтения) Ввод числовых данных, символов, строк и т.д. с клавиатуры обеспечивается операторами вызова стандартных процедур: READ(X1, Х2, ХЗ,...), или READLN(X1, Х2, ХЗ,...), где X1, Х2, ХЗ,... — идентификаторы скалярных переменных. Данные, соответствующие переменным X1, Х2, ХЗ, вводятся с клавиатуры и разделяются либо пробелом, либо Enter. После ввода последнего данного всегда нажимается клавиша Enter. Отличие оператора READLN от READ заключается в том, что после считывания последнего в списке X1 Х2, ХЗ,... значения данные для следующего оператора READLN будут считываться с начала новой строки. То есть, если список ввода X1, Х2, ХЗ,... оператора READLN меньше чем число набранных в одну строку через пробел чисел, то оставшиеся в строке числа будут проигнорированы. Оператор READ сохранит оставшиеся числа для дальнейшего ввода. Вводимые данные должны строго соответствовать типам переменных, описанных в разделе VAR, в противном случае будут возникать сообщения об ошибках ввода. Оператор READLN без параметров вызывает приостановление программы до момента нажатия клавиши Enter.
Операторы вывода (записи) Вывод числовых данных, символов, строк и булевских значений на экран дисплея осуществляется с помощью операторов вызова стандартных процедур: WRITE(X1, Х2, ХЗ,...), или WRITELN(X1, Х2, ХЗ,...). Отличие этих операторов состоит в том, что WRITELN после распечатки списка выражений XI, Х2, ХЗ,... автоматически переводит курсор в начало следующей строки, а после выполнения оператора WRITE курсор остается за последним символом, выведенным на экран. Оператор WRITELN с пустым списком выводимых данных выводит строку пробелов. Управление форматом выводимых данных осуществляется непосредственно в операторе вывода. Для этого используется запись элемента из списка { X i} в виде — X [: В [: С ]], где X — выражение, идентификатор переменной или константа, В – ширина поля для вывода данного X, С – точность (только для типа REAL). Точность представления определяет количество цифр после точки (дробная часть числа). Если указанная ширина поля оказывается 'слишком большой', то Пример 2. Описать формат вывода арифметического выражения X, численное значение которого |X|< 1000, с точностью до пяти знаков после десятичной точки. Решением этой задачи является оператор: WRITELN(X: 10: 5). На рисунке 1 показана схема формата Х:10:5.
Если задать формат в виде Х:8, то вещественное число будет представлено в формате с плавающей точкой и будет включать для своего представления восемь литер. Ограничение ширины поля скажется на разрядности мантиссы. Для вывода целой части X можно форматировать — Х:5:0. В этом случае 'точность' равна 0 и десятичная точка не отображается на экране. Дробная часть вещественного числа округляется с указанной точностью, а не отбрасывается. Таблица 15. Примеры форматов вещественных чисел
Оператор присваивания Вычисления в большинстве случаев реализуются с помощью оператора присваивания, который имеет формат: <Идентификатор> := <Выражение>; Оператор присваивания заменяет значение переменной, идентификатор которой стоит в левой части, на значение, задаваемое выражением в правой части. Выражение строится из операндов (переменных и констант), функций, операций и круглых скобок. Арифметические выражения используют арифметические операции: *, /, DIV, MOD, AND, OR, +, -. Операнды имеют тип REAL или INTEGER. Пример арифметического выражения: X:= (1 - В)*ЕХР(-0.5*А)/(1 - А). Список встроенных арифметических функций, наиболее часто используемых в программах на Паскале, приведен в таблице 8. Последовательность выполнения операции в выражении определяется их приоритетом. В первую очередь делаются операции умножения и деления (*, /), а в последнюю — сложения и вычитания (+, -) слева направо. Приоритетность арифметических операций:
1. Вычисления в круглых скобках; 2. Вычисления значений функции; 3. Унарные операции (NOT, унарный +, унарный -); 4. Арифметические операции 1 уровня (*, /, div, mod, and, shl, shr); 5. Арифметические операции 2 уровня (+, -, or, xor); 6. Операции отношения (=, <, >, <>, >=, <=, in);
В языке существуют ограничения на преобразование типов данных путем присваивания. Переменной А типа REAL можно присвоить значение переменной В типа INTEGER ==> А:= В. Однако обратное присвоение В:= А вызовет прерывание по причине несоответствия типов. Для этого случая предусмотрены функции преобразования типов TRUNC (A) или ROUND (A), то есть используется присвоение вида В:= TRUNC(A) или В:= ROUND(A).
Примеры линейных программ Пример 3. Рассчитать площадь шара в кв. см. Радиус шара ввести с клавиатуры в миллиметрах. PROGRAM PR3; {Программа вычисляет площадь поверхности шара} VAR PL: REAL; { PL - площадь шара} R: INTEGER; { R - радиус } BEGIN WRITELN('Введите радиус шара, мм'); READLN(R); PL:=4*PI*SQR(R)/100; WRITELN('Площадь шара =', PL:8:1, 'кв. см') END.
Пример 4. Осуществить расчеты по формуле:
где φ=arctg(b/a), ψ=arctg(d/c), c=n*a, d=m*b. Поскольку набор символов, используемых в идентификаторах переменных в программе (латиница), не включает традиционные для тригонометрии символы греческого алфавита α, β, φ, ψ, необходимо составить таблицу имен, которая установит соответствие между идентификаторами переменных и этими символами. В таблице имен мы также зафиксируем промежуточные (рабочие) переменные, упрощающие программирование исходной формулы:
Программирование линейных вычислительных процессов очень похоже на вычисления по формулам, которые математик осуществляет на бумаге. Алгоритм таких вычислений, как правило, не составляется в виде блок-схем. Наиболее удобной формой представления такого алгоритма является формульно-словесный способ, при котором действия пронумерованы пунктами 1, 2,3 и т.д. Каждое действие поясняется словами, формулами и расчетами. Алгоритм решения этой задачи описан формульно-словесным способом: 1. Ввод с клавиатуры параметров А, В, М, N, ALPHA, BETA. 2. Вычисление аргументов тригонометрических функций по формулам:
где AF и BP промежуточные рабочие переменные, которые в исходной формуле встречаются по два раза в числителе и знаменателе. Следует отметить, что аргументы встроенных функций Sin и Cos в Паскале должны задаваться в радианах. В исходной формуле подразумевается, что углы α, β, φ, ψ измеряются в радианах. Поэтому углы 15° и 75° градусов подлежат пересчету в радианы, что и сделано в приведенных выше формулах для расчета AF и BP. 3. Последовательное вычисление величин С, D, FI, PSI по формулам: C = n*a, D = m*b, FI = arctg(b/a), PSI = arctg(d/c). 4. Нахождение значений промежуточных переменных SQAB и SQCD по формулам:
5. Вычисление Y по упрощенной формуле за счет уже выполненных в предыдущих пунктах алгоритма расчетов.
6. Последним пунктом этого алгоритма является вывод найденного значения Y на экран монитора. PROGRAM PR4; VAR ALPHA, BETA, FI, PSI, SQAB, SQCD, AF, BP, А, В, C, D, N, M, Y: REAL; BEGIN WRITELN('Введите значения А, В, M, N'); READLN(A, В, M, N); WRITELN('Введите значения АЛЬФА, БЕТТА'); READLN(ALPHA, BETA); С:= N*A; D:= M*B; FI:= ARCTAN(B/A); PSI:= ARCTAN(D/C); AF:= ALPHA + FI + 15*PI/180; BP = BETA + PSI + 75*PI/180; SQAB:= SQRT(A*A + B*B); SQCD:= SQRT(C*C + D*D); Y:=ARCTAN((0.5*SQAB*SIN(AF)+SQCD*SIN(BP))/(SQAB*COS(AF) + SQCD*COS(BP))); WRITELN('Y =', Y:7:3) END. Следует выделить следующие типичные действия программиста при разработке программ такого класса (формализация линейного вычислительного процесса). 1. Формирование таблицы имен. На этом этапе подбираются латинские обозначения (идентификаторы) для отображения в программе математических величин, используемых в формулах. Для некоторых выражений, встречающихся в формулах два и более раза, можно ввести свои идентификаторы (временные переменные). Эти величины рассчитываются один раз перед основной формулой (формулами), что упрощает исходные формулы и ускоряет расчеты. 2. Учитывая последовательный принцип выполнения операторов в программе – друг за другом по мере их написания – необходимо установить порядок расчета формул. Основное требование состоит в том, чтобы при расчете формулы все переменные и параметры были ранее вычислены или введены с клавиатуры. Если формулы можно упростить путем алгебраических преобразований, то это нужно сделать до начала программирования. 3. Все математические величины нужно разбить на две группы: константы и переменные. Константы следует определить в разделе CONST программы, а переменные — в разделе VAR. 4. Проанализировав возможные значения переменных и требуемую точность расчетов, следует определить тип каждой переменной. 5. Требуется проанализировать все переменные из раздела VAR и определить, какие из них вводятся с клавиатуры, а какие вычисляются по ходу программы. 6. Если в тригонометрических функциях в качестве аргументов используются величины в градусах, то необходимо в программе сделать преобразование этих величин в радианы. 7. При выводе результатов расчетов на экран нужно выбрать формат, способ представления результатов (с плавающей или с фиксированной точкой) и задать точность (число значащих чисел).
Пример 5. Осуществить расчеты по формуле:
Для решения этой задачи следует использовать известные математические преобразования, которые приведут исходную формулу к виду, удобному для программирования. Эти преобразования описаны в следующей таблице:
PROGRAM PR5; VAR X, Y: REAL; N: INTEGER; BEGIN WRITELN('Введите значения X, N'); READLN(X, N); Y:= EXP(LN(ABS(EXP((N+1)*LN(X)) + LN(ABS(X+1))/LN(N)))/N); WRITELN(Y = ', Y:8:4) END.
Составной оператор Составной оператор предписывает выполнение составляющих его операторов в порядке их написания. Зарезервированные слова BEGIN и END являются операторными скобками. Формат оператора: BEGIN {Начало составного оператора} <Оператор 1;> < Оператор 2;> … < Оператор n> END; {Конец составного оператора} Составной оператор используется в тех конструкциях, где по синтаксису языка должен быть только один оператор, а для решения задачи требуется более одного. В составном операторе все операторы 1, 2,..., n выполняются последовательно ДРУГ за другом. Логические выражения Одним из нечисловых видов данных является тип BOOLEAN. Булевы (логические) переменные имеют только два значения: FALSE (ложь), TRUE (истина). Существует несколько форм конструирования логического выражения: • константа, описанная в разделе CONST; • переменная, которой можно присвоить булевы значения (например FLAG:= TRUE); • отношение между переменными скалярных и некоторых структурированных В Паскале допускаются отношения, перечисленные в таблице 16
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 160; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.167.85 (0.011 с.) |

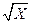
 Цифра 10 определяет ширину поля, то есть общее количество литер, отведенное для отображения вещественного числа вместе со знаком и десятичной точкой. Цифра 5 – точность - указывает количество цифр мантиссы. В этом примере результат вычисления X выводится на экран дисплея в форме вещественного числа с
Цифра 10 определяет ширину поля, то есть общее количество литер, отведенное для отображения вещественного числа вместе со знаком и десятичной точкой. Цифра 5 – точность - указывает количество цифр мантиссы. В этом примере результат вычисления X выводится на экран дисплея в форме вещественного числа с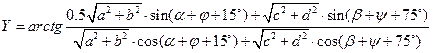 ,
,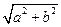

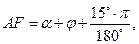
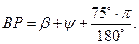
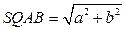 ,
, 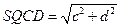
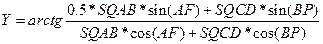
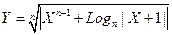
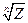 , Z>0
, Z>0