
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема 1. 1. Основні поняття баз данихСтр 1 из 15Следующая ⇒
Методичний посібник Теоретичного матеріалу З курсу «Бази даних» для студентів спеціальності «Розробка програмного забезпечення» Розробив викладач: Пожар Н. А. Вступ Від початку розвитку обчислювальної техніки сформувалися два основні напрями її використання. Перший напрям — застосування комп'ютерів для виконання обчислень, які дуже складно або неможливо здійснювати вручну. Становлення цього напряму сприяло інтенсифікації методів чисельного розв'язання складних математичних задач і розвитку мов програмування, які орієнтовані на зручний запис чисельних алгоритмів. Другий напрям — це використання засобів обчислювальної техніки в системах обробки даних та автоматизованих інформаційних системах. У широкому розумінні інформаційна система є програмним комплексом, функції якого полягають у забезпеченні надійного зберігання даних у пам'яті комп'ютера, виконанні специфічних для певного програмного застосування перетворень інформації та/або обчислень, наданні користувачам зручного й легкого в освоєнні інтерфейсу. Зазвичай обсяги інформації, з якими працюють такі системи, досить великі, а самі вони мають складну структуру. Класичними прикладами інформаційних систем є банківські, системи резервування авіаційних або залізничних квитків, місць у готелях тощо. Другий напрям виник пізніше за перший, що було пов'язано з обмеженими можливостями комп'ютерів у галузі зберігання даних на зовнішніх носіях. Системи керування даними в зовнішній пам'яті з'явилися лише після винайдення магнітних дисків. До цього прикладні програми самі визначали розташування даних на магнітній стрічці чи барабані й здійснювали обмін інформацією між оперативною та зовнішньою пам'яттю за допомогою програмно-апаратних засобів низького рівня (машинних команд або викликів відповідних програм операційної системи). Такий спосіб роботи не дозволяв або дуже ускладнював підтримку на одному зовнішньому носії кількох архівів інформації, якщо вони мали зберігатися тривалий час. Крім того, для кожної прикладної програми доводилося вирішувати проблеми іменування частин даних та їхньої структуризації в зовнішній пам'яті.
Кроком уперед був перехід до використання централізованих систем керування файлами. Для прикладної програми файл — це іменована область зовнішньої пам'яті, куди можна записувати й звідки можна зчитувати дані. Правила іменування файлів, спосіб доступу до даних, що в них зберігаються, та структура цих даних залежать зазвичай від конкретної системи керування файлами, інколи — від типу файла. Система керування файлами, або файлова система (ФС), яку ще називають файловою підсистемою операційної системи, виконує функції розподілу зовнішньої пам'яті, відображення імен файлів на відповідні адреси пам'яті та забезпечення доступу до даних. Файлова система має низку особливостей, які значно обмежують її безпосереднє застосування у зберіганні й обробці великих обсягів складноструктурованих даних, призначених для колективного використання. Розглянемо найістотніші з них. Завдяки використанню файлової системи встановлюється тісний зв'язок між фізичними даними і прикладною програмою. Файл створюється програмою. Окрім логіки прикладної задачі, програма реалізує логіку зображення даних, інтерпретує відповідні операції, переводить їх у примітивні файлові операції, обробляє файли, що містять дані. Отже, дані залежать від програми. Кожний файл існує для забезпечення інформаційних потреб програми. Дані у файлах, як правило, не пов'язуються між собою, тобто відсутня інтеграція даних, що призводить до дублювання даних у різних файлах і, можливо, до суперечності стану системи. У файлових системах відсутня динаміка, оскільки прикладні програми розробляються для виконання наперед відомих запитів і завдань. Вони не можуть виконати нетипові запити, які зазвичай вимагають отримання відповіді в режимі реального часу. Як правило, дані з одних і тих самих файлів не можна спільно використовувати, оскільки подібна практика може призвести до некоректного змінення даних. Дані у файлах використовуються неефективно. Це є прямим наслідком того, що файли й дані, які в них містяться, створюються і обробляються для задоволення інформаційних потреб конкретних програм, а не для адекватного відображення усієї предметної області.
Саме для подолання обмежень, пов'язаних із використанням файлових систем, і були розроблені системи баз даних. Розділ 1. Системи баз даних Основні характеристики СУБД § Контроль за надлишковістю даних § Непротирічність даних § Підтримка цілісності бази даних (коректність та непротирічність) § Цілісність описується за допомогою обмежень § Незалежність прикладних програм від даних § Спільне використання даних § Підвищений рівень безпеки Можливості СУБД § Дозволяється створювати БД (здійснюється за допомогою мови визначення даних DDL (Data Definition Language)) § Дозволяється додавання, оновлення, видалення та читання інформації з БД (за допомогою мови маніпулювання даними DML, яку часто називають мовою запитів) § Можна надавати контрольований доступ до БД за допомогою: 1. Системи забезпечення захисту, яка запобігає несанкціонованому доступу до БД; 2. Системи керування паралельною роботою прикладних програм, яка контролює процеси спільного доступу до БД; 3. Система відновлення - дозволяє відновлювати БД до попереднього непротирічного стану, що був порушений в результаті збою апаратного або програмного забезпечення Історія розвитку баз даних Історію розвитку баз даних можна поділити на чотири періоди. Рис 1. Трирівнева архітектура СКБД Концептуальний рівень На концептуальному рівні здійснюється інтегрований опис предметної області, для якої розробляється БД, незалежно від її сприйняття окремими користувачами та способів реалізації в комп'ютерній системі. Дамо означення основних понять, що використовуються на концептуальному рівні. Предметна область (ПО) — частина реального світу, для якої здійснюється концептуальне моделювання. Концептуальна модель ПО — формальне зображення сукупності думок, які характеризують можливі стани ПО, а також переходи з одного стану в інший (включно з класифікацією наявних у ПО сутностей, чинних правил, законів, обмежень тощо). Концептуальне моделювання ПО — процес побудови концептуальної моделі ПО, яка б відображувала ПО з урахуванням вимог, висунутих до цього процесу. Концептуальна схема — фіксація концептуальної моделі ПО засобами конкретних мов моделей даних. У СКБД концептуальна модель подається у вигляді концептуальної схеми. Опишемо властивості концептуальної моделі (схеми) й характерні особливості концептуального моделювання. ♦ Спільне та однозначне тлумачення предметної області всіма зацікавленими особами. До розробки складної бази даних залучається великий колектив: експерти, системні аналітики, проектувальники, розробники, ті, хто займається впровадженням і супроводом. Усі вони повинні однозначно розуміти, чим є ПО, в чому зміст використаних понять, як вони взаємопов'язані між собою, які обмеження висуваються до моделі ПО тощо. Спільність понять має забезпечувати концептуальна модель. ♦ Концептуальна схема відображує лише концептуально важливі аспекти ПО, виключаючи будь-які аспекти зовнішнього або внутрішнього відображення даних. Ця модель не повинна відображувати конкретні потреби окремих користувачів або застосувань. Вона має фіксувати, чим є ПО в цілому, а не з точки зору інтересів або потреб користувачів. Для отримання цілісного уявлення про ПО її модель має інтегрувати думки, погляди та інтереси окремих користувачів, але саме інтегрувати, а не виражати їхні конкретні побажання.
♦ Визначення допустимих меж еволюції бази даних. У процесі експлуатації база даних може розвиватися, проте цей розвиток може відбуватися тільки в межах, допустимих для концептуальної схеми. ♦ Відображення зовнішніх схем на внутрішню. Саме через концептуальну схему зовнішні дані відображуються на внутрішні, й навпаки. У такий спосіб створюється єдина основа для опису даних і підтримки цих відображень. ♦ Забезпечення незалежності даних. Наявність відображень концептуальний-зовнішній і концептуальний-внутрішній дає змогу вирішувати проблему логічної та фізичної незалежності даних. Будь-які зміни в тій чи іншій зовнішній моделі не повинні спричиняти зміни в концептуальній або внутрішній моделях. У цьому випадку має змінитися тільки відповідне відображення «концептуальний-зовнішній». Аналогічно, будь-які зміни у внутрішній моделі не зачіпають концептуальну модель і моделі зовнішнього рівня, а тільки приводять до змін відображення «концептуальний-внутрішній». ♦ Централізоване адміністрування. Саме через концептуальну схему здійснюється адміністрування баз даних. ♦ Стійкість. Концептуальна схема не має підладжуватися до вимог тих чи інших користувачів (зовнішній рівень) або до вимог зберігання даних (внутрішній рівень). Будучи моделлю ПО, вона має змінюватися тільки тоді, коли входить у суперечність із нею. Існує багато мов, які претендують на роль мов концептуального моделювання ПО. Найпопулярнішими і широковживаними є мови, що належать до класу так званих графічних мов, які оперують поняттями «сутність-атрибут-зв'язок» (Entity-Relationship language). Зовнішній рівень Через зовнішній рівень користувачі та застосування отримують доступ до бази даних. Мета зовнішнього рівня — надати користувачу/застосуванню лише ті дані, які йому потрібні (а отже, до яких дозволений доступ) і в потрібному вигляді. Це індивідуальний рівень користувача, яким може бути кінцевий користувач, програміст чи застосування. Кожен з них має свою мову спілкування: для кінцевого користувача — це спеціальна мова запитів, для програміста - одна з мов програмування, розширена командами звернення до СКБД, для застосувань — це, як правило, певний стандартний інтерфейс звернення до бази даних через СКБД.
Зовнішня модель — це засоби зображення концептуальної моделі ПО з урахуванням інтересів конкретних користувачів або застосувань. Кожна зовнішня модель подається в СКБД у вигляді зовнішньої схеми. Зовнішній рівень виконує такі функції. ♦ Забезпечує зображення даних зручним для людини або застосування способом. Ступінь незалежності зовнішнього зображення від концептуального рівня визначається потужністю засобів опису відображення «концептуальний-зовнішній». ♦ Сприяє вирішенню проблеми безпеки (захисту) даних. Надаючи користувачу лише ті дані, що його цікавлять, ми залишаємо поза межами його доступу решту даних. ♦ Сприяє вирішенню проблеми логічної незалежності даних. Це досягається завдяки відображенню «концептуальний-зовнішній», що встановлює відповідність між концептуальною схемою і конкретною зовнішньою схемою. Потужність його засобів визначає ступінь логічної незалежності застосувань від даних. Внутрішній рівень Внутрішня модель є відображенням концептуальної моделі ПО з урахуванням способів зберігання даних і методів доступу до них. Внутрішня модель відображується в СКБД у вигляді внутрішньої схеми. Внутрішня модель — це не модель фізичної пам'яті з характеристиками конкретних пристроїв зберігання даних (циліндри, доріжки тощо); вона описується у вигляді нескінченної абстрактної лінійної пам'яті, яка може структуруватися за допомогою інших абстрактних понять на зразок блоків, кластерів, індексів тощо. Доступ до фізичної пам'яті надається за допомогою опису відображень внутрішньої моделі на фізичну пам'ять операційної системи. Загалом внутрішній рівень виконує такі функції. ♦ Забезпечує настроювання бази даних для підвищення продуктивності обробки даних, опису й підтримки планованої надлишковості. ♦ Дає змогу описувати й підтримувати структури зберігання та методи доступу. ♦ Сприяє вирішенню проблеми фізичної незалежності даних: зміни у внутрішній схемі не повинні призводити до змін у зовнішній схемі. ♦ Сприяє вирішенню проблеми безпеки (захисту) даних. ♦ Вирішує проблему відображення даних на структури ОС, у яких дані зберігаються (до таких структур належать зокрема файли). Відображення зовнішнього рівня на концептуальний і концептуального рівня на внутрішній показані на рис. 1. Відображення «зовнішній-концептуальний» визначає відповідність між зовнішнім рівнем і концептуальним. Незалежність зовнішньої схеми, відтак і ступінь логічної незалежності даних, обумовлюються потужністю засобів опису цих відображень. Тобто можна описувати або змінювати зовнішню схему тільки в тих межах, які допускає це відображення. Подібне можна сказати і про відображення «концептуальний-внутрішній», яке встановлює відповідність між концептуальною і внутрішньою моделями. Потужність його засобів визначає ступінь фізичної незалежності застосувань від даних. Будь-які зміни у фізичній структурі не повинні призводити до змін у концептуальній моделі — змінюється лише відображення «концептуальний-внутрішній».
За створення і ведення схем усіх рівнів (концептуальної, зовнішньої і внутрішньої), а також відображень відповідає адміністратор бази даних. Розділ 2. Моделі даних Тема 2.1. Поняття про моделювання даних Дані та їхня семантика Слово «дані» походить від латинського «datum» — факт, проте дані не завжди відповідають конкретним чи навіть реальним фактам. Іноді вони неточні або описують те, чого насправді не існує. Даними ми вважатимемо опис будь-якого явища (чи ідеї), що викликає зацікавленість через певні потреби. З даними нерозривно пов'язана їхня інтерпретація (або семантика), тобто той зміст, який їм приписується. Дані описуються тією чи іншою мовою і фіксуються на певному носії (скажімо, папері). Зазвичай дані (факти) та їхня семантична інтерпретація фіксуються спільно. Проте в деяких випадках дані й інтерпретація розділяються. Так, у зведеній статистичній таблиці зверху, в її шапці, міститься інформація стосовно того, чим є дані (заголовок таблиці, описова інформація, назви стовпців тощо), а нижче розташовуються власне рядки чисел. Застосування комп'ютерів для введення й обробки даних сприяло ще більшому розділенню даних та їхньої інтерпретації. Оскільки комп'ютери оперують даними як такими, велика частина інтерпретуючої інформації взагалі явно не фіксується. Програма одержує певні вхідні дані, обробляє їх і видає результат у вигляді сукупності вихідних даних. З розвитком обчислювальної техніки з'явилася можливість фіксувати за допомогою комп'ютерів семантику даних, тобто закладати інтерпретацію в програми, що оперують даними. Проте за умов спільного використання даних різноманітними прикладними програмами цей підхід можна застосовувати лише частково. Інакше процес написання програм, які містять схожі, хоча й не ідентичні механізми інтерпретації, стає неефективним. У подібній ситуації доцільно зв'язувати дані з механізмами інтерпретації, що має забезпечувати уніфікованість подання семантичної інформації. У результаті змінюється роль даних: їх уже не можна розглядати лише як сукупність бітів, вони отримують певне семантичне навантаження. Засоби інтерпретації мають бути гнучкими, аби разом з незмінними параметрами даних відображувати й аспекти їхньої еволюції. Цього досягають двома способами. По-перше, можна відтворювати різні погляди на одні й ті самі дані. Наприклад, розглядати певну особу з точки зору кадрової системи як службовця, з погляду виробничих інтересів — як виконавця робіт, а з боку медичного обслуговування — як пацієнта. По-друге, різні дані можна подавати одноманітно. Так, адміністратори, клерки, агенти, секретарі незалежно від роду своєї діяльності можуть розглядатися в кадровій системі як службовці. Моделювання даних Існує багато типів моделей — фізичні, математичні, економічні тощо, які відображують різні аспекти реального світу. Модель даних відображує уявлення про реальний світ. Проте важливо, аби обсяг знань і семантика даних, відтворені в моделі, були адекватні способу використання даних. Вважатимемо, що модель даних — це сукупність структури даних, операцій над ними (операції маніпулювання даними) та обмежень цілісності. Іншими словами, модель визначає, в який спосіб відбувається об'єднання даних у структури різної складності, які існують обмеження на значення даних і як здійснюється оперування цими даними. Основою для будь-якої структури даних є відображення елементарної одиниці даних у вигляді такої трійки: <об'єкт, властивість об'єкта, значення властивості Сукупність взаємопов'язаних між собою елементарних одиниць даних може відображуватися різноманітними способами, що приводить до формування різних структур, а відтак — різних моделей даних. Моделі даних поділяються на два класи: сильно та слабко типізовані. У сильно типізованих моделях усі дані мають належати до певної категорії, або типу. Якщо дані не підпадають під жодну з категорій, їх потрібно типізувати штучно. Деякі моделі будуються у такий спосіб, що категорії визначаються наперед і не можуть змінюватися динамічно. У цьому випадку модельований світ начебто вміщується в гамівну сорочку. Наприклад, категорія «службовець» — строго фіксована, й усі її об'єкти повинні мати однакові властивості та структуру. Сильно типізовані моделі мають значні переваги, бо дають змогу побудувати абстракції властивостей даних і дослідити їх у термінах категорій. Більшість моделей, що використовуються в автоматизованих системах, зокрема й базах даних, належать до сильно типізованих. (Це стосується й усіх моделей даних, що розглядаються далі.) Для слабко типізованих моделей належність даних до тієї чи іншої категорії не має жодного значення. Категорії використовуються настільки, наскільки це доцільно в кожному конкретному випадку. Окремі дані можуть існувати як незалежно, так і у зв'язку з іншими. Інформація про категорії (якщо вони використовуються) розглядається як додаткова. На відміну від сильно типізованих моделей, слабко типізовані забезпечують інтеграцію даних і категорій. Найкращі можливості такої інтеграції надаються численням предикатів, яке у багатьох моделях даних використовується для зображення знань, що не підтримуються базовими засобами моделювання. Відомі три класичні моделі баз даних: ієрархічна, мережна та реляційна. Ієрархічна структура даних Ієрархічна структура даних визначається ієрархічною впорядкованістю своїх компонентів (або вузлів), тобто кожен вузол має не більше одного «батька» — старшого за ієрархією вузла. Структура складається зі схем елементів даних (описова інформація) та їхніх екземплярів. Інакше кажучи, схема задає логічну структуру (або тип) елементу даних, а екземпляр — його значення. Елементарним значенням структури є пойменоване поле даних, а його екземпляр — це елементарне значення. Схема сегмента (яку називатимемо також просто сегментом) — це пойменована впорядкована сукупність імен полів. Сегмент є одиницею доступу до даних ієрархічної структури під час взаємодії зовнішньої та оперативної пам'яті. Екземпляр сегмента — впорядкована сукупність значень полів. Ієрархічна схема даних — це ієрархічно впорядкована сукупність сегментів, що має певні властивості: ♦ на найвищому рівні ієрархії розташований єдиний сегмент, що називається кореневим) ♦ кожен інший сегмент, окрім кореневого, зв'язаний з одним і тільки одним сегментом вищого рівня, який є для цього сегмента батьківським (початковим); ♦ сегмент може бути зв'язаний з одним або кількома сегментами нижчого рівня, які називаються дочірніми (породженими); ♦ сегменти, що підпорядковані одному батьківському сегменту, називаються близнюками; ♦ сегменти, що не мають дочірніх, вважаються листковими, або їх ще називають листками. Ієрархічний шлях (або просто шлях) — це послідовність сегментів, починаючи з кореневого, де кожний попередній є «батьком» наступного. Рівень сегмента визначається як кількість сегментів, що містяться на шляху, який веде від кореня до даного сегмента. Для ієрархічної схеми використовується така графічна нотація. ♦ Кожний сегмент зображується у вигляді пойменованого прямокутника. Усередині прямокутника записуються імена полів. ♦ Приклад графічного зображення простої ієрархічної схеми даних наведений на рис. 2 а. Якщо немає необхідності уточнювати сегменти полями, що зазвичай робиться під час загального аналізу ієрархічної структури предметної області, то в прямокутнику сегмента зазначається його ім'я (рис. 2 б ). а б Рис 2. Графічне зображення схеми ієрархічної структури даних: з уточненням (а); без уточнень (б) Екземпляр ієрархічної схеми даних складається з одного екземпляра кореневого сегмента і, можливо, кількох екземплярів дочірніх сегментів для кожного екземпляра батьківського сегмента. Припускається існування таких зв'язків між екземплярами сегментів: ♦ кожний екземпляр будь-якого сегмента підпорядкований одному екземпляру батьківського сегмента; ♦ ♦ кожний екземпляр сегмента зв'язаний (підпорядковує собі) з усіма екземплярами дочірніх сегментів; ♦ екземпляри одного сегмента, зв'язані з одним екземпляром батьківського сегмента, можуть бути зв'язані між собою в ланцюжок, що дає змогу виконувати їхнє послідовне перебирання у межах усіх сегментів, породжених з одного початкового.
Ієрархічна схема інколи має розгалуження, як це показано на рис. 2.3. У подібному випадку на рівні схеми батьківський сегмент може зв'язуватися з кількома дочірніми сегментами. Ієрархічна структура даних — це сукупність ієрархічної схеми даних та всіх можливих екземплярів цієї схеми. Сукупність ієрархічних структур даних називається ієрархічною базою даних. Вибирання даних Необхідний екземпляр сегмента вибирається в ієрархічній структурі за допомогою команди «навігації» структурою. Екземпляр сегмента є одиницею навігації. Для визначення необхідного сегмента навігації може накладатися умова на значення полів сегмента. Відносно поточного сегмента можна переміщуватися ієрархічною структурою вверх, вниз і вбік. Навігацію ієрархічною структурою можна здійснювати з метою її впорядкування, а потім переміщуватися нею згідно зі встановленим порядком. Порядок переміщення встановлюється, починаючи з кореня або будь-якого первинного сегмента. Далі рухатись можна зверху донизу і зліва направо. Мережна структура даних Мережна структура даних є сукупністю схеми та екземпляра схеми. У свою чергу мережна схема формується з полів даних, типів записів і наборів, які також мають свої екземпляри. Власне з екземплярів полів, записів та наборів складається екземпляр схеми. Елементарною одиницею даних мережної (так само, як ієрархічної) структури є пойменоване поле даних. Тип запису — це пойменована впорядкована сукупність імен полів. Екземпляр запису (аналог сегмента в ієрархічній структурі даних) — це впорядкована сукупність значень полів запису. Екземпляр запису є одиницею доступу до даних мережної структури.
Тип запису КАФЕДРА (рис. 2.4, а) є власником типу набору, а типи ДИСЦИПЛІНА і ВИКЛАДАЧ - члени типу набору. На рис. 2.4, б зображений екземпляр цього типу набору. Він містить один екземпляр типу запису КАФЕДРА і декілька типів записів ДИСЦИПЛІНА та ВИКЛАДАЧ.
Для отримання багаторівневої ієрархії потрібно більше одного набору. Тип запису, що є власником на нижньому рівні ієрархії, має бути також оголошений членом типу набору вищого рівня.
Для опису будь-якої n -рівневої ієрархії потрібно принаймні п- 1 наборів. Один тип запису може мати кілька батьківських записів, якщо вони є власниками різних типів наборів, тобто запис може бути членом багатьох наборів і мати декілька записів-власників. Так формуються мережні структури. Приклад схеми мережної структури даних, що складається з п'яти типів наборів даних, наведений на рис. 2.6. Мережну структуру формують набори Прослуховує, Читається і Читає, а тип запису ЛЕКЦІЯ є їхнім членом. Отже, одні й ті самі типи записів можуть бути зв'язані в різні набори.
Зв'язок згаданого типу моделюється введенням нового типу запису ЛЕКЦІЯ і встановленням двох зв'язків (наборів) типу «один-до-багатьох» (рис. 2.7).
Петля — це структура, де один тип запису є одночасно власником і членом в одному типі набору. Структура виробів описана на рис. 2.8, б. Виріб складається з вузлів і деталей; у свою чергу вузли можуть складатися з інших вузлів і деталей. Тоді навколо типу запису ВУЗОЛ утворюється петля.
Поняття ключа У будь-якому реляційному відношенні можна виділити таку множину атрибутів, що набори відповідних їм значень однозначно ідентифікуватимуть кортежі відношення. Це випливає з того, що відношення є різновидом множини, а отже, не може містити кортежів, які повторюються, відтак — уся множина атрибутів реляційного відношення унікально ідентифікує кортежі. Множина атрибутів, що однозначно ідентифікують кортежі реляційного відношення, називається ключем. Принцип роботи зв’язків полягає в зіставленні даних у полях ключів — часто такі поля мають однакові імена в обох таблицях. У більшості випадків поля, що збігаються — це первинний ключ однієї таблиці, який створює унікальний ідентифікатор для кожного запису, і зовнішній ключ іншої таблиці. Ключ називається простим, якщо складається з одного атрибута (#Ід), і складеним — якщо з кількох атрибутів, наприклад (ПІБ, Адреса). Ключ називають надлишковим, якщо певна його підмножина також є ключем. Наприклад, ключ (#Ід, ПІБ, Адреса) є надлишковим тому, що містить атрибут #Ід, який також є ключем. Ключ, що не є надлишковим, називають мінімальним. Іноді надлишковий ключ називають суперключем, а мінімальний — можливим ключем. Реляційне відношення може мати багато можливих ключів, але тільки один із них є первинним. Первинний ключ має такі властивості: ♦ кожне реляційне відношення має один і лише один первинний ключ; ♦ значення всіх атрибутів первинного ключа не можуть бути невизначеними, оскільки він має унікально ідентифікувати всі кортежі будь-якого екземпляра реляційного відношення; ♦ значення первинного ключа не можуть повторюватися, але допускаються повторення значень частини складеного первинного ключа; ♦ апріорі значення первинного ключа не впливають на порядок кортежів у табличному зображенні реляційного відношення, хоча інколи таблиці впорядковують за ключем; ♦ первинний ключ не впливає на доступ до кортежів, який може бути здійснено за значенням будь-якого атрибута чи набору атрибутів незалежно від того, чи є він первинним ключем. Якщо розглядається певне реляційне відношення, то сукупність атрибутів, що є первинним ключем іншого реляційного відношення, називається зовнішнім (стороннім) ключем. За допомогою зовнішніх ключів у реляційній моделі встановлюються зв'язки між реляційними відношеннями (точніше, між їхніми кортежами). Зовнішні ключі мають такі властивості: ♦ значення зовнішнього ключа завжди посилається на певне значення відповідного первинного ключа, тобто будь-яке значення зовнішнього ключа має бути значенням первинного ключа іншого відношення; ♦ значення зовнішнього ключа, на відміну від значень первинного ключа, можуть бути невизначеними й повторюватися в межах реляційного відношення. Саме завдяки рівності значень, що відповідають цим двом атрибутам, встановлюється зв'язок між кортежами різних реляційних відношень. Типи зв’язків між таблицями Існує три типи зв’язків між таблицями. · Зв’язок «один-до-багатьох» Розглянемо базу даних відстеження замовлень, яка включає таблицю «Клієнти» й таблицю «Замовлення». Клієнт може розмістити будь-яку кількість замовлень. Таким чином, для будь-якого клієнта, представленого в таблиці «Клієнти», в таблиці «Замовлення» може міститися багато замовлень. Отже, взаємозв’язок між таблицями «Клієнти» та «Замовлення» є зв’язком «один-до-багатьох». Щоб представити зв’язок «один-до-багатьох» у структурі власної бази даних, візьміть первинний ключ на стороні зв’язку «один» і вставте його як додаткове поле або поля в таблицю на стороні зв’язку «багато». У цьому разі, наприклад, нове поле — поле ідентифікатора з таблиці «Клієнти» — потрібно додати до таблиці «Замовлення» та назвати його «Ідентифікатор клієнта». Потім Access зможе використати номер із поля «Ідентифікатор клієнта» в таблиці «Замовлення» для пошуку користувачів, які відповідають певним замовленням. · Зв’язок «багато-до-багатьох» Розглянемо зв’язок між таблицями «Товари» та «Замовлення». В одному замовленні може бути вказано кілька товарів. З іншого боку, один товар може зустрічатися в багатьох замовленнях. Таким чином, кожному запису в таблиці «Замовлення» може відповідати багато записів у таблиці «Товари». Крім того, кожному запису в таблиці «Товари» також може відповідати багато записів у таблиці «Замовлення». Такий тип зв’язку називається зв’язком «багато-до-багатьох», оскільки будь-якому товару може відповідати багато замовлень, а будь-якому замовленню може відповідати багато товарів. Зауважте, що для виявлення наявних зв’язків «багато-до-багатьох» між таблицями важливо розглянути обидва кінці зв’язку. Для представлення зв’язку «багато-до-багатьох» потрібно створити третю таблицю, яку часто називають розподільною, щоб розділити зв’язок «багато-до-багатьох» на два зв’язки «один-до-багатьох». Первинний ключ із кожної з двох таблиць потрібно вставити в третю таблицю. У результаті в третій таблиці буде записано усі випадки, або екземпляри, зв’язків. Наприклад, таблиці «Замовлення» та «Товари» пов’язані зв’язком «багато-до-багатьох», який визначатиметься через створення двох зв’язків «один-до-багатьох» із таблицею «Відомості про замовлення». В одному замовленні може зустрічатися багато товарів, і кожний товар може зустрічатися в багатьох замовленнях. · Зв’язок «один-до-одного» У зв’язку «один-до-одного» кожному запису в першій таблиці може відповідати лише один запис у другій таблиці, а кожному запису в другій таблиці може відповідати лише один запис у першій таблиці. Цей тип зв’язку не дуже поширений, оскільки зазвичай відомості, пов’язані між собою в такий спосіб, зберігаються в одній таблиці. Зв’язок «один-до-одного» можна використовувати для розділення таблиці з великою кількістю полів, для відокремлення частини таблиці з міркувань безпеки або для зберігання даних, які застосовуються лише до підмножини головної таблиці. У разі визначення такого зв’язку обидві таблиці повинні мати спільні поля. Тема 3.2. Реляційна алгебра До складу реляційної моделі даних, крім структури даних, мають входити операції маніпулювання даними. З усіх таких операцій складається мова запитів. Найбільш відомими мовами запитів у реляційній моделі є реляційна алгебра та реляційне числення. У класичному розумінні алгебра визначається як пара, що складається з основної множини і множини операцій (сигнатури), при цьому аргументи й результат кожної операції належать основній множині. Реляційна алгебра є алгеброю в строгому класичному розумінні її визначення. Елементами основної множини є реляційні відношення. У зв'язку з цим операції алгебри можуть вкладатися одна в одну, тобто аргументом певної операції може бути результат виконання іншої операції. Це дає можливість записувати запити довільного рівня складності у вигляді виразів, що містять вкладені одна в одну операції. Операції реляційної алгебри Сигнатура реляційної алгебри Кодда складається з восьми операцій. Перш ніж детально розглянути ці операції, введемо поняття сумісності реляційних відношень. Це поняття є необхідним, оскільки деякі операції (а саме: теоретико-множинні операції об'єднання, перетину та різниці) визначені лише для сумісних реляційних відношень. Реляційні відношення. 1) у них однакова кількість атрибутів, тобто k = п; 2) можна встановити взаємно однозначну відповідність між доменами атрибутів першої та другої реляцій, тобто існує таке об’єктивне відобр
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 365; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.223.106.232 (0.09 с.) |
 Ієрархічний зв'язок між сегментами позначається лініями зі стрілками, що проведені від батьківського сегмента до дочірнього. Батьківські сегменти, як правило, розміщують над дочірніми.
Ієрархічний зв'язок між сегментами позначається лініями зі стрілками, що проведені від батьківського сегмента до дочірнього. Батьківські сегменти, як правило, розміщують над дочірніми. екземпляр будь-якого сегмента (окрім кореневого) не може існувати без відповідного екземпляра батьківського сегмента;
екземпляр будь-якого сегмента (окрім кореневого) не може існувати без відповідного екземпляра батьківського сегмента; У такий спосіб ієрархічна впорядкованість сегментів створює зв'язок «один-до-багатьох» між екземплярами батьківського і дочірнього сегментів. Приклад екземплярів ієрархічної схеми наведений на рис. 2.2.
У такий спосіб ієрархічна впорядкованість сегментів створює зв'язок «один-до-багатьох» між екземплярами батьківського і дочірнього сегментів. Приклад екземплярів ієрархічної схеми наведений на рис. 2.2. Набір — пойменований дворівневий ієрархічний зв'язок типів записів. Із дворівневих наборів можуть будуватися багаторівневі ієрархії та мережні структури. Кожний тип набору — це сукупність зв'язків між двома або кількома типами записів, де один тип запису оголошується власником, а інший (або кілька інших) — членами типу набору. Екземпляр набору містить один екземпляр запису-власника і довільну кількість екземплярів кожного типу запису-члена набору. Отже, набір описує дворівневий ієрархічний зв'язок типу «один-до-багатьох».
Набір — пойменований дворівневий ієрархічний зв'язок типів записів. Із дворівневих наборів можуть будуватися багаторівневі ієрархії та мережні структури. Кожний тип набору — це сукупність зв'язків між двома або кількома типами записів, де один тип запису оголошується власником, а інший (або кілька інших) — членами типу набору. Екземпляр набору містить один екземпляр запису-власника і довільну кількість екземплярів кожного типу запису-члена набору. Отже, набір описує дворівневий ієрархічний зв'язок типу «один-до-багатьох». Типи наборів можуть використовуватися для створення багаторівневих ієрархічних або мережних структур.
Типи наборів можуть використовуватися для створення багаторівневих ієрархічних або мережних структур.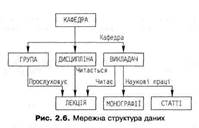 Трирівнева ієрархія у вигляді двох типів наборів: Кафедра і Наукові праці показана на рис. 2.5. Тип запису ВИКЛАДАЧ є власником у типі набору Наукові праці та членом у типі набору Кафедра.
Трирівнева ієрархія у вигляді двох типів наборів: Кафедра і Наукові праці показана на рис. 2.5. Тип запису ВИКЛАДАЧ є власником у типі набору Наукові праці та членом у типі набору Кафедра. Мережна структура дає змогу моделювати зв'язки типу «багато-до-багатьох». Такий зв'язок, наприклад, існує між викладачами та дисциплінами: викладач читає багато дисциплін, і дисципліна може викладатися багатьма викладачами.
Мережна структура дає змогу моделювати зв'язки типу «багато-до-багатьох». Такий зв'язок, наприклад, існує між викладачами та дисциплінами: викладач читає багато дисциплін, і дисципліна може викладатися багатьма викладачами.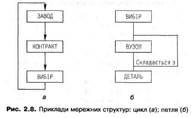 Мережна структура може відображувати цикли та петлі. Циклом називається конфігурація, в якій предок типу запису є водночас його нащадком. Приклад циклічної мережної структури наведений на рис. 2.8, а. Тут вироби певного заводу є сировиною для виробів іншого заводу.
Мережна структура може відображувати цикли та петлі. Циклом називається конфігурація, в якій предок типу запису є водночас його нащадком. Приклад циклічної мережної структури наведений на рис. 2.8, а. Тут вироби певного заводу є сировиною для виробів іншого заводу. Категорії схем, які зустрічаються в мережних структурах даних, зображені на рис. 2.9. Як бачимо, мережна структура даних здатна моделювати в повному обсязі ієрархічну структуру та власне мережні схеми. Окрім того, у загальному випадку вона дає можливість описувати петлі та цикли.
Категорії схем, які зустрічаються в мережних структурах даних, зображені на рис. 2.9. Як бачимо, мережна структура даних здатна моделювати в повному обсязі ієрархічну структуру та власне мережні схеми. Окрім того, у загальному випадку вона дає можливість описувати петлі та цикли. називаються сумісними, якщо:
називаються сумісними, якщо:


