
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Ограничение на количество строкСодержание книги
Поиск на нашем сайте
Если таблица большая (несколько сотен записей), то работать с ней не удобно. Поэтому производят фильтрацию данных, то есть выборку и предъявление на экран группы записей, отвечающих определенным требованиям. С выборкой можно проводить все операции редактирования. По окончании работы с выборкой исходную таблицу восстанавливают в полном (первоначальном) виде. Для установки фильтра данных используют команду SET FILTER ТО <выр.1> В опции <выр. L> указывают имя поля и его значение, по которым надо выполнить фильтрацию. Для снятия фильтра и восстановления первоначального вида таблицы используют ту же команду, но без опции. Ограничение на количество полей Фильтрация полей применяется при работе с длинными записями, которые имеют длину более одного экрана. При редактировании таких записей па экран выводят те поля, в которые надо внести изменения, и одно-два поля, идентифицирующих запись. Фильтрация полей выполняется в два этапа: на первом этапе определяется список полей, а на втором — фактическая установка фильтра. Для определения списка полей используют команду: SET FIELDS ТО [<список полей> | ALL [LIKE <маска> | EXCEPT <маска>] ] После выполнения этой команды, из текущей таблицы для установки фильтра будут отобраны либо поля, имена которых указаны в <списке полей>, либо все поля. По умолчанию приня-» опция ALL — все поля. Опция LIKE включает в список полей е поля, имена которых удовлетворяют маске (шаблону). Опция EХСЕРТ включает в список полей все поля, имена которых не удовлетворяют маске (шаблону). Если повторно подать эту же команду с другим <списком полей>, то вновь определенный список полей будет добавлен к сующему списку полей. Команда SET FIELDS TO без опции закрывает все поля, открытые предыдущими командами SET DS ТО. Для установки фильтра полей используют команду SET FIELDS ON | OFF | LOCAL | GLOBAL. Назначение опций: ON — устанавливает фильтр для ранее определенных полей. OFF — отменяет список полей и разрешает отображение всех полей таблицы. По умолчанию установлена опция OFF. LOCAL — определяет, что для фильтра доступны только поля текущей таблицы. GLOBAL — разрешает отображать поля всех таблиц, между которыми установлены реляционные отношения (установлены взаимосвязи).
ИНДЕКСИРОВАНИЕ БАЗ ДАННЫХ Если записей в таблице много, то найти нужную запись бывает очень трудно. Поиск данных производится методом перебора, то есть просматриваются все записи таблицы от первой записи до последней записи, что приводит к большим затратам времени. Чтобы облегчить поиск данных в таблице, используют индексы. Индекс, иногда его называют указатель, представляет собой порядковый номер записи в таблице. Индекс строится по значениям одного поля или по значениям нескольких полей. Индекс, построенный по значениям одного поля, называется простым, а по значениям двух и более полей — сложным. Во время построения индекса записи в таблице сортируются по значениям поля (или полей) будущего индекса. Затем первой строке таблицы присваивается индекс номер один, второй строке — индекс номер два и т. д. до конца таблицы. Как простой, так и сложный индекс имеют свой тип (Туре). Первичный (Primary) индекс (ключ) — это поле или группа полей, однозначно определяющих запись, то есть значения первичного индекса уникальны (не повторяются). В реляционной базе данных каждая таблица может иметь только один первичный ключ. Внешних ключей у таблицы может быть много и они будут иметь один из типов: • Candidate — кандидат в первичный ключ или альтернативный ключ. Он обладает всеми свойствами первичного ключа. • Unique (уникальный) — допускает повторяющиеся значения в поле, по которому он построен, но на экран будет выводиться только одна первая запись из группы записей с одинаковым значением индексного поля. • Regular (регулярный) — не накладывает никаких ограничений на значения индексного поля и на вывод записей на экран. Индекс только управляет порядком отображения записей. Это наиболее популярный тип индекса. Взаимосвязь между таблицами осуществляется по индексам, которые называют ключами. Построенный индекс хранится в специальном индексном файле. Если индексный файл хранит только один индекс, то он называется одноиндексным и имеет расширение.idx. Индексные файлы, которые хранят много индексов, называются мультииндексными и имеют расширение.cdx. Каждый индекс, который хранится в мультииндексном файле, называется тегом. Каждый тег имеет свое уникальное имя. Мультииндексные файлы бывают двух типов: просто мульти-индексные файлы (о них рассказано выше) и структурные мульти-индексные файлы. Структурный мультииндексный файл имеет одинаковое имя с таблицей, которой он принадлежит (отличие только в расширении файла), и обладает следующими свойствами: • автоматически открывается со своей таблицей; • его нельзя закрыть, но можно сделать не главным. Одна таблица может иметь много индексных файлов как одноиндексных, так и мультииндексных. В старших версиях FoxPro используются Мультииндексные файлы. СОЗДАНИЕ ИНДЕКСА Создать индекс можно двумя способами. а. С помощью команды: INDEX ON <индексное выражение> ТО <idх-файл> | TAG <имя тега> [OF <сdх-файл>] [FOR <условие>] [COMPACT] [DESCENDING] [UNIQUE] [ADDITIVE] [NOOPTIMIZE] Назначение опций: < индексное выражение> — имя поля (или полей), по значениям которого надо построить индекс. При построении сложного индекса имена полей перечисляются через знак + (плюс). Если сложный индекс построен по: • числовым полям, то индекс строится по сумме значений полей; • символьным полям, то индекс строится сначала по значению первого поля, а при повторяющихся значениях первого поля — по значениям второго поля; при повторяющихся значениях первого и второго полей — по значениям третьего поля и т. д.; • по полям разных типов, то сначала значения полей приводят к одному типу, как правило символьному, а затем строят индекс. Длина индексного выражения не должна превышать 254 символа. ТО <idх-файл> — указывается имя одноиндексного файла. TAG <имя тега> [OF <cdx-файл>] — указывается имя тега в мультииндексном файле. Если используется опция [OF <cdx-файл>], то создаваемый тег помещается в указанный мульти-индексный файл, а если требуемый мультииндексный файл отсутствует, то будет построен структурный мультииндексный файл. Если опция [OF <сс!х-файл>] опущена, то созданный тег будет помещен в текущий мультииндексный файл. FOR <условие> — устанавливает режим отбора в индекс тех записей таблицы, которые удовлетворяют <условию>. COMPACT — управляет созданием компактного одноиндексного файла. В старших версиях FoxPro не используется. DESCENDING — строит индекс по убыванию. По умолчанию используется построение индекса по возрастанию (ASCENDING). Для одноиндексных файлов можно построить индекс только по возрастанию. Если перед использованием команды INDEX ON... подать команду SET COLLATE, то можно построить одноин-дексный файл по убыванию. UNIQUE — строит уникальный индекс. Если индексное поле (поля) содержит повторяющиеся значения, то в индекс попадает только одна первая запись и остальные записи будут не доступны. ADDITIVE — вновь создаваемый индексный файл не закрывает уже открытые к этому моменту времени индексные файлы. Если опция опущена, то вновь создаваемый индексный файл закрывает все ранее открытые индексные файлы. б. С помощью Главного меню: В этом случае индекс создается либо при создании таблицы, либо при модификации структуры таблицы. Для этого в диалоговой панели Table Designer надо выбрать вкладку Index (рис. 3.1). Каждый индекс описывается одной строкой в окне диалоговой панели Table Designer.
В графе Туре, снабженной раскрывающимся списком, указывается один из допустимых типов индекса. Если индекс строится для таблицы, входящей в состав базы данных, то возможны четыре значения: Primary, Candidate, Unique и Regular. Если ин деке строится для свободной таблицы, то в раскрывающемся списке отсутствует значение Primary. В графе Expression перечисляются имена полей, по значениям которых надо построить индекс. Если строится сложный индекс, то удобнее воспользоваться построителем выражений, который запускается нажатием кнопки, расположенной справа от поля ввода.
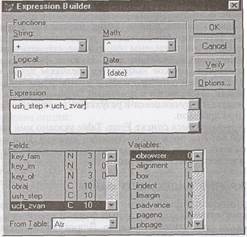
В графе Filter можно задать логическое условие и построить индекс не для всех записей таблицы, а только для записей, удовлетворяющих условию фильтра. Эта графа также снабжена построителем выражений. Содержание и внешний вид обоих построителей одинаковые (рис. 3.2). На рис. 3.2 показано построение сложного индекса по двум символьным полям ush_step и uch_zvan (имя тегу uch было присвоено до вызова на экран построителя выражений). Знак «+», указывающий на построение сложного индекса, взят из раскрывающегося списка String, В раскрывающемся списке String приведены допустимые строковые функции. Аналогично в раскрывающихся списках Math, Logical и Date приведены допустимые математические, логические функции и функции даты. Нужная функция из этих раскрывающихся списков выбирается щелчком левой кнопки мыши. Имена полей (список Fields) и имена переменных (список Variables) выбираются с помощью двойного щелчка левой кнопки мыши. Получившееся в результате выражение помещается в окно Expression. В раскрывающемся списке From Table указано имя таблицы, из которой берутся поля для построения индекса. При желании можно заказать любую таблицу из текущей базы данных и для построения индекса взять любое поле. ОТКРЫТИЕ ИНДЕКСНОГО ФАЙЛА Открыть индексный файл можно только в том случае, если ранее открыт соответствующий табличный файл. В противном случае будет выдано сообщение об ошибке. Для открытия индексного файла надо подать команду: SET INDEX TO [список индексных файлов] [ORDER <выр.N> | <idx-файл>|[ТАG<имя тега>][ОР<cdх-файл>]] [ASCENDING | DESCENDING] [ADDITIVE] Назначение опций такое же, как в командах USE и INDEX ON. Открыть существующий индексный файл можно одновременно с открытием табличного файла командой USE (см. п. 2.2 «Открытие таблицы»). Для закрытия всех индексных файлов надо подать одну из команд: либо SET INDEX TO без опций, либо CLOSE INDEX. ЗАМЕНА ТЕКУЩЕГО ИНДЕКСА Для каждой таблицы одновременно может быть открыто несколько индексных файлов, но текущим (активным) будет только один индекс. По умолчанию принято, что текущим будет первый по порядку индекс в том индексном файле, имя которого указано первым в списке имен индексных файлов команды USE или команды SET INDEX TO. Текущим можно сделать любой индекс из текущего индексного файла с помощью команды SET ORDER TO [<выр.N1> | <idх-файл> | [TAG <имя тега> [OF <сdх-файл>]] [IN <выр.N2> | <выр.С ] [ASCENDING | DESCENDING] Назначение опций: <выр.Nl> — задает текущий индекс по его порядковому номеру в мультииндексном файле. <idx - файл> — делает текущим одноиндексный файл. TAG <имя тега> [OF <cdx - файл>] — задает текущий индекс по имени тега из указанного мультииндексного файла. Если опция [OF <сdx-файл>] опущена, то тег выбирается из текущего мультииндексного файла. IN <выр.N2> — указывает номер рабочей области, в которой находится индексный файл. Опция используется в том случае, если табличный файл открыт в одной рабочей области, а индексный файл — в другой рабочей области. Текущим индекс также можно сделать с помощью диалоговой панели Table Designer, переместив строку описания нужного индекса на первое место.
|
||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 131; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.141.201.95 (0.007 с.) |

 В графе Name указывается имя тега мультииндексного файла. Если ранее открыт один из мультииндексеых файлов, то вновь построенный индекс помещается в открытый мультиин-дексный файл. Если индекс строится одновременно с созданием табличного файла или табличный файл не имеет мультиин-дексных файлов, то вновь построенный индекс помещается в автоматически создаваемый структурный мультииндексный файл.
В графе Name указывается имя тега мультииндексного файла. Если ранее открыт один из мультииндексеых файлов, то вновь построенный индекс помещается в открытый мультиин-дексный файл. Если индекс строится одновременно с созданием табличного файла или табличный файл не имеет мультиин-дексных файлов, то вновь построенный индекс помещается в автоматически создаваемый структурный мультииндексный файл.



