Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Функции SQL для обработки строкСодержание книги Поиск на нашем сайте
CHR(N) Возвращает символ ASCII кода для десятичного кода N ASCII(S) Возвращает десятичный ASCII код первого символа строки INSTR(S2.S1.pos[,N] Возвращает позицию строки S1 в строке S2 большую или равную pos.N - число вхождений LENGHT(S) Возвращает длину строки LOWER(S) Заменяет все символы строки на прописные символы INITCAP(S) Устанавливает первый символ каждого слова в строке на заглавный, а остальные символы каждого слова - на прописные SUBSTR(S,pos,[,len]) Выделяет в строке S подстроку длиной len, начиная с позиции pos UPPER(S) Преобразует прописные буквы в строке на заглавные буквы LPAD(S,N[,A]) Возвращает строку S, дополненную слева симолами A до числа символов N. Символ - наполнитель по умолчанию - пробел Rpad(S,N[,A]) Возвращает строку S, дополненную справа симолами A до числа символов N. Символ - наполнитель по умолчанию - пробел LTRIM(S,[S1]) Возвращает усеченную слева строку S. Символы удаляются до тех пор, пока удаляемый символ входит в строку - шаблон S1 (по умолчанию - пробел) RTRIM(S,[S1]) Возвращает усеченную справа строку S. Символы удаляются до тех пор, пока удаляемый символ входит в строку - шаблон S1 (по умолчанию – пробел). TRANSLATE(S,S1,S2) Возвращает строку S, в которой все вхождения строки S1 замещены строкой S2. Если S1 <> S2, то символы, которым нет соответствия, исключаются из результирующей строки REPLACE(S,S1,[,S2]) Возвращает строку S, для которой все вхождения строки S1 замещены на подстроку S2. Если S2 не указано, то все вхождения подстроки S1 удаляются из результирующей строки NVL(X,Y) Если Х есть NULL, то возвращает в Y либо строку, либо число, либо дату в зависимости от исходного типа Y Специальные функции DECODE(E,S1,R1,S2,R2,…,[def]) Если E соответствует Si, то возвращается Ri, в противном случае - def или NULL, если умолчание не задано TO_NUMBER(S) Возвращает результат преобразования строки S в аргумент типа NUMBER TO_CHAR(X[,F]) Возвращает результат преобразования строки S в аргумент типа DATE согласно заданному формату даты F TO_DATE(S[,F]) Возвращает результат преобразования значения параметра S символьного типа в тип DATE Функции обработки даты и времени SYSDATE Возвращает текущую дату и время ROUND(D[,F]) Округляет значение даты D согласно заданному шаблону TRANC(D[,F]) Усекает значение даты D согласно заданному шаблону NEXT_DAY(D,S) Возвращает дату дня, который является первым днем, более поздним, чем текущая дата с названием S Если потребовался список новых служащих, поступивших за последний квартал в организацию, то можно написать запрос в следующем виде: SELECT ENAME, HIREDATE, HIREDATE + 92 DAYS FROM EMPLOYEE WHERE HIREDATE + 92 DAYS > SYSDATE AND DEPNO=30; Ключевое слово SYSDATE всегда возвращает текущую дату. В этом примере также показано, как используется арифметический оператор сложения с переменными типа "дата". К переменной типа "дата" можно прибавлять и вычитать из него целое число дней, месяцев, лет, часов, минут, секунд, микросекунд. Для этого используются соответствующие ключевые слова (DAY, MONTH и т.д.), следующие за целой константой (дробная часть игнорируется, если вы указываете число с десятичной точкой). Имеется ограничение на использование скобок в таких выражениях (так, заключение в скобки выражения 1 DAYS + 1 YEARS приведет к ошибке). Агрегатные функции Агрегатные функции в SQL позволяют выбирать обобщающую информацию из группы строк и проводить систематизацию данных. AVG(X) = AVG(ALL X) AVG(DISTINCT X) Вычисляет среднее значение аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты COUNT(*) COUNT(X) = COUNT(ALL X) COUNT(DISTINCT X) Вычисляет числа итемов. При указании * всегда возвращается число строк в таблице. Указание DISTINCT подавляет дубликаты MAX(X) = MAX(ALL X) MAX (DISTINCT X) Вычисляет максимальное значение аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты MIN(X) = MIN(ALL X) MIN (DISTINCT X) Вычисляет минимальное значение аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты SUM(X) = SUM(ALL X) SUM (DISTINCT X) Вычисляет сумму значение аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты STDDEV([DISTINCT|ALL]X) Вычисляет стандартное отклонение на множестве значений аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты: VARIANCE([DISTINCT|ALL]) Вычисляет квадрат дисперсии Использование функций агрегирования позволяет вам находить суммарные значения колонок и разброс данных в колонке. Так, после выполнения запроса: SELECT SUM(SAL) FROM EMPLOYEE; - вы узнаете итоговую сумму зарплаты по организации, а из запроса SELECT AVG(SAL), STDDEV(SAL) FROM EMPLOYEE; - среднюю зарплату по организации и ее разброс (дисперсию). Однако наиболее часто требуется подобная итоговая информация не для таблицы в целом, а для определенных наборов (групп) строк таблицы. Для того чтобы группировать строки таблицы по какому-либо признаку, в команде SELECT существует специальное предложение GROUP BY, которое задает колонку (или колонки) для проведения группировки. Это предложение группирует строки таблицы по значениям колонок группировки с последующим подавлением дублирующих значений в колонках группировки, т.е. позволяет определять подмножество значений некоторой колонки в терминах другой колонки и применять к полученным подмножествам функции агрегирования. Предположим, что вы хотите найти минимальные и максимальные оклады служащих в подразделениях, тогда вы можете написать SELECT DEPNO, MIN(SAL), MAX(SAL) FROM EMPLOYEE GROUP BY DEPNO. Предложение GROUP BY должно следовать после предложения WHERE, если последнее присутствует в команде SELECT. Каждая строка результирующей таблицы относится к одной группе строк. Число групп определяется числом различных значений в колонке группировки (в данном случае DEPNO). Агрегатные функции применяются к каждой группе как к отдельному множеству. Агрегатные функции можно использовать при соединении таблиц. Допустим, что вам нужно знать, сколько служащих работает на каждой должности в каждом подразделении, какова сумма зарплаты на подразделение и средняя зарплата. Тогда вам нужен запрос: SELECT DNAME, JOB, SUM(SAL), COUNT(*), AVG(SAL) FROM EMPLOYEE, DEPARTAMENT WHERE EMPLOYEE.DEPNO=DEPARTAMENT.DEPNO GROUP BY DNAME, JOB Функции SUM(), COUNT(), AVG() вычисляют суммы, число строк в группе и среднее значение в группе строк. В SQL можно задавать условия поиска для группы строк. Для этого в команде SELECT существует предложение HAVING, которое должно следовать за предложением GROUP BY. HAVING задает условие поиска для группы строк. Допустим, что вам необходимо получить ответ на тот же вопрос, что и в предыдущем примере, но при этом каждая группа должна состоять не менее чем из двух сотрудников. SELECT DNAME, JOB, SUM(SAL), AVG(SAL) FROM EMPLOYEE, DEPARTAMENT WHERE EMPLOYEE.DEPNO=DEPARTAMENT.DEPNO GROUP BY DNAME, JOB HAVING COUNT(*)>=2 Условие поиска в предложении HAVING исключает из результирующей таблицы группы, содержащие менее двух работников.
Отличие SQL от QBE
SQL является языком высокого уровня. Пользователь не должен при его использовании помнить об открытии и закрытии каких-либо таблиц, определять наиболее эффективный способ реализации запроса, активизировать индексы и т.п. Все это система делает автоматически. Во многих современных СУБД имеются построители запросов SQL. Обычно в этом качестве выступают языки типа QBE. Но не все типы запросов SQL могут быть реализованы на QBE. Некоторые типы запросов, например запрос-объединение (Union), невозможно создать на QBE. Индексация
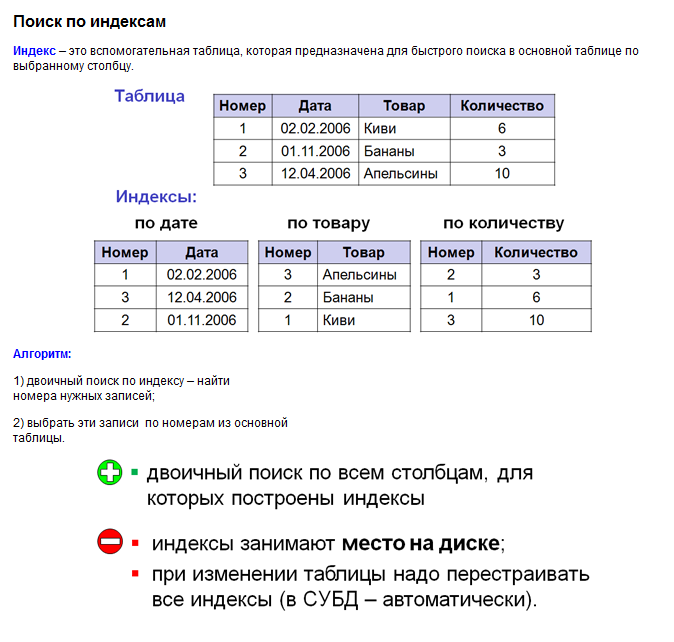
Индекс таблицы - это вспомогательный файл, который создается для того, чтобы ускорить выполнение реляционных операций с участием этой таблицы. Индекс строится для определенного столбца (или совокупности столбцов) таблицы. Он состоит из пар вида {Значение столбца, физический адрес соответствующей строки на диске} и отсортирован по значению столбца в порядке возрастания или убывания. Для одной и той же таблицы может существовать несколько индексов. Не следует путать индекс, построенный для совокупности нескольких столбцов таблицы, и несколько различных индексов, построенных для отдельных столбцов. Если индекс создан, то при выполнении операций с таблицей система будет пользоваться им автоматически. Перечислим коротко ряд рекомендаций по индексации таблиц. Индексируют те столбцы, по которым наиболее часто производятся операции поиска, сортировки, соединения, группирования. При соединении таблиц полезнее иметь индекс для той из них, которая содержит большее число строк. Индексирование замедляет операции вставки, удаления или изменения строк, поскольку эти операции должны быть выполнены не только над таблицей, но и над ее индексами. Поэтому иногда перед массовым занесением строк в таблицу ее индексы уничтожают, а затем вновь создают.
Индексы бывают уникальные и неуникальные. Если вы создаете уникальный индекс по некоторому столбцу, то система гарантирует, что в данном столбце не будет повторяющихся значений. Выделяется кластеризованные индексы. При построении таких индексов данные таблицы физически упорядочиваются на диске в соответствии с упорядоченностью строк индекса. Поскольку операционная система поддерживает буферизацию дискового обмена, физически упорядоченные данные оказываются в буферном кэше вместе, можно сказать, "автоматически". Следовательно, скорость обработки запросов возрастает. Для каждой таблицы может существовать только один кластеризованный индекс, что следует из его определения.
Поиск в БД
Транзакция
Транзакцией называется последовательность операций, которая рассматривается как неделимое место над базой «все или ничего». Если транзакция прошла успешно, то та база проходит из одного непротиворечивого состояния в другое. Если во время выполнения транзакции произошёл сбой, то происходит откат пройденных шагов, и база опять остаётся в целостном непротиворечивом состоянии.
Цели транзакции. Транзакции необходимы для: 1. Восстановления после сбоя 2. Для устранения конфликта пользователей, пытающихся одновременно обратиться к базе. С помощью блокировок система «закрывает автоматически БД на замок», когда один пользователь обновляет БД.
Свойства транзакций: Свойства АСИД Транзакции обладают четырьмя важными свойствами: атомарность, согласованность, изоляция и долговечность (свойствами АСИД).
1. Атомарность. Транзакции атомарны (выполняется все или ничего).
2. Согласованность. Транзакции защищают базу данных согласованно. Это означает, что транзакции переводят одно согласованное состояние базы данных в другое без обязательной поддержки согласованности во всех промежуточных точках.
3. Изоляция. Транзакции отделены одна от другой. Это означает, что, если даже будет запущено множество конкурирующих друг с другом транзакций, любое обновление определенной транзакции будет скрыто от остальных до тех пор, пока эта транзакция выполняется. Другими словами, для любых двух отдаленных транзакций Т1 и Т2 справедливо следующее утверждение: Т1 сможет увидеть обновление Т2 только после выполнения Т2, а Т2 сможет увидеть обновление Т1 только после выполнения Т1.
4. Долговечность. Когда транзакция выполнена, ее обновления сохраняются, даже если в следующий момент произойдет сбой системы.
Фиксация транзакций – это действие, обеспечивающее запись на диск изменений, которые были сделаны во время выполнения транзакции.
Системный компонент, обеспечивающий атомарность (или ее подобие), называется администратором транзакций (или диспетчером транзакций), а ключами к его выполнению служат операторы COMMIT TRANSACTION и ROLLBACK TRANSACTION.
Оператор COMMIT TRANSACTION (для краткости commit) сигнализирует об успешном окончании транзакции. Он сообщает администратору транзакций, что логическая единица работы завершена успешно, база данных вновь находится (или будет находиться) в согласованном состоянии, а все обновления, выполненные логической единицей работы, теперь могут быть зафиксированы, т.е. стать постоянными.
Оператор ROLLBACK TRANSACTION (для краткости ROLLBACK) сигнализирует о неудачном окончании транзакции. Он сообщает администратору транзакций, что произошла какая-то ошибка, база данных находится в несогласованном состоянии и все обновления могут быть отменены, т.е. аннулированы.
Для отмены обновлений система поддерживает файл регистрации, или журнал, на диске, где записываются детали всех операций обновления, в частности новое и старое значения модифицированного объекта. Таким образом, при необходимости отмены некоторого обновления система может использовать соответствующий файл регистрации для возвращения объекта в первоначальное состояние.
SQL поддерживает операции COMMIT и ROLLBACK для фиксации и отката транзакции соответственно.
Специальный оператор SET TRANSACTION используется для определения некоторых характеристик транзакции, которую нужно будет инициировать, такие, как режим доступа и уровень изоляции.
В стандарте языка SQL не предусмотрена поддержка явным образом возможности блокировки (фактически, блокировка в нем вообще не упоминается). Блокировки накладываются неявно, при выполнении операторов SQL.
Журналы транзакций
Каждая база данных SQL Server имеет как минимум два файла, с ней ассоциирующихся: один файл данных, в котором непосредственно хранятся данные и как минимум один файл журнала транзакций. Журнал транзакций это основной компонент системы управления базами данных (СУБД). Все изменения в базе данных записываются в журнал транзакций. Используя эту информацию, СУБД может определить какая транзакция какие изменения внесла в данные SQL Server.
Основы журналирования
Оператор CREATE DATABASE используется для создания базы данных Microsoft SQL Server. Опция этой команды LOG ON используется для определения журнала транзакций создаваемой базы данных. Впервые созданные данные помещаются в файл данных, а запись изменений этих данных помещается в файле журнала транзакций. Как только делаются изменения в базе, журнал транзакций растет. Поскольку большинство изменений вносимых в базу, журналируются, Вам нужно будет отслеживать размер журнала транзакций, потому что, если данные постоянно меняются, журнал соответственно вырастает. Каждая контрольная точка Microsoft SQL Server гарантирует что все записи в журнале и все модифицированные страницы данных корректно записаны на диск. Файл журнала транзакций используется Microsoft SQL Server в процессе операции восстановления базы данных, чтобы зафиксировать завершенные транзакции и откатить незавершенные. Информация, записывающаяся в журнал транзакций, включает:
Ø Время начала каждой транзакции;
Ø Изменения внутри каждой транзакции и информацию для их отката (для этого используются снимки страниц данных до, и после транзакции);
Ø Информация о распределении памяти для страниц БД (выделении и изъятии экстента);
Ø Информация о завершении или откате каждой транзакции.
Эти данные Microsoft SQL Server использует в целях повышения целостности данных. Журнал транзакций используется при старте SQL Server, для того чтобы отменить сделанные изменения и установить состояние базы данных на момент, предшествующий началу изменений. При запуске SQL Server для каждой БД начинается процесс регенерации (recovery). SQL Server определяет те транзакции, которые необходимо откатить. Это происходит в том случае, когда неизвестно все ли изменения из кэша записаны на диск. Поскольку при выполнении контрольной точки все изменения сбрасываются на диск, то с нее и стартует процесс регенерации, который производит фиксацию транзакций на диск. Все изменения на страницах, сделанные до контрольной точки, уже записаны на диск, поэтому нет смысла для сброса их на диск еще раз и изменения, выполненные до контрольной точки, не берутся к рассмотрению. При необходимости отката транзакции SQL Server копирует снимки страниц данных до изменений, сделанных с момента запуска оператора BEGIN TRANSACTION. Журнал транзакций можно использовать при восстановлении базы данных. В этом случае журналируется фиксация транзакций. В процессе фиксации транзакций SQL Server сохраняет все сделанные изменения в базе данных на диске. Журнал транзакций полезен для устранения ошибок в базе данных, ошибок транзакций и позволяет обеспечить целостность данных.
Резервное копирование журнала транзакций
Для того чтобы повысить эффективность стратегии резервирования и восстановления БД, необходимо периодически делать резервные копии журнала транзакций. Создать резервную копию журнала транзакций можно с помощью команды BACKUP LOG. При использовании копирования журнала транзакций, при необходимости, базу данных можно восстановить на любой момент времени, содержащийся в копии журнала. Если Вы не резервируете журнал перед его усечением, то восстановить сможете только последнюю копию базы данных, все изменения прошедшие с этого времени будут потеряны. После того как Microsoft SQL Server заканчивает резервное копирование журнала транзакций, он усекает его неактивную часть, тем самым, высвобождая место. SQL Server может повторно использовать высвобожденное место, т.к. журнал транзакций непрерывно растет и ему требуется свободное пространство. Активная часть журнала содержит изменения, которые были сделаны в базе и еще не зафиксированы на диске. Microsoft SQL Server пытается запустить процесс контрольной точки всякий раз когда журнал транзакций заполняется более чем на 70 процентов, или при получении ошибки переполнения журнала транзакций, а также при останове SQL Server (если используется SHUTDOWN WITH NOWAIT) операция контрольной точки будет запущена для каждой базы данных. При включенной опции 'trunc. log on chkpt.' становится бесполезным выполнение резервного копирования журнала транзакций, поскольку информация о производимых изменениях постоянно уничтожается и неактивная часть журнала транзакций урезается каждый раз после выполнении процесса контрольной точки. По существу эта опция показывает, что Вы не сможете использовать журнал транзакций при восстановлении. Журнал транзакций необходим для отката изменений и в процессе регенерации при старте SQL Server. Используйте эту опцию только для тех систем, для которых не важны потери изменений, сделанных в течение всего дня, потому что в этом случае Вы сможете восстановить только последнюю копию базы данных, а сделанные позже изменения восстановить будет невозможно. Применяется это редко. Если журнал транзакций урезается с помощью оператора BACKUP LOG, то нельзя делать его копию до тех пор, пока не будет создана полная копия базы данных или дифференциальная копия. Дифференциальная копия содержит в себе только те изменения, которые произошли с момента последней полной копии базы данных. Также желательно избегать резервирования журнала транзакций после любых не журналируемых операций, которые произошли после последнего полного резервного копирования базы данных. Лучше сделать полную копию базы данных или разностное резервное копирование.
И в заключении, при добавлении или удалении любого файла из базы данных надо создать полную копию. Восстановить в этом случае базу данных на момент, предшествующий ее изменению, используя журнал транзакций, не удастся.
Блокировка транзакций
В SQL Server используется объект, который называется блокировкой (lock); он препятствует тому, чтобы несколько пользователей одновременно вносили изменения в базу данных и чтобы один пользователь считывал данные, которые изменяет в этот момент другой пользователь. Блокировка помогает обеспечивать логическую целостность транзакций и данных. Управление блокировками осуществляется внутренним образом из программного обеспечения SQL Server и захват блокировки осуществляется на уровне пользовательского соединения. Если пользователь захватывает блокировку (становится ее владельцем) по какому-либо ресурсу, то эта блокировка указывает, что данный пользователь имеет право на использование данного ресурса. К ресурсам, которые может блокировать пользователь, относятся строка данных, страница данных экстент (8 страниц), таблица или вся база данных. Например, если пользователь владеет блокировкой по странице данных, то другой пользователь не может выполнять операции на этой странице, которые повлияют на операции пользователя, владеющего данной блокировкой. Поэтому любой пользователь не может модифицировать страницу данных, которая блокирована и считывается в данный момент другим пользователем. Кроме того, ни один пользователь не может владеть блокировкой, конфликтующей с блокировкой, которой уже владеет другой пользователь. Например, два пользователя не могут одновременно владеть блокировками на одновременную модификацию одной и той же страницы. Одна блокировка не может одновременно использоваться более чем одним пользователем.
Система управления блокировками SQL Server автоматически захватывает и освобождает блокировки в соответствии с действиями пользователей. Для управления блокировками не требуется никаких действий со стороны DBA (администратора базы данных) или программиста. Однако вы можете использовать программные подсказки (hint), чтобы задать для SQL Server, какой тип блокировки нужно захватывать при выполнении определенного запроса или модификации базы данных (см. раздел "Подсказки блокировки" далее).
Поддерживаются различные уровни блокировок. Блокировка (Lock) – временное ограничение на выполнение операций обработки данных. Управлением блокировок занимается менеджер блокировок, т.е. пользователь на это никак не влияет.
1. Блокировка обновления. Когда транзакция пытается изменить данные, то устанавливается запрет для чтения этих данных другими транзакциями. Только когда 1-ая транзакция завершится, т.е. произойдёт фиксация, то открывается доступ к этим данным
2. Тупиковая или мертвая блокировка – первой транзакции нужно получить данные из второй транзакции, а вторая не может начаться до завершения первой. Происходит зависание. Тогда менеджер блокировок генерирует преимущества выполнения какой то одной транзакции, или обе посылает на откат.
Если нескольким пользователям требуется читать один фрагмент, то транзакция не блокируется, а выполняется параллельно.
Восстановление данных
1. Восстановление после жесткого сбоя Резервная копия + журнал транзакций 2. Индивидуальный откат транзакции Когда сбой в одной транзакции 3. Мягкий сбой системы Данные на диске остались не поврежденными, поэтому теряется только содержимое буфера памяти, но при перезагрузке все восстанавливается.
Контрольные точки
Если в транзакции задействовано много операций, то в алгоритме выполнения закладываются несколько контрольных точек, контрольные точки устанавливаются индивидуально.
Результаты выполнения контрольных точек записываются в журнал отдельно, и в случае сбоя уже не надо выполнять все операции, а использовать результаты контрольной точки.
Основные функции СУБД
Более точно, к числу функций СУБД принято относить следующие:
|
||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 171; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.17.75.138 (0.012 с.) |