Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
В-дерево. Добавление и удаление элементовСодержание книги
Поиск на нашем сайте
Видимо, наиболее популярным подходом к организации индексов в базах данных является использование техники B-деревьев. С точки зрения внешнего логического представления B-дерево - это сбалансированное сильно ветвистое дерево во внешней памяти. Сбалансированность означает, что длина пути от корня дерева к любому его листу одна и та же. Ветвистость дерева - это свойство каждого узла дерева ссылаться но большое число узлов-потомков. С точки зрения физической организации B-дерево представляется как мультисписочная структура страниц внешней памяти, т.е. каждому узлу дерева соответствует блок внешней памяти (страница). Внутренние и листовые страницы обычно имеют разную структуру. Поиск в B-дереве - это прохождение от корня к листу в соответствии с заданным значением ключа. Заметим, что поскольку деревья сильно ветвистые и сбалансированные, то для выполнения поиска по любому значению ключа потребуется одно и то же (и обычно небольшое) число обменов с внешней памятью. Более точно, в сбалансированном дереве, где длины всех путей от корня к листу одни и те же, если во внутренней странице помещается n ключей, то при хранении m записей требуется дерево глубиной logn(m), где logn вычисляет логарифм по основанию n. Если n достаточно велико (обычный случай), то глубина дерева невелика, и производится быстрый поиск. Основной "изюминкой" B-дереве является автоматическое поддержание свойства сбалансированности. Бинарные деревья представляют эффективный способ поиска. Бинарное дерево представляет собой структурированную коллекцию узлов. Деревья являются структурами несколько более сложными,чем списки. Списки представляются обычно, как нечто линейное, в то время как деревья в естественном представлении имеют более одного измерения. Деревья обычно изображают растущими сверху вниз, с корнем наверху. Отдельные ячейки, из которых составляется дерево, называют узлами (или потомками). Узел, имеющий дочерние узлы, называется их родительским узлом. Аналогия с генеалогическим деревом позволяет ввести термины прародитель, предок и потомок. Узел, не имеющий дочерних узлов, называется листом. Хотя узел может иметь более одного дочернего, родительский узел может быть у него только один. Структура данных, в которой узлы имеют более одного родителя, не может считаться деревом. Единственым узлом, не имеющим родителя является корневой узел. В двоичном дереве у узла может быть один, два или ни одного потомка. Дочерний узел, расположенный левее родительского, называется левым потомком (левым дочерним). Дочерний узел правее родителя называют правым потомком.
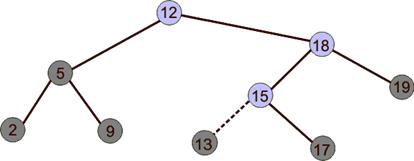 7 тогда x равно left[x]8 иначе x равно right[x]9 Конец10 p[z] равно y11 если y равно NULL12 тогда root[T] равно z13 иначе если key[z] меньше key[y]14 тогда left[y] равно z15 иначе right[y] равно z 16 7 тогда x равно left[x]8 иначе x равно right[x]9 Конец10 p[z] равно y11 если y равно NULL12 тогда root[T] равно z13 иначе если key[z] меньше key[y]14 тогда left[y] равно z15 иначе right[y] равно z 16 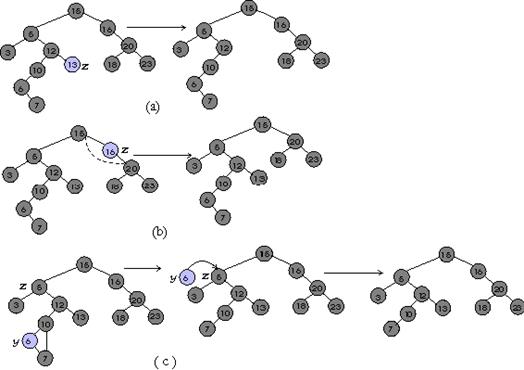 Конец Конец Удаление. Параметром процедуры удаления явяляется указатель на удаляемую вершину. При удалении возможны случаи, указанные на рисунке ниже. Если у z нет детей, для удаления z достаточно поместить NULL в соответствующее поле его родителя (вместо z). Если у z есть один ребёнок, можно вырезать z, соединив его родителя напрямую с ребенком. Если же детей двое, требуются некоторые приготовления: мы находим следующий (в смысле порядка на ключах) за z элемент y; у него нет левого ребёнка. Теперь можно скопировать ключ и дополнительные данные из вершины y в вершину z, а саму вершину y удалить описанным образом. Удаление(T,z)Начало1 если left[z] равно NULL или right[z]=NULL2 тогда y равно z3 иначе y равно ПолучитьСледующийЭлемент(z)4 если left[y] не равно NULL5 тогда x равно left[y]6 иначе x равно right[y] 7 если x не равно NULL 8 тогда p[x] равно p[y]910 если p[y] равно NULL11 тогда root[T] равно x12 иначе если y равно left[p[y]] 13 тогда left[p[y]] равно x14 иначе right[p[y]] равно x 15 если y не равен z16 тогда key[z] равно key[y]17 // Копируем дополнительные данные связанные с y18 Удалить y КонецПример. Пусть у нас есть дерево третьего порядка, с ключами 12, 8, 4, 9, 6, 13, 14, 16,100, 10. Приходит ключ 12, его заносим в корень
Приходит 4, места в корне нет, разбиваем на 2
Приходит 9, она больше 8, но меньше 12, 12 сдвигаем, перед ней записываем 9, приходит 6 она меньше 8, но больше 4, записываем ее после 4:
После того как придет 13, 14, 16, 100, 10 вид дерева будет следующим:
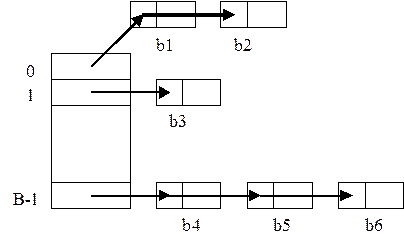
Основная идея, лежащая в основе организации файлов с хэшированным доступом заключается в разделении записей файла между участками, каждый из которых, содержит один или более блоков памяти. Для любого файла, хранимого таким образом, существует функция h, которая использует в качестве аргумента значение ключа файла и производит некоторое целое число от нуля до некоторого максимального значения.
Допустим V это значение ключа. Тогда h(V) указывает номер участка, в котором должна находится запись с этим значением ключа, если она присутствует вообще. Необходимо, чтобы h хэшировала, т.е. чтобы h(V) принимала все ее возможные значения примерно с равной вероятностью, когда V пробегает по множеству значений ключа. На данном ниже рисунке показана организация хэширования файла с B-участками. 1. Интерпретируем значения ключа как последовательность битов, формированную путем конкатенации значений всех полей ключа. Эта последовательность имеет фиксированную длину, поскольку каждое поле имеет фиксированную длину. 2. Делим последовательность битов на группы, состоящие из фиксированного числа битов, например 16-ти. Последнюю группу при необходимости дополняем нулями. 3. Складываем группу битов как целые числа. 4. Делим сумму на число участков и используем остаток как номер участка.
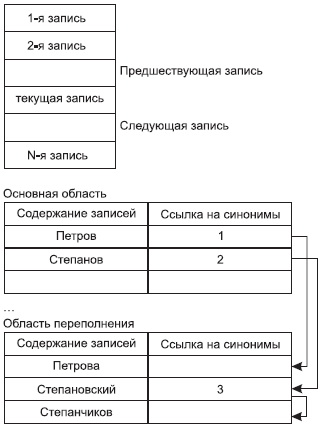
Поиск. Предположим, что имеется значение V единственного поля ключа. В том случае, когда ключ состоит из нескольких полей, V является списком значений полей ключа в фиксированном порядке. Вычислим h(V), которая даст нам номер участка, например i. Далее обращаемся в справочник и найдем первый блок участка i. После этого необходимо исследовать каждый блок участка и выяснить содержится ли в нем запись со значением ключа V. Если да, то мы нашли нужную запись, если в блоках участка записи с таким значением ключа нет, то такой записи не сущетсвует. Модификация. Пусть необходимо модифицировать одно или более полей записи со значением ключа V. Интерпретируем эту модификацию как удаление и включение. Включение. Применяем процедуру поиска. Если запись с заданным значением ключа V найдена, то ошибка, так как такая запись уже есть. Если записи нет, то находим первый свободный субблок среди блоков участка h(V). Субблок – это часть блока куда помещаются записи. Адрес такого субблока можно запомнить при операции поиска. Помещаем запись в субблок. Если свободных субблоков нет, то делаем новый пустой блок, помещаем указатель на него в заголовок предыдущего блока, а в заголовок его самого помещаем null. После этого помещаем в него запись. Удаление. Ищем. Если записи нет, то ошибка. Далее устанавливаем в заголовке блока бит, означающий, что соответствующий ему субблок свободен. Однако если существуют указатели на удаленную запись, то кроме этого бита включается бит, говорящий, что запись была удалена. Таким образом, если на этоже место будет записана другая информация, то при обработке указателя на этот субблок мы увидим, что старая запись была удалена, что будет означать, что старый указатель больше не действителен. Возможно дополнить механизм удаления так, чтобы блок, который окажется свободным после удаления также был удален. Основным требование к хэш-функции является равномерное распределение значений свертки, где одному значению хэш-функция может соответствовать одно значение ключа. Если для нескольких значений ключа получается одно и то же значение хэш-функция – коллизия. Значения ключей, которые имеют одно и то же значение хэш-функции – синонимы. Методы разрешения коллизий 1. Метод последовательного перебора. Значение хэш-функции – отправная точка для дополнительного просмотра и поиска. Запись сохраняется в первом свободном месте. 2. Стратегия разрешения коллизий с областью переполнения. Область хранения разбивается на две части: основную и область переполнения. Значение хэш-функции – адрес записи, запись заносится в основную область. Если при вставке нового значения возникает коллизия, то новая запись заносится в область переполнения на первое свободное место, а записи-синониме в основной области делается ссылка на адрес вновь размешенной записи в области переполнения. Следующая новая запись-синоним будет располагаться на втором месте списка. Т. о. для размещения новой записи требуется не более двух обращений к диску. Хорошим результатом может считаться наличие не более 10 синонимов.
3. Организация стратегии свободного размещения. Одна общая область замещения. Записи-синонимы организуются в двухсвязный список. a. Если при вставке новой записи ее адрес занят записью, которая не является заголовком списка, то она перемещается на свободное место с коррекцией указателей. А новая запись встает на ее место. b. Если адрес занят заголовком списка, то новая запись располагается на свободном месте, и для нее устанавливаются соответствующие указатели. c. Если адрес свободен, то новая запись размещается в заданном месте и становится заголовком в списке синонимов.
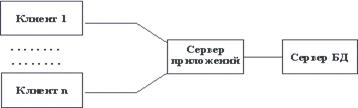
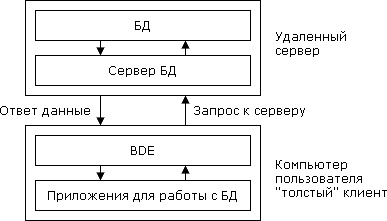
Архитектуры БД В корпоративных информационных системах по естественным причинам часто возникает потребность в распределенном хранении общей базы данных. Например, разумно хранить некоторую часть информации как можно ближе к тем рабочим местам, в которых она чаще всего используется. По этой причине при построении информационной системы приходится решать задачу согласованного управления распределенной базой данных (иногда применяя методы репликации данных). При однородном построении распределенной базы данных (на основе однотипных серверов баз данных) эту задачу обычно удается решить на уровне СУБД (большинство производителей развитых СУБД поддерживает средства управления распределенными базами данных). Если же система разнородна (т.е. для управления отдельными частями распределенной базы данных используются разные серверы), то приходится прибегать к использованию вспомогательных инструментальных средств интеграции разнородных баз данных типа мониторов транзакций. Традиционным методом организации информационных систем является двухзвенная архитектура "клиент-сервер" (рисунок 1.1). В этом случае вся прикладная часть информационной системы выполняется на рабочих станциях системы (т.е. дублируется), а на стороне сервера(ов) осуществляется только доступ к базе данных. Если логика прикладной части системы достаточно сложна, то такой подход порождает проблему "толстого" клиента. Каждая рабочая станция должна обладать достаточным набором ресурсов, чтобы быть в состоянии произвести прикладную обработку данных, поступающих от пользователя и/или из базы данных. Для того, чтобы клиенты могли быть "тощими", а зачастую и для повышения общей эффективности системы, все чаще применяются трехзвенные архитектуры "клиент-сервер" (рисунок 1.2). В этой архитектуре, кроме клиентской части системы и сервера(ов) базы данных, вводится промежуточный сервер приложений. На стороне клиента выполняются только интерфейсные действия, а вся логика обработки информации поддерживается в сервере приложений. В следующих частях курса мы рассмотрим возможные технологии организации трехзвенных архитектур . Рис. 1.1. Традиционная двухзвенная архитектура "клиент-сервер"
Рис. 1.2. Трехзвенная архитектура "клиент-сервер" с выделенным сервером приложений Заметим, что некоторые черты трехзвенности могут присутствовать и в двухзвенной архитектуре. Если, например, используемый сервер баз данных поддерживает развитый механизм хранимых процедур (например, такой, как в Oracle V.7), то можно перебросить некоторую часть логики приложения на сторону баз данных. Заметим, что механизм хранимых процедур недостаточно полно специфицирован в стандарте языка SQL. Как только вы решаетесь использовать действительно развитые средства, то немедленно привязываете свою информационную систему к конкретному производителю серверов баз данных. Развязаться будет очень трудно. Структурная схема терминов
Архитектуры БД В настоящее время применяются различные архитектуры БД и СУБД, их многообразие складывалось исторически по мере развития средств вычислительной техники и языков программирования. Все архитектуры БД имеют свои достоинства и недостатки. 1. Локальная
Локальная (персональная) архитектура СУБД означает, что БД и СУБД располагаются на одном и том же локальном компьютере. 2. Архитектура "файл-сервер"
Архитектура "файл-сервер" также является локальной, т.к. предназначена для локальной сети, включает приложение и СУБД, расположенные на компьютере пользователя, и файл БД, находящийся на локальном сервере. 3. Архитектура удаленных БД ("клиент-сервер")
Архитектура "клиент-сервер" предназначена для работы с удаленными БД, состоит из приложения клиента, расположенного на компьютере пользователя, а также удаленной БД и СУБД, располагающихся на удаленном компьютере в глобальной сети (сервере). Архитектура "клиент-сервер" может быть использована и в пределах локальной сети. Удаленные БД называют также многопользовательскими. СУБД в архитектурах "клиент-сервер" и "файл-сервер" позволяют работать с БД одновременно нескольким пользователям. БД архитектуры "клиент-сервер" позволяют работать одновременно многим пользователям и предназначены для обработки информации большого объема, поэтому их называют также "промышленными".
|
|||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 181; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.162.155 (0.011 с.) |

 Существенное свойство двоичного дерева - это то, что для каждого данного узла все узлы левее его (т.е. левый дочерний и все его потомки) содержат значения, меньше значения самого узла. Аналогичным образом все узлы правее данного содержат большие либо равные значения.
Существенное свойство двоичного дерева - это то, что для каждого данного узла все узлы левее его (т.е. левый дочерний и все его потомки) содержат значения, меньше значения самого узла. Аналогичным образом все узлы правее данного содержат большие либо равные значения.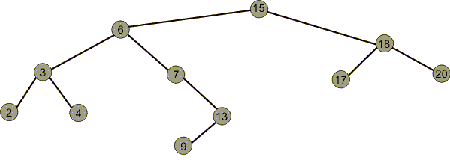



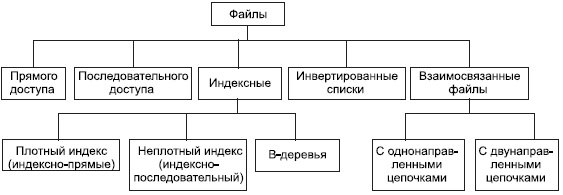 Рис. 9.1. Классификация файлов, используемых в системах баз данных
С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на внешних носителях. На рис. 9.2 представлена такая условная последовательность записей.
Так как файл — это линейная последовательность записей, то всегда в файле можно определить текущую запись, предшествующую ей и следующую за ней. Всегда существует понятие первой и последней записи файла
Рис. 9.1. Классификация файлов, используемых в системах баз данных
С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на внешних носителях. На рис. 9.2 представлена такая условная последовательность записей.
Так как файл — это линейная последовательность записей, то всегда в файле можно определить текущую запись, предшествующую ей и следующую за ней. Всегда существует понятие первой и последней записи файла
 Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа.
В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи (NZ).
Рис. 9.2. Файл как линейная последовательность записей
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа.
В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи (NZ).
Рис. 9.2. Файл как линейная последовательность записей