Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Формализация знаний в интеллектуальных системах. Данные и знанияСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте Формализация знаний в интеллектуальных системах. Данные и знания Информация ЭВМ, разделяется на процедурную и декларативную. Процедурная информация овеществлена в программах, которые выполняются в процессе решения задач, декларативная информация - в данных, с которыми эти программы работают. Стандартной формой представления информации в ЭВМ является машинное слово, состоящее из числа двоичных разрядов - битов. Машинное слово для представления данных или команд, образующих программу, могут иметь одинаковое или разное число разрядов. В последнее время для представления данных и команд используются одинаковые по числу разрядов машинные слова. Однако в ряде случаев машинные слова разбиваются на группы по восемь двоичных разрядов, которые называются байтами. Одинаковое число разрядов в машинных словах для команд и данных позволяет рассматривать их в ЭВМ в качестве одинаковых информационных единиц и выполнять операции над командами, как над данными. Содержимое памяти образует информационную базу. Параллельно с развитием структуры ЭВМ происходило развитие информационных структур для представления данных. Появились способы описания данных в виде векторов и матриц, возникли списочные структуры, иерархические структуры. В настоящее время в языках программирования высокого уровня используются абстрактные типы данных, структура которых задается программистом. Появление баз данных (БД) знаменовало собой еще один шаг на пути организации работы с декларативной информацией. В базах данных могут одновременно храниться большие объемы информации, а специальные средства, образующие систему управления базами данных (СУБД), позволяют эффективно манипулировать с данными, при необходимости извлекать их из базы данных и записывать их в нужном порядке в базу.По мере развития исследований в области ИС возникла концепция знаний, которые объединили в себе многие черты процедурной и декларативной информации.В ЭВМ знания так же, как и данные, отображаются в знаковой форме - в виде формул, текста, файлов, информационных массивов и т.п. Поэтому можно сказать, что знания - это особым образом организованные данные. Но это было бы слишком узкое понимание. А между тем, в системах ИИ знания являются основным объектом формирования, обработки и исследования. База знаний, наравне с базой данных, - необходимая составляющая программного комплекса ИИ. Машины, реализующие алгоритмы ИИ, называются машинами, основанными на знаниях, а подраздел теории ИИ, связанный с построением экспертных систем, - инженерией знаний. Особенности знаний:
Перечисленные пять особенностей информационных единиц определяют ту грань, за которой данные превращаются в знания, а базы данных перерастают в базы знаний (БЗ). Совокупность средств, обеспечивающих работу с знаниями, образует систему управления базой знаний (СУБЗ). В настоящее время не существует баз знаний, в которых в полной мере были бы реализованы внутренняя интерпретируемость, структуризация, связность, введена семантическая мера и обеспечена активность знаний
Продукционные модели Продукционная модель знания — модель, основанная на правилах, позволяет представить знание в виде предложений типа «Если (условие), то (действие)». Продукционная модель — фрагменты Семантической сети, основанные на временных отношениях между состояниями объектов. Продукционная модель обладает тем недостатком, что при накоплении достаточно большого числа (порядка нескольких сотен) продукций они начинают противоречить друг другу. В общем случае продукционную модель можно представить в следующем виде:
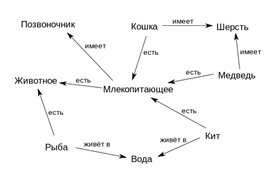
· · · · Семантические сети Семанти́ческая сеть — информационная модель предметной области, имеющая вид ориентированного графа, вершины которого соответствуют объектам предметной области, а дуги (рёбра) задают отношения между ними. Объектами могут быть понятия, события, свойства, процессы[1]. Таким образом, семантическая сеть является одним из способов представления знаний. В названии соединены термины из двух наук:семантика в языкознании изучает смысл единиц языка, а сеть в математике представляет собой разновидность графа — набора вершин, соединённых дугами (рёбрами), которым присвоено некоторое число. В семантической сети роль вершин выполняют понятия базы знаний, а дуги (причем направленные) задают отношения между ними. Таким образом, семантическая сеть отражает семантику предметной области в виде понятий и отношений.
Фрэймы Фреймы- это разбиение внутри рабочей области браузера на несколько окон [областей]. Каждое окно может содержать свой документ, иметь свои полосы прокрутки. Фреймы по своей сути очень похожи на ячейки таблицы, однако более универсальны. Фреймы разбивают веб-страницу на отдельные миникадры, расположенные на одном экране, которые являются независимыми друг от друга. Каждое окно может иметь собственный адрес. При нажатии на любую из ссылок, расположенных в одном фрейме, можно продолжать видеть страницы в других окнах. Фреймы часто использовались для навигации по веб-сайту. При этом навигационная страница располагается в одном окне, а страницы с текстом — в другом. В настоящее время использование фреймов для публичных сайтов не рекомендовано. Главным образом это связано с принципом работы поисковых машин, которые приводят пользователя к HTML-документу, являющемуся согласно задумке лишь одним из фреймов того, что автору сайта хотелось бы представить. Данный недостаток фреймов устраняется средствами JavaScript.
Онтологии верхнего уровня Пренебрегая незначительными различиями в определениях термина " онтология ", полученных из разных источников (и приведенных в лекции 1), в этом разделе под онтологией будем понимать систему, которая состоит из множества понятий, их определений и аксиом, необходимых для ограничения интерпретации и использования понятий. OpenCyc OpenCyc1 - открытая для общего пользования часть коммерческого проекта Cyc, в рамках которого создана наиболее масштабная и детализированная на текущий момент онтология в области здравого смысла. База знаний OpenCyc содержит информацию из различных предметных областей: Философия, Математика, Химия, Биология, Психология, Лингвистика и т.д.Структурно база знаний OpenCyc состоит из констант (терминов) и правил (формул), оперирующих этими константами. Правила делятся на два вида: аксиомы и выводимые утверждения. Под аксиомами в OpenCyc понимаются утверждения, которые были явно и вручную введены в базу знаний экспертами, а не появились там (или могут появиться) в результате работы машины вывода. Все утверждения или формулы в базе знаний OpenCyc фиксируются на языке CycL, выразительно эквивалентном исчислению предикатов первого порядка. DOLCE DOLCE (Descriptive Ontology for Linguistic and Cognitive Engineering) - первая из онтологий в библиотеке базовых онтологий проекта WonderWeb.Для представления своей онтологии авторы DOLCE избрали более гибкий, чем в проекте Cyc, подход: онтология фиксируется с использованием логики предикатов первого порядка. Затем описывается та часть утверждений, которая может быть представлена на языке OWL. Оставшиеся аксиомы, выраженные на языке KIF2, добавляются к OWL -описаниям в виде комментариев. Таким образом достигается выразительность уровня KIF3 и совместимость с OWL. Недостаток такого подхода в том, что приложения, не имеющие информации о действительной структуре OWL -документа, не смогут получить доступ к "закомментированным" утверждениям. SUMO SUMO (StandardUpperMerged Ontology) - онтология верхнего уровня, разработанная в рамках проекта IEEE SUO (IEEE StandardUpper Ontology) и Teknowledge. Проект претендует на статус стандарта для онтологий верхнего уровня.Аксиомы ограничивают интерпретацию концептов и предоставляют основу для систем автоматизированного рассуждения, которые могут обрабатывать базы знаний, соответствующие по своей структуре онтологии SUMO. Пример аксиомы: "Если Cявляется экземпляром процесса горения, то существуют выделение тепла H и излучение света L такие, что оба они - H и L- являются подпроцессами C ". Более сложные предложения говорят, что процессы выделения тепла и излучения света сопутствуют каждому процессу горения. Аксиомы кодируются в SUMO на формальном логическом языке SUO-KIF. 9. Онтология предметных областей на примере онтологии CIDOC CRM CIDOC CRM ("Committee on Documentation" "Conceptual Reference Model") представляет собой формальную онтологию, предназначенную для улучшения интеграции и обмена гетерогенной информацией по культурному наследию. Более конкретно, CIDOC CRM определяет семантику схем баз данных и структур документов, используемых в культурном наследии и музейной документации, в терминах формальной онтологии. Модель не определяет терминологию, появляющуюся в конкретных структурах данных, но имеет характерные отношения для ее использования. В 2007 году модель CIDOC CRM была утверждена в качестве стандарта ISO/CD 21127 и на сегодняшний день является основным международным стандартом для описания информации по культурному наследию. Основная роль CRM должна включить обмен информацией и интеграцию между неоднородными источниками информации о культурном наследии. Это стремится обеспечивать семантические определения, и разъяснения должны были преобразовать несоизмеримые, локализованные источники информации в когерентный глобальный ресурс. CRM поддерживает следующую определенную функциональность: • Сообщает разработчикам информационных систем как руководство по хорошей практике в концептуальном моделировании, чтобы эффективно структурировать и связать информационные активы культурной документации. • Служит общим языком для специалистов по проблемной области и разработчиков IT, чтобы сформулировать требования о системной функциональности относительно корректной обработки культурного содержания. • Служит формальным языком для идентификации общего информационного содержания в различных форматах, данных; в частности поддерживает реализацию автоматических алгоритмов преобразования данных от локального до глобальных структур данных без потери значения. • Усовершенствование алгоритмов естественного языка, для разрешения информации о произвольном тексте в формальную логическую форму. Онтология CIDOC CRM в явном виде представляет имплицитные связи, фигурирующие в различных концептуальных схемах данных, обобщает введенные связи и для каждой связи задает область ее значений (диапазон) и область определения (домен). Одним из преимуществ онтологии CRM является разнообразие свойств, которые точно определяют семантику того или иного понятия. Авторами модели подчеркивается тот факт, что новая сущность в CRM может быть введена только как домен или диапазон некоторого уже существующего отношения онтологии. Из онтологии CIDOC CRM заимствованы следующие типы сущностей: 1) Постоянные и Временные сущности, 2) Концептуальные и Материальные сущности, 3) Виды деятельности и их отношения с другими понятиями онтологии, 4) Агенты: Персоны, Организации, 5) Временные интервалы (промежутки времени) и местоположения.
13. RDF/XML — это заданный консорциумом W3C синтаксис[1] выражения (т.н. сериализации) графа RDF в виде документа XML. Согласно определению W3C, "RDF/XML — это нормативный синтаксис записи RDF"[2]. RDF (Resource Description Framework) — это модель данных, используемая для представления ресурсов т.н. семантической паутины (semantic web).RDF/XML рассматривается как более машиночитаемая форма записи RDF. XML/RDF синтаксис позволяет выразить RDF данные c помощью языка расширяемой разметки XML, что отчасти решает проблему интеграции RDF с Интернет - технологиями и дает возможность применять RDF для обмена метаданными в среде Интернет. Кроме того, XML/RDF-синтаксис RDF позволяет применять для обработки RDF-конструкций технологии, которые разрабатываются для XML. Для того, чтобы закодировать граф на XML, узлов и предикаты должны быть представлены в XML термины - имена элементов, имена атрибутов, элементов содержания и значения атрибутов. Предикаты являются RDF URI ссылки и можно интерпретировать либо как отношения между двумя узлами или в качестве определяющего значения атрибута (объект узла) для некоторых тему узла. RDF / XML используется XML QNames, как определено в Пространства имен в XML [XML-NS] для представления RDF URI ссылки. Все QNames есть пространства имен, который является ссылкой URI и короткое локальное имя. Кроме того, QNames может либо имеют короткий префикс или быть объявлен с объявлением имен по умолчанию. Ссылки RDF URI представлены QName определяется путем добавления локальной части названия QName после того, как пространство имен URI (ссылка) часть QName. Это используется, чтобы сократить RDF URI ссылки всех предикатов и некоторых узлов. RDF URI ссылки определении субъекта и объекта узлы также могут быть сохранены как XML значения атрибутов. Когда предикат дуги в точках RDF, который не имеет никаких дальнейших узлов,то тогда он появляется в RDF / XML как пустой <rdf:Description узла элемента rdf:about="..."></ RDF: описание > (или <rdf:Description rdf:about="..." />) эта форма может быть сокращена. Это делается с помощью ссылки RDF URI объекта узла в качестве значения атрибута XML RDF: ресурс содержащий элемент собственности и делает элемент свойства пустым. Чтобы создать полный документ RDF/XML, преобразование в последовательную форму графа в XML обычно содержится в rdf:RDF XML элемент, который становится высокопоставленным элементом документа XML. Традиционно rdf:RDF элемент также используется, чтобы объявить XML namespaces (Пространство имен), которые используются, хотя это не требуется. Когда есть только один высокопоставленный элемент узла внутри rdf:RDF, rdf:RDF может быть опущен, хотя любой XML namespaces должен все еще быть объявлен. OWL Lite OWL Lite - имеет наименьшую выразительную мощность из всех, но для решения простых задач его может быть достаточно. Данный диалект языка OWL эквивалентен некоторой дескриптивной логике (разрешимой части логики предикатов первого порядка). OWL Lite обладает важнейшим свойством - разрешимостью (т.е. задача вывода следствий из утверждений, сформулированных в этом языке, является вычислимой). Именно разрешимость (и относительно невысокая вычислительная сложность) является главной причиной использования OWL Lite для создания многочисленных практических онтологий (в медицине, биоинформатике и т.п.). Описание языка OWL Lite OWL Lite использует только некоторые из особенностей языка OWL и имеет больше ограничений на использование этих особенностей, чем OWL DL или OWL Full. Например, в OWL Lite классы могут только быть определены в терминах именованных суперклассов (суперклассы не могут быть произвольными выражениями), и могут использоваться только определенные виды ограничений класса. Эквивалентность между классами и соподчинение между классами также разрешается только между именованными классами, а не между произвольными выражениями класса. Точно так же, ограничения в OWL Lite используют только именованные классы. OWL Lite также имеет ограниченное понятие кардинальности - разрешены только кардинальности 0 или 1.
Class: Класс определяет группу индивидов, которых объединяет наличие некоторых общих свойств rdfs:subClassOf: Иерархии классов могут быть созданы, путем одного или нескольких утверждений, что данный класс - подкласс другого класса rdf:Property: Свойства могут использоваться, чтобы установить отношения между индивидами или от индивидов к значениям данных. rdfs:subPropertyOf: Иерархии свойств могут быть созданы путем одного или нескольких утверждений, что данное свойство - подсвойство одного или нескольких других свойств. rdfs:domain: Область определения (домен) свойства ограничивает индивидов, к которым это свойство может быть применено. Если свойство связывает индивида с другим индивидом, и это свойство имеет какой-то класс в качестве одного из своих доменов, то индивид должен принадлежать этому классу. rdfs:range: Диапазон свойства, ограничивающий индивидов, которые могут выступать в качестве значений этого свойства. Если свойство связывает одного индивида с другим, и это свойство имеет класс в качестве своего диапазона, то другой индивид должен принадлежать этому классу. Individual: Индивиды - это представители классов, и чтобы связать одного индивида с другим могут использоваться свойства. Формализация знаний в интеллектуальных системах. Данные и знания Информация ЭВМ, разделяется на процедурную и декларативную. Процедурная информация овеществлена в программах, которые выполняются в процессе решения задач, декларативная информация - в данных, с которыми эти программы работают. Стандартной формой представления информации в ЭВМ является машинное слово, состоящее из числа двоичных разрядов - битов. Машинное слово для представления данных или команд, образующих программу, могут иметь одинаковое или разное число разрядов. В последнее время для представления данных и команд используются одинаковые по числу разрядов машинные слова. Однако в ряде случаев машинные слова разбиваются на группы по восемь двоичных разрядов, которые называются байтами. Одинаковое число разрядов в машинных словах для команд и данных позволяет рассматривать их в ЭВМ в качестве одинаковых информационных единиц и выполнять операции над командами, как над данными. Содержимое памяти образует информационную базу. Параллельно с развитием структуры ЭВМ происходило развитие информационных структур для представления данных. Появились способы описания данных в виде векторов и матриц, возникли списочные структуры, иерархические структуры. В настоящее время в языках программирования высокого уровня используются абстрактные типы данных, структура которых задается программистом. Появление баз данных (БД) знаменовало собой еще один шаг на пути организации работы с декларативной информацией. В базах данных могут одновременно храниться большие объемы информации, а специальные средства, образующие систему управления базами данных (СУБД), позволяют эффективно манипулировать с данными, при необходимости извлекать их из базы данных и записывать их в нужном порядке в базу.По мере развития исследований в области ИС возникла концепция знаний, которые объединили в себе многие черты процедурной и декларативной информации.В ЭВМ знания так же, как и данные, отображаются в знаковой форме - в виде формул, текста, файлов, информационных массивов и т.п. Поэтому можно сказать, что знания - это особым образом организованные данные. Но это было бы слишком узкое понимание. А между тем, в системах ИИ знания являются основным объектом формирования, обработки и исследования. База знаний, наравне с базой данных, - необходимая составляющая программного комплекса ИИ. Машины, реализующие алгоритмы ИИ, называются машинами, основанными на знаниях, а подраздел теории ИИ, связанный с построением экспертных систем, - инженерией знаний. Особенности знаний:
Перечисленные пять особенностей информационных единиц определяют ту грань, за которой данные превращаются в знания, а базы данных перерастают в базы знаний (БЗ). Совокупность средств, обеспечивающих работу с знаниями, образует систему управления базой знаний (СУБЗ). В настоящее время не существует баз знаний, в которых в полной мере были бы реализованы внутренняя интерпретируемость, структуризация, связность, введена семантическая мера и обеспечена активность знаний
Продукционные модели Продукционная модель знания — модель, основанная на правилах, позволяет представить знание в виде предложений типа «Если (условие), то (действие)». Продукционная модель — фрагменты Семантической сети, основанные на временных отношениях между состояниями объектов. Продукционная модель обладает тем недостатком, что при накоплении достаточно большого числа (порядка нескольких сотен) продукций они начинают противоречить друг другу. В общем случае продукционную модель можно представить в следующем виде:
· · · ·
|
||
|
|
Последнее изменение этой страницы: 2016-09-20; просмотров: 928; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.102 (0.011 с.) |

 , где:
, где: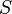 — описание класса ситуаций;
— описание класса ситуаций; — условие, при котором продукция активизируется;
— условие, при котором продукция активизируется; — ядро продукции;
— ядро продукции;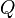 — постусловие продукционного правила.
— постусловие продукционного правила.