
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Результаты измерения массы тела 7-летних мальчиков города N в 2000 г.Содержание книги
Поиск на нашем сайте
В сгруппированном вариационном ряду центральная варианта рассчитывается как полусумма начальных вариант соседних интервалов.
Выводы: 1. Средняя масса тела 7-летних мальчиков в городе N в 2000 г. составляет 24,0 кг. 2. σ= ±4,68 кг. 3. Величина коэффициента вариации, равная 19,5%, свидетельствует о среднем разнообразии признака, приближающемся к сильному. Таким образом, можно считать, что полученная средняя величина массы тела является достаточно представительной (типичной) для изучаемой совокупности. По сравнению с 1990 г. в 2000-м отмечается более значительная вариабельность массы тела у мальчиков 7 лет (4,68 кг против 3,6 кг). Аналогичный вывод вытекает и из сопоставления коэффициентов вариации (C в 1990 г. равен (3,6*100)/23,8 =15,1%).
Стандартная ошибка среднего. Случайные ошибки выборок возникают за счет того, что для анализа всей совокупности используется только ее часть. Хотя выборочный метод и позволяет обоснованно судить о средней арифметической некоторого количественного признака генеральной совокупности по средней арифметической, исчисленной по выборке, это, однако, не означает, что выборочная средняя совпадает с генеральной средней. Она, как правило, в той или иной степени от нее отличается. Величина ошибки выборки представляет собой разность между генеральной и выборочной средними. Ошибки выборки различны для каждой конкретной выборки и в принципе могут быть обобщенно охарактеризованы с помощью средней из всех таких отдельных ошибок. В математической статистике получены формулы, которые позволяют приближенно вычислить среднюю ошибку выборки, основываясь на данных только той выборки, которая имеется в распоряжении исследователя. Стандартная ошибка среднего отражает точность оценки среднего значения признака в популяции по его выборке. Небольшая стандартная ошибка (существенно меньше соответствующего среднего значения) означает достаточно точную оценку. Стандартная ошибка уменьшится, т. е. оценка станет более точной, если объем выборки увеличится или данные имеют небольшое рассеяние (дисперсию). При неограниченном увеличении объема выборки стандартная ошибка среднего обращается в 0. Следовательно, эта величина не имеет никакого биологического смысла. Cтандартная ошибка среднего может быть найдена по формуле: где
Доверительный интервал Выборка из популяции позволяет получить точечную оценку интересующего нас параметра и вычислить стандартную ошибку для того, чтобы указать точность оценки. Следует отметить, что для большинства исследований стандартная ошибка как таковая неприемлема, поскольку она, в отличие от стандартного отклонения, не отражает вариабельности в значениях данных. Гораздо полезнее объединить эту меру точности с интервальной оценкой для параметра популяции. Для этого нужно вычислить доверительный интервал (ДИ), который дает вероятное значение верхней и нижней границ оцениваемой неизвестной величины, что позволяет заявить: «Я утверждаю, что точное значение неизвестной величины с определённой вероятностью (чаще всего эта вероятность составляет 0,95) находится между этими двумя числами». Обычно доверительные интервалы показывают, насколько надежной в действительности является статистическая оценка. Например, утверждение, что в результате проведения лечебных мероприятий у группы больных среднее значение АД = 119,5 мм рт.ст. содержит некоторую определенную информацию. Однако утверждение, что врач на 95% уверен в том, что истинное (среднее популяционное) АД будет находиться в пределах от 115 до 125 мм рт.ст., позволяет сделать гораздо более глубокие выводы об эффективности лечения. Доверительный интервал визуально удобно представлять в виде ящика с усами. Ящик с усами (англ. box-and-whiskers plot, box plot) – график, компактно изображающий одномерное распределение вероятностей. Несколько таких ящиков можно нарисовать бок о бок, чтобы визуально сравнивать одно распределение с другим. В случае нормального распределения «ящик» рисуется на промежутке
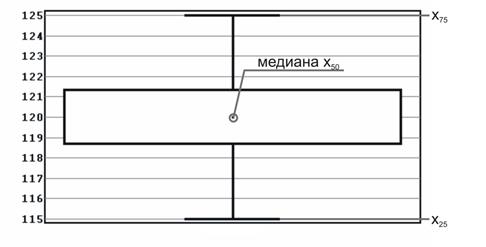
Рис. 1. Доверительный интервал для среднего в случае нормального распределения. В случае распределения, отличного от нормального, вычисляют медиану x50, квартили (x25, x75) и статистически значимый диапазон — например: «Ящик» рисуется от квартиля до квартиля, внутри него проводится риска – медиана. «Усы» тянутся от квартилей до статистически значимых крайних точек x1 и x2. Не входящие в статистически значимый диапазон точки (выбросы) изображаются отдельно (рис. 2).
Рис. 2. Доверительный интервал для среднего (медианы) в случае распределения, отличного от нормального.
Доверительные интервалы представляют оценку в некоторой перспективе и позволяют избежать необходимости указывать одно и то же число как точное значение, в то время как фактически в биологии это число точным никогда и не является. При интерпретации ДИ исследователь формулирует следующие вопросы: 1. Насколько широк ДИ? Широкий ДИ указывает на менее точную оценку, узкий - на более точную оценку. 2. Какой клинический (биологический) смысл можно извлечь из рассмотрения ДИ? Верхние и нижние пределы показывают, будут ли результаты клинически (биологически) значимы. 3. Включает ли ДИ какие-либо значения, представляющие особый интерес? Можно проверить, попадает ли вероятное значение для параметра популяции в пределы ДИ. Если да, то результаты согласуются с этим вероятным значением. Если нет, то маловероятно (для 95% ДИ шанс меньше 5%), что параметр имеет это значение. 1. Способ оценки достоверности с помощью определения ошибок репрезентативности Средняя ошибка средней арифметической величины определяется по формуле:
Ошибка относительного показателя определяется по формуле:
q = (100 – p) при p, выраженном в %; или (1000 – p) при p, выраженном в % о; (10 000 — p) при p, выраженном в % оо и т.д. При числе наблюдений меньше 30 ошибки репрезентативности определяются, соответственно, по формулам:
Результат считается достоверным (Р или
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-09-19; просмотров: 285; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.217.241.235 (0.008 с.) |


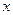


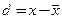
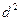
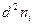
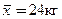




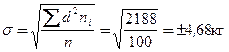

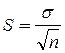
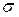 – среднее квадратическое отклонение,
– среднее квадратическое отклонение, 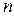 – объем выборочной совокупности.
– объем выборочной совокупности.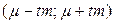 , где t – коэффициент Стьюдента – величина, зависящая от объема выборки (или соответствующего числа степеней свободы) и выбранного уровня доверительной вероятности, определяется по таблицам распределения Стьюдента; а m – стандартная ошибка среднего. Внутри «ящика» проводится риска – среднее арифметическое
, где t – коэффициент Стьюдента – величина, зависящая от объема выборки (или соответствующего числа степеней свободы) и выбранного уровня доверительной вероятности, определяется по таблицам распределения Стьюдента; а m – стандартная ошибка среднего. Внутри «ящика» проводится риска – среднее арифметическое 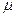 (рис. 1).
(рис. 1).
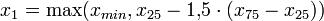 ;
; 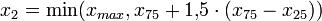 .
.
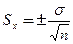 , где σ - среднеквадратическое отклонение; n - число наблюдений.
, где σ - среднеквадратическое отклонение; n - число наблюдений.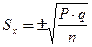 , где p — показатель, выраженный в %, % о,% оо и т.д.
, где p — показатель, выраженный в %, % о,% оо и т.д.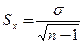 и
и 
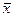 ), если он, соответственно, превышает удвоенную или утроенную ошибку репрезентативности:
), если он, соответственно, превышает удвоенную или утроенную ошибку репрезентативности: 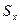 ; Р≥2-3
; Р≥2-3 


