Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Кластеризация автомобилей в модуле Cluster Analysis (Кластерный анализ)Содержание книги
Поиск на нашем сайте
Шаг 1. В рабочем окне Statistica выберете название модуля – Cluster Analysis (Кластерный анализ),высветите его имя и щелкните на его имени (рисунок 16.1).
Рисунок 16.1 – Запуск модуля Кластерный анализ На экране появится стартовая панель модуля Claster Analysis (Кластерный анализ) (рисунок 16.2).
Рисунок 16.2 – Стартовая панель модуля Кластерный анализ Шаг 2. Стандартным образом, нажав кнопку Open Data, откройте окно выбора файла (рисунок 16.3).
Рисунок 16.3 – Выбор файла с данными об автомобилях Шаг 3. Выберите в этом окне файл Cars.sta, как показано на рисунке, и два раза нажмите левую кнопку мышки. Файл выбран, и вы вернетесь обратно, в стартовую панель модуля. В рабочем окне, сзади стартовой панели, вы видите открытый файл с данными (рисунок 16.4).
Рисунок 16.4 – Файл Cars.sta с данными автомобилей разных марок Изинформации в верхней части окна вы видите, что в файле Cars.sta записаны цена автомобиля, технические характеристики, количество миль, пройденных на одном галлоне бензина. Всего в файле содержатся данные о 22 машинах разных марок. Марки машин – это случаи. Переменные в этом файле: - PRICE – цена; - ACCELE – HANDLI – технические характеристики; - MILAGE – расход горючего (количество миль, пройденных на одном галлоне бензина). Все характеристики машин уже стандартизованы: например, из значений переменной price вычтена средняя цена и разность поделена Задача состоит в том, чтобы разбить автомобили на несколько групп, в которых автомобили мало отличаются друг от друга (существенно меньше, чем в целом в совокупности). Задача эта сложна, так как сравниваются машины не по какому-то одному параметру, а по нескольким параметрам одновременно. Вы видите, что по одним характеристикам одни машины близки друг к другу, по другим – нет. В конечном итоге разбиение на группы – тоже не самоцель. Конечно, число параметров можно увеличить. Очевидно, разбив машины на группы, можно лучше в целом представить их совокупность, с тем, чтобы затем более обоснованно принимать решение, например при покупке или обмене одной машины на другую. Если бы машины сравнивались по одному параметру, например по расходу горючего, то, наверное, следовало бы выбрать машину с меньшим расходом топлива на одну милю. Все машины были бы упорядочены в одну линию, и задача не представляла бы проблем. Однако параметров несколько, и ситуация существенно усложняется. Посмотрите на стартовую панель. В главной ее части находится список методов кластерного анализа, реализованных в Statistica. Шаг 4. В списке методов высветите k-means (k-средних) Диалоговое окно метода k-means появится на экране (рисунок 16.5).
Рисунок 16.5 – Диалоговое окно метода k-means Шаг 5. Начните работать в данном окне. Прежде всего, выберите переменные для анализа. Нажмите кнопку Variables (Переменные) в левом верхнем углу текущего окна и откройте диалоговое окно: Select variable for the analysis (Выбрать переменные для анализа) (рисунок 16.6).
Рисунок 16.6 – Выбор переменных для кластерного анализа
Так как машины разбиты на группы и учитываются все параметры, то нажмите вначале кнопку Select All (Выбрать все),а затем нажмите кнопку OK. Шаг 6. Посмотрите далее на поле Cluster (Кластер),находящееся ниже кнопки Variables (Переменные). Нажав на стрелку в этом поле, выберите пункт меню Cases (Случаи). Альтернативный выбор был бы Variables (Переменные). Так следует поступить, если нужно кластеризировать переменные. В данном примере кластеризируются машины, которые являются случаями в исходном файле данных, поэтому выбирается пункт Cases. Шаг 7. В поле Number of clusters (Число кластеров) нужно определить число групп, на которые необходимо разбить автомобили. Запишите в это поле число 3. Таким образом, машины разбиваются на 3 кластера. Шаг 8. В строке Number of iterations (Число итераций) задается максимальное число итераций, используемых при построении классов. Задайте, например, число 11. Шаг 9. В строке Missing data задается способ обработки пропущенных значений в данных (например, для какой-то машины отсутствует значение некоторого параметра). В данном примере пропусков в данных нет и обработки пропущенных значений не происходит. Группа опций Initial cluster centers позволяет задать начальные центры кластеров. Сделайте установки, как показано на рисунке 16.5. Шаг 10. После того как все установки сделаны, нажмите кнопку ОК в верхнем правом углу окна k-means Clustering и запустите вычислительную процедуру. Шаг 11. Спустя несколько секунд после нажатия кнопки ОК в
Рисунок 16.7 – Окно результатов кластеризации машин В верхней части окна записана информация: число переменных, Кнопки в нижней части окна позволяют провести анализ результатов кластеризации. Кнопка Analysis of variation (Дисперсионный анализ) позволяет просмотреть таблицу дисперсионного анализа. Кнопка Cluster Means&Euclidean Distances позволяет вывести таблицы, в первой из которых указаны средние для каждогокластера (усреднение производится внутри кластера), во второй указаны евклидовы расстояния и квадраты евклидовых расстояний между кластерами. Кнопка Graph of means позволяет посмотреть средние значения для каждого кластера на линейном графике. Кнопка Descriptive Statistics for each clusters открывает электронную таблицу с описательными статистиками для каждого кластера (среднее, дисперсия и т. д.) Кнопка Save classifications and distances позволяет сохранить результаты классификации в файле Statistica для дальнейшего исследования. Шаг 12. Следует посмотреть, как распределились машины по кластерам. Нажмите для этого кнопку Member of each На экране появятся 3 электронные таблицы с названиями машин, отнесенных к определенным кластерам (рисунки 16.8 — 16.10).
Рисунок 16.8 – Первый кластер
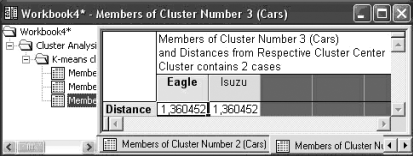
Рисунок 16.9 – Второй кластер
Рисунок 16.10 – Третий кластер В строках таблиц указано расстояние от каждой машины до центра кластера. Шаг 13. Нажмите на кнопку Cluster means&Euclidean distances. На экране появится таблица, в которой даны евклидовы расстояния
Рисунок 16.11 – Расстояния между кластерами Из таблицы вы видите, что расстояние между первым и вторым кластером 0,969, а например, между вторым и третьим – 1,876. Над диагональю в таблице даны квадраты расстояний между кластерами. Шаг 14. С помощью кнопки Graph of means (График средних) строятся следующие графики средних значений характеристикмашиндля каждого кластера (рисунок 16.12).
Рисунок 16.12 – График средних для каждого кластера Закроем окно результатов и вернемся в начальное окно метода Изменим переменные для анализа. Шаг 15. Нажмите кнопку Variables (Переменные)в левом верхнем углу текущего окна и откройте диалоговое окно: Select variables for the analysis. Сделайте в нем установки, как показано на рисунке 16.13 (выберем теперь только 3 параметра, характеризующих машины).
Рисунок 16.13 – Выбор части переменных для кластерного анализа методом k-средних Шаг 16. Повторите действия, описанные ранее. Нажмите кнопку Graph of means (График средних), постройте следующие графики средних значений характеристик машин для каждого кластера
Рисунок 16.14 – График средних для новых кластеров Заметьте, что состав групп изменился. Теперь машины более отчетливо группируются. Пожертвовав размерностью, сократили Поэкспериментируйте с этими данными. Возможно, вам удастся найти оптимальную кластеризацию. После того как вы поработаете с этим примером, обязательно попробуйте расклассифицировать другие свои собственные данные. В системе реализованы также и другие методы кластеризации, в частности, так называемый two-way joining, в котором кластеризируются случаи и переменные одновременно. Шаг 17. Если вы воспользуетесь Joining (tree clustering), то сможете увидеть дендрограмму, или дерево объединения (рисунок 16.15), о котором говорилось вначале.
Рисунок 16.15 – Дерево объединения машин разных марок в кластер методом одиночной связи
|
||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 755; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.135.193.166 (0.006 с.) |