Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Режим работы с выделенным серверомСодержание книги
Поиск на нашем сайте
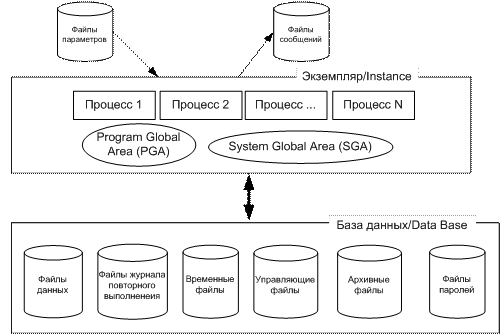
Основные понятия: база данных, система управления базами данных, экземпляр базы данных, архитектура клиент/сервер СУБД, архитектура СУБД ANSI-SPARC, СУБД и модель OSI/ISO, 12 правил Кодда, компоненты СУБД, основные функции поддерживаемые современными СУБД, классификация СУБД, основные тенденции технологий СУБД, наиболее распространенные СУБД. База данных – организованная в соответствии с определенными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области. Система управления базами данных (СУБД, DBMS) – совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных. Экземпляр (instance) менеджера СУБД - логическая среда, которая характеризуется своими ресурсами и параметрами. Архитектура СУБД ANSI-SPARC
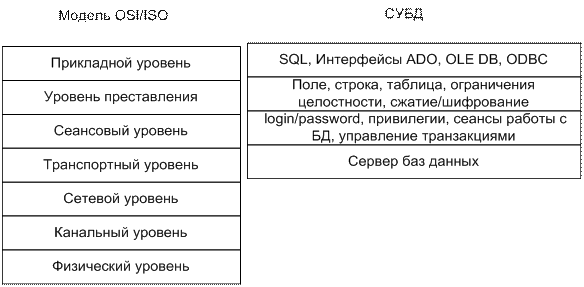
СУБД и модель OSI/ISO
СУБД, имеющие архитектуру клиент сервер, как правило, состоят из двух частей: - клиент (набор интерфейсных модуле и утилит); - сервер (ядро, языковый процессор, подсистема поддержки времени исполнения). 12 правил Кодда: 0) Реляционная СУДБ должна полностью управлять базой данных через ее реляционные возможности; 1) Информационное правило (явное представление данных): вся информация в базе данных должна быть организована как значения в таблицах (таблица атомарных ячеек, нет порядка строк); 2) Гарантированный доступ к данным: все данные должны быть доступны по имени таблицы, первичному ключу и имени столбца; 3) Поддержка пустых значений: наличие значения NULL;
4) Поддержка реляционного каталога (словаря данных): доступ к словарю данных должен обеспечиваться в терминах реляционной модели (можно получить информацию о данных также как и сами данные); 5) Исчерпывающий язык управления данными (полнота языка управления): СУБД должна поддерживать реляционный язык полное управление данными (создание, модификацию, манипулирование, описание структур данных и правил целостности, авторизацию, транзакции и...); 6) Правило обновлений представлений (возможность модификации представлений): для любого представление должны поддерживаться все операции DML; 7) Наличие высокоуровневых операций манипулирования данными: Insert, Delete, Update можно выполнять для любого множества строк;
8) Физическая независимость данных:приложения не зависят от физического расположения данных и от аппаратного обеспечения компьютеров; 9) Логическая независимость данных: представление данных в приложении не должно зависеть от структуры реляционных таблиц, изменение логической структуры базы данных не должно сказываться на приложении; 10) Независимость контроля целостности:вся информация для поддержания целостности должна находится в словаре, язык для работы с данными должен автоматически выполнять проверку данных; 11) Дистрибутивная независимость является база данных распределенной или централизованной не должно влиять на приложение, перемещение базы данных не должно сказываться на приложении; 12) Неподрывность (согласованность языковых уровней): невозможность обойти правила целостности,если для доступа к данным используется низкоуровневый язык, то он не должен игнорировать правила безопасности и целостности. Компоненты: - ядро (управление внешней и оперативной памятью, журнализация); - процессор (компилятор или интерпретатор) языка базы данных (обычно вместе с оптимизатором); - подсистема поддержки времени исполнения (исполнение откомпилированных операторов языка базы данных); - сервисные утилиты. Основные функции современных СУБД: Данные Управление данными Языковая поддержка Средства безопасности Средства программирования Режимы работы Утилиты СУБД Классификация СУБД: - по поддерживаемой модели; - по степени распределенности (централизованные, распределенные); - по способу доступа (файл-серверные:Microsoft Access, Clipper, dBase, клиент-серверные: Oracle, MS SQL Server, IBM DB2, встраиваемые: SQLite, BerkeleyDB); по технологии физического хранения (во вторичной памяти, в оперативной памяти, в третичной памяти). Тенденции: - Повсеместность структурированных и не структурированных данных - Расширяющиеся требования разработчиков - Облачные (cloud) технологии - Пересмотр архитектуры серверов баз данных - Декларативное программирование для новых платформ (распараллеливание); - Взаимосвязь структурированных и неструктурированных данных; - Облачные службы данных
- Мобильные приложения.
90% данных в мире хранятся в СУБД Oracle, MS SQL Server и IBM DB2;
2. Дистрибутивы (варианты поставки) СУБД Oracle. Архитектура клиент/сервер. Переменные окружения сервера (реестр) и клиента. Основные системные пользователи СУБД, системная роль DBA, специальные системные привилегии (SYSDBA и SYSOPER). EE, SE (не более 4х процессорных разъемов), SE1 (не более 2х процессорных разъемов), PE (один пользователь), Lite (для мобильных и встраиваемых устройств), XE (бесплатная ограниченная версия). СУБД, имеющие архитектуру клиент сервер, как правило, состоят из двух частей: - клиент (набор интерфейсных модуле и утилит); - сервер (ядро, языковый процессор, подсистема поддержки времени исполнения). - SYS – генерируемый Oracle (предопределенный) привилегированный пользователь ранга администратора базы данных (АБД), который является владельцем ключевых ресурсов БД Oracle (модули Oracle, таблицы словаря БД, V$-представления словаря,...). - INTERNAL – специальный привилегированный псевдоним для пользователя SYS, который используется, как правило, для запуска и остановки экземпляра БД Oracle. - SYSTEM - генерируемый Oracle (предопределенный) привилегированный пользователь, которому принадлежат ключевые ресурсы БД Oracle (представления словаря БД, репозиторий инструментов,...). - SYSMAN -генерируемый Oracle (предопределенный) пользователь, который является владельцем всех ресурсов Enterprise Manager (EM). - DBA – предопределенная роль, которая автоматически создаётся для каждой базы данных Oracle и содержит все системные привилегии, кроме SYSDBA и SYSOPER. Должна назначаться только администраторам, которым требуется полный доступ. - SYSDBA и SYSOPER - специальные привилегии администратора, которые позволяют выполнять базовые задачи администрирования: запуск или остановка экземпляра БД; создание, удаление, открытие или монтирования базы и др. Роль DBA не включает SYSDBA и SYSOPER. Привилегии могут быть указаны при подключении (connect) пользователя к БД.
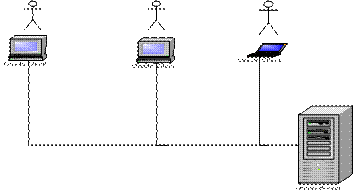
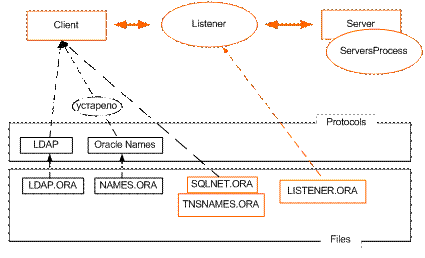
Архитектура БД под управлением СУБД Oracle: клиент/серверная архитектура, принципы (протоколы) взаимодействия клиента и сервера, абстрактная схема, основные области оперативной памяти, файлы СУБД Oracle, принципы, схема работы с выделенным сервером, схема работы с разделяемыми серверами (многопоточный режим),процессы Oracle (серверные и фоновые), слушатели и диспетчеры, параметры экземпляра Oracle, буферные пулы (DEFAULT, KEEP, RECYCLE). Клиент-сервер
Взаимодействие клиента и сервера
Абстрактная схема СУБД Oracle
Области оперативной памяти System Global Area (SGA) –системная глобальная память, состоящая из следующих компонент: § fixed sga – фиксированная часть SGA; § buffer cache – буферный кэш; содержимое кэша регулируется LRU; § log buffer – буферы журналов повтора; § shared pool – разделяемый пул; компоненты разделяемый пула: library cache – библиотечный кэш (откомпилированные SQL-операторы и их планы исполнения, разделяемые курсоры); dictionary cache – словарный кэш (хранение данных словаря БД); § java pool – используется для процедур и функций на Java; § large pool –используется в режиме MTS сервера Oracle. Program Global Area (PGA) – программная глобальная область: значения переменных для исполняемых SQL-операторов, область сортировки, характеристики обработки курсоров. Фоновые процессы ARCn – архивирование журналов; LGWR – запись журнала; MMAN – управление памятью (буферный пул, shared, Java, Large); PMON – монитор процессов(очистка после нештатного прекращения подключения, перезапуск всех процессов, устанавливает связь с Listener);
Подчиненные процессы: процессы ввода-вывода (имитация асинхронных устройств) распараллеливание запросов к базе данных. BUFFER_POOL (тип буферного пула): значения KEEP (объект по возможности навсегда останется в оперативной памяти), RECYCLE (объект удаляется сразу, как только становится не нужным), DEFAULT (повторное применение буферов по алгоритму LRU); применение KEEP и RECYCLE требует специальной DBA-настройки.
RESTRICTED SESSION ALTER SYSTEM DISABLE RESTRICTED SESSION;
Operation SHUTDOWN TRANSACTIONAL -не позволено никому подключаться к экземпляру, не позволены никакие новые транзакции, экземпляр ждет завершения текущих транзакций и разрывает соединения SHUTDOWN IMMEDIATE - не позволено никому подключаться к экземпляру, все незавершенные транзакции откатываются, после отката разрывает соединения; SHUTDOWN ABORT -- не позволено никому подключаться к экземпляру, прекращается выполнение любой SQL-команды, незавершенные транзакции не откатываются.
Создание роли
Объектные привелегии
PL/SQL: курсоры (неявные и явные), атрибуты курсоров, объявление и схема работы с явным курсором, явные курсоры с параметрами, операторы INSERT, DELETE, UPDATE в PL/SQL, курсорные переменные и их применение, курсорные подзапросы, параметры Oracle, связанные с курсорами, конструкция WHERE CURRENT OF, псевдостолбцы ROWID, ROWNUM. Неявные курсоры – содержит строку таблицы, в переменной которая типа строки таблицы. Явные курсоры – объявляем в секции declare cursor… for select … Курсор Oracle – указатель на область в PGA (контекстная область) в которой хранится: 1)строки запроса, 2)число строк, 2)указатель на разобранный запрос в общем пуле. Открытие курсора –создание контекстной области PGA (создается моментальный снимок (snapshot) данных запроса). WHERE CURRENT OF – определяет только что считанную строку. ROWID-двухбайтовая величина, которая соответствует физическому положению любой строки БД. ROWNUM-используется для ограничения кол-ва выводимых записей
24. PL/SQL: исключения, встроенные исключения и пользовательские исключения, генерация (RAISE, RAISE_APPLICATION_ERROR) и обработка исключений, порядок распространения исключений. Исключение – прерывание, которое возникает при наступлении какого-либо события. Встроенное исключение – исключение которое определено в СУБД. Пользовательское исключение – исключение, которое определил пользователь. RAISE- инициализация именованного исключения.
RAISE_APPLICATION_ERROR- создает собственное сообщение об ошибке.
Типы ошибок: 1) ошибки компиляции (уровнем сообщений можно управлять); 2) ошибки времени выполнения (могут быть обработаны). Если используется динамический SQL, то можно обработать ошибку компиляции, т.к. компиляция исполняется во время исполнения. Исключительная ситуация – событие, возникающее в программе и требующее незамедлительной обработки. Два типа исключительных ситуаций: 1) определяемые пользователем; 2) предопределенные (стандартные). 25. PL/SQL:константы, %TYPE, %ROWTYPE, записи (RECORD) и их применение, вложенные записи, присваивание записей. %TYPE – используется для объявления переменной того же типа что и строка в необходимой таблице. %ROWTYPE – используется для объявления записи того же типа, что и строка в необходимой таблице, представлении или курсоре. Тип данных записи (RECORD) – тип данных, инкапсулирующий в себе несколько переменных одного или нескольких типов. Триггеры: DLL/DML – триггеры, BEFORE/AFTER-триггеры, триггеры уровней строки и оператора, необходимые привилегии, операторы создания, предикаты INSERTING, UPDATATING, DELETING, INSTEAD OF-триггеры, NEW/OLD-префиксы, системные (DDL) триггеры. Триггер базы данных: особый вид именованных блоков PL/QL (особый вид процедур) которые срабатывают (firing – стрелять, запускать) по запускающему их событию. Триггер базы данных: выполняется под правами создателя триггера. Запускающие события: DML – события, системные события. Применение триггеров: для реализации сложных ограничений целостности базы данных; для аудита (контроля хранимой и изменяемой информации – дельного аудита); для автоматического оповещения программ о произошедших событиях; Типы триггеров: DML – триггеры, триггеры замещения instead-of), системные триггеры. Привилегии на триггер: назначаются напрямую USER у, а не через роль. CREATE TRIGGER (создавать, удалять изменять в своей подсхеме); CREATE ANY TRIGGER (создать любой триггер в любой схеме, кроме SYS, не рекомендуется для словаря, не разрешает менять текст триггера); ALTER ANY TRIGGER (разрешать, запрещать, изменять, компилировать, любые, кроме SYS-триггеров, триггеры); DROP ANY TRIGGER (удалять любой триггер, кроме SYS-триггеров); ADMINISTER DATABASE TRIGGER (создавать, изменять, удалять системные триггеры, должен иметь привилегию CREATE TRIGGER или CREATE ANY TRIGGER). DML-события: оператор: INSERT, DELETE, UPDAТE. DML-триггеры: только для таблиц, для представлений нельзя DML-триггеры: момент времени: AFTER (после события), BEFFORE (до события). BEFORE – до записи в журнал, AFTER – после записи в журнал. DML-триггеры: уровень: FOR EACH ROW (для каждой строки), ПО УМОЛЧАНИЮ (операторный уровень). DML-триггеры: всего типов триггеров = 28 = (7 комбинаций операторов)× 2 момента × 2 уровня. DML-триггеры: для таблицы может быть любое количество. DML-триггер – это часть транзакции: не может выдавать COMMIT/ROLBACK (может только, если в теле триггера автономная транзакция),может выдавать RAISE_SPPLICATION_ERROR. Системные триггеры: BEFORE, AFTER (момент выполнения) Системные триггеры: DATABASE, SCHEMA (уровень триггера) Системные триггеры: 1)серверные события; 2) DDL-события; 3)события сбора статистики; 4) события аудита; 5) DCL-события.
Системные триггеры: все кроме LOGOFF работают в режиме автофиксации; LOGOFF входит в транзакцию отключения. Системный триггер: может генерировать исключение RAISE.
Объектные типы и объектные таблицы и представления: понятие типа, необходимые привилегии, оператор создания и удаления типа, принцип применения в PL/SQL-коде, методы, конструкторы, перегрузка методов, статические методы, ключевое слово SELF, MAP и ORDER-методы, наследование, коллекции объектов, объектные поля и объектные таблицы, добавление (INSERT) объектов, объектные представления, функции REF,DEREF, DANGLING, VALUE. Объекты: тип, атрибуты, методы, конструкторы. Привилегии: CREATE TYPE или CREATE ANY TYPE. Объектные типы: базируются только на типах базы данных. Объектные типы: методы member(действует в рамках экземпляра объекта) Объектные типы: методы member могут перегружаться по типу и количеству и типам параметров. Объектные типы: static-методы не могут ссылаться на атрибуты объекта, они независимы от экземпляра объекта, вызов: имя_типа.имя_функции. Объектные типы: constructor всегда есть, определенный по умолчанию с числом аргументов равным числу атрибутов, можно создать свой. Конструкторы можно перегрузить. Объектные типы: SELF – ссылка на объект (автоматически передается первым параметром в функции(IN) и процедуры (IN, OUT)) Объектные типы: MAP-метод,может быть только один, используются для сравнения и сортировки объектов. Может вернуть: DATE, NUMBER, VARCHAR2, CHAR, REAL. MAP-функция может получить (и получает)только один параметр SELF. Объектные типы: ORDER-методы может быть только один, используются для сравнения и сортировки объектов. Возвращает всегда NUMBER. ORDER-функция получает два параметра SELF и сравниваемый объект. Объектные типы: у одного типа не могут быть одновременно ORDER и MAP-функции. Объектная таблица: таблица, содержащая строки-объекты; каждая строка – экземпляр объекта. Перманентные объекты: персистентные объекты Объектная таблица: имеет только один столбец объектного типа. REF ссылка на объект. (SQL Developer неправильно оказывает REF, преобразует в DEREF) REF – ссылка DEREF – раскрытие ссылки Висячий тип данных REF. Объект, идентифицированный типом данных REF, может стать недоступным из-за его удалении или изменения привилегий. Такой тип данных REF называется висячим. В Oracle SQL есть предикат (с именем IS DANGLING), который позволяет проверить, не является ли REF висячим.Разыменовывание типа данных REF. Доступ к объекту, на который ссылается тип данных REF, называется разыменованием типа данных REF. Для этого в Oracle предусмотрен оператор DEREF. Разыменование висячего REF приводит к появлению объекта с пустым значением
Loader SQL*Loader инструмент для загрузки данных из внешних файлов в таблицы БД ORACLE. SQL*Loader обрабатывает широкое разнообразие форматов входных файлов и дает вам возможность управлять загрузкой записей в таблицы ORACLE. SQL*Loader загружает данные в различных форматах, выполняет фильтрацию (выборочную загрузку записей в зависимости от значений данных), и может загружать несколько таблиц одновременно. Во время выполнения SQL*Loader формирует детальный файл отчета со статистикой загрузки и может также создавать файл отброшенных записей (записи, отброшенные из-за ошибок в данных) и файл пропущенных записей (записи, которые не соответствуют критерию выбора). Утилита загрузки SQL*Loader обладает следующими возможностями: 1. Загрузки данных по сети. 2. Загрузки данных из нескольких файлов данных в течение одной операции загрузки. 3. Загрузки данных одновременно в несколько таблиц одной операцией загрузки. 4. Указания символьного набора данных. 5. Выборочной загрузки данных (можно загружать записи в зависимости от значений отдельных полей). 6. Изменять данные перед их загрузкой, используя функции SQL. 7. Генерации уникальных последовательных значений ключа в указанных столбцах. 8. Загрузки данных с диска, кассеты или именованного шлюза. 9. Генерации замысловатых отчетов об ошибках, которые могут значительно помочь в локализации ошибок. 10. Загрузки сколь угодно сложных объектно-реляционных данных. 11. Для загрузки данных типа LOB и коллекций из вспомогательных файлов данных. Чтобы загрузить данные из внешних файлов в БД ORACLE, нужно подготовить для SQL*Loader входную информацию 2 типов: сами данные и управляющую информацию, описывающую, как выполнять загрузку. Данные, загружаемые в БД ORACLE, должны находиться в файлах на диске. Эти файлы данных SQL*Loader должны распознаваться при загрузке. Информация для этого находится в управляющем файле. Данные и управляющая информация может быть подготовлены в отдельных файлах или вместе в одном и том же файле. Контрольный файл Назначение этого файла – описать данные, которые должно быть загружены. Например, он описывает: § имена файлов данных § формат файлов данных § поля данных в этих файлах § как загружать данные в таблицы (какие таблицы и колонки должно быть загружены). Некоторая информация является обязательной (где найти данные и как они соответствуют таблицам БД), однако имеется также много опций для описания и манипулирования данными. Например, инструкции могут включать указание, как форматировать или фильтровать данные, или как генерировать уникальный № ID. Выходная информация 1. Файл отчета (log file) 2. Файл отброшенных записей (bad file) 3. Файл пропущенных данных Порядок загрузки данных 1. Создать таблицу в которую будут загружаться данные 2. Создать файл данных в своем текущем рабочем каталоге. Данные в файле должны быть разделены. Роль разделителей могут играть любые знаки препинания. Содержимое файла может быть следующим: "Абалхассанбейнги Араш";"Магистрант";"Факультет технологии органических веществ\Магистранты";Абалхассанбейнги Араш.bmp 3. Создать контрольный файл SQL*Loader формата ctl в своем текущем рабочем каталоге. Его можно создать в любом текстовом редакторе. Содержимое файла: LOAD DATA INFILE personal.txt --имя файла с данными INTO TABLE personal --имя таблицы REPLACE -- метод загрузки --задается что разделителем является “;” FIELDS TERMINATED BY ';' OPTIONALLY ENCLOSED BY '"' (fio, jobtitle, subdn, img FILLER CHAR(100), photo LOBFILE (img) TERMINATED BY EOF ) Следует отметить, что колонки содержащие имя файла отмечены как FILLER, они не загружаются, но используются при определении LOBFILE, для определения места содержания LOB информации. Методы загрузки: Ø INSERT Метод используемый по умолчанию. При этом предполагается, что таблица перед загрузкой пустая. Если в таблице есть строки данных, то выполнение загрузки будет прекращено. Ø APPEND Этот метод позволяет добавлять строки в таблицу таким образом, чтобы они не оказывали воздействия на уже существующие строки данных. Ø REPLACE При использовании этого метода вначале удаляются все имеющиеся в таблице строки, а затем загружаются новые.
4. Из текущего рабочего каталога выполняется следующая команду SQL*Loader в приглашении командной строки
sqlldr имя_пользователя/пароль CONTROL=контрольный_файл.ctl
IMP/EXP, PUMP Утилита экспорта exp.exe Представляет собой исполняемый модуль, который находится в каталоге определенным переменной ORACLE_HOME. Утилита читает базу данных, включая словарь данных, и записывает результаты в двоичный файл, который именуется как файл дампа экспорта (export dump file). В данном смысле можно экспортировать всю базу данных, конкретных пользователей (схемы) или конкретные таблицы вашей БД. В процессе экспорта, вы можете определиться есть ли необходимость экспортировать связанную с таблицами информацию словаря данных, такую как привилегии, индексы и ограничения. Созданный утилитой экспорта файл, будет содержать команды необходимые для полного восстановления всех выбранных объектов. Можно осуществлять полный (complete) экспорт всех таблиц БД, или только тех, которые были изменены, со времени последнего экспорта. Во втором случае экспорт будет инкрементальным или кумулятивным. Инкрементальный (incremental) экспорт приведет к записи всех таблиц изменившихся со времени последнего экспорта, а кумулятивный (cumulative) - всех таблиц изменившихся со времени последнего полного экспорта. Также утилита предоставляет вам возможность сжимать свободные экстенты сильно фрагментированных сегментов данных. Например, когда какая-либо схема более менее сформировалась можно уничтожить ее табличное пространство предварительно все слив в экспорт, а далее восстановив табличное пространство импортировать данные. Для работы с данным инструментом пользователь Oracle должен обладать привилегиями dba. Формат исполнения команд выглядит таким образом: exp … parameter_name = value …, exp – имя утилиты, parameter_name – список параметров с указанными значениями value. Утилита импорта imp.exe Утилита импорта тоже представляет собой исполняемый модуль, как и exp.exe. Однако применяется она для импорта данных в БД. Это означает, что imp.exe считывает двоичный дамп файл, созданный при экспорте утилитой exp, и запускает все находящиеся в нем команды на исполнение. Формат исполнения ничем не отличается от exp. Отличие заключается лишь в списке параметров. Утилита экспорта expdp.exe Утилита экспорта Oracle Pump позволяет экспортировать данные и метаданные в набор файлов операционной системы. Набор файлов дампа состоит из одного или нескольких файлов, содержащих табличные данные, метаданные объектов базы данных и управляющую информацию. Эти файлы записываются в специальном бинарном формате, поэтому они могут быть импортированы только impdp.exe. Необходимо заметить, что данные утилиты являются более совершенными по сравнению с традиционными утилитами exp и imp. В поставку Oracle они входят начиная с версии Oracle Database 10gR1. К основным нововведениям можно отнести: • Существенные архитектурные и функциональные усовершенствования. • Поддержка внешних таблиц и предоставление PL/SQL API. • Один поток expdp примерно в два раза быстрее exp. • В отличие от утилит IMP и EXP, все файлы Data Pump создаются на сервере Oracle, а не на клиентской машине. • Возможность параллельного выполнения извлечения или загрузки данных. Так как файлы дампа записываются сервером базы данных, а не самой помпой данных (клиентом), то необходимо создать объекты с типом directory, для тех каталогов, в которые эти файлы будут записаны. Объектdirectory - это объект базы данных, который является синонимом соответствующего каталога в файловой системе сервера. Можно также осуществлять экспорт по сети. При этом, данные из экземпляра базы данных записываются в набор файлов дампа на сервере. Утилита импорта impdp.exe Помпа данных импорта позваляет импортировать набор файлов дампа в целевую базу данных Oracle. Набор файлов дампа может быть импортирован в ту же самую базу данных, откуда был произведен, или в другую базу данных Oracle на другой системе. При импорте по сети, данные загружаются в целевую базу данных из базы-источника прямо по сети, минуя стадию файлов дампа. С помощью этого механизма можно запускать экспорт и импорт параллельно, минимизируя время, необходимое для всей этой операции. По сравнению с утилитой imp impdp в 15-45 раз быстрее. Нужно сказать, что данное отличие явно заметно при импорте очень большого объема данных.
JOB, SHEDULE Это может быть и блок PL/SQL, и хранимая процедура, и внешняя процедура на C или JAVA.Частота выполнения задается или как однократное задание или регулярное. Важное свойство пакета – задание попадает в очередь только после фиксации транзакции. То есть, если задание включено в транзакцию, а транзакция подверглась откату, то задание выполняться не будет. Управление фоновыми заданиями реализуется отдельными серверными процессами (SNP), которые должны быть запущены, прежде чем будут активизированы задания. Эти процессы активизируются с установленной периодичностью, просматривают очередь и выполняют те задания, у которых настало время активизации. Одновременно может работать до 10 процессов SNP, которые являются неотъемлемой частью нашего экземпляра. Поэтому сначала необходимо установить количество фоновых процессов для выполнения наших заданий. ALTER SYSTEM SET JOB_QUEUE_PROCESSES=NN, где NN – желаемое количество процессов (допустимо от 0 до 10). NN зависит от интенсивности использования пакета. Если у вас много снапшотов, различных заданий, то может потребоваться увеличение NN. Еще один параметр инициализации JOB_QUEUE_INTERVAL интервал активизации фоновых процессов в секундах. Допустимо от 1 до 3600. Основные методы: · DBMS_JOB. SUBMIT – создание задания · DBMS_JOB.ISUBMIT – создание задания с указанием номера · DBMS_JOB.INSTANCE – выбор экземпляра для выполнения · DBMS_JOB.REMOVE – удаление задания · DBMS_JOB.RUN – немедленное выполнение · DBMS_JOB.CHANGE – изменение параметров · DBMS_JOB.WHAT – изменение задания · DBMS_JOB.NEXT_DATE – изменение следующей даты выполнения Задания выполняются последовательно в соответствии с заданным временем выполнения. Если у вас один процесс обработки очереди (смотрите параметр JOB_QUEUE_PROCESSES в init.ora), а в очереди у вас несколько заданий на одно и тоже время, то очевидно задания будут выполняться последовательно, с некоторым смещение относительно заданного времени. И к тому же очередь просматривается периодически, например 30 сек. Исходя из всего этого очевидно, что если задавать относительный момент времени (например, sysdate+1), то получим медленное смещение времени выполнения регулярного задания. Поэтому, если важно точно выполнять задание в конкретный момент времени, то используйте функцию, которая всегда возвращает фиксированный момент времени (например, trunc(sysdate)+1+2/24).
Dbms_sсhedule К версии 11 такое устройство имевшегося планировщика заданий было сочтено слишком примитивным, и в ней появился новый планировщик, DBMS_SHEDULE,значительно более проработанный. Он использует следующие основные понятия: q Schedule (расписание) q Program (программа) q Job (плановое задание = расписание + программа) В отличие от старого планировщика, в новом «программой» может быть не только блок PL/SQL, но и хранимая процедура на PL/SQL или на Java, внешняя процедура на С или даже команда ОС. Последнее означает, что Oracle отменяет необходимость использовать специфичные для разных платформ планировщики заданий ОС. Вдобавок, сам запуск заданий получил возможность учета текущей вычислительной обстановки в СУБД, а также желаемой приоритетности среди прочих заданий. Расписание (Schedule) Расписание - объект базы данных, применяемый для хранения определенного расписания выполнения заданий. Программа (Program) Программа - объект базы данных, хранящий определенный набор действий, который впоследствии будет сопоставлен расписанию.
DBLINK Database Link (dblink): объект базы данных (СУБД), предназначенный для доступа к объектам базы данных, управляемой другим сервером dblink: привилегии
Dblink: user1-user2
Dblink: shared user1-user2
Dblink: global
Секцинирвание Секционирование – метод, позволяющий хранить сегмент данных (таблица, индекс) в виде нескольких секций, причём секции-сегменты при общности логической структуры могут иметь собственные физические атрибуты. К секционированию предъявляют следующие требования: Прозрачность для пользователя (пользователь приложения не должен знать, работает ли он с секционированными данными или нет) Прозрачность для разработчика (запросы в приложении не должны специальным образом модифицироваться для работы с секционированными данными) Удобство администрирования (секционирование данных должно не осложнять жизнь администратора базы данных, а упрощать ее) Диапазонное секционирование Диапазонное (range) секционирование – это секционирование, при котором для каждой секции определяется диапазон значений ключа секционирования. Ключ секционирования в диапазонном секционировании может принимать значение даты и времени, числа или текста. Для задания диапазона используется ключевое слово less than. Используются секции небольшого, примерно равного размера. Хэш-секционирование Хэш-секционирование позволяет равномерно распределить строки между секциями, т.е. при помощи встроенной функции хэширования “разбросать” строки по разным секциям и сделать эти секции равновеликими. Равномерное распределение данных по разным дискам позволяет распределить нагрузку по вводу-выводу между дисками, избежать перегруженности отдельных блоков (например, последнего табличного блока при вставках строк или крайнего индексного блока при монотонном увеличении ключа), очень важная возможность при использовании кластерных конфигураций (RAC), организовать эффективную параллельную обработку данных путем одновременного доступа к дискам (особенно при эквисекционировании объектов). Списочное секционирование Списочное секционирование позволяет разбить таблицу по списку дискретных значений. Ключ списочного секционирования может быть только одностолбцовым, каждое ключевое значение может быть указано только в одном списке, слово DEFAULT описывает все значения, не попавшие в другие списки, NULL может быть ключевым значением. Списочные секции можно добавить, при этом должна отсутствовать секция DEFAULT, в противном случае прибегают к рассечению секции DEFAULT. Списочные секции можно удалить, слить, добавить/сократить список ключей. Композитное секционирование При секционировании большой таблицы сами секции могут оказаться достаточно крупными. Такие секции могут секционироваться по другому критерию секционирования. Такое двухуровневое секционирование называется композитным (допускается 2 уровня секционирования(секции и подсекции)). При композитном секционировании реальные сегменты хранения есть только у подсекций (секции в этом случае носят только логический, "объединительный" характер). Как правило, верхний уровень секционирования выбирается из соображений управляемости БД, уровень же подсекции обычно выбирается из соображений производительности. Эквисекционирование Объекты эквисекционированы, если они секционированы одинаковым образом (общий метод секционирования, равное количество секций, те же границы, количество, порядок и типы столбцов в ключе). Объекты могут быть эквисекционированы на одном или разных уровнях(секции, подсекции). Идентичность секций или подсекций позволяет соединять их попарно (параллельная попарная обработка может выполняться достаточно быстро, так называемые "Partition-Wise Joins", минимизируется обмен данными между параллельными процессами и узлами в RAC), локализованность проблем при управлении и сбоях. Эквисекционирование двух таблиц возможно только при общем ключе секционирования, часто вынуждает вносить ключ (столбцы) секционирования в дочернюю таблицу искусственным образом, только для целей эквисекционирования главной и подчиненной таблиц. Секционирование по ссылке Ссылочное секционирование выполняется только, если таблицы явным образом связаны ссылочными ограничениями целостности (метод и ключ секционирования подчиненной таблицы наследуются из главной). Манипуляции с секциями главной таблицы автоматически отражаются на секциях подчиненной, наблюдается каскадный эффект, если описана цепочка связанных и секционируемых по ссылке таблиц (ссылочное секционирование тоже наследуется). Системное секционирование <
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 319; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.17.77.29 (0.017 с.) |