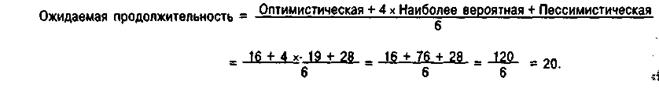Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Повторяйте пп. 2 и 4 до получения желаемого уровня продолжительности или до тех пор, пока сокращение возможно.Содержание книги
Поиск на нашем сайте
28. Вероятностный подход в оценке длительности проекта (PERT-метод) На практике не возможно, что продолжительность всех действий по проекту известна. Продолжительность можно только спрогнозировать исходя из прошлого опыта. Использование ПЕРТ позволяет проводить более сложный анализ поставленной задачи. Этот метод заключается в определении крайних сроков каждого действия и их наиболее вероятной продолжительности. Например, в таблице ниже дана наиболее вероятная, максимально возможная и минимально возможная продолжительность некоего действия. Максимальная оценка часто называется пессимистической, а минимальная — оптимистической Ожидаемую (среднюю) продолжительность этого действия можно оценить как взвешенное среднее трех оценочных показателей следующим образом:
Далее, целесообразно оценить показатель разброса (среднеквадратическое отклонение) с тем, чтобы проанализировать возможный разброс в продолжительности всего проекта. Три среднеквадратических отклонения в любую из сторон от среднего фактически захватят все из значений распределения. Отсюда, разница между максимальным и минимальным значениями в этом распределении составляет приблизительно 6 среднеквадратических отклонений.
Такого рода анализ можно провести по каждому действию, предусмотренному проектом. Ожидаемая продолжительность и среднеквадратическое отклонение продолжительности всего проекта могут быть получены путем сочетания ожидаемых значений и среднеквадратических отклонений всех критических действий. Так, если действия А, Б и В - критическими с ожидаемыми значениями ЕА, ЕБ и Ев и среднеквадратическими отклонениями σА, σБ и σв, то общая продолжительность проекта определяется следующим образом:
Основные понятия и круг проблем, история технологий текстового поиска. Технологии текстового поиска имеют дело с информацией, представленной на естественных языках. Основная единица информации в системах текстового поиска - документ - это порция информации, обладающая законченным содержанием и какого-либо рода уникальным идентификатором. Системы поиска оперируют электронными документами, хранимыми в памяти компьютеров и доступными для автоматизированной обработки в оцифрованном виде (ввод с клавы, сканирование, распознование голаса…), когда каждая литера представляющего его текста программно доступна. Классические направления в тестовом поиске — библиографический и полнотекстовый поиск. Обработка естественного языка, т.е. компьютерное решение задач, связанных с пониманием, анализом, выполнением различных операций над текстами на естественном языке, а также с их генерацией. (искусственный интеллект). Работы связанные с созданием электронных библиотек(90-е) - возникли новые направления, как обнаружение информации в глобальной компьютерной сети, текстовый поиск в Web, мультиязыковой поиск. Появляются мультимедийные системы поиска - системы более общего класса, которые имеют дело с информацией, представленной в различных средах, где содержание документов - сочетание текстовых элементов, картинок, музыки, мультфильмов… За свою историю развития технологии продвинулись к системам полнотекстового поиска - позволяют хранить огромные объемы информации, осуществлять обработку документов, выполнять алгоритмически сложные процедуры обработки хранимых коллекций документов(классификацию, кластеризацию, глубинный анализ текстов, перевод…) Новое зарождающееся направление текстового поиска связано с потоками документов. Для поиска в потоке документов необходимы новые подходы и новые методы. Формирование систем управления документами, где важная роль отводится организации групповой разработки документов, их хранения, распространения, а также технологиям текстового поиска. Краткая история в 50-х годах Разработки простейших систем. Ранние текстовые информационные системы были ориентированы на функцию поиска - информационно-поисковые системы (ИПС). Получил распространение библиографический поиск. Многие используются до настоящего времени. в 60-х годах. формируются технологии полнотекстового поиска, т.е. поиска по полному содержанию текстовых документов на естественных языках. Получил распространение контекстный поиск - поиск документов, имеющих вхождения в них заданного контекста. Позднее - грамматические формы элементов контекста, фонетическую близость слов… В 60-е годы был выполнен ряд проектов, например проект SMART (Salton's Magical Automatic Retriever of Texts) - полнотекстовый поиск на основе естественных языков, под руководством Джерарда Сэлтона в Гарвардском и Корнельском университетах(1962-1965). Важное достоинство - позволяла исследовать различные автоматизированные методы анализа текстов и оценивать качество текстового поиска, сравнивать результаты обработки запросов при различных методах поиска. «Крэнфильдские эксперименты» проведены группой Кирилла Клевердона из колледжа по аэронавтике в Крэнфильде (Англия), была предложена методология сравнения средств индексирования документов в системах текстового поиска. Результат - автоматическое индексирование не уступает по качеству ручному индексированию, продемонстрировали также полезность тестовых коллекций документов и запросов. Учреждена международная конференция по текстовому поиску TREC (Text Retrieval Conference), в 1992 в США - деятельность по сравнению возможностей различных систем текстового поиска, общему анализу состояния их разработок и определению перспективных направлений развития. Исследований 60-х годов стали основой многочисленных практических разработок систем текстового поиска. Начала формироваться индустрия коммерческого программного обеспечения для систем текстового поиска, т.е. информационно-поисковыми системами. В настоящее время проблематика текстового поиска стала довольно обширной. Значительное развитие получила функциональность систем текстового поиска. Создаются комплексные системы обработки текстов с разнообразными функциями, лишь одной из которых является текстовый поиск. Созданы новые технологии глубинного анализа текстов (Text Mining), служащим для обозначения технологий глубинного анализа данных.
|
||||
|
|
Последнее изменение этой страницы: 2016-07-14; просмотров: 226; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.164.100 (0.006 с.) |