Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Расчет уровня рисков и их влиянияСодержание книги
Поиск на нашем сайте
Результатом данной таблицы является предварительная оценка возможного ущерба от нештатных ситуаций. Данные показатели можно внести в проект в виде страховых резервов времени и денег. Однако основной задачей данных работ является не столько расчет резерва, сколько снижение затрат и оценка и сравнение затрат на профилактические работы с затратами от ожидаемого ущерба.
Снижение потерь Снижение потерь возможно за счет трех действий: профилактики (предотвращения), мониторинга (своевременного распознавания ситуации) и управления критической ситуацией (правильными действиями в случае ее возникновения). Рассмотрим более подробно каждое из них. Профилактика - некие затраты для устранения, снижения вероятности или снижения ущерба нештатной ситуации. Нередко очень трудно убедить заказчика в дополнительных затратах, особенно если угроза не очень понятна заказчику. Например, достаточно легко получить дополнительное финансирование на дополнительную проработку системы безопасности (угроза несанкционированного доступа), однако нередко очень трудно добиться обучения конечных пользователей, хотя неграмотная эксплуатация также может привести к образованию дыр в системе безопасности. И обычно только хорошо обоснованный документ с оценкой вероятности и значения ущерба может убедить заказчика в правильном распределении средств. Мониторинг означает разработку системы показателей, определяющих возникновение той или иной проблемы, и механизмов их отслеживания. Своевременное распознавание проблемы нередко позволяет минимизировать потери или свести их к нулю. Например, отслеживание текущего законодательства и своевременное распознавание принципиальных изменений позволят существенно сократить затраты на адаптацию за счет изменений ряда концептуальных решений, таких, как изменение структуры данных или разработка новых алгоритмов. В случае, если время упущено, начинают работать механизмы латания дыр, которые приводят к усложнению системы и, как следствие, росту временных затрат на решения новых задач. >Управление критической ситуацией означает документирование и регламентирование действий в случае возникновения непредвиденной ситуации. Четкое понимание действий менеджером позволяет многократно снизить отрицательный эффект. Предварительное документирование действий позволит скорректировать расчетный эффект ущерба и, как следствие, снизить суммы резервов и сделать проект более привлекательным для инвесторов и заказчиков. Также частью работ по этому направлению может быть создание механизмов смягчения критической ситуации. Например, наличие информации о квалифицированных соискателях на работу в организации будет очень кстати при неожиданном увольнении ключевого работника. Основой работ по сокращению затрат является разработка плана противодействия рискам проекта. Примером оформления данного плана может служить дальнейшее развитие таблицы рисков (табл. 18).
Таблица 18 Оформление плана противодействия рискам
Из таблицы хорошо виден эффект от контроля за рисками, и этот факт непременно поможет менеджерам максимально контролировать весь проект в целом и более аргументированно отчитываться перед инвестором и заказчиком. Однако необходимо помнить, что управление рисками носит относительный характер и все приведенные цифры в таблице условны и служат для общей оценки нестандартных ситуаций. Также необходимо помнить о динамическом изменении основных показателей проекта, что приводит к постоянному пересчету приводимых ранее величин. ----------------- Анализ уязвимости и рисков проекта с использованием PERIL. Др. Джеймс Мак-Кэффри (Dr. James McCaffrey) Загружаемый файл с кодом доступен в коллекции кода MSDN
Мета-риски Все программные проекты сталкиваются с рисками. Риск – это событие, которое может произойти или не произойти и которое вызывает потери какого-либо рода. Взаимоотношения между риском и тестированием программного обеспечения прямолинейны. Поскольку, за исключением редких ситуаций, исчерпывающее тестирование программной системы невозможно, анализ рисков раскрывает проблемы, могущие принести наибольший ущерб. Эту информацию можно использовать для помощи в расстановке приоритетов тестирования. В статье за этот месяц я представлю практические методики, которые можно использовать для определения и анализа рисков, связанных с программным проектом. Приступим же. Представьте себе гипотетическую ситуацию разработки веб-приложения ASP.NET какого-либо рода. Рис. 1 иллюстрирует некоторые из ключевых идей и проблем, связанных с анализом программных рисков. Общий процесс анализа рисков включает определение рисков, оценку того, насколько вероятен каждый из них, определение ущерба, связанного с каждым из них и сочетание информации о вероятности и ущербе в значение, именуемое степенью риска.
Согласно примеру данных с рис. 1, риск «просмотра идентификатора пользователя» имеет наибольшую степень, так что, при прочих равных условиях, тестирование в этой области вероятно стоит сделать наиболее приоритетным, чтобы предотвратить превращение риска в реальность. Но как можно определять риски? Как можно оценить вероятность риска и ущерб от него? Можно ли выполнять анализ рисков, если невозможно определить вероятность риска и ущерб от него? Хотя уже было предпринято несколько попыток формализовать и стандартизировать терминологию анализа рисков, на практике в различных областях проблем обычно используются различные термины. Я буду использовать термин «анализ рисков», когда имею в виду степень риска, получаемую умножением вероятности риска на потенциальный ущерб, а также общий процесс определения рисков программного проекта, их анализа и управления ими. Несмотря на то, что анализ рисков является ключевой частью разработки программного обеспечения, согласно моему опыту многие методики анализа рисков неизвестны за пределами сообщества тестеров программного обеспечения. Поиск по сети может дать десятки тысяч ссылок по анализу программных рисков. Однако большинство их них либо рассматривают анализ рисков на очень общем уровне и не предоставляют практических методик, либо предоставляют лишь одну конкретную методику анализа рисков и не объясняют, какое место это методика занимает в общей инфраструктуре анализа рисков. Я представлю читателям как обзор анализа рисков, так и полезные методики, которые можно немедленно применить в среде разработки программного обеспечения. В разделах этой статьи я опишу два мета-риска, типичных для всех программных проектов. Далее я представлю три способа, которыми можно определять конкретные риски, связанные с программным проектом и три способа их анализа. В частности, я представлю новую интересную методику анализа рисков, именуемую Project Exposure using Ranked Impact and Likelihood (PERIL, «Степень риска с использованием ранжированных воздействия и вероятности»). Я завершу статью кратким рассказом об управлении рисками. Думаю, что представленные здесь методики станут чрезвычайно ценным дополнением к набору средств тестирования, разработки и управления программным обеспечением читателей.
Мета-риски Два специальных типа анализа проектных рисков – это то, что я называю анализами мета рисков времени и затрат. Традиционное управление проектами определяет концепцию, носящую различные имена, включая «тройное ограничение управления проектом» и «треугольник управления проектом». Идея, если говорить кратко, в том, что практически каждый проект имеет три ограничивающих фактора: затраты, график и объем. Затраты – это деньги, которые можно потратить на проект; график – срок, за который его надо завершить; а объем – набор требуемых компонентов проекта и их качество. Три ограничения проектов носят массу псевдонимов. Например, затраты также именуются бюджетом или деньгами. График часто именуется временем или продолжительностью. А объем порой называется функциями или качеством или даже функциями/качеством. Отметьте, что последнее ограничение функций/качеств может считаться (и, на деле, часто считается) двумя отдельными ограничениями. Ключевая идея состоит в том, что изменение в любом из ограничений вероятно вызовет изменение в одном или обеих других ограничениях. Например, если ведется разработка программного приложения и проект неожиданно потребовалось завершить за более короткий промежуток времени, чем первоначально планировалось, то, вероятно, придется потратить больше денег (например, для покупки дополнительных ресурсов или использования внешних услуг для части проекта), либо урезать часть функций, либо качество. Если бюджет для проекта урезан, то, вероятно, придется увеличить время на завершение проекта, удалить часть компонентов или понизить качество проекта. При использовании парадигмы треугольника управления проектом, из того, что тестирование программ предназначено для повышения качества системы следует то, что двумя высочайшими уровнями риска в проекте является незавершение его в срок и выход за пределы бюджета. Существует относительно простой, но эффективный способ оценки общих рисков затрат и графика для программного проекта. Давайте просто взглянем на мета-риск время/график (анализ риска бюджет/затраты работает точно так же). Первым этапом в анализе высокоуровневого мета-риска является разбиение общего проекта на более мелкие и управляемые фрагменты действий. К примеру, предположим, что разрабатывается небольшой проект веб-приложения, который необходимо завершить за 30 рабочих дней. Анализ мета-риска начинается с перечисления всех действий, входящих в проект. Наиболее обычным подходом здесь является использование того, что называется структурой разделения работ (WBS), которую можно увидеть на рис. 2. Разработчик создает задачу высшего уровня, которая состоит из всего проекта. Затем эта задача разбивается на несколько меньших подзадач, обычно от трех до семи задач. Разработчик повторяет процесс, разлагая каждую подзадачу на меньшие подзадачи, пока не достигнут нужный уровень детализации для среды.
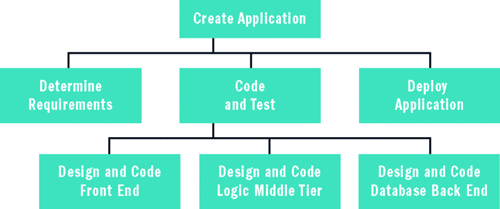
Рис. 2. Структура разделения работ Нижний уровень, задачи оконечных узлов дерева, порой именуется рабочими пакетами. Как именно разлагаются задачи и насколько детальной делается WBS, зависит от ряда факторов. Например, в среде гибкой разработки можно запросто решить, что простая структура разделения работы на два уровня в глубину отвечает потребностям. Или, при работе над очень большими, комплексными программными проектами, использующими традиционную методологию жизненного цикла разработки программного обеспечения, можно столкнуться с десятками тысяч рабочих пакетов. Небольшую WBS можно создать вручную, используя универсальные средства повышения продуктивности, такие, как Microsoft Office Excel или более изощренные средства, такие как Microsoft Office Project. WBS не содержит информации по последовательности, времени или затратам. Другими словами, WBS говорит, что необходимо сделать, но не в каком порядке и не говорит, сколько времени потратит или затрат повлечет каждая из задач. После создания структуры разделения работ, следующим этапом обычно является использование рабочих пакетов для создания того, что именуется схемой приоритетности.
Рис. 3. Схема приоритетности
Схема приоритетности добавляет информацию о последовательности. Схема, показанная на рис. 3, указывает, что задача Requirements («Требования») должна быть завершена до задачи Database Back End («Серверная часть базы данных»), которая, в свою очередь, должна быть завершена, прежде чем приступать к задачам Middle-Tier («Промежуточный уровень») и Front-End («Клиентская часть»). Последние две задачи, согласно схеме последовательности, должны быть выполнены параллельно. Наконец, как задача Middle-Tier, так и задача Front-End должны быть завершены, перед тем как приступать к работе над задачей Deploy Application («Развертывание приложения»). После создания схемы приоритетности, с ее информацией о последовательности, следующим этапом анализа мета-риска времени является оценка времени, необходимого для каждого отдельного рабочего пакета. Хотя каждое время можно оценить как единственную точку данных, лучшим подходом будет предоставление трех оценок – оптимистической оценки, наиболее вероятного предположения и пессимистической оценки. Хорошо, но откуда берутся такие оценки? Определение оценок времени и затрат – это, без преувеличения, сложнейшая часть анализа мета-рисков программного проекта. Существует много способов оценить время действия и затраты. Можно использовать исторический опыт, обоснованные предположения, замысловатые математические модели и так далее. Используемые методики будут зависеть от конкретной ситуации. Вне зависимости от используемого метода, оценка времени и затрат для набора небольших действий гораздо проще, чем для одного монолитного действия. Таблица на рис. 4 показывает пример мета-анализа рисков времени. При анализе оптимистичных, наиболее вероятных и пессимистичных данных обычно используется простое математическое распределение, именуемое бета распределением. Среднее арифметическое, или просто среднее, значение бета-распределения вычисляется так: (optimistic + (4 * best-guess) + pessimistic) / 6Так что среднее оценочное время для задачи Deploy Application таково: mean = (3 + 4*8 + 13) / 6 = 48 / 6 = 8.0 days.Следует отметить, что среднее арифметическое значение бета-распределения – это просто средневзвешенное значение чисел 1, 4 и 1: ((pessimistic - optimistic)/6)²Так что расхождение для задачи Deploy Application таково: variance = ((13 - 3) / 6)² = (10/6)² = (1.6667)² = 2.78 days²Общее стандартное отклонение для проекта – это квадратный корень из суммы расхождений действий. Таким образом, в данном примере уравнение выглядит следующим образом: std. deviation = sqrt(5.44 + 1.78 + 2.25 + 2.78) = sqrt(12.25) = 3.50 daysОтметьте, что мои расчеты не используют данные для действия разработки и кодирования логики промежуточного уровня (Design and Code Logic Middle-Tier). Поскольку это действие можно выполнить параллельно действию Database Back-End, а действие Front-End не может начаться, пока оба параллельных действия не завершились, более короткое параллельное действие (Logic Middle-Tier) не вносит прямого вклада во время, уходящее на завершение проекта. Этот тип анализа именуется методом ключевого пути (CPM) и является стандартной методикой управления проектами. С вычисленными средними данными и данными отклонения для расписания, теперь можно вычислить вероятность того, что завершение всего проекта займет дольше чем 30 дней: z = (30.00 - 28.83) / 3.50 = 0.33p(0.33) = 0.6293p(late) = 1.0000 - 0.6293 = 0.3707Сперва можно вычислить так называемую величину Z, равную объему времени, в который запланировано завершить проект (в данном случае 30 дней) минус предполагаемое время до завершения (28,83 дня), поделенному на общее стандартное отклонение задачи (3, 50 дней). Затем берется величина Z (0,33) и в таблице стандартного нормального распределения находится соответствующее значение вероятности, либо используется функция Excel NORMSDIST (0,6293). Наконец, значение вероятности вычитается из 1,0000, чтобы получить вероятность выхода проекта за временные рамки. Мы анализируем здесь лишь один «хвост» кривой распределения, поскольку нам без разницы, если проект займет меньше времени, а волнует лишь его незавершение в срок. С данными из этого примера вероятность того, что работа над веб-приложением займет дольше, чем 30 дней, составляет 0,3707 или почти 40% – довольно рискованная ситуация. Если задуматься об этом на минуту, такой результат не должен удивлять. Запланированное расписание в 26 дней разработки слишком близко к пределу проекта в 30 дней, так что для учета возможных вариантов в расписании может не хватить места для маневра. Очевидно, что результаты оценки мета-риска хороши лишь в той же мере, что и используемые данные – в данном случае, оценка времени. Если используемые оценки неверны, то никакой статистический анализ не сможет дать осмысленных результатов. Степень мета-риска выхода за пределы бюджета проекта можно оценить, используя ту же методику, которую я только что продемонстрировал для расписания. После наличия вероятности незавершения проекта в срок, можно вычислить степень риска для мета риска, если можно оценить денежные потери от задержки. В некоторых ситуациях разработчик может работать над созданием программной системы по контракту, и контракт может включать в себя хорошо определенные и существенные неустойки в случае задержки. Предположим, контракт гласит, что неустойка в случае поздней доставки составляет 10 000 долларов США. Степень мета риска составляет 10 000 * 0,3707 = 3 707 долларов США. В других случаях, потери вызванные задержкой программного проекта сложно оценить точнее чем «очень, очень большие». Но обратите внимание на то, что даже без вычисления степени риска, анализ временного мета-риска дает полезную информацию. Если изучить данные на рис. 4, можно увидеть, что задача Determine Requirements («Определить требования») отличается наибольшими расхождениями в расписании. Следовательно, простое приложение дополнительных ресурсов на раннем этапе проекта может уменьшить расхождение для задачи, что, в свою очередь, уменьшит вероятность невыполнения проекта в срок.
Определение рисков В отличие от мета-рисков времени и затрат, где события рисков могут быть определены достаточно поэтапным (хотя и отнюдь не простым) образом, путем последовательного разложения задач на меньшие подзадачи, определение рисков, в общем случае, куда менее механистично. В среде разработки и тестирования программного обеспечения существуют три основных подхода к определению рисков: на основе классификации, сценариев и спецификаций. Классификация – это просто систематический список. Подумайте над следующей аналогией. Некто собирается отправиться в авиапутешествие, так что он проходит по стандартному списоку-памятке, используемому перед каждой поездкой. Список содержит заявления или вопросы, такие как: «На месте ли мои документы?» или: «Проверил ли я, не задерживается ли мой вылет?» С течением времени многие люди и организации создали классификации программных рисков. Один такой список был создан Барри Боэмом (Barry Boehm) первопроходцем и широко известным исследователем в области рисков для программных проектов. В 1989 году Боэм определил классификацию 10 основных рисков при разработке программного обеспечения, а в 1995 году обновил список. Версия 1995 года приведена здесь: 1. Недостатки персонала 2. Расписания, бюджеты, процессы 3. Готовые коммерческие программы, внешние компоненты 4. Несоответствие требований 5. Несоответствие интерфейса пользователя 6. Архитектура, производительность качество 7. Изменения требований 8. Устаревшее программное обеспечение 9. Внешне выполняемые задачи 10. Насилие над теорией программирования Должно быть очевидно, что список 10 основных рисков Боэма не определяет риски немедленно. Вместо этого, классификация просто представляет начальную точку, с которой можно приступить к обдумыванию рисков, относящихся к проекту. Например, первый риск, «недостатки персонала», охватывает множество различных возможных рисков, относящихся к кадрам. У проекта может просто не быть достаточно программистов для создания приложения или системы. Или ключевой специалист может оставить проект на середине работы. Или у штата программистов может не оказаться необходимых технических умений для проекта. Ну, и так далее. Большинство из 10 основных категорий должны быть знакомы читателям, за исключением, возможно, 10-й категории «насилие над теорией программирования». Это, в какой-то степени, универсальная категория, охватывающая задачи, относящиеся к таким вещам как технический анализ, анализ затрат/прибылей и прототипизация. Другая часто используемая классификация рисков разработки программного обеспечения была создана Институтом разработки программного обеспечения (SEI). SEI – это один из 36 федерально спонсируемых центров исследований и разработки в США. Эти исследовательские центры являются странными, гибридными организации, которые финансируются на деньги налогоплательщиков, но продают продукты и службы. Классификация рисков при разработке программного обеспечения SEI была создана в 1993 году и содержит примерно 200 вопрос. Например, вопрос №1 таков: «Стабильны ли требования? Если нет, каков эффект этого для системы (качества, функциональности, расписания, интеграции, архитектуры, тестирования)?» Вопрос № 16: «Как определяется приемлемость алгоритмов и конструкций (прототипизация, моделирование, анализ, симуляция)?» Классификацию рисков SEI можно найти в приложении к этому документу. При определении рисков на основе сценариев разработчик представляет себя в различных ролях, создает сценарии для этих ролей и определяет, что может пойти не так в каждом сценарии. Используя ранее описанную аналогию с авиаперелетом, путешественник может в уме проследить действия, которые он будет предпринимать в поездке. Например: «Сперва я приеду в аэропорт. Затем я припаркую мой автомобиль. Затем я пройду регистрацию у стойки авиакомпании. Такой процесс представления себе сценариев может раскрыть много рисков, включая задержки в пути из-за дорожных работ или аварии, отсутствие парковки, возможность забыть документы и так далее. В среде программного проекта распространенными ролями, используемыми для определения рисков на основе сценариев, являются пользователи, разработчики, тестеры, продавцы, архитекторы программного обеспечения и руководители проектов. Сценарий пользователя может представлять из себя нечто вроде: «Во-первых, я устанавливаю приложение. Затем я запускаю приложение». Во многих случаях сценарий определения рисков непосредственно соответствует тестовому случаю. Ролями определения рисков на основе сценариев не обязательно должны быть люди. Роли также могут быть программными модулями и подсистемами. Например, предположим, что у нас имеется некий объект C#, выполняющий шифрование и дешифрование. Можно представить себе такой объект как роль и создать сценарий вроде: «Сперва я принимаю некий ввода и создаю экземпляр себя. Затем я принимаю некий ввод и передаю его моему методу шифрования». По определению рисков на основе сценариев существует меньше исследований, чем по определению на основе классификаций. Технический документ, который можно найти на Шаблоны определения рисков для программных проектов предоставляет хороший обзор этой области и предлагает интересный, теоретический, основанный на шаблонах подход к определению рисков. Вдобавок к стратегиям определения рисков на основе классификаций и сценариев, существует третий подход, стратегия на основе спецификаций. В этом подходе вплотную рассматривается каждая функция и процесс в документе спецификаций продукта и системы и делается попытка определить, что может пойти не так. Используя аналогию с авиаперелетом, это будет тщательное изучение подробного плана поездки, созданного агентом бюро путешествий. Представьте себе, что один из документов спецификаций для веб-приложения заявляет, что предполагается использовать внешнего подрядчика для создания различных файлов справки к приложению. Внешняя зависимость в проекте может породить массу рисков. Что если подрядчик не сделает работу вовремя? Что если качество его работы не будет соответствовать субъективным стандартам заказчика? Единой, оптимальной стратегии определения рисков не существует, потому что каждая из них имеет свои достоинства и недостатки. Классификации рисков являются отличным способом приступить к процессу определения рисков в программном проекте. Они представляют достаточно механистичный путь начала работы, в том смысле, что их пользователь просто начинает изучать каждый вопрос или заявление в классификации. Классификации также помогают распределить процесс определения рисков между несколькими людьми, назначая различным сотрудникам различные вопросы классификаций. С отрицательной стороны, использование классификаций для определения рисков может отнять массу времени. Кроме того, классификации по своей природе являются обобщенными, так что они не могут определить риски, уникальные для программной системы, если не приложить усилий к определению этих рисков. По сравнению с определением рисков на основе классификаций, подход на основе сценарий имеет преимущество меньшей обобщенности и заставляет пользователя думать более определенно. С другой стороны, определение рисков на основе сценариев – это, скорее, искусство, чем наука и пропустить ключевой сценарий довольно просто. Определение рисков на основе спецификаций обычно является наименее общим, наиболее конкретным подходом. Однако подход на основе спецификаций даст результаты, которые хороши лишь в той же мере, что и документы спецификаций. При использовании вместе три подхода дают хороший шанс верно определить риски при разработке программного обеспечения.
Анализ рисков Анализ рисков – это процесс сочетания вероятности (или правдоподобия) события риска с денежными потерями (или отрицательным эффектом) в случае этого события, чтобы произвести значение, которое можно использовать для сравнения риска с другими рисками и определения его приоритетности. В этом разделе я представляю два старых подхода к анализу рисков (методика ожидаемого значения и категориальная методика) и один новый подход, именуемый PERIL. Давайте сперва взглянем на методику ожидаемого значения. Взгляните на пример, показанный на рис. 5. Предположим, что определено четыре события рисков. Давайте назовем их рисками А, В, С и D. Каждому событию риска назначается вероятность. Вероятность – это число между 0,00 (значащим невозможность) и 1,00 (значащим гарантированность), которое определяет, насколько возможно определенное событие. Далее, каждому событию риска назначается значение денежных потерь – это издержки, которые возникнут, если событие случится. Далее, достаточно перемножить вероятность риска и потери от него для каждого события риска, чтобы получить степень риска.
При использовании этого метода степень риска – это просто форма ожидаемого значения. Очевидно, что подход ожидаемого значения имеет несколько крупных проблем. Как можно оценить вероятности риска? Как можно оценить возможный ущерб? В некоторых ситуациях могут существовать хорошие исторические данные и опыт, на которых можно основать оценки, но в целом это редкая ситуация при создании программ. Согласно моему опыту, подход ожидаемого значения к анализу рисков часто неприменим в среде разработки программного обеспечения. Поскольку оценить вероятность события риска или связанный с ним ущерб во многих средах разработки программного обеспечения невозможно, частой альтернативой является использование категориальных шкал как для возможности риска, так и для ущерба. Это категориальная методика. Пример сделает эту идею ясной. Предположим, что определено четыре риска, A, B, C и D. Теперь, вместо того чтобы предполагать их вероятность и ущерб для каждого из них, можно создать категориальную таблицу степени риска, подобную показанной на рис. 6.
Как можно увидеть, у меня есть всего девять категорий степени риска. Три – это категории вероятности риска, низкая, средняя и высокая. Три – это категории ущерба, также низкий, средний и высокий. Продуктом пересечения этих категорий являются девять категорий степени риска от «низкая-низкий» (вероятность и ущерб) до «высокая-высокий» (аналогично). Теперь я могу рассмотреть любое из своих четырех событий риска, назначая каждому из них низкую, среднюю или высокую вероятности и, аналогично, ущерб, чтобы выдать одну из девяти точек степени риска. Идея состоит в том, что часто разумнее назначить вероятности значение «низкая», вместо точного числового значения вроде 0,05. Гипотетические данные в таблице внизу рис. 6 указывают, что степень риска В наиболее высока и он может потребовать больше внимания или ресурсов (включая тестирования), чем риск А, степень которого наиболее низка. Хотя категорический подход к анализу рисков несколько упрощает проблему назначения вероятностей или информации об ущербе, определить которые сложно или невозможно, эта методика создает новые проблемы. Обратите внимание на то, что я произвольно использую три категории как для вероятности, так и для ущерба. Это очень грубый подход. Но предположим, что я решил улучшить мой анализ рисков, используя пять категорий как для фактора вероятности, так и для фактора ущерба: «Очень низкий», «низкий», «средний», «высокий» и «очень высокий». Теперь у меня есть 25 категорий степени риска – от («очень низкий» + «очень низкий») до («очень высокий» + «очень высокий»). Как можно ранжировать или сравнить эти 25 значений риска? Насколько именно степень риска («очень низкий» + «высокий») сравнима со степенью («высокий» + «средний»)? Если несколько человек оценивают категориальные данные степени риска, интерпретируют ли они их одинаково? Чтобы решить проблемы с чисто категориальным подходом к анализу рисков, несколько лет назад я разработал методику под названием Project Exposure using Ranked Impact and Likelihood (PERIL). Суть идеи состоит в том, чтобы использовать категории (как в категориальном подходе), но преобразовывать их в замеряемую шкалу, позволяя легко сочетать их (как в подходе ожидаемого значения) для выдачи цифровых показателей степени риска. Позвольте мне показать это на примере. Предположим, что определено четыре риска. A, B, C и D. Теперь предположим, что выделение осмысленных числовых значений вероятности и ущербу каждого риска просто нереально. Вдобавок разработчик решает, что в его среде имеет смысл разделить вероятность на пять категорий: «Очень низкая», «низкая», «средняя», «высокая» и «очень высокая». Далее определяется, что ущерб/воздействие будет разделен на шкалу из четырех категорий: «Очень низкий», «низкий», «высокий» и «очень высокий». Методика PERIL сопоставляет категориальные данные с измеряемой шкалой, используя простую математическую конструкцию, именуемую средневзвешенными значениями в иерархии. Методику сопоставления проще всего определить на примере. Для шкалы вероятности с пятью позициями, мои средневзвешенные значения в иерархии показаны на рис. 7. Аналогично, мои средневзвешенные значения в иерархии с четырьмя категориями показаны на рис. 8. Теперь я могу соединить средневзвешенные значения в иерархии возможности и воздействия каждого риска, чтобы получить степень этого риска путем умножения. Например, взгляните на рис. 9. Здесь риск D имеет высокую возможность, что соответствует 0,25667 и низкое воздействие, что соответствует 0,14583, так степень риска – 0,25667 * 0,14583 = 0,03743. Из этих данных я заключил, что риск С явно имеет наивысшую степень, и буду выискивать пути предотвращения этого риска, а также создам запасной план, на случай, если он когда-нибудь произойдет.
Вместо вычисления степени каждого риска отдельно я могу сконструировать законченную таблицу подстановки степени PERIL для пяти уровней вероятности и четырех уровней воздействия, после чего просто прочесть значения степени риска PERIL из таблицы, как иллюстрирует рис. 10. Методика PERIL обобщается для любого числа категорий возможности и воздействия.
Средневзвешенные значения в иерархии сопоставляют позиции (такие как первая, вторая, третья) с числовыми значениями (такими как 0,61111, 0,27778, 9,11111). Отметьте, что средневзвешенные значения в иерархии нормализованы в том смысле, что их сумма равна 1,0 (возможна ошибка округления). Если использовать обозначение со знаком суммы, то если N – число категорий, то числовое значение, соответствующее категории kth, равно:
Существует много других математических сопоставлений между категориями и числовыми значениями, но существуют исследования, предполагающие, что использование средневзвешенных значений в иерархии является очень хорошим способом сопоставления рангов, вроде тех, что используются в анализе рисков. Завершенный рассказ о средневзвешенных значениях в иерархии выходит за рамки данной статьи, но читателям стоит обдумать следующий неформальный аргумент. Предположим, что речь идет всего о двух категориях возможности событий риска: «низкой» и «высокой». Предположим, что возможность события с высоким риском составляет больше 0,5 и, следовательно возможность события с низким риском ниже 0,5. Без дополнительной информации можно предположить, что высокая возможность события находится на середине между 0,5 и 1,0, тем самым составляя 0,75. Аналогично, низкая возможность события находится на полпути между 0,0 и 0,5, то есть составляет 0,25. Эти два значения, 0,75 и 0,25 являются средневзвешенными значениями в иерархии для категорий N = 2 (как показано на рис. 11).
Отметьте, что при использовании PERIL я применяю термины «возможность» и «воздействие» вместо «вероятность» и «ущерб». «Возможность» и «воздействие» PERIL – это относительные, нормализованные значения. Хотя значения возможности PERIL имеют сумму 1,0, точно так же, как набор вероятностей, позвольте мне обратить внимание, что значения возможности PERIL – это не вероятности. Аналогично, значения воздействия PERIL имеют значение лишь при сравнении друг с другом и не являются значениями денежного ущерба. Три методики определения степени риска – методика ожидаемого значения, категориальная методика и методика PERIL имеют свои силы и слабости. При наличии основательных исторических данных, позволяющих оценить вероятности событий риска и связанный с каждым из них ожидаемый денежный ущерб, лучшим подходом обычно является методика ожидаемых значений. Однако в среде разработки програ
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-11; просмотров: 403; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.144.224.105 (0.015 с.) |

 Cодержание
Cодержание