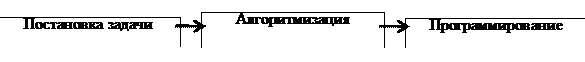Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Иерархическая и сетевая модели данныхСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
В иерархической модели база данных представляется в виде иерархически упорядоченных структур – деревьев (диаграммы Бахмана). Каждая вершина дерева означает объект данных, каждая дуга означает связь между объектами. Все вершины графа – дерева распределены по уровням. Каждая вершина низшего уровня связана только с одной вершиной из верхнего уровня. Связей внутри уровня и через уровень не существует. На самом верхнем уровне существует только одна вершина - корень дерева. корень
Пример, описание ННГУ в иерархической модели выглядит так 2 уровень.
Уровень 1. Университет вершины
Рис. 4.3. Иерархическая модель Ниже перечислены преимущества иерархической модели. · Простота модели. Иерархия базы данных напоминает структуру компании или генеалогическое дерево. · Использование отношений предок/потомок. СУБД позволяет легко представлять отношения подчиненности, например: «А является частью В» или «А владеет В». · Быстродействие. В СУБД отношения предок/потомок реализованы в виде физических указателей из одной записи на другую, вследствие чего перемещение по базе данных происходило быстро. Групповое отношение - иерархическое отношение между записями двух типов. Родительская запись называется исходной записью, а дочерние записи – подчиненными. Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись. При удалении родительской записи автоматически удаляются все подчиненные. Недостатки иерархических БД: · Каждый объект данных может участвовать только в одной иерархии объектов. Поэтому, если объект должен присутствовать в нескольких иерархиях, то его приходится дублировать. Например, данные о сотруднике должны участвовать в иерархии подчиненности отделам и в подчиненности контрактам в качестве исполнителей (такие записи называют парными). В иерархической модели не предусмотрена поддержка соответствия между парными записями. ·. Иерархическая модель реализует отношение между исходной и дочерней записью по схеме l:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором Исполнитель будет являться исходной записью, а контракт – дочерней. Таким образом, мы опять вынуждены дублировать информацию. · Изменение структуры данных требует перестройки всей системы указателей на записи. Чтобы получить доступ к данным, содержащимся в базе данных, СУБД может: · найти конкретный объект (Финансовый факультет) по его номеру; · перейти «вниз» к первому потомку (Группа 13101); · перейти «вверх» к предку (Университет); · перейти «в сторону» к другому потомку (Мехмат). Таким образом, для чтения данных из иерархической базы данных требуется перемещаться по записям, за один раз переходя на одну запись вверх, вниз или в сторону. Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Типичным представителем иерархической модели является СУБД Information Management System (IМS) фирмы IBM. Первая версия появилась в 1968 г. В сетевой модели БД изображается в виде графа произвольной структуры (рис 11.4.).
Основные различия двух моделей состоят в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно сетевой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства, общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник, например, не может работать в двух отделах). Каждый экземпляр группового отношения характеризуется следующими признаками: 1. способ упорядочения подчиненных записей: - произвольный, - хронологический /очередь/, - обратный хронологический /стек/, - сортированный. Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания. 2. режим включения подчиненных записей: - автоматический - невозможно занести в БД запись без владельца; - ручной - позволяет запомнить в БД подчиненную запись и не включать ее немедленно в экземпляр группового отношения. Эта операция позже инициируется пользователем. 3. режим исключения Принято выделять три класса членства подчиненных записей в групповых отношениях: 1. Фиксированное. Подчиненная запись жестко связана с записью владельцем и ее можно исключить из группового отношения, только удалив. При удалении записи-владельца все подчиненные записи автоматически тоже удаляются. 2. Обязательное. Допускается переключение подчиненной записи на другого владельца, но невозможно ее существование без владельца. Для удаления записи-владельца необходимо, чтобы она не имела подчиненных записей с обязательным членством. Таким отношением связаны записи "СОТРУДНИК" и "ОТДЕЛ". Если отдел расформировывается, все его сотрудники должны быть либо переведены в другие отделы, либо уволены. 3. Необязательное. Можно исключить запись из группового отношения, но сохранить ее в базе данных, не прикрепляя к другому владельцу. При удалении записи-владельца ее подчиненные записи - необязательные члены сохраняются в базе, не участвуя более в групповом отношении такого типа. Примером такого группового отношения может служить "ВЫПОЛНЯEТ" между "СОТРУДНИКИ" и "КОНТРАКТ", поскольку в организации могут существовать работники, чья деятельность не связана с выполнением каких-либо договорных обязательств перед заказчиками. Как и в иерархической модели обеспечивается только поддержание целостности по ссылкам (владелец отношения - член отношения). Сетевые базы данных обладали рядом преимуществ: · Гибкость. Множественные отношения предок/потомок позволяли хранить данные, структура которых была сложнее простой иерархии. · Стандартизация. Появление стандарта CODASYL обеспечили популярность сетевой модели. · Быстродействие. Вопреки своей большой сложности, сетевые базы данных достигли быстродействия, сравнимого с быстродействием иерархических баз данных. Множества были представлены указателями на физические записи данных. Конечно, у сетевых баз данных были недостатки. Как и иерархические базы данных, сетевые базы данных были очень жесткими. Наборы отношений и структуру записей приходилось задавать наперед. Изменение структуры базы данных обычно означало перестройку всей базы данных. Как иерархическая, так и сетевая база данных были инструментами программистов. Чтобы получить ответ на вопрос типа: «Какой товар наиболее часто заказывает компания Паровые машины?», программисту приходилось писать программу для навигации по базе данных. Реализация пользовательских запросов часто затягивалась на недели и месяцы, и к моменту появления программы информация, которую она предоставляла, часто оказывалась бесполезной. Типичным представителем является Integrated Database Management System (IDMS) компании Cиllinet Software, Inc. Практически все существующие СУБД в наше время используют реляционную модель данных. Реляционная модель данных Реляционная модель ориентирована на представление данных в виде двумерных таблиц. Множество атрибутов объекта данных образует кортеж. Отношением (relation) называется множество кортежей, обладающее следующими свойствами: * все кортежи однородны, т.е. имеют одинаковое количество и характеристики атрибутов; * атрибуты в кортежах неупорядочены; * кортежи в отношении неупорядочены; Если проигнорировать последние 2 свойства, то отношение можно изображать в виде двумерной таблицы, в которой строки соответствуют кортежам, а столбцы - атрибутам. В таблице строки и столбцы все-таки упорядочены – есть первый и следующий, последний. Понятие «отношение» позволяет отделить проблему хранения данных от проблемы их упорядочения. Проблема упорядочения решается с помощью особого средства – ключей. Также становится несущественным физический порядок хранения объектов данных на внешних носителях информации. Новые данные добавляются в конец файла или на место удаленных данных внутри файла. Одни и те же данные могут группироваться в отношения различным образом. Отношение представляет собой некую связь между объектами данных. Дадим несколько понятий, используемых в теории БД. Недействительное значение – значение, соответствующее отсутствию данных. Они используются для обозначения того факта, что атрибуту ничего не присвоено, по причине того, что отсутствует, потеряно, неизвестно, недоступно или неприменимо значение. Часто обозначается как NULL. Отличается от строк нулевой длины, строки пробельных символов, от нуля и любого другого числа. Транзакция – групповое изменение данных. Транзакция имеет начало и окончание, между которыми обозначены операции обработки данных. Операции выполняются, но изменения данных не попадают в БД, пока не произойдет нормального окончания транзакции. При ненормальном окончании происходит возвращение БД к тому состоянию, в котором она была до начала транзакции (откат БД). Лозунг транзакции: «Все или ничего». Транзакции введены для защиты от сбоев и для ситуаций, когда частичное изменение данных бессмысленно. Например, изменение фамилии работника должно произойти или для всех его платежей, или ни для одного. Ситуация частичного изменения здесь недопустима. Другой пример. Перечисление денег внутри банка состоит из двух операций: снятие денег с одного счета и зачисление их на другой счет. Представим себе, что после первой операции произошел сбой. Тогда деньги будут сняты со счета, но не появятся на другом счете. Это нарушит баланс между расходами и доходами. Поэтому операции должны быть или выполнены обе, или не выполнена ни одна. Представление – искусственная временная таблица, созданная из одной или нескольких таблиц БД. Представления позволяют создавать таблицы, которых нет в БД. После создания представления с ним можно работать как с обычной таблицей. Блокировка – запрет на доступ и модификацию записи или таблицы. Используется для того, чтобы другой пользователь не мог прочитать и модифицировать запись или таблицу в то время, когда Вы ими пользуетесь. Имеют смысл только в многопользовательской СУБД. Обновление – обобщенное название для трех операций: добавления, изменения и удаления записи. Правила Кодда Тэд Кодд в 1969 году сформулировал двенадцать правил, которым должна соответствовать настоящая реляционная база данных. (табл 11.1). Они являются полуофициальным определением понятия «реляционная база данных». Таблица 11. 1.
Правило 1 гласит, что вся информация в реляционных базах данных представляется значениями в таблицах. Все данные представляются в табличном формате - другого способа просмотреть информацию в базе данных не существует. Набор связанных таблиц образует базу данных. Таблицы в реляционной базе разделены, но полностью равноправны. Между ними не существует никакой иерархии. Правило 2 указывает на роль первичных ключей при поиске информации в базе данных. Имя таблицы позволяет найти требуемую таблицу, имя столбца позволяет найти требуемый столбец, а значение первичного ключ позволяет найти строку, содержащую искомый элемент данных. Правило 3 требует, чтобы отсутствующие данные можно было представить с помощью недействительных значений (NULL). Существенно, что использование нулей инициирует переход с двухзначной логики (да/нет) на трехзначную (да/нет/может быть). Правило 4 гласит, что реляционная база данных должна сама себя описывать. В реляционной базе данных существует два типа таблиц - пользовательские таблицы и системные таблицы. Пользовательские таблицы содержат информацию. Системные таблицы описывают структуру самой базы данных, однако доступ к ним можно получить так же, как и к любым другим таблицам. Правило 5 требует, чтобы СУБД использовала язык реляционной базы данных, например SQL, хотя явно SQL в правиле не упомянут. Такой язык должен поддерживать все основные функции СУБД - создание базы данных, чтение и ввод данных, реализацию защиты базы данных и т. д. Правило 6 касается представлений, которые являются виртуальными таблицами. Виртуальные таблицы, в отличие от «настоящих» таблиц, физически не хранятся в базе данных. В то же время необходимо осознавать, что виртуальные таблицы это не копия некоторых данных, помещаемая в другую таблицу. Когда вы изменяете данные в виртуальной таблице, то тем самым изменяете данные в базовых таблицах. В идеальной реляционной системе с виртуальными таблицами можно оперировать, как и с любыми другими таблицами. Это одно из правил, которые сложнее всего реализовать на практике. Правило 7 акцентирует внимание на том, что базы данных по своей природе ориентированы на множества. Оно требует, чтобы операции добавления, изменения и удаления можно было выполнять над множествами строк. Это правило запрещает реализации, в которых поддерживаются операции только над одной строкой. Правило 8 и 9 означают отделение пользователя и прикладной программы от низкоуровневой реализации базы данных. Они утверждают, что конкретные способы реализации хранения или доступа, используемые в СУБД, и даже изменения структуры таблиц базы данных не должны влиять на возможность пользователя работать с данными. Реляционная модель обеспечивает независимость данных на двух уровнях - физическом и логическом. Физическая независимость данных означает с точки зрения пользователя, что представление данных абсолютно не зависит от способа их физического хранения. Логическая независимость означает, что изменение взаимосвязей между таблицами и строками, их структура не влияют на правильное функционирование программ и текущих запросов. Правило 10 гласит, что язык базы данных должен поддерживать ограничения на вводимые данные и на действия, которые могут быть выполнены над данными. Целостность - очень сложный и серьезный вопрос при управлении реляционными базами данных. Несогласованность или противоречивость данных может возникать вследствие сбоя системы - проблемы с аппаратным обеспечением, ошибки в программном обеспечении или логической ошибки в приложениях. Реляционные системы управления базами данных защищают данные от такого типа несогласованности, гарантируя, что команда либо будет исполнена до конца, либо будет полностью отменена. Другой тип целостности, называемый объектной целостностью, связан с корректным проектированием базы данных. Объектная целостность требует, чтобы ни один первичный ключ не имел нулевого значения. Третий тип целостности, называемой ссылочной целостностью, означает непротиворечивость между частями информации, повторяющимися в разных таблицах. Например, если вы изменяете неправильно введенный номер карточки страхового полиса в одной таблице, другие таблицы, содержащие эту же информацию, продолжают ссылаться на старый номер, поэтому необходимо обновить и эти таблицы. Чрезвычайно важно, чтобы при изменении информации в одном месте, она соответственно изменялась и во всех других местах. Кроме того, по определению Кодда, ограничения на целостность должны: - Определяться на языке высокого уровня, используемом системой для всех других целей; - Храниться в базе данных, а не в программных приложениях. Эти возможности в том или ином виде реализованы в большинстве СУБД. Правило 11 гласит, что язык базы данных должен обеспечивать возможность работы с распределенными данными, расположенными на других компьютерных системах. И, наконец, правило 12 предотвращает использование других возможностей для работы с базой данных, помимо языка базы данных, поскольку это может нарушить ее целостность. Двенадцать правил Кодда считаются определением реляционной СУБД. Однако можно сформулировать и более простое определение: Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. Целостность связей Под целостностью связей понимается соответствие данных в нескольких наборах объектов друг другу. Не соответствующие друг другу данные противоречат предметной области БД, т.е. окружающему миру. Нарушение соответствия данных, целостности связей может произойти только при операциях изменения данных. Рассмотрим правила поддержки целостности связей между двумя наборами объектов, которые применяются при операциях добавления, изменения и удаления объектов из наборов. Считается, что связь между двумя наборами относится к типу «один ко многим». Один из наборов содержит родительские объекты, другой – дочерние. Эти правила называются стандартной целостностью. Основное требование стандартной целостности состоит в наличии для дочерних объектов ссылок на родительский объект. Всего правил десять: 2 правила при добавлении, 4 правила при изменении, 4 правила при удалении. Выбор правил зависит от предметной области.
При добавлении дочернего объекта возможны 2 правила: 1) Запрет Запрещено добавлять дочерний объект, если для него не указан родительский объект. Например, запрещено добавлять нового сотрудника, если для него не указано подразделение. 2) Игнорировать Разрешено добавлять дочерний объект без указания для него родительского объекта. Например, разрешается добавлять новый первичный документ, не указывая для него сводного документа.
Подразумеваются изменения, которые касаются ссылок в дочерних объектах. При изменении родительского или дочернего объекта возможен выбор одного из 4-х правил. 1) Запрет Запрещено изменять в дочернем объекте ссылку на родительский объект так, что она указывает на несуществующий родительский объект. Например, запрещено указывать для сотрудника несуществующее подразделение. 2) Каскад При изменении родительского объекта каскадно изменяются ссылки на него во всех дочерних объектах, если изменения родительского объекта касаются таких ссылок. Например, при изменении внутреннего номера подразделения этот номер автоматически изменяется в соответствующем атрибуте для всех сотрудников подразделения. 3) Очистить При изменении родительского объекта, которые касаются ссылок на него, ссылки на него во всех дочерних объектах заполняются значением 0, NULL или пустой строкой. 4) Игнорировать При изменении родительского объекта, которые касаются ссылок на него, ссылки на него во всех дочерних объектах остаются без изменений, указывая теперь на несуществующий родительский объект.
При удалении родительского объекта возможен выбор одного из 4-х правил. 1) Запрет Запрещено удалять родительский объект, если у него имеются дочерние объекты. Можно удалять только родительские объекты, у которых нет дочерних. Например, нельзя удалить все данные о подразделении, в котором числятся сотрудники. Необходимо предварительно сотрудников или удалить, или перевести в другие подразделения. 2) Каскад При удалении родительского объекта каскадно удаляются все его дочерние объекты. Например, при удалении сотрудника удаляются все сведения об его продвижениях по службе и обо всех выплатах ему. 3) Очистить При удалении родительского объекта ссылки на него во всех дочерних объектах заполняются значением 0, NULL или пустой строкой. Например, при удалении сводного документа ссылки на него во всех его первичных документах заполняются пустым значением. Это будет служить признаком, что первичные документы не участвуют ни в каких сводных документах. 4) Игнорировать При удалении родительского объекта ссылки на него во всех дочерних объектах остаются без изменений, указывая теперь на несуществующий родительский объект. Перечисленные правила стандартной целостности стали классическими и поддерживаются во всех СУБД общего назначения. Возможны некоторые коллизии правил, когда правила для нескольких связей вступают в противоречие друг тс другом. Например Существуют другие, пока нестандартные правила целостности связей, которые обсуждаются ниже. · Агрегирование. Родительский объект содержит обобщение информации из всех его дочерних объектов. Например, поле «Итого» расходной ведомости должно содержать сумму выдач по строкам ведомости. Например, поле «Номер комнаты» для проживающего в общежитии должно содержать номер комнаты из переселения, последнего по дате. · Удаление последнего. Если удаляется единственный дочерний объект, то удаляется и родитель. Например, при удалении единственного заказа одного из клиентов, желательно удалить и соответствующую запись в списке клиентов. При добавлении объекта применяется аналогичное правило. Например, при вводе первого заказа для нового клиента автоматически добавляется клиент и о нем запрашивается информация. · Ограниченное добавление. Разрешается добавлять записи, удовлетворяющие определенному условию. Например, иногда нежелательно обслуживать клиентов из определенных областей. В списке регионов такие области отмечены признаком. Метод «сущность-связи»
Программное обеспечение ЭВМ Программа - упорядоченная последовательность команд компьютера для решения задачи. Программное обеспечение (software) - совокупность программ и необходимых для их эксплуатации документов, предназначенных для решения задач на компьютере. Программы предназначены для машинной реализации задач. Термины задача и приложение имеют очень широкое употребление в контексте информатики и программного обеспечения. Основные понятия Термины задача и приложение имеют очень широкое употребление в контексте информатики и программного обеспечения. Задача - проблема, подлежащая решению. Приложение - программная реализация на компьютере решения задачи. Таким образом, задача означает проблему, подлежащую реализации с помощью средств информационных технологий, а приложение - реализованное на компьютере решение задачи. Приложение, является синонимом слова программа. Термин задача употребляется также в сфере программирования, особенно в режиме мультипрограммирования и мультипроцессорной обработки, как единица работы вычислительной системы, требующая выделения вычислительных ресурсов: процессорного времени, основной памяти и т.п. В данной главе этот термин употребляется в смысле первого определения. С позиций программного обеспечения будем различать два класса задач - технологические и функциональные. Технологические задачи ставятся и решаются при организации технологического процесса обработки информации на компьютере. Технологические задачи являются основой для разработки сервисных средств программного обеспечения в виде утилит, сервисных программ, библиотек процедур и др., применяемых для обеспечения работоспособности компьютера, разработки других программ или обработки данных функциональных задач. Функциональные задачи требуют решения при реализации функций управления в рамках информационных систем предметных областей. Например, управление деятельностью торгового предприятия, планирование выпуска продукции, управление перевозкой грузов и т.п.
Процесс создания программ можно представить как последовательность действий рис 12.1, Рис. 12.1. Схема процесса создания программ Рассмотрим эти этапы Постановка задачи - это точная формулировка решения задачи на компьютере с описанием входной и выходной информации. Постановка задачи связана с конкретизацией основных параметров ее реализации, определением источников и структурой входной и выходной информации. К основным характеристикам постановки задачи относятся: § цель или назначение задачи, ее место и связи с другими задачами; § условия решения задачи с использованием средств вычислительной техники; § функции обработки входной информации; § требования к периодичности решения задачи; § ограничения по срокам и точности выходной информации; § состав и форма представления выходной информации; § источники входной информации для решения задачи; § пользователи задачи. Алгоритм - система правил, определяющая процесс преобразования допустимых исходных данных в желаемый результат за конечное число шагов. Алгоритм должен обладать рядом свойств: § дискретность - разбиение алгоритма на более простые этапы, выполнение которых компьютером или человеком не вызывает затруднений; § определенность - однозначность выполнения каждого отдельного этапа; § выполнимость - конечность действий алгоритма решения задач, позволяющая достичь желаемый результат при допустимых исходных данных за конечное число шагов; § массовость - пригодность алгоритма для решения определенного класса задач. Программирование - теоретическая и практическая деятельность, связанная с созданием программ.
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-06-26; просмотров: 1291; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.73 (0.018 с.) |

 2-й уровень
2-й уровень Корень дерева Вуз
Корень дерева Вуз


 Уровень 2. Финансовый ф-т Мехмат
Уровень 2. Финансовый ф-т Мехмат
 связи
связи
 Уровень 3. Группа 1311
Уровень 3. Группа 1311
 Уровень 4. Иванов И.И.
Уровень 4. Иванов И.И.