Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
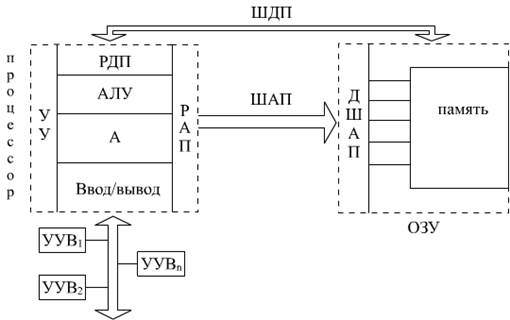
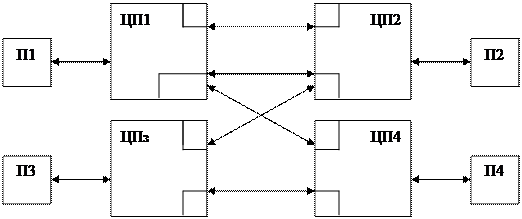
Схема взаимосвязи регистров в процессоре.Содержание книги Поиск на нашем сайте
Структура ЭВМ В современных компьютерах реализуется Фан Теймана. В этой концепции архитектура ЭВМ поддерживает следующие принципы: 1. Двоичное кодирование внутреннего содержания. 2. Программное управление работы машины. 3. Однородность использованной памяти. 4. Адресуемая память. В классическом случае машина по принципам Фан Теймана содержит следующие блоки: 1. Оперативная память. 2. Арифметико-логическое устройство. 3. Устройство управления. 4. Устройство ввода/вывода. Структурная схема ЭВМ в этом случае имеет след вид:
Оперативная память предназначена для хранения, как команд, так и данных, представляющие собой двоичные коды и на первый взгляд не различимы. Это принципиально важно, поскольку позволяет иметь память с единой адресацией, что позволяет упростить программирование. АЛУ – арифметико-логическое устройство УУ – устройство управления РАП – регистр адреса памяти ШАП – шина адреса памяти РДП – регистр данных памяти ДАП – дешифратор адреса памяти Блок управления формирует сигналы управления (последовательность микроопераций) для выполнения команд программирования. Регистр адреса памяти содержит адрес той ячейки, в которой будет происходить обращение в данный момент. Выбор этой ячейки по адресу осуществляется с помощью дешифратора адреса памяти. Обмен данными (и командами) между процессором и памятью осуществляется по шине данных в памяти. Этот обмен происходит через регистр данных в памяти. Любая ЭВМ работает синхронно с поступлением тактовых импульсов от внутреннего генератора. Выполнение программы является сложным процессом и поэтому на её выполнение требуется несколько периодов тактовых импульсов. Время выполнения команды называется циклом. Если команда простая, то она выполняется за один машинный цикл, а если сложная, то может потребоваться несколько машинных циклов.
Структура машинного цикла Машинный цикл схематично можно представить следующим образом:
Совокупность цикла выборки и исполнительного цикла составляет машинный цикл.
Структура и типы команд Для работы компьютера команда задает операцию и те данные, над которыми эта операция должна быть выполнена. Обычно тип операции задаётся кодом внутри команды. Также внутри команды задаются тем или иным способом операнды, т.е. в общем случае команда задает следующие условия: какую выполнить операцию, с какими операндами её выполнить и куда поместить результат? Информация по каждому из этих разделов задается в команде в специальном коде. В общем случае команда состоит из следующих полей:
Регистр команд служит для хранения команды в процессе её дешифрации и выполнения. К каждому полю регистра команд подключен свой дешифратор.
На выходе дешифратора в зависимости от кода операции появляется сигнал, который запускает соответствующую цепочку действий по выполнению операции. Код способа адресации и код адреса операнда с помощью операндов позволяют вычислить физические адреса операнда. В случае 2х местной операции, т.е. операции с двумя операндами, команда должна задавать: 1. Операцию 2. Адрес 1го операнда 3. Адрес 2го операнда 4. Адрес сохранения адресата 5. Адрес следующей команды Если все эти адреса задать в явном виде, то команда будет иметь следующие поля:
Чтобы иметь возможность строить длинные программы, эти поля адресов должны иметь достаточное количество разделов. Поскольку современные ЭВМ должны иметь 16р., 32р., 64р., то длинная команда не укладывается в одномашинное слово 16разрядов, т.е. необходимо будет размещать машинную команду в несколько машинных слов и соответственно в несколько ячеек памяти, т.е. резко удлиняется процесс выборки команд, а следовательно падает быстродействие ЭВМ. Существует несколько способов, которые позволяют сократить длину команды.
Х адресные команды Если расположить команды программы в соседних ячейках таким образом, что в следующей ячейке находится следующая команда, то от 4го адреса можно избавиться.
Но тогда нам надо знать номер или адрес этой ячейки памяти, в которой будет храниться следующая команда, т.е. иметь такой регистр, который указывает нам на адрес следующей команды. Такое устройство называется – счетчик команд. Программу представляем в виде некоторой ленты, расположенной в соседних ячейках памяти, а счетчик команд указывает на ту ячейку, где хранится следующая команда.
Х адресные команды В этом случае отказываемся от указания адреса результата и записываем результат по адресу одного из операндов
т.е. результат записывается поверх самого операнда, при этом значение операнда теряется, но длина команды существенно сокращается.
Здесь Адрес 1 – адрес источника Адрес 2 – адрес приема
Поскольку второй операнд после выполнения операции теряется, то нужно пересылать операнды из одного места в другое. Это потребовало в архитектуру специальные команды – пересылка данных.
О адресные команды Предположим, что мы избавляемся от задания адреса одного из операндов. Тогда мы должны знать, где всегда находится один из операндов.
Если мы введем в состав АЛУ специальный регистр, в который будем заранее помещать один из операндов, то адресовать в команде нужно будет только второй операнд. Такой регистр называется – регистр-аккумулятор, т.е. в этот регистр помещается один из операндов и также оказывается результат операции. Поскольку быстродействие памяти меньше быстродействия регистров, то для то для повышения всей системы в целом разработчики пошли дальше и кроме одного регистра добавили ещё несколько адресуемых регистров – регистры общего назначения. При этом появилось 2 вида команд: регистр/регистр, регистр/память. Регистр/регистр являются наиболее компактными и быстродействующими.
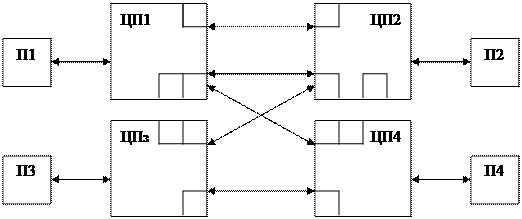
Классификация систем Мультипроцессорные системы С распределительной памятью Рассмотрим вариант системы с распределительной памятью, построенной с помощью общей шины. В качестве общей шины может использоваться шина PCI или шина VME. В этом случае каждый процессор имеет некоторый интерфейсный блок для подключения шины и индивидуальной памяти.
Подключение процессоров к шине осуществляется через интерфейсный блок. Каждый процессор имеет свою индивидуальную память Pi. Достоинством такой топологии является простота и низкая стоимость средств коммутации. Недостатком является наличие общей шины, поскольку при увеличении числа процессоров она становится узким местом и результируемый эффект от увеличения числа процессоров снижается. Рассмотрим другую топологию, которая называется – полный граф.
В данном случае интерфейсные блоки обеспечивают связь точка-точка. В топологии «полный граф» каждый процессор непосредственно связан с любым другим. Это обеспечивает максимальные возможности для информационного обмена между узлами. Недостатком такой топологии является тот факт, что с ростом числа процессоров резко возрастает количество интерфейсных блоков, т.е. возрастает сложность коммуникационного оборудования.
Двумерный гиперкуб. В этом случае каждый процессор связан только со своими ближайшими соседями. Несмотря на сложное название, эта топология проще.
В этой топологии количество требуемых интерфейсных блоков и интерфейсный обмен между ними меньше, чем в системах «полный граф». Топология «гиперкуб» находит применение в системах с большим количеством процессов. Сравним 2 способа построения мультипроцессорных систем СМП и МРР. Основное преимущество систем СМП – это простота программирования. Поскольку в системах СМП все процессоры имеют одинаково быстрый доступ к памяти, то вопрос о том, какой процессор будет выполнять те или иные вычисления не принципиальны. Кроме того, большая часть вычислительных алгоритмов, разработанных для однопроцессорных систем могут использоваться в СМП при условии применения распараллеливаемых компиляторов. Системы СМП – это наиболее распространенный сейчас тип параллельных систем, т.е. 2х-4х процессорные системы уже широко применяются. Однако с большим числом процессов требуется решение возникших проблем, таких как: 1. Когерентность КЭШ памяти. 2. Арбитраж конкуренции за шину. 3. Обработка аппаратных прерываний. Системы МРР позволяют строить наиболее высоко производимые структуры. Узлами в таких структурах возникают системы СМП.
Топология внутренних связей Многопроцессорных систем. Топология – абстрактная характеристика структуры вычислительной системы. Она учитывает свойства существования элементов структуры и их связанности. Топологию очень удобно моделировать с помощью графов. Для сети внутренних связей важной является такая характеристика топологии, которая называется – диаметр графа сети. Под диаметром графа d понимается число ребер в кротчайшем маршруте. Если диаметр графа равен d, то передача сообщений из узла сети в любой другой может быть выполнена не более чем через d-1 промежуточный минимум. Можно считать, что диаметр графа в определенной степени характеризует время передачи сообщений в сети. Чем меньше диаметр графа в сети, тем лучше для передачи сообщений. Отмети, что рассмотренные выше коммутаторы относятся к динамическим схемам коммутации, т.к. они обеспечивают установление прямых каналов между узлами и их гибкую реконфигурацию. Сети связи относятся к статическим схемам коммутации, т.к. обеспечивают связь только с соседними сигналами и используют пакеты, а не каналы. Важным параметром является число соседних узлов связи в сети, с которыми установлено непосредственное соединение. Это зависит от размерности метрического пространства, в котором реализуются системы связи. Существует одно-, двух, трёхмерные и гиперкубические группы сетей связи.
Общая шина с арбитром. В соответствии с приоритетами арбитр выбирает несколько вопросов от процессоров на доступ к шине и обеспечивает данному процессору монопольное владение шины. Такая схема сочетает экономичность и логическую простоту. Для повышения пропускной способности внутренних связей используют набор из нескольких шин, параллельные не зависимо работающие шины имеют возможность одновременно обслужить несколько запросов в памяти.
Кольцевая структура. Эффективность информационного обмена в цепочке можно повысить, если замкнуть цепочку в кольцо.
Общая шина с арбитром: 1 2 3 4

В кольце передачи информации осуществляются от некоторого текущего процессора – предшественника к процессору – приемнику, и дальше к следующему процессору – приемнику до тех пор, пока сообщение не достигнет адресата. Как и в обычном кольце каждый процессор проверяет адрес сообщения. Если адрес соответствует текущему процессору, то сообщение читается целиком и передача прекращается. Если же адрес не соответствует, то текущий процессор посылает сообщение следующему приемнику. Данная структура отличается логической простотой и модульностью, то есть легко позволит наращивать количество узлов. У каждого процессора имеется 2 процессора – приёмника. Если общее количество узлов N, то диаметр сети d=N/2. Связи типа «звезда». В этом случае информация передается по индивидуальным связям, которые существую между некоторыми центральными узлами и процессором:
В центральном узле помещается коммутатор, который осуществляет обмен между процессорами. Каждая передача требует прохождения по двум радиусам. Функционально эта структура соответствует общей шине коммутатора, но поскольку здесь используются индивидуальные траты, то пропускная способность в такой структуре лучше.
Архитектура NUMA. При создании этой архитектуры разработчики стремились объединить достоинства от систем СМП. Создатели архитектуры NUMA предложили набор кластеров, которые соединены в межкластерные шины. Адресное пространство с помощью старших разрядов адреса делятся между кластерами. Когда процессор обращается к памяти, он посылает адрес к своему контроллеру памяти. Резидентная память кластера связана с процессором через некоторую локальную шину. Контроллер анализирует старшие разряды адреса, и по ним определяет в каком модуле находится требуемая ячейка памяти. Если адрес локальный, то запрос выставляется на локальную шину, либо на кластерную шину. Следует заметить, что локальный запрос выполняется быстрее, чем удаленный. Здесь существует проблема обеспечения когерентности КЭШов, т.е. обеспечение идентичности всех копий данных в системе. В следующей архитектуре сделана попытка аппаратными средствами решить эту проблему. СС- NUMA => Cache Coherent NUMA. Отличием СС- NUMA является использование аппаратуры для связки механизма работы КЭШ памяти вычислительного модуля с удаленным блоком памяти других модулей. Такая архитектура была применена разработчиками: NUMA Q2000.
Р6 Р6 Р6 Р6 Вычислительный модуль
Вход Выход
Каждый вычислительный модуль является системой СМП и содержит 4 процессора Pentium Pro. Основой модуля является системная шина, которой кроме процессора подключена память 4гб. Этот модуль содержит 2 моста с шинами PCI и адаптер IQ Link. Через мосты PCI к модулю подключено внешнее устройство. Адаптер IQ реализует протокол когерентности КЭШей. содержит блоки подключения входных и выходных Linkов при работе этого вычислительного модуля в составе системы. Такой модуль может работать как самостоятельно, так и в составе системы. В составе системы это выглядит следующим образом:
В адаптер вводится дополнительно удаленный КЭШ 3-го уровня. В этом КЭШе хранятся копии строк данных, загружаемых из удаленных блоков памяти. Этот КЭШ обслуживает обращение к данным при отсутствии требуемой строки, при отсутствии КЭШа и в блоке локальной памяти.
Локальная память вычислительного модуля отображается в единое для системы глобальное адресное пространство. Попадание в определенный диапазон определяется идентификатором. Он используется для маршрутизации пакета, который доставляет требуемую строку КЭШ память. Для быстрого определения строк используется специальный каталог. Существенной особенностью организации памяти в системах NUMA, является то, что в ней объединены передача данных в течении когерентности от передач данных, связанных с в/в и обменом между процессором и памятью. График в/в и график процессорной памяти выполняются параллельно. Существенным достоинством систем СМП является простота. Обеспечивается быстрый доступ ко всем частым оперативной памяти.
Архитектура СС- NUMA. Одна из основных проблем при создании разделяемой памяти в мультипроцессорных системах, состоит в том, как извещать другие процессоры об изменениях, вызванных выполнением команд записи. Для идентификации удаленных копий данных используются 2 протокола: коммуникационный и протокол когерентности. Коммуникационный протокол используется для доставки сообщений. Протокол когерентности используется для предотвращения использования копий тех данных, которые изменились в другом процессоре. При разработке протоколов используются модели состоятельности памяти. Простейшей является модель строгой состоятельности. Операция чтения из разделяемой памяти в этом случае должна доставлять в процессор последнее записанное значение переменной. Поэтому когда одна из копий переменных модифицируется, то все остальные копии других переменных так же должны быть модифицированы. Для выполнения такой модели требуются дополнительные аппаратные средства. Использование этих средств снижает производительность системы. Это получается из-за того, что для синхронизации необходимо вводить единое глобальное время в многопроцессорную систему. Поэтому, в реальных системах чаще всего используются модели не полной состоятельности данных. В это случае допускается появление не согласованных копий данных в ходе параллельной обработки, при условии, что эта несогласованность не влияет на конечный результат. При построении разделяемой памяти, существенными являются характеристики: - способ реализации механизмов управления работой этой памяти. Эти механизмы бывают: аппаратными, программными, или смешанно аппаратно-проргаммные; - размер минимально разделяемой единицы данных, может быть слово, строка, сегмент, объект; - модуль состоятельности памяти; - механизм управления разделением памяти.
Интеграция функции. С увеличением интеграции микросхем появилась возможность создания целых систем на одном кристалле, такие систему наз-ся «Sistem on chip». На кристалле теперь интегрирующие функции. Для их выполнения ранее требовались наборы микросхем, сетевые платы и другие устройства. При интеграции функционирующих элементов системы на одном кристалле естественным образом уменьшается задержка при информационных обменах за счет того, что при близкорасположенных элементах время передачи информации между ними очень мало, а уменьшение информационной задержки приводит к быстродействию системы. С другой стороны, уменьшение количества микросхем, упрощает изготовление функционирующих плат, устройств, что уменьшают стоимость системы и повышают её надежность. Таким образом, интеграция функционирующей системы на кристалле, улучшает все общетехнические показатели системы. В качестве примера можно привести изготовление стандартных интерфейсов на одном кристалле для сетевых и телекоммуникационных соединений.
Структура ЭВМ В современных компьютерах реализуется Фан Теймана. В этой концепции архитектура ЭВМ поддерживает следующие принципы: 1. Двоичное кодирование внутреннего содержания. 2. Программное управление работы машины. 3. Однородность использованной памяти. 4. Адресуемая память. В классическом случае машина по принципам Фан Теймана содержит следующие блоки: 1. Оперативная память. 2. Арифметико-логическое устройство. 3. Устройство управления. 4. Устройство ввода/вывода. Структурная схема ЭВМ в этом случае имеет след вид:
Оперативная память предназначена для хранения, как команд, так и данных, представляющие собой двоичные коды и на первый взгляд не различимы. Это принципиально важно, поскольку позволяет иметь память с единой адресацией, что позволяет упростить программирование. АЛУ – арифметико-логическое устройство УУ – устройство управления РАП – регистр адреса памяти ШАП – шина адреса памяти РДП – регистр данных памяти ДАП – дешифратор адреса памяти Блок управления формирует сигналы управления (последовательность микроопераций) для выполнения команд программирования. Регистр адреса памяти содержит адрес той ячейки, в которой будет происходить обращение в данный момент. Выбор этой ячейки по адресу осуществляется с помощью дешифратора адреса памяти. Обмен данными (и командами) между процессором и памятью осуществляется по шине данных в памяти. Этот обмен происходит через регистр данных в памяти. Любая ЭВМ работает синхронно с поступлением тактовых импульсов от внутреннего генератора. Выполнение программы является сложным процессом и поэтому на её выполнение требуется несколько периодов тактовых импульсов. Время выполнения команды называется циклом. Если команда простая, то она выполняется за один машинный цикл, а если сложная, то может потребоваться несколько машинных циклов.
Структура машинного цикла Машинный цикл схематично можно представить следующим образом:
Совокупность цикла выборки и исполнительного цикла составляет машинный цикл.
Структура и типы команд Для работы компьютера команда задает операцию и те данные, над которыми эта операция должна быть выполнена. Обычно тип операции задаётся кодом внутри команды. Также внутри команды задаются тем или иным способом операнды, т.е. в общем случае команда задает следующие условия: какую выполнить операцию, с какими операндами её выполнить и куда поместить результат? Информация по каждому из этих разделов задается в команде в специальном коде. В общем случае команда состоит из следующих полей:
Регистр команд служит для хранения команды в процессе её дешифрации и выполнения. К каждому полю регистра команд подключен свой дешифратор.
На выходе дешифратора в зависимости от кода операции появляется сигнал, который запускает соответствующую цепочку действий по выполнению операции. Код способа адресации и код адреса операнда с помощью операндов позволяют вычислить физические адреса операнда. В случае 2х местной операции, т.е. операции с двумя операндами, команда должна задавать: 1. Операцию 2. Адрес 1го операнда 3. Адрес 2го операнда 4. Адрес сохранения адресата 5. Адрес следующей команды Если все эти адреса задать в явном виде, то команда будет иметь следующие поля:
Чтобы иметь возможность строить длинные программы, эти поля адресов должны иметь достаточное количество разделов. Поскольку современные ЭВМ должны иметь 16р., 32р., 64р., то длинная команда не укладывается в одномашинное слово 16разрядов, т.е. необходимо будет размещать машинную команду в несколько машинных слов и соответственно в несколько ячеек памяти, т.е. резко удлиняется процесс выборки команд, а следовательно падает быстродействие ЭВМ. Существует несколько способов, которые позволяют сократить длину команды.
Х адресные команды Если расположить команды программы в соседних ячейках таким образом, что в следующей ячейке находится следующая команда, то от 4го адреса можно избавиться.
Но тогда нам надо знать номер или адрес этой ячейки памяти, в которой будет храниться следующая команда, т.е. иметь такой регистр, который указывает нам на адрес следующей команды. Такое устройство называется – счетчик команд. Программу представляем в виде некоторой ленты, расположенной в соседних ячейках памяти, а счетчик команд указывает на ту ячейку, где хранится следующая команда.
Х адресные команды В этом случае отказываемся от указания адреса результата и записываем результат по адресу одного из операндов
т.е. результат записывается поверх самого операнда, при этом значение операнда теряется, но длина команды существенно сокращается.
Здесь Адрес 1 – адрес источника Адрес 2 – адрес приема
Поскольку второй операнд после выполнения операции теряется, то нужно пересылать операнды из одного места в другое. Это потребовало в архитектуру специальные команды – пересылка данных.
О адресные команды Предположим, что мы избавляемся от задания адреса одного из операндов. Тогда мы должны знать, где всегда находится один из операндов.
Если мы введем в состав АЛУ специальный регистр, в который будем заранее помещать один из операндов, то адресовать в команде нужно будет только второй операнд. Такой регистр называется – регистр-аккумулятор, т.е. в этот регистр помещается один из операндов и также оказывается результат операции. Поскольку быстродействие памяти меньше быстродействия регистров, то для то для повышения всей системы в целом разработчики пошли дальше и кроме одного регистра добавили ещё несколько адресуемых регистров – регистры общего назначения. При этом появилось 2 вида команд: регистр/регистр, регистр/память. Регистр/регистр являются наиболее компактными и быстродействующими.
Схема взаимосвязи регистров в процессоре. .
|
||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-06-06; просмотров: 193; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.149.232.87 (0.01 с.) |