Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Advancd Linear/ Nonlinear Models Nonlinear estimationСодержание книги
Поиск на нашем сайте Нестандартні типи регресій
Advanced Linear/ Nonlinear Models > Time Series Аналіз часових рядів: визначення законів циклічності, періодичності, тренду, дослідження стохастичної компоненти.
Multivariate Exploratory Techniques > Discriminant Analysis Дискримінантний аналіз: знаходження визначальних показників для класифікації об’єктів у задані групи
Multivariate Exploratory Techniques >Cluster Analysis Кластерний аналіз: поділ даних на групи за певними ознаками (наприклад, поділ країн на групи за показником ВВП) Multivariate Exploratory Techniques >Factor Analysis Факторний аналіз: проблеми класифікації і вибору показників, які є головними для опису даного явища
Виберемо File > New. У діалоговому вікні, що відкрилося (див. рис. 2), можемо вибрати кількість змінних і випадків, а також розміщення таблиці даних, яку ми створюємо.
Рис. 2
Стандартна таблиця даних має розмір 10х10, де стовпці відповідають змінним (VAR1,VAR2,…,VAR10), а рядки – випадкам зі значеннями, яких набувають змінні. Опція InanewWorkbook розмістить новостворену таблицю у робочій книзі, в яку також будуть записуватися всі графіки, діаграми і таблиці, отримані у процесі роботи з даними. Опція Asa standalonewindow створить таблицю в окремому вікні так, що дані можна буде зберегти окремо виконавши File > Save при активізованій таблиці. Слід зазначити, що STATISTICA7 оперує з “робочими книгами” – спеціальними файлами, в яких зберігається, залежно від обраних користувачами опцій, та чи інша інформація і результати роботи. Коли ви починаєте виконувати певні дії в пакеті, автоматично буде створено файл звіту. На вкладці Report можна вибрати розміщення даних звіту (опції аналогічні згаданим раніше). Натискаємо OK внизу вікна Createnewdocument. З’явиться нова порожня таблиця. Якщо ми хочемо змінити кількість змінних, то натиснемо на верхній панелі кнопку VARS > Add. У вікні, що з’явилося (див. рис. 3), вказуємо скільки змінних ми хочемо додати і після якої змінної вставити нові змінні. Також можна обрати ім’я змінної (Name) за замовчуванням, тип даних (Type) і довге ім’я (Long Name).
Рис.3
Перемістити змінні можна таким чином: натиснути на верхній панелі кнопку VARS > Move (або виділити змінну і натиснути праву кнопку миші для отримання контекстного меню в якому вибираємо MoveVariables). Вказуємо, з якої по яку змінну ми хочемо перемістити, і після якої змінної їх вставити (див. рис. 4). Аналогічно, операції VARS > Copy, VARS > Delete (або Copy Variables і Delete Variables в контекстному меню) дають змогу скопіювати певні змінні, вставивши їх після вказаної нами змінної, та видалити вказані користавачем змінні. Аналогічно всі згадані операції виконуються з випадками за допомогою меню Cases верхньої панелі.
Рис. 4
Виділимо якусь змінну, натиснувши на її ім’я лівою кнопкою миші (LC), далі натиснемо праву кнопку миші (надалі RC) та виберемо VariableSpecs. На екрані з’явиться вікно опису даної змінної (див. рис. 5).
Рис. 5
Дамо короткий опис полів для заповнення:
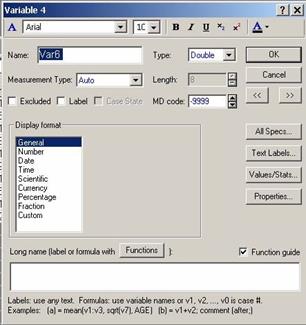
A Опції для вибору різних характеристик шрифтів Name Ім’я змінної Type Вибрати тип даних – байти, ціле число, текст і т.д. Length Ширина колонки даної змінної (для тексту) Excluded Виключити змінну з подальшого аналізу Label Використовувати значення змінної як тексові мітки, наприклад для точок на графіку MD Code (missing data code) – значення, яке за замовчування присвоюється змінній, якщо її справжнє значення відсутнє з якихось причин. (Наприклад, у нас немає спостережень даного показника у в окремі роки) Display format Вибір формату відображення числа (як дата, тощо). Long name Поле, в якому можна задавати формулу для обчислення значення даної змінної.
Кнопки мають такі функції: <<, >> для переходу до попередньої і наступної змінної, яку відображає даний діалог; All specs відкриває таблицю з усіма специфікаціями змінних; Values/Stats дає змогу дізнатися „швидку статистику” – значення окремих випадків, середнє арифметичне, стандартне відхилення та інше (див. рис. 6). Кнопка Functions відкриває вікно вибору функцій для формули, яка визначатиме значення змінної.
Проілюструємо це на прикладі. Для цього заповнимо колонки перших двох змінних довільними значеннями. Далі виділимо третю змінну, натиснемо RC > VariableSpecs. У полі LongName напишемо: =v1+v2. Далі двічі натиснемо OK. Бачимо, що тепер змінна VAR3 є сумою VAR1 та VAR2. Зауваження: імена v1,v2,… за замовчуванням присвоюються по порядку першій, другій, і т.д. змінним. Якщо ім’я першої змінної буде VAR10, то v1 буде відповідати саме змінній VAR10.
Якщо змінюються значення незалежних змінних, то перерахувати залежну змінну можна натиснувши на верхній панелі кнопку VARS > Recalculate або кнопку x=?.
Рис. 6 Інколи бувають потрібні не точні значення змінних, а їх порівняння з іншими значеннями цієї ж змінної, тобто треба замінити значення змінної на їх місце у варіаційному ряді за зростанням чи спаданням. Ранжування змінної - це впорядкування за зростанням чи спаданням. Воно виражається в присвоєнні кожному значенню певного рангу – порядкового номера в списку впорядкованих значень. Для здійснення цієї операції натискаємо VARS > Rank. У вікні, що з’явиться (див. рис. 7), вибираємо: найбільшому чи найменшому значенню присвоїти ранг 1 (тобто за спаданням чи за зростанням будуть впорядковані значення), а також обираємо опцію Mean (якщо хочемо, щоб однакові значення мали однаковий усереднений ранг) або Sequential (якщо хочемо, що однакові значення мали послідовні значення рангу). Зсув всіх даних вниз на кілька позицій: виділити стовпчик, Vars->Shift(Lag). Інколи буває потрібно розбити значення змінних на групи (наприклад, якщо певний показник більший за певну величину або менший за цю величину). Виділяємо, наприклад, першу змінну, далі натискаємо VARS > Recode. У першому полі Include If пишемо умову для потрапляння значення змінної у групу: v1<5. У другому полі IncludeIf пишемо: v1>=5. У полях NewValue1 та NewValue2 вибираємо 1 та 2 відповідно (див. рис. 8). Натискаємо ОК і зберігаємо змінені значення. Бачимо, що всі значення, що були менші за 5, отримали нове значення 1, а ті, що були не менші за 5 отримали значення 2.
Рис. 7
Рис. 8
Оскільки візуально краще працювати з текстом, який би вказував назви груп, на які ми щойно розбили значення змінної, то виконаємо Data > TextLabelsEditor і для значень 1 та 2 введемо назви груп, наприклад male та female і натиснемо Enter. Натискаючи кнопку Show/HideTextLabels на верхній панелі бачимо, що у всіх клітинках замість числових значень з’явились назви груп. Для заповнення значень змінної можемо використовувати послідовність команд RC > Fill/Standartize Block > Fill Random Values. У результаті змінна буде заповнена випадковими значеннями. Генерація даних, розподілених за певним законом. Якщо ми хочемо якусь змінну заповнити, наприклад, вибіркою, нормально розподіленою з параметрами Інші закони розподілу задаються аналогічно, наприклад:
Якщо хочемо заповнити весь стовпчик або весь рядок одним й тим самим значенням, то набираємо це значення в першій клітинці. Далі починаючи з цієї ж клітинки виділяємо вниз або вправо стовпчик чи рядок відповідно і натискаємо RC > Fill/StandartizeBlock > Fill/CopyDown або RC > Fill/Standartize Block > Fill/CopyRight відповідно. Якщо ми хочемо заповнити стовпчик арифметичною прогресією, то в перших двох клітинках вводимо два перші члени арифметичної прогресії, виділяємо ці клітинки, переміщуємо курсор у правий нижній кут виділеної області, доки він не змінить форму хрестика і тягнемо вниз з натиснутою лівою кнопкою миші до тієї клітинки, до якої потрібно заповнити стовпчик. Для зміщення всіх даних у змінній, як одне ціле, на кілька позицій використовуємо на верхній панелі кнопку VARS > Shift (Lag). Для стандартизації змінних використовуємо на верхній панелі кнопку VARS > Standardize. Створені нами дані ми можемо зберігати в різних форматах. Для цього при виділеному окремому вікні з даними натиснемо File > Saveas. Далі маємо можливість вибрати формат, в якому хочемо зберегти інформацію. Якщо дані містяться в робочій книзі, клацаємо правою клавішею миші на назві таблиці в дереві документів (зліва) і вибираємо Saveitemas. Потрібну таблицю, графік можна виокремити з робочої книги за допомогою команди Extractasastandalone, якщо відмітити їх у робочій книзі і натиснути праву клавішу миші (див. рис. 1.9). Якщо у нас є дані в Excel і ми хочемо частину з цих даних скопіювати у файл в Statistica, то існує два способи це зробити: 1. за допомогою звичайних операцій Copy в Excel і Paste в Statistica, 2. або знову ж таки Copy в Excel та Edit > Paste special > Paste Link в Statistica. Другий спосіб має ту перевагу над першим, що при зміні даних в таблиці Excel, дані в файлі Statistica теж будуть відповідно змінюватися, а при першому способі цього не відбудеться. Якщо після внесення даних в файл з допомогою PasteLink подивитися на Edit > Link, то побачимо там запис про те, з яким файлом встановлено динамічний зв'язок – в нашому випадку на файл Excel.
Рис. 9
Для створення звіту – тобто файлу, в якому будуть записані результати всіх дій, що ми проводимо, таблиці, графіки тощо – натискаємо File > OutputManager (див. рис. 10). Вибираємо опцію, щоб інформація автоматично відсилалась до файлу звіту, потім визначаємо, чи створюватиметься окремий звіт для кожного графіку/аналізу, чи в одному вікні зливатиметься вся звітність, чи створиться файл звіту із вказаним іменем. Аналогічно у верхній частині вікна можна вибрати опції щодо використання робочих книг.
Рис. 10
Розглянемо типи файлів пакету Statistica. Про інформацію, що міститься у файлах, свідчить розширення файлу:
.sta Файли з даними у вигляді таблиць .stw Файли робочих книг .stg Файли з графіками .str Файли звіту .svb,.svx Файли STATISTICA Visual Basic чи макроси .stm Файли матриць .snn Файли нейронних мереж .sdm Файли проектів модуля Data Miner .sti Файли на віддалених серверах
Для роботи з усіма змінними таблиці даних або кількома файлами даних використовуємо меню Data. Наприклад, щоб транспонувати таблицю даних виконуємо Data > Transpose > File. Іноді виникає потреба об’єднати дані з двох файлів в один. Наприклад, потрібно додати спостереження з показниками підприємств за нові роки, або додати нові показники діяльності підприємств до тих, що вже спостерігаются протягом певного часу. Для цього виконуємо Data > Merge. У вікні, що з’явиться (див. рис. 11), вказуємо імена файлів з якими будуть здійснюватися операції і вибираємо опції об’єднання на закладках Variables чи Cases.
Рис. 11
Розглянемо як створювати макроси, які дають змогу автоматизувати виконання деякої послідовності команд. Натиснемо Tools > Macro > Start Recording Log of Analyses (Master Macro) (див. рис. 12).
Рис. 12
Індикатором того, що запис команд почався і триває, слугує віконце з кнопками управління записом. Наприклад, виберемо на верхній панелі Graphs > Histograms потім натиснемо Variables > Select all > Ok ще раз натиснемо Ok. Отримаємо гістограми усіх змінних. Після цього перейдемо в верхнє меню Statistics > Basic statistics/Tables > Descriptive statistics > OK. Знову оберемо змінну: Variables > Select all > Ok. Натиснемо кнопку Summary. З’явиться таблиця з описовою статистикою всіх змінних. Для закінчення запису макросу натиснемо кнопку зупинки макросу. У вікні, яке з’явиться (див. рис. 13), натискаємо Ok. Бачимо текст STATISTICA Visual Basic з послідовністю виконаних операцій (див. рис. 14).
Рис. 13
Рис. 14
Натискаємо File > Save as Global Macro і зберігаємо макрос в головну директорію, в якій встановлено пакет Statistica. Щоб виконати макрос вибираємо на верхній панелі Tools > Macro > Macros. Відмічаємо потрібний макрос у вікні, що з’явилось, і натискаємо Run (див. рис. 15). Потім оберемо Tools > Customize. Відмітимо на закладці Toolbars категорію Macro– з’явиться нова панель інструментів. На закладці Command/Macros виберемо категорію Macros (див. рис. 16), і потім перетягнемо створений раніше макрос в панель інструментів. Тепер після натискання кнопки з назвою макросу будуть автоматично побудовані гістограми і проведена описова статистика змінних. Аналогічно можна записувати макрос, що відтворює послідовність дій з клавіатури (Tools > Macro > Start Recording Keyboard Macros). У цьому випадку команди, що будуть записані в макрос, повинні бути введені тільки за допомогою клавіатури.
Рис. 15
Рис. 16
Описова статистика
Якщо потрібно знайти значення теоретичної функції розподілу в певній точці, або, вказавши значення функції розподілу, знайти квантиль, то для цього можна скористатися імовірнісним калькулятором: Statistics > ProbabilityCalculator > Distribution (див. рис. 17).
Рис. 17
Панель ProbabilityDistributionCalculator (див.рис. 2.2) дає змогу подивитися, як виглядає один із даних нам розподілів. Змінюючи значення параметрів розподілу, будемо бачити автоматичну зміну щільності розподілу (Density Function) та функції розподілу (Distribution Function). Задавши значення в полі X після натискання Compute в полі р з’явиться значення функції розподілу F(x). Аналогічно в полі р можна задати ймовірність від 0 до 1, тоді після натискання Compute в полі X з’явиться значення квантилі рівня p. Якщо відмітити CreateGraph та SendtoReport і натиснути Compute, то в окремих вікнах отримаємо, відповідно, графік та звіт (див. рис. 18).
Рис. 18
Розглянемо модуль Basic Statistics/Tables. Натиснемо Statistics > BasicStatistics/Tables (див. рис. 2.3) і зайдемо в розділ Descriptive Statistics. Відкриємо файл Adstudy.sta (…\STATISTICA 7\Examples\ Datasets\), у якому зібрані дані про оцінки чоловіками та жінками реклами напоїв Pepsi та Coke. Кожен опитуваний оцінював рекламу по різних показниках, виставляючи оцінку від 0 до 9 (див. рис. 19).
Рис. 19
Рис. 20
Активізуємо вікно DescriptiveStatistics з нижньої панелі. В полі Variables вкажемо 3-Measure01. В закладці Quick знаходяться найбільш вживані описові статистики, таблиця частот, гістограма, а також „коробка з вусами” (див. рис. 21). Для того щоб побачити описові статистики натиснемо Summary. В інших закладках ми можемо налаштувати і подивитись детальніші характеристики.
Рис. 21
Так, якщо вибрати закладку Advanced, а потім натиснути Selectallstats та Summary то отримаємо інші характеристики даних (див. рис. 22). Зокрема, значення Skewness показує коефіцієнт асиметрії, тобто наскільки розподіл "скособочений". А значення Kurtosis показує наскільки розподіл "пікоподібний". Для стандартного нормального розподілу Skewness та Kurtosis дорівнюють нулю. Повернемось до закладки Quick. Натиснувши кнопку FrequencyTables отримаємо таблицю частот для нашої вибірки. Натиснувши кнопку Histograms отримаємо гістограму, на якій червоною лінією зображено підігнану криву нормального розподілу (див. рис. 23). В закладці Options ми можемо обрати тип "коробки з вусами". Оберемо перший тип Median/Quart/Range. Повернемось у закладку Quick і натиснемо Box & whisker plot for all variables – з’явиться вікно з рисунком коробки з вусами, в якій маленький прямокутник відповідає значенню медіани, великий прямокутник – нижній та верхній квартилі, а вуса – найменшому та найбільшому значенню вибірки (див. рис. 22).
Рис. 22
Рис. 23
Рис. 24
В закладці Categorized Plots натиснемо Categorized box & whisker plots (див. рис. 25). Далі оберемо 1-GENDER, як першу змінну, 2-ADVERT, як другу. Третю змінну вказувати не будемо і натиснемо ОК. З’явиться вікно Select Codes for the grouping variables. Для Gender, і для Advert виберемо ALL (див. рис. 26). Натиснемо ОК. У вікні, що з’явиться (див. рис. 27), отримуємо коробки з вусами окремо для Pepsi і Coke, і окремо для чоловіків і жінок (male і female). Бачимо, що реклама Pepsi подобається чоловікам більше, ніж жінкам. Для реклами Coke у жінок розкид уподобань більший, ніж у чоловіків. Зауважимо, що отримані дані стосуються першої вибірки. Для того, щоб візуально побачити, наскільки наша вибірка відповідає нормальному закону розподілу у вікні Descriptive Statistics в закладці Prob. & Scatterplots натиснемо Normal Probability Plots (див. рис. 28).
Рис. 25
Рис. 26
Рис. 27
Рис. 28
Чим ближче точки розміщені до прямої, на графіку який з’явився, тим краще Закон нормального розподілу описує розподіл наших даних (див. рис. 29). Якщо ми хочемо вибирати той тип розподілу з яким візуально найкраще узгоджується наша вибірка, то виконуємо Graphs > 2D Graphs > Quantile-QuantilePlots (див. рис. 30). Перейдемо на закладку Advanced. За допомогою кнопки Variables задаємо потрібну змінну. У полі Distribution вибираємо розподіл, на відповідність якому хочемо перевірити нашу вибірку (див. рис. 31) і натискаємо ОК. У результаті отримуємо Q-Q графік, точки якого тим ближче розміщені до прямої, чим краще заданий тип розподілу описує наші даних. Наприклад, з рисунка 32 видно, що експоненційний розподіл візуально не підходить до наших даних.
Рис. 29
Рис. 30
Рис. 31
Рис. 32
Контрольні запитання 1. Перечисліть назви модулів, які доступні в меню Statistics. 2. Як перемістити змінні в таблиці даних, скопіювати, видалити їх? 3. Кожному рядку в таблиці даних відповідає змінна чи випадок? І відповідно, що відповідає кожному стовпчику таблиці даних: випадок чи змінна? 4. Що таке MD Code у вікні опису змінної? 5. Чи залежать імена змінних у вигляді v1, v2, v3 в полі LongName вікна властивостей від імен змінних у полі Name і в таблиці даних (напр. var1, var5 і т.п.). Чи вплине на формулу (=v1+v2) записану в полі Long name переіменування змінної var1 в полі Name на var10? 6. Як перерахувати значення залежної змінної, розраховані за формулою, після того, як змінилися значення незалежних змінних? 7. Що таке ранжування змінної? В числовому ряді 12, 3, 5, 92, 43 в результаті ранжування за зростанням якого значення набуде «92»? 8. Як заповнити змінну випадковими значеннями згенерованими за певним законом розподілу? Як заповнити стовпчик арифметичною прогресією? 9. Скільки відсотків значень змінної лежать вище квантилі xp= 0.47? 10. Які закони розподілу вам відомі? 11. Як запустити імовірнісний калькулятор?
Лабораторна робота 6 Лінійна регресія
Створимо новий файл, в якому змінну VAR1 заповнимо послідовно значеннями від 0 до 10, змінну VAR2 – випадковими значеннями від 0 до 1, а змінну VAR 3 задамо, як суму VAR1+ VAR2. Виконаємо послідовність команд: Statistics -> Basic Statistics/Tables -> Descriptive Statistics -> Prob.&Scatterplots (див. рис. 1).
Рис. 1
Як Variables виберемо VAR1-VAR3, натиснемо кнопку 2D Scatterplot. У першому списку змінних вкажемо VAR1, в другому – VAR3 і натиснемо кнопку ОK (див. рис. 2). На графіку, що з’явився, зображено пряму лінійної регресійної моделі для VAR3 через VAR1, а у верхній частині вікна бачимо рівняння лінійної регресії (див. рис. 3).
Рис. 2
Рис. 3
Якщо у змінній VAR3 замінити одне із значень, наприклад на 70, і побудувати графік знову, то побачимо, що рівняння регресії буде враховувати дане значення і з графіка буде очевидно, що 70 є викидом (див. рис. 4). Натиснемо піктограму Brushing. У вікні, що з’явиться зробимо активними Exclude та Box, виділимо прямокутником значення (див. рис. 5) і натиснемо кнопку Apply. Виділене значення зникне з графіка і регресійна пряма змінить своє положення. Для того, щоб значення викиду не виводилось у наступних графіках та не враховувалось при обчисленні регресійної формули, у змінній VAR4 заповнимо всі значення одиницями, а те значення, що стоїть напроти викиду – нулем (див. рис. 6).
Рис. 4
Рис. 5
Рис. 6 У вікні Descriptive Statistics натиснемо кнопку Weight (див. рис. 1). Оберемо змінну VAR4, перемкнемо Status на On та натиснемо OK (див. рис. 7). Тепер при аналізі викиди враховуватися не будуть.
Рис. 7 Нехай маємо таку таблицю з даними:
де Y – врожайність, X – добрива, Z – опади. Потрібно знайти формулу багатофакторної лінійної регресії для Y:
Y=B0 +B1 X+B2 Z,
де Bі – невідомі коефіцієнти. Виконаємо послідовність команд: Statistics -> Multiple Regression, як змінні оберемо Y – залежна, X і Z – незалежні (див. рис. 8). Натиснемо OK. Отримуємо результат, який зображено на рис. 9.
Рис. 8
Рис. 9
В закладці Quick натиснемо кнопку Summary: Regression results. У вікні, що з’явилось (див. рис. 10), бачимо оцінки параметрів та допоміжну статистику. Обидві змінні значимі (виділені червоним). У третьому стовпці таблиці вказані оцінки для коефіцієнтів Bі. Отже, Y=28.095+0.038*X+0.833*Z. Якщо наші змінні попередньо стандартизувати, то у результаті такого регресійного аналізу отримали б оцінки коефіцієнтів, які записані в першому стовпчику таблиці (зрозуміло, що В0=0). Коефіцієнти з першого стовпця показують внесок у регресійну модель змінних X та Z.
Рис. 10
Для того, щоб обчислити передбачуване значення для Y для заданих X та Z і побудувати 95% проміжок надійності, перейдемо у закладку Residuals/assumptions/prediction і натиснемо Predict dependent variable (див. рис. 11). У відповідні віконця вводимо значення змінних X та Z (див. рис. 12) і натискаємо OK. Якщо незалежні змінні набувають одного і того ж значення його можна ввести у віконці Common Value і натиснути Apply. У вікні результатів аналізу (див. рис. 13) бачимо передбачуване значення Y, верхню і нижню межу надійного проміжку для цього значення.
Рис. 11
Рис. 12
Рис. 13 Якщо ж потрібно подивитись як розподілені залишки, то натиснемо кнопку Perform residual analysis. У вікні, що з’явилось (див. рис. 14), зібрані різні методи для аналізу залишків регресійної моделі.
Рис. 14 Наприклад, натиснувши Normal plot of residuals отримаємо Q-Q графік, на якому видно наскільки залишки узгоджуються з нормальним законом розподілу (див. рис. 15).
Рис. 15 Контрольні запитання 1. Як створити новий документ з трьома змінними? Як заповнити змінну послідовно значеннями 1, 2, 3, 4, 5 і т.д. Як заповнити змінну випадковими величинами від 0 до 1? (Опишіть послідовність дій) 2. Як виключити з розрахунку і побудови графіків викиди? 3. Як можна забезпечити, щоб значення викиду не виводилось у наступних графіках та не враховувалось при обчисленні регресійної формули? 4. Як знайти формулу багатофакторної лінійної регресії? У чому полягає відмінність між однофакторною і багтофакторною регресією? Лабораторна робота №7 Багатофакторна регресія
Відкриємо файл Job_prof.sta (див. рис. 1). У файлі вказано бали, отримані претендентами під час тестування при прийнятті на посаду (у перших чотирьох стовпцях), та оцінка професійної здатності претендентів (у п’ятому стовпці) після закінчення випробувального терміна. Нам потрібно знайти лінійну багатофакторну регресійну модель залежності оцінки професійної здатності від оцінок за тести. Завантажимо модуль Multiple Regression: Statistics -> Multiple Regression.
Рис. 1
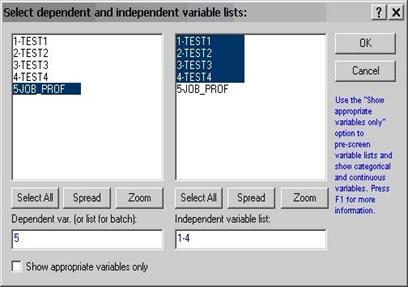
Натиснувши Variables, обираємо Job-Prof, як залежну змінну, а як незалежні змінні вибираємо перші чотири змінні (див. рис. 2). Двічі натискаємо ОK. Результати регресійного аналізу зображені на рисунку 3. Всі змінні, окрім другої, є значимими (виділені червоним). У закладці Quick натиснемо Summary: Regression result (див. рис. 3). У вікні, що з’явилось (див. рис. 4), бачимо результати аналізу: у третьому стовпці – коефіцієнти багатофакторної лінійної регресійної моделі, а в першому стовпці – коефіцієнти цієї ж регресійної моделі для стандартизованих змінних. Проаналізувавши результати прийдемо до висновку, що Test 2 досить мало впливає на оцінку професійної здатності претендентів: відповідний коефіцієнт у першому стовбці становить 0,043. Тому можливо є доречним взагалі вилучити Test 2 з регресійної моделі.
Рис. 2
Рис. 3
Рис. 4
Проведемо спочатку аналіз залишків побудованої моделі. У закладці Residuals/assumptions/prediction, натиснемо кнопку Perform residual analysis. У вікні, що з’явилось, обираємо Residuals -> Casewise plot of residuals (див. рис. 5).
Рис. 5
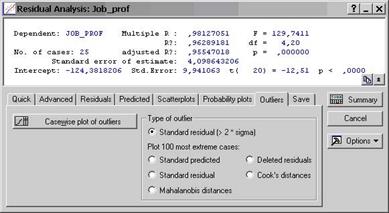
Так ми перевіримо, чи не виходять залишки за межі 3δ. Отримаємо таблицю (див. рис. 6), в якій знаком «*» вказано де знаходиться залишок у інтервалі (-3δ; 3δ). У правій частині таблиці міститься додаткова інформація про залишки. Бачимо, що залишки лежать у проміжку (-2δ; 2δ) і їхні середнє і медіана дорівнюють нулю. Потім оберемо закладку Outliers (див. рис. 7). Натиснемо Casewise plot outliers та упевнимося, що викидів немає – з’явиться відповідне повідомлення (див. рис. 8).
Рис. 6
Рис. 7
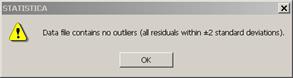
Рис. 8
На основі цих результатів можна вважати, що багатофакторна регресійна модель достатньо добре описує наші дані. Цікаво дослідити, що відбудеться, якщо вилучити змінну Test 2, яка досить мало впливає на оцінку професійної здатності претендентів, з регресійної моделі. Розглянемо, як автоматизовано процес знаходження змінних, які дають малий внесок у регресійну модель, у пакеті Statistica. У вікні Multiple Regression у закладці Advanced відмітимо Advanced options (stepwise or ridge regression) та натиснемо OK (див. рис. 9).
Рис. 9
У закладці Stepwise вкажемо метод Forward stepwise – змінні будуть введені у регресійну модель по одній. У Display results вкажемо покроковий вивід результатів – At each step (див. рис. 10). Тобто ми будемо здійснювати покрокову регресію, з виводом результатів після кожного кроку. У полі F to enter вказуємо значення 1, а у полі F to remove вказуємо 0.01. Ці два числа визначають верхню та нижню межі проміжку для значимості внеску у регресійну модель змінних. Якщо значимість змінної потрапляє в цей проміжок, то включаємо її до регресійної моделі, інакше – відкидаємо.
Рис. 10
Оскільки маємо чотири незалежні змінні, то кількість кроків множинної регресії Number of steps досить вказати рівною чотирьом (після кожного кроку до моделі може включатись не більше однієї змінної). Натискаємо кнопку OK. У вікні, що з’явилось, бачимо, що в моделі ще немає жодної змінної (див. рис. 11). Натискаємо Next. З’явився перший коефіцієнт та перша, вибрана до рівняння регресії змінна (див. рис. 12). Натискаємо кнопку Next, допоки на цій кнопці не з’явиться напис ОК. Це означатиме, що процедуру вибору змінних до регресійної моделі закінчено і всі змінні значимість внеску яких знаходиться у вказаних межах увійшли до рівняння регресії. Бачимо, що змінна Test 2 не увійшла у нову багатофакторну регресійну модель (див. рис. 13). Далі можемо подивитися результати. Для цього натиснемо на закладці Advanced, кнопку Stepwise Regression Summary (див. рис. 14). У вікні, що з’явилось (див. рис. 15), бачимо, статистику внеску обраних змінних і порядок включення їх у регресійну модель. Якщо натиснемо на закладці Advanced, кнопку Summary: Regression results (див. рис. 14), то у вікні, що з’явилось (див. рис. 16), побачимо з якими коефіцієнтами змінні увійшли до регресійної моделі. Використовуючи отриману інформацію (рис.15 і 16) можемо порівняти стару і нову регресійну моделі. Бачимо, що вони майже не відрізняються. Отже, внесок змінної Test 2 дійсно був незначним.
Рис. 11
Рис. 13
Рис. 15
Рис. 16
Якщо є мультиколінеарність змінних (наприклад, в кількох стовпцях містяться дані про ціну одного і того ж товару в різних валютах), то очевидно, що для регресійної моделі слід взяти не всі із таких змінних. Якщо для обробки таблиці мультиколінеарних даних так як і раніше скористатися стандартним алгоритмом, то з’явиться повідомлення про помилку (див. рис. 17).
Рис. 17
У цьому разі для регресійного аналізу потрібно вибирати метод Forward stepwise (який дозволяє вводити у модель по одній змінній), а не Standard.
Конторольні запитання 1. На рис. 4. представлені результати аналізу. Яким чином з рисунка можна визначити які змінні несуттєво впливають на регресійну модель? 2. На
|
||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 451; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.113 (0.041 с.) |







 , то ми повинні в специфікації змінної в полі Long Name написати =VNormal(rnd(1);0;1). Якщо заповнення не відбудеться відразу, то треба перерахувати змінну за допомогою Recalculate.
, то ми повинні в специфікації змінної в полі Long Name написати =VNormal(rnd(1);0;1). Якщо заповнення не відбудеться відразу, то треба перерахувати змінну за допомогою Recalculate.