Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
syms x y % создаем символьные переменныеСодержание книги
Поиск на нашем сайте
Порядок выполнения работы 1. Получить задание по одному из вариантов таблицы (п. 4). 2. Подготовить нечеткие правила в соответствии с графическим представлением функций задания. 3. Трехмерное изображение выбранной зависимости построить, вос- пользовавшись программными средствами MATLAB. При этом можно руководствоваться программой нижеприведен- ного примера, которая моделирует зависимость % Построение графика функции z = y.^2.*cos(x).^2
Рис.1
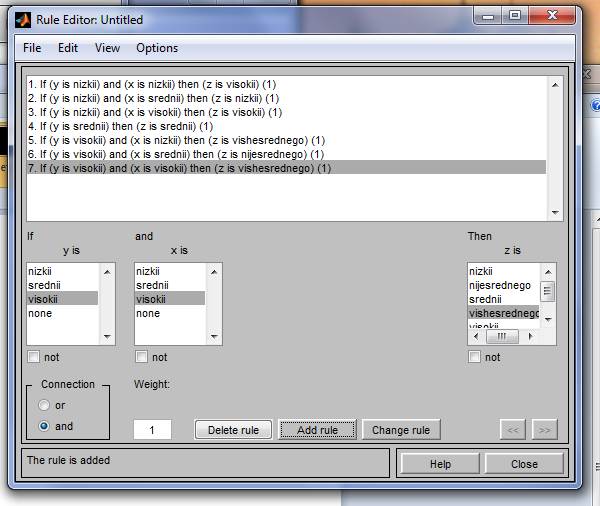
Можно воспользоваться и возможностями пакета Symbolic Math Toolbox, введя, например, следующие команды: syms x y % создаем символьные переменные Z = y.^2*cos(x)^2 ezsurf(z,[-1,1]) Для лингвистической оценки входных переменных х1 и х2 выберем по три терма - низкий, средний, высокий; для выходной y пять термов - низкий, ниже среднего, средний, выше среднего, высокий 1) ЕСЛИ Y = низкий И X = низкий, ТО y = высокий; 2) ЕСЛИ Y = низкий И х = средний, ТО y = низкий; 3) ЕСЛИ Y = низкий И х = высокий, ТО y = высокий; 4) ЕСЛИ Y = средний, ТО y = средний; 5) ЕСЛИ Y = высокий И x = низкий, ТО y = выше среднего; 6) ЕСЛИ Y = высокий И х = средний, ТО y = ниже среднего; 7) ЕСЛИ Y = высокий И х = высокий, ТО y = выше среднего 4. Спроектировать нечеткую систему, выполнив следующую последовательность шагов. 1. Открыть FIS–редактор, напечатав слово fuzzy в командной строке. 2. В появившемся графическом окне FIS Editor добавим вторую входнуюпеременную. Для этого в менюEdit выбираем команду Add input. 3. Переименуем первую входную переменную. Для этого сделаем щелчок левой кнопкой мыши на блоке Input 1, введем новое обозначение х1 в поле редактирования имени текущей переменной и нажмем <Enter>. 6. Зададим имя системы. Для этого в меню File выберем в под меню Export команду To File и введем имя файла, например, Lab_2.
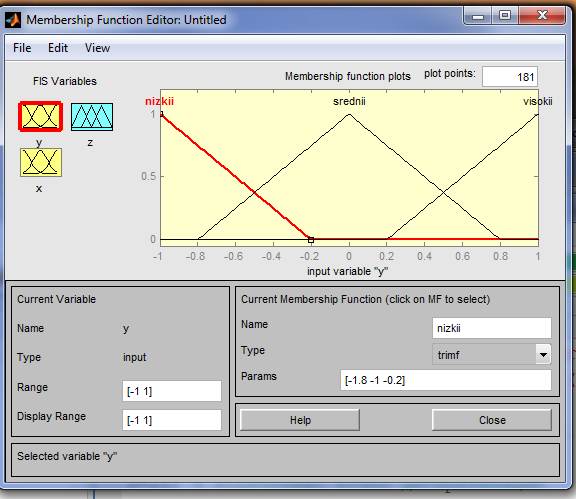
7. Перейдем в редактор функций принадлежности. Для этого сделаем двойной щелчок левой кнопкой мыши на блоке x1 и зададим диапазон изменения переменной х1, напечатав -6 4 в поле Range (рис. 2).
8.Зададим функции принадлежности переменной х1. Для лин- гвистической оценки этой переменной будем использовать три терма с треугольными функциями принадлежности. Эти функции установлены по умолчанию, поэтому переходим к следующему шагу
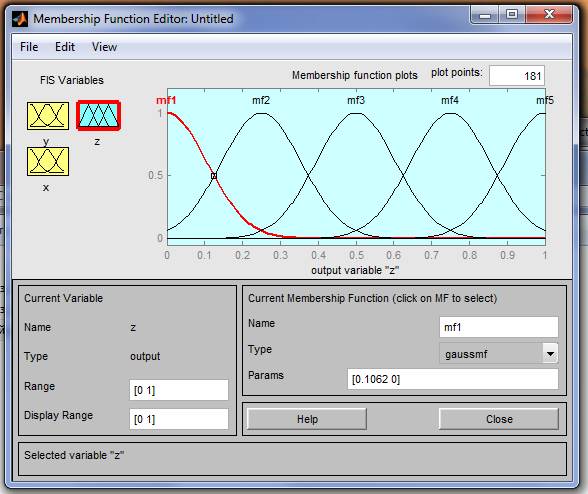
9.Зададим наименования термов переменной х1. Для этого щелкнем мышкой по графику первой функции принадлежности (см. рис. 2). График активной функции принадлежности выделяется крас- ной жирной линией. Затем введем наименование терма Низкий в поле Name и нажмем <Enter>. Щелкнем мышкой по графику второй функ- ции принадлежности, введем наименование терма Средний в поле Name и нажмем <Enter>. Щелкнем мышкой по графику третьей функции принадлежности, введем наименование терма Высокий в поле Name и нажмем <Enter>. 10. Зададим функции принадлежности переменной х2. Для этого активизируем переменную х2 щелчком мышкой по блоку х2.Зададим диапазон изменения переменной х2. Для этого напечатаем -4.4 1.7 в поле Range и нажмем <Enter>. Для лингвистической оценки этой переменной будем использовать, как и ранее, три терма с треугольными функциями принадлежности. Они установлены по умолчанию, поэтому переходим к следующему шагу удаления установленных по умолчанию функций принадлежности. После этого в меню Edit выберем команду Add MF В появившемся диалоговом окне выберем тип функции принадлежности gaussmf в поле МFtуре и пять термов в поле Number МFs. После ввода функций принад-лежности редактор активизирует первую входную переменную, поэтому для продолжения работы щелкнем мышкой по пиктограмме у.
13. По аналогии с шагом 9 зададим следующие наименования термов переменной у: Низкий, Ниже среднего, Средний, Выше среднего, Высокий. В результате получим графическое окно, изображенное на рис. 1.3.
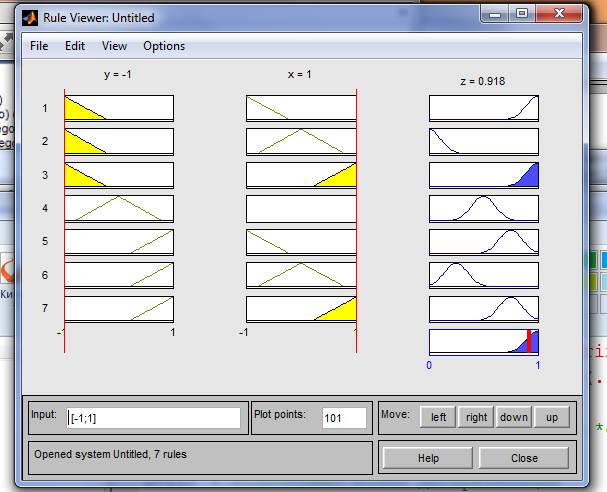
14. Перейдем в редактор базы знаний Rule Editor. Для этого в меню Edit выберем команду Rules... Для ввода правила выбираем в меню соответствующую комбинацию термов и нажимаем кнопку Add rule. На рис. 1.4 изображено окно редактора базы знаний после ввода всех семи правил. В конце правил в скобках указаны весовые коэф- фициенты.
На рис. 5 приведено окно визуализации нечеткого вывода. Окно активизируется командой Rules меню View. В поле Input указываются значения входных переменных, для которых выполняется нечеткий логический вывод.
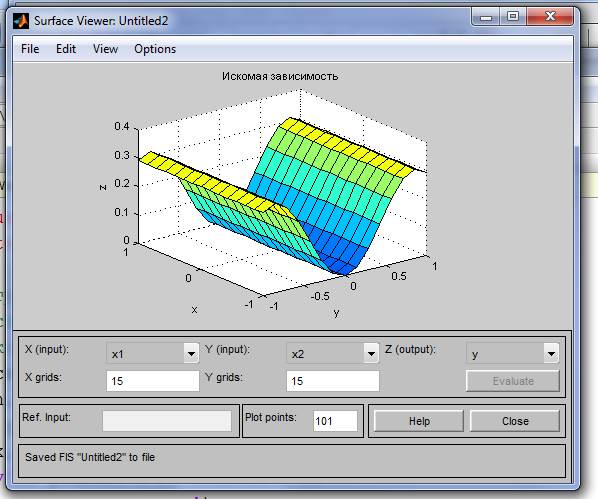
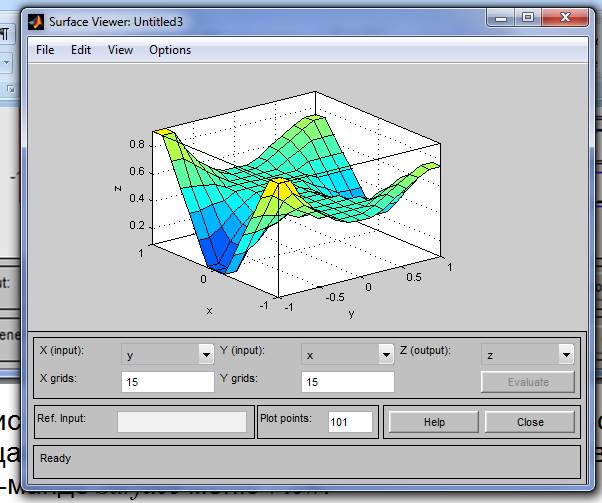
На рис. 6 приведена поверхность «входы - выход», соответст- вующая синтезированной нечеткой системе. Окно выводится по ко-манде Surface меню View.
Работа №2 Нейронные сети – это одно из направлений научных исследований в области создания искусственного интеллекта (ИИ) в основе которого лежит стремление имитировать нервную систему человека. В том числе ее (нервной системы) способность исправлять ошибки и самообучаться. Все это, хотя и несколько грубо должно позволить смоделировать работу человеческого мозга. Под искусственными нейронными сетями принято понимать вычислительные системы, имеющие способности к самообучению, постепенному повышению своей производительности. Основными элементами структуры нейронной сети являются: § Искусственные нейроны, представляющие собой элементарные, связанные между собой единицы. § Синапс – это соединение, которые используется для отправки-получения информации между нейронами. § Сигнал – собственно информация, подлежащая передаче. Область применения искусственных нейронных сетей с каждым годом все более расширяется, на сегодняшний день они используются в таких сферах как: § Машинное обучение (machine learning), представляющее собой разновидность искусственного интеллекта. В основе его лежит обучение ИИ на примере миллионов однотипных задач. В наше время машинное обучение активно внедряют поисковые системы Гугл, Яндекс, Бинг, Байду. Так на основе миллионов поисковых запросов, которые все мы каждый день вводим в Гугле, их алгоритмы учатся показывать нам наиболее релевантную выдачу, чтобы мы могли найти именно то, что ищем. § В роботехнике нейронные сети используются в выработке многочисленных алгоритмов для железных «мозгов» роботов. § Архитекторы компьютерных систем пользуются нейронными сетями для решения проблемы параллельных вычислений. § С помощью нейронных сетей математики могут разрешать разные сложные математические задачи. В целом для разных задач применяются различные виды и типы нейронных сетей, среди которых можно выделить: § сверточные нейронные сети, § реккурентные нейронные сети, § нейронную сеть Хопфилда. Сверточные сети являются одними из самых популярных типов искусственных нейронных сетей. Так они доказали свою эффективность в распознавании визуальных образов (видео и изображения), рекомендательных системах и обработке языка. § Сверточные нейронные сети отлично масштабируются и могут использоваться для распознавания образов, какого угодно большого разрешения. § В этих сетях используются объемные трехмерные нейроны. Внутри одного слоя нейроны связаны лишь небольшим полем, названые рецептивным слоем.
§ Нейроны соседних слоев связаны посредством механизма пространственной локализации. Работу множества таких слоев обеспечивают особые нелинейные фильтры, реагирующие на все большее число пикселей. Рекуррентными называют такие нейронные сети, соединения между нейронами которых, образуют ориентировочный цикл. Имеет такие характеристики: § У каждого соединения есть свой вес, он же приоритет. § Узлы делятся на два типа, вводные узлы и узлы скрытые. § Информация в рекуррентной нейронной сети передается не только по прямой, слой за слоем, но и между самими нейронами. § Важной отличительной особенностью рекуррентной нейронной сети является наличие так званой «области внимания», когда машине можно задать определенные фрагменты данных, требующие усиленной обработки. Рекуррентные нейронные сети применяются в распознавании и обработке текстовых данных (в частотности на их основе работает Гугл переводчик, алгоритм Яндекс «Палех», голосовой помощник Apple Siri). Содержание отчёта:
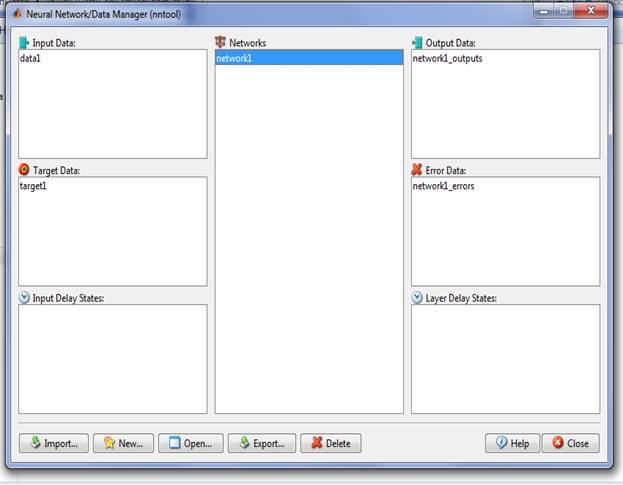
1. Цель работы. 2. Задание. 3. Описание алгоритма обучения. 4. Описание каждого этапа выполнения работы. 5. Сравнение работы алгоритма для 2-х заданных функций. 6. Графики, иллюстрирующие качество аппроксимации синусоидальной функции для различного количества нейронов N Краткие теоретические сведения: Нейронные сети (НС) широко используются для решения разнообразных задач. Основы теории и технологии применения НС широко представлены в пакете MATLAB с графическим интерфейсом пользователя NNTool. Чтобы запустить NNTool, необходимо выполнить команду в командном окне MATLAB: >> nntool После этого появится главное окно NNTool, именуемое «Окном управления сетями и данными» (Network/Data Manager) (рис. 1). Рис.1. Главное окно NNTool Окно имеет функциональные клавиши со следующими назначениями:
Главное окно NNTool Окно имеет функциональные клавиши со следующими назначениями: Помощь (Help)– краткое описание управляющих элементов данного окна; Новые данные (New…)– вызов окна, позволяющего создавать новые наборы данных и новую сеть; Импорт (Import)– импорт данных из рабочего пространства MATLAB в пространство переменных; Экспорт (Export)– экспорт данных из пространства переменных NNTool в рабочее пространство MATLAB; Удалить (Delete)– удаление выбранного объекта. Открыть (Open)– Просмотр созданной сети или наборов данных
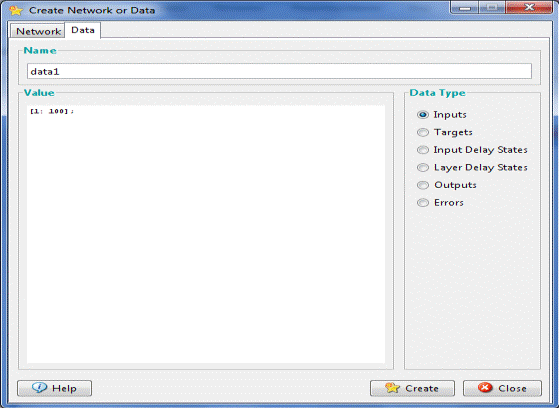
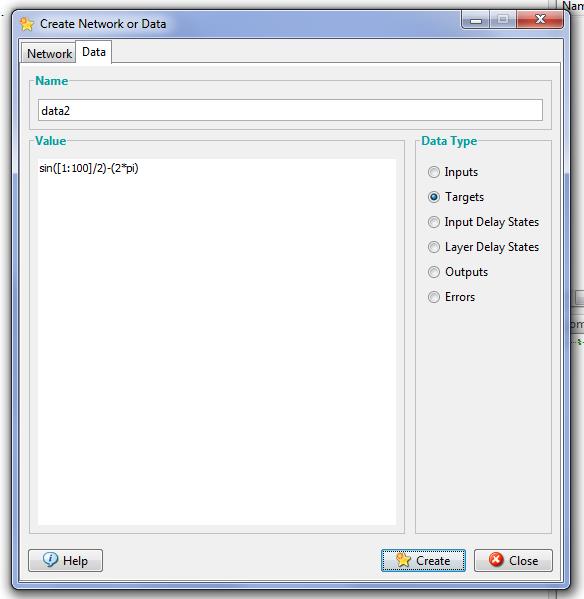
Одним из самых замечательных свойств нейронных сетей является способность аппроксимировать и, более того, быть универсальными аппроксиматорами. Это означает, что с помощью нейронных цепей можно аппроксимировать сколь угодно точно непрерывные функции многих переменных. Рассмотрим создание нейронной сети с помощью графической среды NNTool на следующем примере. Необходимо выполнить аппроксимацию функции следующего вида: Создание сети Перед созданием сети необходимо подготовить набор обучающих и целевых данных. Подготовка набора обучающих данных (1, 2, 3, … , 100), задается следующим выражением: [1:100]. Воспользуемся кнопкой «Новый» (New). В появившемся окне следует произвести изменения, показанные на рис. 2, и нажать кнопку «Создать» (Create).
После этого в окне управления появится вектор data1 в разделе Input Data. Вектор целей задаётся схожим образом (рис. 3). В поле «Значение» (Value) окна создания новых данных необходимо ввести выражение: Sin([1:100]/2)-(2*pi) Эта кривая представляет собой отрезок периодического колебания с частотой 5pi/N, модулированного по фазе гармоническим колебанием с частотой 7N
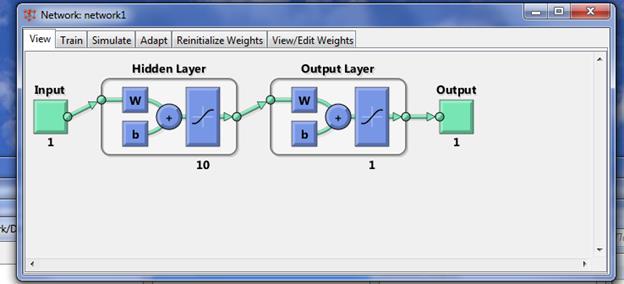
После нажатия на кнопку «Создать» (Create) в разделе Target Data появится вектор target1. Теперь следует приступить к созданию нейронной сети, т. е. выбрать закладку Network и заполнить форму. Указать однонаправленную сеть с обратным распространением ошибки (Feed-Forward Backprop) c тринадцатью сигмоидными (LOGSIG) нейронами скрытого слоя и одним линейным (PURELIN) нейроном выходного слоя. Обучение производить, используя алгоритм Левенберга-Маркардта (Levenberg-Marquardt), который реализует функция TRAINLM. Функция ошибки – MSE. Поля несут следующие смысловые нагрузки: - Имя сети (Name) – это имя объекта создаваемой сети. -Свойства сети (Network Properties) – определяет свойства сети и в контексте выбранного типа представляет ввод различных параметров в части окна, расположенные ниже. -Передаточная функция (Transfer function) – в этом пункте выбирается передаточная функция (функция активации) нейронов.
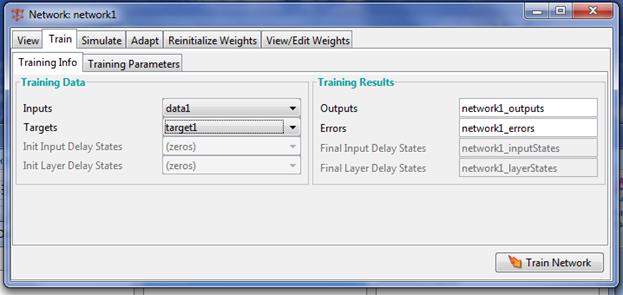
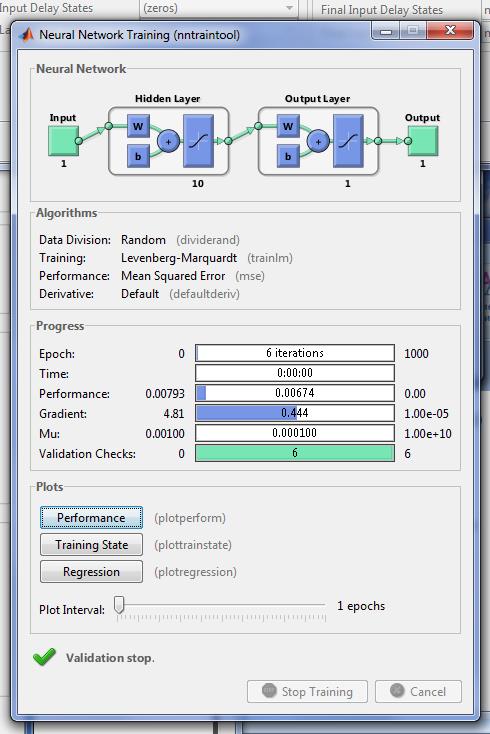
Нажав кнопку «Создать» (Create) в окне создания сети произойдет создание новой нейронной сети. В результате проделанных операций в разделе «Сети» (Networks) главногоокна NNTool появится объект с именем network1. Обучение сети Основная цель – построить нейронную сеть, которая выполняет аппроксимацию заданной функции. Очевидно, нельзя рассчитывать на то, что сразу после этапа создания сети последняя будет обеспечивать правильный результат (правильное соотношение «вход/выход»). Для достижения цели сеть необходимо должным образом обучить, то есть подобрать подходящие значения параметров. В MATLAB реализовано большинство известных алгоритмов обучения нейронных сетей. При создании сети, выбран TRAINLM в качестве функции, реализующей алгоритм обучения. Главное окно NNTool. На данном этапе интерес представляет панель «Сети» (Networks). Отметив указателем мыши объект сети network1, вызовем окно управления сетью нажатием кнопки «Open». В результате возникнет окно «Network: network1»содержащее, в свою очередь, еще одну панель вкладок (рис. 5). Их главное назначение – управление процессом обучения. На вкладке «Информация обучения» (Training info) требуется указать набор обучающих данных в поле «Входы» (Inputs) и набор целевых данных в поле «Цели» (Targets). Поля «Выходы» (Outputs) и «Ошибки» (Errors) NNTool заполняет автоматически. При этом результаты обучения, к которым относятся выходы и ошибки, будут сохраняться в переменных с указанными именами.
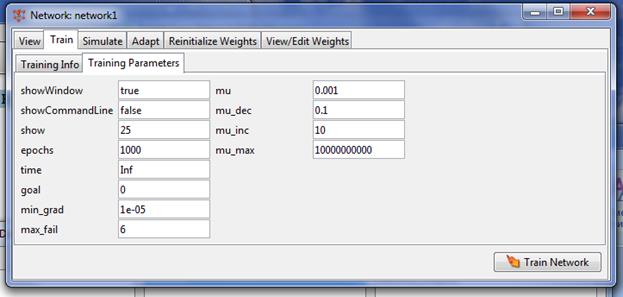
Завершить процесс обучения можно, руководствуясь разными критериями. Возможны ситуации, когда предпочтительно остановить обучение, полагая достаточным некоторый интервал времени. С другой стороны, объективным критерием является уровень ошибки. На вкладке «Параметры обучения» (Training parameters) (рис. 6) можно установить следующие поля: Количество эпох (epochs) – определяет число эпох (интервал времени), по прошествии которых обучение будет прекращено. Эпохой называют однократное представление всех обучающих входных данных на входы сети. Достижение цели или попадание (goal) – здесь задаётся абсолютная величина функции ошибки, при которой цель будет считаться достигнутой. Период обновления (show) – период обновления графика кривой обучения, выраженный числом эпох. Время обучения (time) – по истечении указанного здесь временного интервала, выраженного в секундах, обучение прекращается.
Чтобы начать обучение, нужно нажать кнопку «Обучить сеть» (Train Network) на вкладке «Обучение» (Train). После этого, если в текущий момент сеть не удовлетворяет ни одному из условий, указанных в разделе параметров обучения (Training Parameters), появится окно, иллюстрирующее динамику изменения целевой функции (рис. 8). Кнопкой «Остановить обучение» (Stop Training) можно прекратить этот процесс.
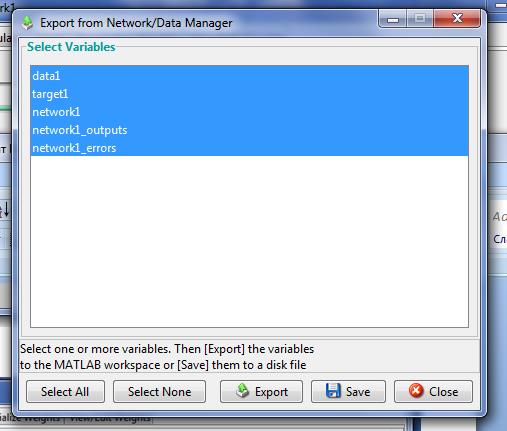
Использование сети На вкладке «Моделировать» (Simulate) выбрать в ниспадающем списке «Входы» (Inputs) подготовленные данные. В данной задаче естественно использовать тот же набор данных, что и при обучении data1. При желании можно установить флажок «Задать цели» (Supply Targets). Тогда в результате прогона дополнительно будут рассчитаны значения ошибки. Нажатие кнопки «Моделировать сеть» (Simulate Network) запишет результаты прогона в переменную, имя которой указано в поле «Выходы» (Outputs). Теперь можно построить два графика функции в одном окне: первый график – заданная функция, второй – в качестве аргумента значение вектора из «Входы» (Inputs), а в качестве значений функции значение вектора «Выходы» (Outputs). Для построения графиков необходимо экспортировать полученные данные аппроксимации в рабочее пространство MATLAB нажатием кнопки «Экспорт» (Export…) в окне NNTool. В окне экспорта данных нажать кнопку «Выделить все» (Select All) и кнопку «Экспорт» (Экспорт) (рис. 9). .
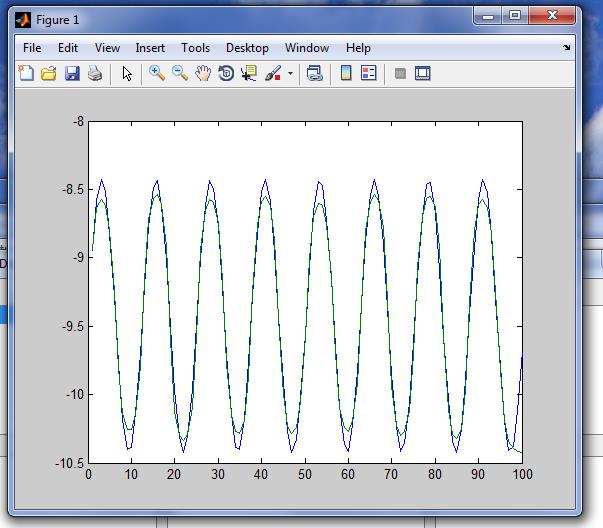
В рабочем окне MATLAB ввести команду: >>plot(data1, target1, data1, network1_outputs) Получится следующий график функции (рис. 10), иллюстрирующий разницу между целевыми данными и полученной аппроксимирующей кривой. При выборе нейронной сети для решения конкретной задачи трудно предсказать её порядок. Если выбрать неоправданно большой порядок, сеть может оказаться слишком гибкой и может представить простую зависимость сложным образом. Это явление называется переобучением. В случае сети с недостаточным количеством нейронов, напротив, необходимый уровень ошибки никогда не будет достигнут. Здесь налицо чрезмерное обобщение.Для предупреждения переобучения применяется следующая техника. Данные делятся на два множества: обучающее (Training Data) и контрольное (Validation Data). Контрольное множество в обучении не используется. В начале работы ошибки сети на обучающем и контрольном множествах будут одинаковыми. По мере того, как сеть обучается, ошибка обучения убывает, и, пока обучение уменьшает действительную функцию ошибки, ошибка на контрольном множестве также будет убывать. Если же контрольная ошибка перестала убывать или даже стала расти, это указывает на то, что обучение следует закончить.
Остановка на этом этапе называется ранней остановкой (Early stopping). Таким образом, необходимо провести серию экспериментов с различными сетями, прежде чем будет получена подходящая. При этом чтобы не быть введённым в заблуждение локальными минимумами функции ошибки, следует несколько раз обучать каждую сеть. Если в результате последовательных шагов обучения и контроля ошибка остаётся недопустимо большой, целесообразно изменить модель нейронной сети(например, усложнить сеть, увеличив число нейронов, или использовать сеть другого вида). В такой ситуации рекомендуется применять ещё одно множество – тестовое множество наблюдений (Test Data), которое представляет собой независимую выборку из входных данных. Итоговая модель тестируется на этом множестве, что даёт дополнительную возможность убедиться в достоверности полученных результатов. Очевидно, чтобы сыграть свою роль, тестовое множество должно быть использовано только один раз. Если его использовать для корректировки сети, оно фактически превратится в контрольное множество.
Работа №3 В настоящее время различают три вида систем машинного перевода: - Системы на основе грамматических правил (Rule-Based Machine Translation, RBMT); - Статистические системы (Statistical Machine Translation, SMT); - Гибридные системы; Системы на основе грамматических правил производят анализ текста, который используется в процессе перевода. Перевод производится на основе встроенных словарей для данной языковой пары, а так же грамматик, охватывающих семантические, морфологические, синтаксические закономерности обоих языков. На основе всех этих данных исходный текст последовательно, предложение за предложением, преобразуется в текст на требуемом языке. Основной принцип работы таких систем — связь структур исходного и конечного текстов. Системы на основе грамматических правил часто разделяют еще на три подгруппы — системы пословного перевода, трансфертные системы и интерлингвистические системы. Преимуществами систем на основе грамматических правил являются грамматическая и синтаксическая точность, стабильность результата, возможность настройки на специфическую предметную область. К недостаткам систем на основе грамматических правил относят необходимость создания, поддержки и обновления лингвистических баз данных, трудоемкость создания такой системы, а так же ее высокая стоимость. Статистические системы при своей работе используют статистический анализ. В систему загружается двуязычный корпус текстов (содержащий большое количество текста на исходном языке и его «ручной» перевод на требуемый язык), после чего система анализирует статистику межъязыковых соответствий, синтаксических конструкций и т. д. Система является самообучаемой — при выборе варианта перевода она опирается на полученную ранее статистику. Чем больший словарь внутри языковой пары и чем точнее он составлен, тем лучше результат статистического машинного перевода. С каждым новым переведенным текстом улучшается качество последующих переводов. Статистические системы отличаются быстротой настройки и легкостью добавления новых направлений перевода. Среди недостатков наиболее значительными являются наличие многочисленных грамматических ошибок и нестабильность перевода. Гибридные системы сочетают в себе подходы, описанные ранее. Ожидается, что гибридные системы машинного перевода позволят объединить все преимущества, которыми обладают статистические системы и системы, основанные на правилах.
Оригинальный текст:
Promt Переводчик.
Автор технической статьи стремится к исключению возможности любой интерпретации существа затронутой темы вследствие того, что в научной литературе почти, не встречают такие средства выражения как метафоры, метонимии и другие стилистические числа, которые широко используются в произведениях искусства для предоставления речи живого, фигуративного характера.
Yandex Переводчик.
Автор технической статьи стремится исключить возможность произвольного толкования предмета, в результате чего в научной литературе практически отсутствуют такие выразительные средства, как метафоры, метонимии и другие стилистические фигуры, которые широко используются в произведениях искусства для придания речи живого, образного характера.
Google Переводчик
Автор технической статьи стремится исключить возможность произвольного толкования сущности интерпретируемого объекта, в результате чего такие выразительные средства, как метафоры, метонимия и другие стилистические фигуры, широко используются в произведениях искусства для придания Живой, образный характер не встречается в научной литературе. ,
Переводчики Объем подсчитанных исправлений Google Translate Promt Яндекс
|
|||||||||
|
|
Последнее изменение этой страницы: 2024-06-17; просмотров: 6; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.17.131.133 (0.017 с.) |