Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Послідовні і паралельні моделі програмуванняСодержание книги Поиск на нашем сайте Лекція №1 Послідовні і паралельні моделі програмування Сукупність прийомів програмування, структур даних, що відповідає гіпотетичному комп’ютеру, який призначений для виконання визначеного класу алгоритмів називається моделлю програмування. Алгоритм можна представити у вигляді діаграми – інформаційного графу (рис. 1.1). Інформаційний граф описує послідовність виконання операцій та взаємну залежність між різними операціями або блоками операцій. Вузлами інформаційного графа є операції, а одно направленими дугами канали обміну даними.
Вихід
Рис. 1.1 Інформаційний граф алгоритму В інформаційному графу кожен вузол задається парами (n, s): n – ім’я вузла s – його розмір Розмір вузла визначається кількістю найпростіших операцій, що входять до його складу. Дуги характеризуються значеннями (v, d): v – змінна, що пересилається d – час, що затрачається на її пересилку Зливання декількох вузлів в один (упаковка вузлів) зменшує ступінь деталізації алгоритму, але збільшує кількість дуг, що виходять з вершин графу.
Вихід Рис.1. 2 Повністю Рис. 1.3 Повністю паралельний алгоритм послідовний алгоритм
Тут представлені два граничні випадки інформаційного графа. Традиційною вважається послідовна модель програмування (рис. 1.2). В даному випадку в будь-який момент часу виконується тільки одна операція і тільки над одним елементом даних. Головна ідея, що покладена в основу паралельного програмування (рис. 1.3), заключається в розпаралелюванні процесу обробки даних, коли одна і та ж сама операція застосовується одночасно до масиву (вектора) значення.
Чотири фундаментальних вимоги до паралельного програмування: 1. Паралелізм 2. Масштабованість 3. Локальність 4. Модульність
Рис. 1.4 Модель задача/канал Найпростіші моделі паралельного програмування, що називається моделлю задача/канал (рис.1.4), - це програма складена з декількох задач пов’язаних між собою каналами комунікацій і які виконуються одночасно. Кожна задача складається з послідовного коду і локальної пам’яті. Можна вважати, що задача – це віртуальна машина фон Неймана. Набір вхідних і вихідних портів визначає її інтерфейс з оточенням. Канал – це черга повідомлень-посилок з даними. Задача може помістити в чергу своє повідомлення, чи навпаки, видалити повідомлення прийнявши дані, що в ньому містяться. Кількість задач може змінюватись в процесі виконання. Крім зчитування і запису даних в локальну пам'ять кожна задача може посилати і отримувати повідомлення, породжувати нові задачі та завершати їх виконання. Операція відправки даних асинхронна, вона завершується відразу. Операція прийому синхронна, вона блокує виконання задачі до тих пір, поки не буде отримано повідомлення. Незалежність результату виконання паралельної програми від відображення на конкретну архітектуру забезпечується тим, що задачі взаємодіють між собою за допомогою універсального механізму. Він не залежить від того, як розподілені задачі, тому і результат виконання програми не повинен залежати від засобу розподілення. При збільшення кількості процесорів кількість задач, що приходиться на один процесор зменшується, але алгоритм при цьому, змінювати не потрібно.
Інші моделі паралельного програмування Передача повідомлень Програми, написані в рамках цієї моделі, як і в програмах моделі задача/канал, при виконанні породжується декілька задач. Кожній задачі привласнюється свій унікальний ідентифікатор, а взаємодія здійснюється завдяки відправці і прийому повідомлень. Можна вважати, що дана модель програмування відрізняється від моделі задача/канал тільки механізмом передачі даних. Повідомлення відправляється не в канал, а конкретній задачі. В моделі передачі повідомлень нові задачі можуть створюватись під час виконання паралельної програми, декілька задач можуть виконуватись на одному процесорі.
Паралелізм даних Ця модель заснована на застосуванні однієї операції до множини елементів структури даних. Моделі програмування відрізняються гнучкістю, механізмами взаємодії між задачами, рівнем паралелізму і «зернистістю», масштабованістю, підтримкою модульності і т. д. В моделі паралелізму даних «зернистість» обчислень мала, оскільки кожна операція над кожним елементом даних може обчислюватись незалежною задачею. Програміст повинен указати транслятору, як дані слід розподіляти між процесорами (між задачами).
Лекція №2 Закон Амдала За допомогою інформаційного графа можна оцінити максимальне прискорення, якого можна досягти при розпаралелюванні алгоритму там де це можливо. Допустимо, що програма виконується на машині, архітектура якої ідеально відповідає структурі інформаційного графа програми. Нехай час виконання алгоритму на послідовній машині Т1: Ts – час виконання послідовної частини алгоритму Тр – час виконання паралельної частини алгоритму При виконанні тієї ж програми на ідеальній паралельній машині, N незалежних гілок паралельної частини розподіляються на N процесорів, тому час виконання цієї частини зменшується до величини Коефіцієнт прискорення, який показує в скільки разів швидше програма виконається на паралельній машині, ніж на послідовній визначається формулою:
S i P відносні частки (долі) послідовної і паралельної частини
Рис 2.1 Графік залежності коефіцієнта прискорення від числа процесорів і ступенів паралелізму алгоритма Ця залежність називається законом Амдала. Наведемо різні кількісні характеристики паралелізму. Ефективне використання процесорів характеризується величиною
Але на практиці це значення ефективності недосяжне. Ступенем паралелізму називається кількість процесорів, що використовуються в кожен момент часу для виконання програми. Ступінь паралелізму може змінюватись в процесі виконання програми.
Паралелізм даних Головна ідея підходу – застосування однієї операції одразу до декількох елементів масиву даних. Різні фрагменти такого масиву обробляються на векторному процесорі або на різних процесорах паралельної машини. Векторизація або розпаралелювання в даному випадку частіше за все використовується вже під час трансляції – переводом вихідного тексту програми в машинні команди. Підхід, застосований на паралелізмі даних, базується на використанні в програмах базового набору операцій: 1) Операції керування даними 2) Операції над масивами в цілому, а також їх фрагментами 3) Умовні операції 4) Операції приведення 5) Операції зсуву 6) Операції сканування 7) Операції, що пов’язані з пересилкою даних. Реалізація моделі паралелізму даних потребує підтримки паралелізму на рівні транслятора. Таку підтримку можуть забезпечувати: 1) Препроцесори 2) Предтранслятори 3) Транслятори, що розпаралелюють
Лекція №3 Паралелізм задач Метод програмування заснований на паралелізмі задач передбачає розбиття обчислювальної задачі на декілька відносно самостійних під задач. Кожна під задача виконується на своєму процесорі. Для кожної під задачі пишеться своя власна програма на звичайній мові програмування (С або Fortran). Під задачі повинні обмінюватись результатами своєї роботи, отримувати вихідні дані. Практично такий обмін здійснюється викликом процедур спеціалізованої бібліотеки. Програміст при цьому може контролювати розподіл даних між різними процесами і під задачами, а також обмін даними. Прикладом спеціалізованої бібліотеки є MPI (Message Passing Interface) і PVM (Parallel Virtual Machine). Ці бібліотеки розповсюджуються вільно і існують у вихідних кодах.
Лекція №4 Розділяюча пам'ять Найпростіший спосіб створити багатопроцесорний обчислювальний комплекс з розділяючою пам’яттю – взяти кілька процесорів, з'єднати їх загальною шиною між собою і з ОП. Якщо один процесор приймає команду або передає дані всі інші процесори вимушені переходити в режим очікування. Це призводить до того, що починаючи з деякого числа процесорів швидкодія такої системи припиняє збільшуватись при додаванні нового процесора. Покращити картину може застосування кеш-пам'яті для зберігання команд. При наявності локальної, тієї, що належить даному процесору кеш-пам'яті, наступна необхідна йому команда з найбільшою імовірністю буде знаходитись у кеш-пам'яті. В результаті цього зменшується кількість звернень до шини і швидкодія системи зростає. Кеш-пам'ять Кеш-пам'ять діє наступним чином: якщо центральний процесор звертається до ОП, то спочатку запит на необхідні дані поступає в кеш-пам'ять. Якщо ці дані там уже знаходяться, то виконується швидка пересилка даних в регістр процесора, а в протилежному випадку дані зчитуються з оперативної пам'яті і розміщуються в кеш-пам'яті, а з неї вже завантажуються в регістр. При використанні в багатопроцесорних обчислювальних системах кеш-пам'яті виникає проблема кеш-когерентності. Вона полягає в тому, що якщо двом або більше процесорам знадобилось значення однієї і тієї ж змінної, воно буде зберігатись у вигляді декількох копій в кеш-пам'яті всіх процесорів. Один з процесорів може змінити це значення в результаті виконання своєї команди і воно буде передано в ОП комп’ютера. Але в кеш-пам'яті інших процесорів все ще буде зберігатись старе значення. Тобто, необхідно забезпечити своєчасне оновлення даних в кеш-пам'яті всіх процесорів комп’ютера. Проблема кеш-когерентності може вирішуватись програмним шляхом на рівні транслятора і ОС (системи). Транслятор, наприклад, може визначати моменти безпечної синхронізації кеш-пам'яті при виконанні програми. Інший підхід заснований на апаратному вирішенні проблеми кеш-когерентності. Обчислювальною системою (ОС) з розділяючою пам'яттю є комп’ютери фірми Kendall Square Research. Чередуюча пам'ять Чергуюча пам'ять розділяється на банки пам'яті. Прийнято, що комірка пам'яті з номером «і» знаходиться в банкові пам'яті i mod n, де n – це кількість банків пам’яті, mod – операція обчислення залишку від ділення. Якщо є 8 банків пам'яті, то першому будуть належати комірки пам'яті з номерами 0, 8, 16, …, другому – 1, 9, 17, …, і т.д. Запити до різних банків пам'яті можуть оброблюватись одночасно. При достатній кількості банків пам'яті швидкість обміну даними між пам'яттю і процесором може бути близька до ідеального значення, тобто одне машинне слово може передатись за один такт роботи процесора. Комірки пам'яті можуть бути пронумеровані і неперервним чином, тобто в першому банку знаходяться комірки з номерами від 0 до 255, в другому – від 256 до 511 і т.д. В векторних комп’ютерах зазвичай використовується перший спосіб адресації, а в багатопроцесорних комп’ютерах з розділяючою пам'яттю – другий. Розподілена пам'ять В обчислювальних системах з розподіленою пам'яттю оперативна пам'ять є у кожному процесорі. Процесор має доступ тільки до своєї пам'яті. В цьому випадку відпадає необхідність у перемикачі та немає конфліктів по доступу до пам'яті. Немає також притаманних системам з розділяючою пам'яттю обмежень на кількість процесорів і не виникає проблема з кеш-когерентністю. З іншого боку, ускладнена організація обміну даними між процесорами. Зазвичай такий обмін здійснюється за допомогою пересилання повідомлень-посилань, що містять дані. Для формування такого пересилання потрібен час, а для отримання і зчитування отриманих даних також потрібен час. Програмування для систем з розподіленою пам'яттю потребує розбиття вихідної задачі на підзадачі, виконання яких може бути доручено різним процесорам. Одним з комп’ютерів такого типу є СМ-5 фірми Thinking Machines. Ця система складається з процесорних елементів, побудованих за допомогою мікропроцесора SPARC і з’єднаних мережею зі спеціальною топологією типу «дерево». У кожного процесорного елемента є своя локальна пам'ять об’ємом 32Мб. В схемі з розподіленою чи розділяючою пам'яттю кожен процесорний елемент має власний модуль пам'яті, але адресний простір у них спільний. Листинг 1. Фрагмент коду, що демонструє незалежність по керуванню do k = 1, m a[k] = b[k] if (a[k] < c) then a[k] = 1 endif enddo
Листинг 2. Фрагмент коду, що демонструє залежність по керуванню do k = 1, m a[k] = b[k] if (a[k-1] < c) then a[k] = 1 endif enddo
Дві підзадачі можуть виконуватися паралельно, якщо вони незалежні за даними, по керуванню й по операціях виведення. Властивість паралельності має властивість комутативності - якщо підзадачі а й b паралельні, то b й а теж паралельні, але не транзитивно, тобто якщо а й b паралельні, то також паралельні b і с, звідси не обов'язково випливає паралельність а й с. Декомпозиція повинна бути такою, щоб час рахунку або обробки даних перевершувв час, затрачуваний на пересилання даних. Навряд чи існують точні алгоритми такої декомпозиції, можна вважати, що сегментування алгоритму - це мистецтво. Лекція №6 Проектування комунікацій Підзадачі не можуть бути абсолютно незалежними, тому наступним етапом розробки алгоритму є проектування обмінів даними між ними. Проектування полягає у визначенні структури каналів зв'язку й повідомлень, якими повинні обмінюватися підзадачі. Канали зв'язку можуть створюватися неявно, як це відбувається, наприклад, у мовах програмування, що підтримують модель паралелізму даних, а можуть програмуватися явно. Якщо на першому етапі застосовується декомпозиція даних, проектування комунікацій може виявитися непростою справою. Сегментація даних на непересічні підмножини й зв'язування з кожною з них своєї безлічі операцій обробки - досить очевидний крок. Однак залишається необхідність обміну даними, а також керування цим обміном. Структура комунікацій може виявитися складною. У схемі функціональної декомпозиції організація комунікацій звичайно простіша - вона відповідає потокам даних між завданнями. Комунікації бувають наступних типів: · локальні - кожна підзадача пов'язана з невеликим набором інших підзадач; · глобальні - кожна підзадача пов'язана з більшим числом інших підзадач; · структуровані - кожна підзадача й підзадачі, пов'язані з нею утворять регулярну структуру (наприклад, з топологією ґрат); · неструктуровані - підзадачі зв'язані довільним графом; · статичні - схема комунікацій не змінюється із часом; · динамічні - схема комунікацій змінюється в процесі виконання програми; · синхронні - відправник й одержувач даних координують обмін; · асинхронні - обмін даними не координується. У глобальній схемі може бути занадто багато обмінів, що погіршує масштабованість програми. Прикладом використання такої схеми є програми, організовані за принципом хазяїн/працівник (master/slave), коли один процес запускає безліч подзадач, розподіляє між ними роботу й приймає результати. Недоліком програми з такою організацією може бути те, що головна програма приймає повідомлення від підлеглих завдань по черзі. У цьому випадку вона працює в послідовному режимі. Неструктуровані комунікації застосовуються, наприклад, у методі кінцевих елементів, де доводиться мати справу з геометричними об’ємами складної форми, а також при використанні в сіткових методах не рівномірних сіток. Структура сітки може змінюватися в процесі розрахунку. На перших етапах розробки паралельного алгоритму неструктурований характер комунікацій звичайно не завдає труднощів. Проблеми можуть виникати на етапах укрупнення й планування обчислень. У випадку асинхронних комунікацій відправники даних не можуть визначити, коли дані потрібні іншим завданням, тому останні повинні самі запитувати дані. От кілька рекомендацій по проектуванню комунікацій: · кількість комунікацій у підзадачах повинна бути приблизно однакова, інакше додаток стає погано масштабованим; · там, де це можливо, варто використати локальні комунікації; · комунікації повинні бути, по можливості, паралельними. Оптимальна організація обміну даними між підзадачами повинна враховувати архітектуру комунікаційної мережі високопродуктивної обчислювальної системи, повинна забезпечувати її рівномірне завантаження й мінімізувати конфлікти по доступу до різних вузлів системи. Тупикові ситуації можуть бути пов'язані з неправильною послідовністю обміну даними між процесами, коли, наприклад, перший процес очікує дані від другого, той, у свою чергу, від третього, а третьому процесу потрібен результат роботи першого процесу. Вирішити проблему тупиків можна, використовуючи неблокуючий прийом даних, сполучаючи прийом даних з їхнім відправленням і т.д. Обмін повідомленнями може бути реалізований по-різному: за допомогою потоків, міжпроцесних комунікацій (ІPC - Іnter-Process Communіcatіon), TСР-пакетів і т.д. Один з найпоширеніших способів програмування комунікацій - використання бібліотек, що реалізують обмін повідомленнями. Наприклад, уже згадувані бібліотеки PVM (Parallel Vіrtual Machіne) і MPІ (Message Passіng Іnterface), які дозволяють створювати паралельні програми для самих різних платформ. Так, програми, написані для кластера, можуть виконуватися на суперкомп'ютері. Існують й інші способи організації комунікацій. Метод RFC (Remote Procedure Control - вилучене керування процедурами) уперше був запропонований фірмою Sun Mіcrosystems. Він дозволяє одному процесу викликати процедуру з іншого процесу, передавати їй параметри й, при необхідності, одержувати результати виконання. CORBA (Common Object Request Broker Archіtecture) визначає протокол взаємодії між процесами, незалежний від мови програмування й операційної системи. Для опису інтерфейсів використається декларативна мова ІDL (Іnterface Defіnіtіon Language). ОМ (Dіstrіbuted Component Object Model, розробка Mіcrosoft) дає приблизно такої ж можливості, що й CORBA. Лежить в основі інтерфейсів Actіve, за допомогою яких один додаток MS Wіndows може запустити інший додаток й управляти його виконанням. Укрупнення Результатом перших двох етапів розробки паралельного алгоритму є алгоритм, що не орієнтований на конкретну архітектуру обчислювальної системи, тому він може виявитися неефективним. На етапі укрупнення враховується архітектура обчислювальної системи, при цьому часто доводиться поєднувати (укрупнювати) завдання, отримані на перших двох етапах, для того щоб їхнє число відповідало числу процесорів. Приклад укрупнення наведений на рис. 6.1.
Рис. 6.1 Укрупнення в тривимірному сіточному методі При укрупненні можуть досягатися такі цілі, як збільшення "зернистості" обчислень і комунікацій, збереження гнучкості й зниження вартості розробки. Основні вимоги: · зниження витрат на комунікації; · якщо при укрупненні доводиться дублювати обчислення або дані, це не повинно приводити до втрати продуктивності й масштабованості програми; · результуючі завдання повинні мати приблизно однакову трудомісткість; · збереження масштабованості; · збереження можливості паралельного виконання; · зниження вартості й трудомісткості розробки. Планування обчислень На етапі планування обчислень, заключному етапі розробки паралельного алгоритму, необхідно визначити, де та на яких процесорах будуть виконуватися підзадачі. Основним критерієм ефективності тут є мінімізація часу виконання програми. Проблема планування легко вирішується при використанні систем з розділяючою пам'яттю, однак не завжди вдається знайти ефективний спосіб укрупнення й планування обчислень. У цьому випадку застосовують евристичні алгоритми динамічно збалансованого завантаження процесорів, коли перевизначення стратегії укрупнення й планування виробляється періодично під час виконання програми й іноді з досить великою частотою. В алгоритмах, заснованих на функціональній декомпозиції, часто створюється безліч дрібних "короткоживучих" підзадач. У цьому випадку застосовуються алгоритми планування виконання завдань (tasks schedulіng), які розподіляють завдання по незавантаженим роботою процесорам. Планування виконання завдань полягає в організації їхнього доступу до ресурсів. Порядок надання доступу визначається використовуваним т цього алгоритмом. Як приклад можна привести планування за принципом кругового обслуговування (round robіn). Це алгоритм планування, коли кілька процесів обслуговуються по черзі, одержуючи однакові порції процесорного часу. Часто використається також метод збалансованого завантаження (load balancіng) процесорів обчислювальної системи. Він заснований на обліку поточного завантаження кожного процесора. Іноді при реалізації методу збалансованого завантаження передбачається перенос ("міграція") процесу з одного процесора на іншій. В алгоритмах планування виконання завдань формується набір (пул) завдань, у який включаються знову створені завдання й з якого завдання вибираються для виконання на процесорах, що звільнилися. Стратегія розміщення завдань на процесорах звичайно являє собою компроміс між вимогою максимальної незалежності завдань, що виконуються (мінімізація комунікацій) і глобальним обліком стану обчислень. Найчастіше застосовуються стратегії хазяїн/працівник (рис. 6.2), ієрархічні й децентралізовані стратегії.
Рис6.2 Стратегія управління хазяїн/працівник
У реалізації цієї простої схеми (ефективної для невеликого числа процесорів), головне завдання відповідає за розміщення підлеглих завдань Підлегле завдання одержує вихідні дані для обробки від головного завдання й повертає йому результат роботи. Ефективність даної схеми залежить від числа підлеглих завдань і відносних витрат на обміни даними між підлеглим і головним завданнями. При використанні централізованої схеми збалансованого завантаження головне завдання не повинно бути "слабкою ланкою" програми, тобто воно не повинно гальмувати виконання інших завдань. Ієрархічна схема хазяїн/працівник є різновидом простої схеми хазяїн/працівник, у якій підлеглі завдання розділені на непересічні підмножини й у кожної із цих підмножин є своє головне завдання. Головні завдання підмножин управляються одним "самим головним" завданням. У децентралізованих схемах головне завдання відсутнє. Завдання можуть обмінюватися даними одне з одним, дотримуючись певної стратегії. Це може бути випадковий вибір об'єкта комунікації або взаємодія з невеликим числом найближчих сусідів. У гібридній централізовано/розподіленій схемі запит посилається головному завданню, а воно передає його підлеглим завданням, використовуючи метод кругового планування. При рішенні складних завдань динамічні методи планування простіші, але продуктивність програми при цьому може бути менша. З іншого боку, алгоритм SPMD забезпечує більш повний контроль над комунікаціями й обчисленнями, хоча він і складніший. Динамічно збалансоване завантаження може бути ефективно реалізоване, якщо враховані наступні міркування: · якщо кожен процесор виконує одну підзадачу, тривалість виконання всієї програми буде визначатися часом виконання самої тривалої підзадачі; · оптимальна продуктивність досягається, якщо всі підзадачі мають приблизно однаковий розмір; · піклуватися про збалансовану роботу процесорів може програміст, але є й засоби автоматичної підтримки збалансованої роботи; · збалансованість може бути забезпечена за допомогою завантаження кожного процесора декількома завданнями. Існують різні алгоритми збалансованого завантаження, застосовувані в методах декомпозиції даних. Це методи рекурсивної дихотомії, локальні алгоритми, імовірнісні методи, циклічні відображення і т.д. Всі вони призначені для укрупнення дрібнозернистих завдань, так, щоб у результаті на один процесор доводилося одне великоблочне завдання. Будемо вважати, що дані пов'язані з певною просторовою структурою, наприклад, тривимірною сіткою, і цю структуру будемо називати областю. Рекурсивна дихотомія використається для розбивки області на підобласті, яким відповідає приблизно однакова трудомісткість обчислень, а комунікації зведені до мінімуму. Область спочатку розбивається на дві частини уздовж одного виміру. Розбивка повторюється рекурсивно в кожній новій підобласті стільки разів, скільки буде потрібно для одержання необхідного числа підзадач. Метод рекурсивної координатної дихотомії звичайно застосовується до нерегулярних сіток. Розподіл виконується на кожному кроці уздовж того виміру по якому сітка має найбільшу довжину. Це досить простий метод, що, однак, не дозволяє домогтися великої ефективності комунікацій. Тут можливі ситуації, коли виникають пропалені підобласті з більшим числом локальних комунікацій. Метод рекурсивної дихотомії графа використається для нерегулярних сіток. У ньому за допомогою інформації про топологію ґрат мінімізується кількість ребер, що перетинають границі підобластей. Це дозволяє знизити кількість комунікацій. Локальні алгоритми, що забезпечують динамічно збалансоване завантаження процесорів, використають інформацію тільки про найближчих сусідів (підзадачі або процесори). На відміну від глобальних алгоритмів вони більш ощадливі й частіше використовуються в тих ситуаціях, коли завантаження швидко міняється згодом. Однак ефективність локальних алгоритмів менша, ніж глобальних, оскільки вони використовують обмежену інформацію про стан обчислювального процесу. Імовірнісні методи планування ощадливі й дозволяють забезпечити гарну масштабованість додатків. У цьому випадку завдання розміщуються для виконання на випадково обраних процесорах. Якщо кількість завдань велика, середнє завантаження всіх процесорів буде однаковим. Недоліком даного підходу можна вважати те, що для рівномірного завантаження кількість завдань повинна набагато перевершувати кількість процесорів. Найбільшу ефективність імовірнісні методи показують у ситуаціях з невеликим числом обмінів. Циклічне планування є різновидом імовірнісного планування. У цьому випадку вибирається певна схема нумерації підзадач, і кожен N-й процесор завантажується кожним N-им завданням. Лекція №7 Зв'язок між елементами паралельних обчислювальних машин Одним із найважливіших елементів архітектури будь-якого комп’ютера, а високопродуктивних обчислювальних систем в тому числі, є комунікаційна мережа, яка зв’язує процесори з оперативною пам’яттю, процесори між собою, процесори з іншими пристроями. Вона надає вирішальний вплив на продуктивність системи. Трафік в такій мережі складається з даних, що пересилаються і команд. Основною характеристикою мережі є пропускна здатність, що вимірюється в бітах в секунду. Далі мова піде про багатопроцесорні комп’ютери, які в даному контексті прийнято розглядати як набір вузлів (процесорних елементів, модулів пам’яті, перемикачів) і з’єднань між вузлами. Приведемо декілька визначень. · Організація внутрішніх комунікацій обчислювальної системи називається її топологією. · Два вузли іменуються сусідніми, якщо між ними є пряме з’єднання. · Порядком вузла називається кількість його сусідів. · Комунікаційним діаметром мережі іменується максимальний шлях між двома будь-якими вузлами. · Масштабність характеризує зростання складності з’єднань при додаванні в конфігурацію нових вузлів. Якщо система володіє високим степенем масштабності, її складність буде незначною мірою змінюватися при наростанні системи, незмінним буде і діаметр мережі. Є два типи топологій комунікаційних мереж – статичні і динамічні. У випадку статичної мережі всі з’єднання фіксовані, а в динамічній мережі в між процесорних з’єднаннях використовуються перемикачі. Перший тип мереж більше всього підходить для рішення тих задач, в яких відомі структура і характер обміну даними. Динамічні з’єднання більш універсальні, але вони дорожчі, їх реалізація складніша.
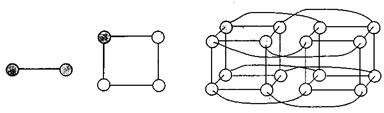
Статичні топології З’єднання за допомогою одиночної шини є самим простим і дешевим (рис. 7.1). Основним його недолік заклечається в тому, що в кожний момент часу можлива тільки одна пересилка даних/команд. Пропускна спроможність зворотно пропорційна кількості процесорів, підключених до шини.
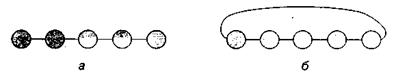
Рис. 7.1. З’єднання за допомогою шини. Більш ефективним є другий спосіб з’єднання – одномірна решітка. У кожного елемента в цьому випадку є два зв’язки із сусідами, а граничні елементи мають по одному зв’язку (рис. 7.2). Якщо замкнути кінці одномірної решітки, отримаємо топологію «кільце».
Рис. 7.2. Одномірна решітка (а) і кільце (б)
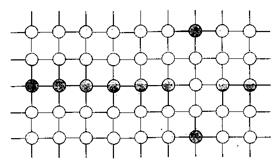
Двомірна решітка представлена на рис. 7.3
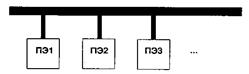
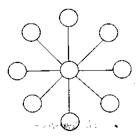
Рис. 7.3. Плоска решітка. Двомірна решітка забезпечує хорошу швидкодію. Для передачі даних між процесорними елементами необхідно визначити маршрут пересилки даних, при цьому для решітки розміром n*n потребується максимум 2*(n-1) проміжних вузлів. Досить часто використовуються і тривимірні решітки. В топології «зірка» є один центральний вузол, з яким з’єднуються всі інші процесорні елементи. Таким чином, у кожного ПЕ є одне з’єднання, а в центрального ПЕ – (N-1) з’єднання (рис. 7.4).
Рис. 7.4. З’єднання «зірка»
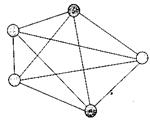
В мережі із повнозв’язною топологією (рис. 7.5) усі процесорні елементи зв’язані один одним. Пересилки можуть виконуватися одночасно між різними парами процесорних елементів. В такій системі легко можуть бути реалізовані широкомовні і багато адресні пересилки.
Рис. 7.5. Мережа із повнозв’язною топологією
Досить розповсюдженою є топологія «гіперкуб», що добре масштабується (рис. 7.6). В ній 2n процесорних елементів можуть бути організовані в n-мірний гіперкуб. У кожного ПЕ є n з’єднань. Тут також потребується маршрутизація пакетів із даними, причому максимальна кількість проміжних вузлів рівна n. Вона і визначає максимальну затримку передачі даних.
а б в
Рис. 7.6. Одномірний гіперкуб (а), двомірний гіперкуб (б), чотиримірний гіперкуб (в)
Динамічні топології Основним представником цього класу є перехресне з’єднання (рис. 7.7). Воно забезпечує повну зв’язність, тобто кожний процесор може зв’язатися із будь-яким іншим процесором чи модулем пам’яті (як на рисунку). Пропускна здатність мережі при цьому не зменшується. Схеми із перехресними переключеннями можуть використовуватися і для організації між процесорних з’єднань. В цьому випадку кожен процесор має власний модуль пам’яті (системи із розподіленою пам’яттю).
Багатокаскадні мережі Багатокаскадні (multistage) мережі засновані на використанні 2х2 перехресних перемикачів – комутаторів (рис. 7.8).
Рис. 7.8. Перемикачі без широкомовного розсилання (а) і з широкомовним розсиланням (б) В цьому випадку на одному кінці з’єднання знаходяться процесори, а на іншому – процесори або інші вузли між ними розташовані перемикачі. При передачі даних від вузла до вузла, перемикачі встановлюються таким чином, щоб забезпечити потрібне з’єднання. В залежності від способу з’єднання є різні топології динамічних багатокаскадних мереж. Ось деякі з них: · бан’ян (схема мережі схожа на коріння екзотичної рослини бан’ян – індійської смоківниці); · куб; · «дельта»; · тригер; · «омега». Найважливішими атрибутами системи комунікацій є стратегії управління, комутації і синхронізації. Що стосується управління, то тут можна виділити дві альтернативи: централізоване управління єдиним контролером (модулем управління) і розподілене управління. Розподілене управління застосовується в багатокаскадних з’єднаннях, де кожен вузол приймає рішення, як діяти із повідомленням, що поступило – залишити його собі або передати сусіду. Інший варіант використовується, наприклад, в з’єднаннях типу «зірка», де кожне повідомлення пересилається в контролер, який і визначає його подальшу долю. Синхронізація також може бути глобальною, коли послідовність імпульсів, що синхронізується передається всім вузлам обчислювальної системи, але може бути і локальною, коли кожний вузол має свій власний генератор. Останній варіант називається асинхронною роботою. Лекція №8 Що таке MPІ? MPІ дослівно перекладається як "Інтерфейс Передачі Повідомлень" (Message Passіng Іnterface або, скорочено, MPІ). Розберемо загальну організацію й структуру однієї з його реалізацій - MPІCH. Обговоримо особливості програмування з використанням MPІCH, у тому числі організацію обміну даними. Розглянемо структуру MPІ-програми. Традиційної є послідовна модель програмування. Програміст, працюючи в рамках цієї моделі, вважає, що в нього є абстрактний комп'ютер, що складається з одного центрального процесора й пам'яті (як оперативної, так і зовнішньої). На такому комп'ютері й виконується послідовна програма, що являє собою єдине ціле. У моделі передачі повідомлень, що є різновидом паралельної моделі програмування, архітектура комп'ютера відрізняється від фон-нейманівської. У цьому випадку вважають, що комп'ютер складається з декількох процесорів, кожний з яких постачений своєю власною пам’яттю. Процесор і його власна оперативна пам'ять, тобто комп'ютер, включений у комунікаційну мережу, часто називають хост-машиною (від англійського host) або, на програмістському жаргоні, просто "хостом". Паралельна програма в моделі передачі повідомлень являє собою набір звичайних послідовних програм, які відпрацьовуються однаково. Звичайно, кожна із цих послідовних програм виконується на своєму процесорі й має доступ до своєї, локальної, пам'яті. Очевидно, у такому випадку потрібен механізм, що забезпечує погоджену роботу частин паралельної програми. Частини паралельної програми в процесі їхнього виконання будемо називати підзадачами. Для забезпечення узгодженої роботи підзадачі повинні обмінюватися між собою інформацією. Інформація може бути різною. Це можуть бути дані, обробку яких виконує програма, а можуть бути керуючі сигнали. У
|
|||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 1351; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.217.27 (0.018 с.) |

 Вхід
Вхід Вхід
Вхід

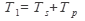
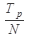 , а повний час виконання програми складає:
, а повний час виконання програми складає: 
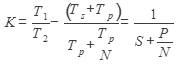





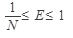 В ідеальній ситуації K=N; E=1
В ідеальній ситуації K=N; E=1