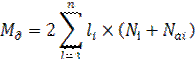Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
По проведению практических (семинарских) занятийСтр 1 из 6Следующая ⇒
МЕТОДИЧЕСКИЕ УКАЗАНИЯ По проведению практических (семинарских) занятий по дисциплине (модулю) «Базы данных»
основной профессиональной образовательной программы высшего образования – программы бакалавриата по направлению подготовки 09.03.01 «Информатика и вычислительная техника»
с профилем «Электронно-вычислительные машины, комплексы, системы и сети»
Формы обучения: очная, заочная
Идентификационный номер образовательной программы: 090301-02-18
Тула 2019 год Разработчик(и) методических указаний
____ Набродова И.Н., доцент, к.т.н. ____________ _______________ (ФИО, должность, ученая степень, ученое звание) (подпись) Практическая работа № 1 Инфологическое проектирование Цель и задачи работы Целью практической работы является получения навыков проектирования модели на основе инфологического проектирования.
Порядок выполнения работы - ознакомится с теоретическими сведениями; - выполнить задание; - оформить отчет; - ответить на контрольные вопросы, заданные преподавателем.
Оформление отчета Отчет должен содержать: титульный лист, цель работы, описание пунктов выполнения лабораторной работы в соответствии с заданием, ответы на контрольные вопросы и выводы по работе. Теоретические сведения Инфологический подход не предоставляет формальных способов моделирования реальности, однако он закладывает основы методологии проектирования БД. Первой задачей инфологического проектирования является определение ПО системы, позволяющее изучить информационные потребности будущих пользователей. Другая задача этого этапа – анализ ПО, который призван сформировать взгляд на ПО с позиций сообщества будущих пользователей БД, т.е. инфологической модели ПО. Анализ ПО выполняется разработчиком логической базы данных – специалистом в данной ПО. Инфологическая модель ПО представляет собой описание структуры и динамики ПО, характера информационных потребностей пользователей системы в терминах, понятных пользователю и независимых от реализации системы. Более того, инфологическая модель ПО не должна зависеть от модели данных, которая будет использована при создании БД.
Обычно описание ПО выражается в терминах не отдельных объектов и связей между ними, а их типов, связанных с ними ограничений целостности и тех процессов ПО, которые приводят к переходу ПО из одного состояния в другое. Такое описание может быть представлено любым способом, допускающим однозначную интерпретацию. В простых случаях описание ПО представляется на естественном языке, в более сложных используется также математический аппарат: таблицы, диаграммы, графы и т.п. При выполнении работы необходимо придерживаться следующих обозначений: 1. Имя отношения выделяется курсивом и подчеркиванием и пишется прописными буквами, например: СОТРУДНИКИ. 2. Имя атрибута отношения выделяется курсивом и подчеркиванием и пишется с большой буквы, например: Оклад. 3. Ключевые атрибуты отношения выделяются полужирным шрифтом, например: Табельный номер. 4. Имя связи между отношениями выделяется курсивом и подчеркиванием и пишется строчными буквами, например: работает. Построение инфологической модели базы данных необходимо производить с использованием метода "сущность–связь". Необходимо разбить ПО на ряд локальных областей, каждая из которых (в идеале) включает в себя информацию, достаточную для обеспечения информационных потребностей одной группы будущих пользователей или решения отдельной задачи. Каждое локальное представление моделируется отдельно, а затем выполняется их объединение. Выбор локального представления зависит от масштабов ПО. Обычно ПО разбивается на локальные области так, чтобы каждая из них соответствовала отдельному внешнему приложению и содержала 6-7 сущностей (т.е. объектов, о которых в системе будет накапливаться информация). Для каждой сущности определяются атрибуты, которые делятся на два типа: идентифицирующие и описательные. Идентифицирующие атрибуты входят в состав ключа (или ключей) и позволяют однозначно распознавать экземпляры сущности. Первичный ключ базовой сущности не может содержать неопределённые значения атрибутов (null). Первичный ключ должен включать в свой состав минимально необходимое для идентификации количество атрибутов. Описательные атрибуты заключают в себе свойства сущности, интересующие пользователей.
Спецификация атрибута состоит из его названия, указания типа данных и описания ограничений целостности – множества значений, которые может принимать данный атрибут. Обязательно предложите в инфологической модели составные атрибуты (с неопределенным числом элементов). Это гарантирует качественное выполнение этапа «Логическое проектирование». Далее осуществляется спецификация связей: выявляются связи между сущностями внутри локального представления. Каждая связь именуется. Кроме спецификации связей типа "сущность – сущность", выполняется спецификация связей типа "сущность – атрибут" и "атрибут – атрибут" для отношений между атрибутами, которые относятся к одной и той же сущности или к одной и той же связи типа "сущность – сущность". При объединении проектировщик может формировать конструкции, производные по отношению к тем, которые были использованы в локальных представлениях. Цель введения подобных абстракций: · объединение в единое целое фрагментарных представлений о различных свойствах одного и того же объекта; · введение абстрактных понятий, удобных для решения задач системы, установление их связи с более конкретными понятиями модели; · образование классов и подклассов подобных объектов (например, класс "изделие" и подклассы типов изделий, производимых на предприятии). При небольшом количестве локальных областей (не более пяти) объединение выполняется за один шаг. В противном случае обычно выполняют бинарное объединение. При объединении представлений используют три основополагающие концепции: 1. Идентичность. Два или более элементов модели идентичны, если они имеют одинаковое семантическое значение. 2. Агрегация. Позволяет рассматривать связь между элементами как новый элемент. Например, связь экзамен между сущностями СТУДЕНТ, ДИСЦИПЛИНА, ПРЕПОДАВАТЕЛЬ может быть представлена агрегированной сущностью ЭКЗАМЕН с атрибутами Название дисциплины, Фамилия преподавателя, Фамилия студента, Оценка. 3. Обобщение. Позволяет образовывать многоуровневую иерархию обобщений. По завершении объединения результаты проектирования представляют собой концептуальную инфологическую модель ПО. Модели локальных представлений – это внешние инфологические модели. БД publications должна хранить сведения о печатных изданиях, а также ссылки на интересные ресурсы в Internet. И те и другие источники информации будут касаться одной темы, а именно "баз данных". Попробуем выделить интересующие нас сущности и определить связи между ними. Прежде всего займемся понятием "печатное издание". Что это такое? Мы знаем, что объект "печатное издание" воплощается в виде книги, которую можно полностью описать с помощью следующих характеристик: название, автор, год издания и издатель (издательство). Можно ли на основании этого ввести сущность "книга", а названные характеристики определить в качестве ее атрибутов? Прежде чем сделать это рассмотрим более внимательно отношения между книгой и ее характеристиками: Один автор может написать несколько книг, и, в то же время, одна книга может быть написана несколькими авторами. Следовательно, "книга" и "автор" в данном случае выступают как различные сущности, объединяемые связью N:M. Для того, чтобы определить класс принадлежности сущностей в связи, отметим, что книг без авторов не бывает, как и авторов без книг. Значит, каждая сущность должна иметь обязательный класс принадлежности (кардинальность связи(1,N): (1,N)).
Точно так же один издатель может издавать сразу несколько книг, но каждая конкретная книга издается только в одном месте. Следовательно, мы должны ввести сущность "издатель", ассоциируемую с "книгой" связью типа 1:N. Т.к. каждая книга кем-то издана, класс принадлежности сущности "издатель" в данной связи будет (1,1), но в то же время мы допускаем хранение сведений об издательствах, чьих книг в нашей базе данных пока нет. Соответственно, класс принадлежности сущности "книга" в этой связи (0,N). По поводу характеристики книги "название" можно сказать следующее: как правило авторы, пишущие на одну тему, стараются придумывать для своих произведений оригинальные названия. Поэтому, можно уверенно предположить, что каждое название обязательно связано только с одной книгой (и каждая книга имеет только одно название). Следовательно, "название" нужно оставить в списке атрибутов "книги". Те же рассуждения можно повторить и для характеристики "год издания". Ее мы тоже оставим в списке атрибутов "книги". Таким образом, мы определили, что у сущности "книга" имеется два атрибута "название" и "год издания". Как уже говорилось, название, скорее всего, будет однозначно определять данную книгу, чего не скажешь о годе издания. Поэтому объявим ключом сущности атрибут "название" (или "имя_книги"). Что касается всех возможных авторов, то нас интересует только одна их характеристика – имя. Поэтому, сущность "автор" имеет только один атрибут "имя_автора", который и является ключом. С сущностью "издатель" обстоит несколько сложнее. Практически все крупные издательства имеют сейчас собственные web-страницы, которые могут содержать информацию полезную для пользователей проектируемой базы данных. Поэтому, нужно рассмотреть две характеристики этого объекта: "имя_издателя" и "URL" (uniform resource locator - универсальный указатель ресурсов, с помощью которого в Internet определяется путь к web - странице). Ясно, что каждый издатель имеет уникальное имя и уникальный url, но прежде чем внести их в список атрибутов, вспомним, что наша база данных должна также содержать ссылки и на другие Internet-ресурсы. Возможно, при дальнейшем анализе возникнет необходимость во введении отдельной сущности "URL". Поэтому "имя_издателя" внесем в список атрибутов сущности "издатель", а "URL" будем считать атрибутом отдельной сущности "web-страница", ассоциируемой с "издателем" связью (1,1):(1,1).
Теперь настала пора заняться объектом "ресурс Internet". Его мы можем описать с помощью понятий "имя ресурса", "url", "автор". Внимательно рассмотрев связи этих понятий с описываемым объектом, можно прийти к заключению, что "имя_ресурса" и "url" однозначно с ним связаны, т.е. являются атрибутами. В то же время, "автор" является отдельной сущностью (один ресурс может иметь много авторов, и один автор может быть создателем многих web-страниц). Т.к. мы уже ранее ввели сущность "автор" просто определим характеристики ее связи с сущностью "Internet-ресурс". Из сказанного выше следует, что эти сущности объединяются связью n:m, в то же время, автор какой-либо книги может не иметь собственной web-страницы, а авторы некоторых Internet ресурсов не указывают своих имен (т.е. можно формально сказать, что эти ресурсы не имеют авторов). Следовательно, класс принадлежности обеих сущностей будет необязательным. Прежде чем объявить нашу модель готовой, проверим еще раз определение каждой сущности. Внимательный анализ покажет, что построенная модель имеет несколько ошибок: Сущность "автор" имеет обязательный класс принадлежности в связи с сущностью "книга". Это означает, что мы не сможем добавить в базу данных сведения о человеке, который создал собственный web-сайт, но не написал ни одной книги. Для того, что бы устранить это ограничение изменим класс принадлежности сущности "книга" в рассматриваемой связи "автор" - "книга" на необязательный. При анализе объекта "издатель" мы предположили, что сущность "web-страница" может быть объединена с сущностью "Internet-ресурс". Однако, мы видим, что эти сущности имеют разный набор атрибутов, следовательно выполнить такое объединение нельзя. Вспомним, что в противном случае, предполагалось единственный атрибут сущности "web-страница" присоединить к атрибутам сущности "издатель". Тем не менее, не будем этого делать, в следующем разделе мы увидим, что с помощью правил порождения реляционных отношений из модели "сущность-связь" в том и в другом случае мы получим одинаковый результат. Готовая модель "сущность-связь" представлена на следующем рисунке:
Рисунок 1 - Модель «сущьность-связь»
На этапе анализа ПО также необходимо решить следующие задачи: 1. Определить правила (ограничений целостности), которым должны удовлетворять сущности ПО, атрибуты сущностей и связи между ними. Часть этих правил реализуется в схеме базы данных (возможности реализации ограничений целостности в схеме БД определяются моделью данных той СУБД, которая будет выбрана для реализации проекта). Остальные правила реализуются с помощью программного обеспечения.
2. Выделить группы пользователей системы. Каждая группа выполняет определённые задачи и обладает разными правами доступа к системе. 3. Создать внешнюю спецификацию тех функций (процессов), которые эта система будет выполнять. Например, для той же библиотечной системы это задачи поиска книг (по определённым критериям), выдачи/приёма книг, определение списка должников и т.д. Оборудование Оборудование: персональный компьютер с установленной операционной системой Windows XP/7/8, браузер (Например, Internet Explorer, Google Chrome, Opera), СУБД.
Задание на работу 1. Выделить необходимый набор сущностей, отражающих предметную область и информационные потребности пользователей. 2. Определить необходимый набор атрибутов каждой сущности, выделив идентифицирующие атрибуты. 3. Классифицировать атрибуты каждой сущности (описательные, указывающие, вспомогательные). 4. Определить сущности вида подтип/супертип, где это необходимо. 5. Определить связи между сущностями. 6. Проанализировав структуру связей, исключить избыточные. 7. Определить множественность и условность связей. 8. Дать формулировку связей с точки зрения каждой участвующей сущности. 9. Формализовать связи вида 1:1, 1:M, M:N. 10. Классифицировать сущности, разделив их на стержневые, ассоциативные, характеристические, обозначающие. 11. Построить ER-диаграмму модели базы данных. 12. Описать модель базы данных на языке инфологического проектирования. 7. Контрольные вопросы 1. Каковы задачи, решаемые на этапе инфологического проектирования? 2. В чем состоит отличие понятия типа сущности и элемента сущности? 3. Каковы способы представления сущности? 4. Каковы правила атрибутов? 5. Как классифицируются атрибуты? 6. Каковы фундаментальные виды связей? 7. Как формализуется связь 1:1? 8. Как формализуется связь 1:M? 9. Как формализуется связь M:N? 10. Что такое композиция связей? Практическая работа №2 Определение требований к операционной обстановке Цель и задачи работы Целью практической работы является получения навыков подбора требований к операционной обстановке.
Порядок выполнения работы - ознакомится с теоретическими сведениями; - выполнить задание; - оформить отчет; - ответить на контрольные вопросы, заданные преподавателем.
Оформление отчета Отчет должен содержать: титульный лист, цель работы, описание пунктов выполнения лабораторной работы в соответствии с заданием, ответы на контрольные вопросы и выводы по работе. Теоретические сведения На этом этапе производится оценка требований к вычислительным ресурсам, необходимым для функционирования системы, выбор типа и конфигурации ЭВМ, типа и версии операционной системы. Выбор зависит от таких следующих показателей: · примерный объём данных в БД; · динамика роста объёма данных; · характер запросов к данным (извлечение и обновление отдельных записей, групп записей, обработка отдельных отношений или соединение отношений); · интенсивность запросов к данным по типам запросов; · требования к времени отклика системы по типам запросов. Для выполнения этого этапа необходимо знать (хотя бы ориентировочно) объём хранимых записей, а также иметь представление о характере и интенсивности запросов. Объём внешней памяти, необходимый для функционирования системы, складывается из двух составляющих: память, занимаемая модулями СУБД (ядро, утилиты, вспомогательные программы), и память, отводимая под данные (МД). Наиболее существенным обычно является МД. Объём памяти МД, требуемый для хранения данных, можно приблизительно оценить по формуле
где li,- длина записи в i -й таблице (в байтах); Ni - максимально возможное количество записей в i -й таблице; Na - количество записей в архиве i-й таблицы. , Коэффициент 2 перед суммой нужен для того, чтобы выделить память для хранения индексов, промежуточных данных, для выполнения объёмных операций (например, сортировки) и т.п. Объём памяти, занимаемый программными модулями пользователя, обычно невелик по сравнению с объёмом самих данных, поэтому может не учитываться. Требуемый объём оперативной памяти определяется на основании анализа интенсивности запросов и объёма результирующих данных. Оборудование Оборудование: персональный компьютер с установленной операционной системой Windows XP/7/8, браузер (Например, Internet Explorer, Google Chrome, Opera), СУБД Oracle.
Задание на работу 1. Произвести оценку требований к вычислительным ресурсам, в выбранной предметной области, необходимым для функционирования системы. 2. Выбрать тип и конфигурацию ЭВМ, тип и версию операционной системы (обосновать выбор). 7. Контрольные вопросы 1. От каких показателей зависит выбор типа и конфигурации ЭВМ, типа и версии операционной системы? 2. Как оценить объем памяти, отводимый под данные, требуемый для хранения данных? Практическая работа №3 Цель и задачи работы Целью практической работы является получения навыков выбора СУБД для проектирования БД.
Порядок выполнения работы - ознакомится с теоретическими сведениями; - выполнить задание; - оформить отчет; - ответить на контрольные вопросы, заданные преподавателем.
Оформление отчета Отчет должен содержать: титульный лист, цель работы, описание пунктов выполнения лабораторной работы в соответствии с заданием, ответы на контрольные вопросы и выводы по работе. Теоретические сведения Выбор СУБД является одним из важнейших моментов в разработке проекта БД, так как он принципиальным образом влияет на весь процесс проектирования БД и реализации информационной системы. Теоретически при осуществлении этого выбора нужно принимать во внимание десятки факторов. Но на практике разработчики руководствуются лишь собственной интуицией и несколькими наиболее важными критериями, к которым, в частности, относятся: · тип модели данных, которую поддерживает данная СУБД, адекватность модели данных структуре, рассматриваемой ПО; · характеристики производительности СУБД; · запас функциональных возможностей для дальнейшего развития информационной системы; · степень оснащенности СУБД инструментарием для персонала администрирования данными; · удобство и надежность СУБД в эксплуатации; · стоимость СУБД и дополнительного программного обеспечения. В связи с тем, что в данной работе СУБД задается в задании, на данном этапе решается задача выбора инструментального ПО. Оборудование Оборудование: персональный компьютер с установленной операционной системой Windows XP/7/8, браузер (Например, Internet Explorer, Google Chrome, Opera), СУБД Oracle.
Задание на работу 1. Определить тип модели данных, которую поддерживает данная СУБД, ее адекватность потребностям рассматриваемой предметной области. 2. Определить характеристики производительности системы. 3. Определить запас функциональных возможностей для дальнейшего развития информационной системы. 4. Определить степень оснащенности системы инструментарием для персонала администрирования данными. 5. Определить удобство и надежность СУБД в эксплуатации. 6. Определить стоимость СУБД и дополнительного программного обеспечения. 7. Контрольные вопросы 1. Назовите основные функции СУБД. 2. Из каких компонентов состоит СУБД? 3. Каким образом классифицируются СУБД по способу доступа к БД? Приведите примеры СУБД. 4. Какими критериями необходимо руководствоваться при выборе СУБД для проектирования БД?
Практическая работа №4 Цель и задачи работы Целью практической работы является получения навыков по проектированию БД на логическом уровне.
Порядок выполнения работы - ознакомится с теоретическими сведениями; - выполнить задание; - оформить отчет; - ответить на контрольные вопросы, заданные преподавателем.
Оформление отчета Отчет должен содержать: титульный лист, цель работы, описание пунктов выполнения лабораторной работы в соответствии с заданием, ответы на контрольные вопросы и выводы по работе. Теоретические сведения На этапе логического проектирования разрабатывается логическая структура БД, соответствующая инфологической модели ПО. Решение этой задачи существенно зависит от модели данных, поддерживаемой выбранной СУБД. Результатом выполнения этого этапа являются схемы БД концептуального и внешнего уровней архитектуры, составленные на языках определения данных (DDL) выбранной СУБД. При этом разработка логической структуры базы данных должна производиться с учетом соблюдения условий нормализации отношений. На начальном шаге логического проектирования таблицы строятся таким образом, чтобы минимизировать количество таблиц в базе данных. Очевидно, что при таком подходе отношения не будут находиться ни в одной из нормальных форм, либо находиться в 1й нормальной форме. Необходимо последовательно привести каждую таблицу к 4й нормальной форме. Ниже рассматривается отношение КНИГИ (табл. 3.1) и последовательность его приведения к 4й нормальной форме. Id – идентификатор (первичный ключ), Code – шифр рубрики, Theme – название рубрики, Title – название книги, Author – автор, Editor – редактор, Type – тип издания (учебник, учебное пособие, сборник и.т.п.), Year – год издания, Pg – количество страниц.
Таблица 3.1. Исходное отношение КНИГИ
Примечание. В таблице 3.1 используются следующие сокращения: ВТ – вычислительная техника; ПО ВТ – программное обеспечение вычислительной техники; МО – математическое обеспечение; ИИ – искусственный интеллект. Оборудование Персональный компьютер с установленной операционной системой Windows XP/7/8, браузер (Например, Internet Explorer, Google Chrome, Opera), СУБД Oracle. Задание на работу 1. Изучить вопросы теории нормализации, условия нахождения отношения в той или иной нормальной форме 2. Выполнить процедуру построения реляционной модели данных из ER-модели, построив необходимый набор отношений. Определить состав атрибутов отношений. 3. Определить первичные и внешние ключи отношений. 4. Выполнить шаги по нормализации полученных отношений, приведя модель к третьей нормальной форме. 5. Задать необходимые декларативные ограничения целостности исходя из специфики предметной области. 6. Представить связи между первичными и внешними ключами в виде вертикальной диаграммы. 7. Средствами имеющейся СУБД создать спроектированную базу данных, ее таблицы, задать необходимые ограничения целостности. 7. Контрольные вопросы 1. Каковы задачи, решаемые на этапе логического проектирования? 2. Каковы базовые свойства реляционной модели данных? 3. В чем состоят требования структурной части реляционной модели данных? 4. В чем состоят требования манипуляционной части реляционной модели данных? 5. В чем состоят требования целостной части реляционной модели данных? 6. Каковы общие свойства нормальных форм? 7. Что такое функциональная, функционально полная зависимость? 8. Каковы условия нахождения отношений в первой нормальной форме? 9. Каковы условия нахождения отношений во второй нормальной форме? 10. Каковы условия нахождения отношений в третьей нормальной форме? 11. Каковы условия нахождения отношений в третьей усиленной нормальной форме? 12. Что понимается под многозначной зависимостью? 13. Каковы условия нахождения отношений в четвертой нормальной форме? 14. В чем состоят общие требования обеспечения ограничений целостности? Практическая работа №5 Цель и задачи работы Целью практической работы является получения навыков проектирования БД на физическом уровне.
Порядок выполнения работы - ознакомится с теоретическими сведениями; - выполнить задание; - оформить отчет; - ответить на контрольные вопросы, заданные преподавателем.
Оформление отчета Отчет должен содержать: титульный лист, цель работы, описание пунктов выполнения лабораторной работы в соответствии с заданием, ответы на контрольные вопросы и выводы по работе. Теоретические сведения Этап физического проектирования заключается в увязке логической структуры БД и физической среды хранения с целью наиболее эффективного размещения данных, т.е. отображении логической структуры БД в структуру хранения. Решается вопрос размещения хранимых данных в пространстве памяти, выбора эффективных методов доступа к различным компонентам "физической" БД. Результаты этого этапа документируются в форме схемы хранения на языке определения хранимых данных. Принятые на этом этапе решения оказывают определяющее влияние на производительность системы. Фактически проектирование БД имеет итерационный характер. В процессе функционирования системы становится возможным измерение её реальных характеристик, выявление "узких" мест. И если система не отвечает предъявляемым к ней требованиям, то обычно она подвергается реорганизации, т.е. модификации первоначально созданного проекта. Важным шагом на данном этапе необходимо проработать вопрос использования индексов. В системах, поддерживающих язык SQL, индекс создаётся командой CREATE INDEX. Индексы повышают производительность запросов, которые выбирают относительно небольшое число строк из таблицы. Для определения целесообразности создания индекса нужно проанализировать запросы, обращённые к таблице, и распределение данных в индексируемых столбцах. Система может воспользоваться индексом по определённому полю, если в запросе на значение этого поля накладывается условие, например: SELECT * FROM authors WHERE name = 'Даль'; Но даже при наличии такой возможности система не всегда обращается к индексу. Очевидно, что если запрос выбирает больше половины записей отношения, то извлечение данных через индекс потребует больше времени, чем последовательная обработка данных. В подобных случаях использование индекса нецелесообразно. Обращение к составному индексу возможно только в том случае, если в условиях выбора участвуют столбцы, представляющие собой лидирующую часть составного индекса. Например, если индекс строится по столбцам (X, Y, Z), то обращение к индексу будет происходить в тех случаях, когда в условии запроса участвуют столбцы XYZ, XY или X. При создании индекса большое значение имеет понятие селективности. Селективность определяется процентом строк, имеющих одинаковое значение индексируемого столбца: чем выше этот процент, тем меньше селективность. Выбор индексируемых столбцов определяется следующими соображениями: · В первую очередь выбираются столбцы, которые часто встречаются в критериях поиска. · Стоит индексировать столбцы, которые используются для соединения таблиц или являются внешними ключами. В последнем случае наличие индекса позволяет обновлять строки подчиненной таблицы без блокировки основной таблицы, когда происходит интенсивное конкурентное обновление связанных между собою таблиц. · Нецелесообразно индексировать столбцы с низкой селективностью. Если селективность столбца низкая, то индексирование проводится только в том случае, если выборка чаще производится по редко встречающимся значениям. · Не индексируются столбцы, которые часто обновляются, т.к. команды обновления ведут к потере времени на обновление индекса. · Не индексируются столбцы, которые часто используются как аргументы функций или выражений: как правило, такие функции не позволяют использовать индекс. Необходимо произвести экспериментальные исследования, показывающие повышение (или снижение) быстродействия индексированной базы данных при выборке/добавлении/удалении данных. Исследования производить многократным выполнением повторяющихся запросов со случайными параметрами. На основании результатов исследования сделать выводы о необходимости индексирования тех или иных столбцов таблиц базы данных.
Оборудование Персональный компьютер с установленной операционной системой Windows XP/7/8, браузер (Например, Internet Explorer, Google Chrome, Opera), СУБД Oracle. Задание на работу Cпроектировать БД, выбранной предметной области (см. предыдущие практические работы), на физическом уровне. 7. Контрольные вопросы 1. Что собой представляет физическая модель базы данных? 2. Способы создания таблиц в Oracle? Что такое поля базы данных? И основные свойства. 3. Использование полей подстановок при создании таблиц. 4. Как создается схема данных? Как связываются таблицы между собой? Практическая работа №6 Цель и задачи работы Целью практической работы является получения навыков определения подхода к безопасному проектированию БД.
Порядок выполнения работы - ознакомится с теоретическими сведениями; - выполнить задание; - оформить отчет; - ответить на контрольные вопросы, заданные преподавателем.
Оформление отчета Отчет должен содержать: титульный лист, цель работы, описание пунктов выполнения лабораторной работы в соответствии с заданием, ответы на контрольные вопросы и выводы по работе. Теоретические сведения Для каждой локальной области должна быть создана роль. Для этой роли определяется доступ к объектам базы данных (в виде привилегий). Кроме того, должен быть реализован принцип защиты данных на уровне строк. Для этого необходимо заменить таблицы на представления, определить правила выборки данных в этих представлениях в зависимости от подключенного пользователя. Создать триггеры, осуществляющие привязку строк таблиц к имени пользователя. Проанализировав средства обеспечения безопасности СУБД, архитектуру БД, известные уязвимости и инциденты безопасности, можно выделить следующие причины возникновения такой ситуации: · проблемами безопасности серьезно занимаются только крупные производители; · программисты баз данных, прикладные программисты и администраторы не уделяют должного внимания вопросам безопасности; · разные масштабы и виды хранимых данных требуют разных подходов к безопасности; · различные СУБД используют разные языковые конструкции для доступа к данным, организованным на основе одной и той же модели; · появляются новые виды и модели хранения данных. Хранилища данных включает в себя два компонента: хранимые данные (собственно БД) и программы управления (СУБД). Обеспечение безопасности хранимой информации, в частности, невозможно без обеспечения безопасного управления данными. Исходя из этого, все уязвимости и вопросы безопасности СУБД можно разделить на две категории: зависящие от данных и не зависящие от данных. Уязвимости, независящие от данных, являются характерными и для всех прочих видов ПО. Их причиной, например, может стать несвоевременное обновление ПО, наличие неиспользуемых функций или недостаточная квалификация администраторов ПО. Большинство аспектов безопасности СУБД является именно зависящими от данных. В то же время многие уязвимости являются косвенно зависимыми от данных. Например, большинство СУБД поддерживают запросы к данным с использованием некоторого языка запросов, содержащего наборы доступных пользователю функций (которые, в свою очередь, тоже можно считать операторами запросного языка) или произвольные функции на языке программирования. На основании разделения уязвимостей можно выделить зависящие и независящие от данных меры обеспечения безопасности хранилищ информации. Не зависящими от данных можно назвать следующие требования к безопасной системе БД: · Функционирование в доверенной среде.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-05-26; просмотров: 91; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.138.105.124 (0.21 с.) |