
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Раздел 1. Введение в архитектуру эвм.Стр 1 из 9Следующая ⇒
Раздел 1. Введение в архитектуру ЭВМ.
Принцип однородности памяти Программы и данные хранятся в одной и той же памяти, поэтому компьютер не различает, что хранится в данной ячейке памяти — число, текст или команда. Над командами можно выполнять такие же действия, как и над данными. Принцип адресности Структурно основная память состоит из пронумерованных ячеек. Процессору в произвольный момент времени доступна любая ячейка. Память компьютера должна состоять из некоторого числа пронумерованных ячеек, в каждой из которых могут находиться или обрабатываемые данные, или инструкции программ. Все ячейки памяти должны быть одинаково легко доступны для других устройств компьютера. Отсюда следует возможность давать имена областям памяти так, чтобы к сохраненным в них значениям можно было впоследствии обращаться или менять их в процессе выполнения программ с использованием присвоенных имен.
Принцип двоичного кодирования Согласно этому принципу, вся информация, как данные, так и команды, кодируются двоичными цифрами 0 и 1. Каждый тип информации представляется двоичной последовательностью и имеет свой формат. Последовательность битов в формате, имеющая определенный смысл, называется полем. В числовой информации обычно выделяют поле знака и поле значащих разрядов. В формате команды можно выделить два поля: поле кода операции и поле адресов.
Обычно программы хранятся во внешней памяти ПЭВМ и для выполнения передаются в оперативную память. Некоторые программы постоянно размещаются в памяти (ядро операционной системы, архиватор Zip Magic, монитор антивирусной программы Касперский АнтиВирус и др.) и называются резидентными, а другие – загружаются только на время выполнения, а затем удаляются из памяти, и называются транзитными. Часть машинных программ, обеспечивающих автоматическое управление вычислениями и используемых наиболее часто, может размещаться в постоянном запоминающем устройстве – реализовываться аппаратно. Программы, записанные в ПЗУ, составляют базовую систему ввода/вывода (BIOS), которая является промежуточным звеном между программным обеспечением компьютера и его электронными компонентами. Ее компоненты обеспечивают выполнение всех операций ввода/вывода в соответствии со специфическими особенностями работы каждого из периферийных устройств данного компьютера (драйверы стандартных устройств), тестируют работу памяти и устройств компьютера при включении электропитания (тест), а также выполняют загрузку операционной системы.
Реализация механизма перехода. Если выбранная команда, находящаяся в РК, является командой перехода, тогда ее младшие 12 бит служат адресом ячейки ОЗУ для следующей команды. Для осуществления перехода достаточно перенести код из этих разрядов в регистр СК, и тогда следующие команды будут выбраны из другого места программы. Примечание. Если команды хранятся парами (по две в одной ячейке ОЗУ), то ситуация сложнее. Здесь возможно два пути: первый - разрешить переход только на первую инструкцию пары. Второй - предусмотреть инструкции, позволяющие реализовать переход на первую и на вторую часть команды, что сложнее. В большинстве машин инструкции выбираются по одной и обсуждаемой проблемы просто не существует.
Развитие Как отмечалось, в каждой ячейке ОЗУ хранится по две команды. Причиной появления такой схемы является одноадресная структура команды, при которой в нее входят короткий код операции и один адрес памяти. В итоге общая длина команды оказывается небольшой и для ее сохранения достаточно половины ячейки. Если, же включить в состав машинной инструкции два или даже три адреса, то необходимое для записи такой команды число разрядов существенно возрастет. С практической точки зрения удобно так подобрать структуру команды, чтобы ее общая длина оказалась равной длине обрабатываемых в ЭВМ чисел. Большинство машин первого и второго поколений конструировались именно по такой схеме. БЭСМ-6 имела слово разрядностью 48 бит и команды длиной 24 бита, состоявшие из 15-разрядного адресного поля (возможна адресация 215 К слов) и 9-разрядного кода операции. Конвейер команд.
В отечественной литературе утверждается, что идея использования совмещения операций в машине была впервые высказана известным советским конструктором ЭВМ академиком С.А. Лебедевым (1957 год).
В наиболее общем виде идеи конвейеризации выполнения последовательности команд программы состоят в следующем. Все операции разбиваются на ряд стандартных шагов, для выполнения каждого из которых проектируется отдельное устройство. Благодаря узкой специализации указанных устройств они способны быстро выполнять какую-либо одну часть машинной инструкции, а затем результат передавать следующему устройству. Пока следующие устройства заканчивают операцию, первое из рассмотренных устройств уже освободилось и способно начать выполнение второй инструкции и т.д. Теоретически цепочка из 5 устройств способна при удачном стечении обстоятельств одновременно выполнять до 5 инструкций, причем первая будет уже завершаться, обработка пятой только начнется, а выполнение 2-4 команд будет находиться в различных промежуточных состояниях. Рассмотрим простейший пример организации конвейерного выполнения команд программы. Предположим, что все этапы выполнения команды абсолютно независимы и выполняются за одинаковое время (реально это не всегда так). Разобьем команду на 5 этапов: • ВК - выборка команды из памяти; • ДК - декодирование команды; • ВО - выборка операндов; • РО - реализация операции; • ЗР - запоминание результата. Выполнение 5 последовательных команд, первая из которых имеет некоторый условный номер n, можно проиллюстрировать с помощью следующей таблицы: КОМАНДА | Номер такта | |||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||||||
| Команда n | ВК | ДК | ВО | РО | ЗР | ||||||||||
| Команда n + 1 | ВК | ДК | ВО | РО | ЗР | ||||||||||
| Команда n + 2 | ВК | ДК | ВО | РО | ЗР | ||||||||||
| Команда n + 3 | ВК | ДК | ВО | РО | ЗР | ||||||||||
| Команда n + 4 | ВК | ДК | ВО | РО | ЗР | ||||||||||
Из таблицы видно, что конвейер начинает работать не сразу: первые 4 такта имеется хотя бы одно устройство, которое простаивает. Только начиная с пятого такта конвейер начинает функционировать на полную мощность и каждый такт сопровождается завершением одной инструкции. Если исполнять команды программы строго последовательно, то на каждую уйдет 5 тактов, т.е. конвейер ускоряет выполнение программы в 5 раз.
На практике трудности процесса могут быть вызваны следующими причинами:
1. Не все команды строго одинаковы (например, некоторые берут данные из памяти, а некоторые из регистров, что значительно быстрее; разные команды требуют для исполнения неодинаковое число тактов); по этой причине некоторые устройства конвейера в некоторых тактах вынуждены будут простаивать.
2. Наиболее критичной операцией конвейера является обращение к ОЗУ. Две команды не могут одновременно обращаться к ОЗУ (в частности, этапы ВК и ВО не должны находиться в одном столбце).
3. Последующим командам могут требоваться результаты предыдущих.
4. Для выхода на нормальный режим от "пустого" конвейера требуется некоторое время. Команды переходов изменяют адрес исполняемой команды, нарушая тем самым нормальный процесс конвейеризации, что вынуждает заново перезапускать конвейер.
5. Отдельная команда даже при благоприятном стечении обстоятельств в конвейере выполняется дольше, чем если бы она выполнялась отдельно: в работе конвейера имеются "накладные временные расходы".
|
|
Отметим еще одну важную с теоретической точки зрения деталь. Вычислительные системы классифицируются по двум принципам: является ли поток команд и поток данных в этой системе одиночным или множественным. Классическая модель, предложенная Д. фон Нейманом, выполняет команды программы последовательно одна за другой, причем каждая команда обрабатывает только одно число. Такой способ обработки называется Одиночный поток Команд и Одиночный поток Данных. Конвейерные вычислительные системы, способные одновременно выполнять несколько команд, уже используют множественный поток команд и соответственно обозначаются аббревиатурой МКОД.
Идея совмещения операций при выполнении программы с целью повышения производительности ЭВМ в современных микропроцессорах получила дальнейшее развитие. Рассмотрим наиболее распространенные направления модификации исполнения инструкций в современных процессорах.
Наиболее "узким" местом производительности процессора является обращение к ОЗУ. В отличие от регистров процессора, входящих в его состав, ОЗУ является отдельным устройством и "диалог" с ним требует значительных затрат времени.
Уже в процессоре Intel 8086 применена конвейерная архитектура, позволяющая выполнять выборку кодов инструкций из памяти и их декодирование во время исполнения внутренних операций. Конвейер процессора 8086 имеет 6-байтовую внутреннюю очередь инструкций. Блок предварительной выборки при наличии двух свободных байт в очереди старается ее заполнить в то время, когда внешняя шина процессора не занята операциями обмена.
Описанный процесс "досрочного" считывания последовательно расположенных байт памяти в процессорах Intel называют опережающей выборкой. Размер очереди команд имеет тенденцию к увеличению. Так, в 80386 он равнялся 16 байтам, что соответствовало 3-7 машинным инструкциям, а в 80486 - 32 байтам.
В процессорах марки Pentium впервые в семействе Intel появились два конвейера, которые могли функционировать параллельно. Теоретически при благоприятных обстоятельствах с такого конвейера сходит более одной выполненной инструкции (в данном случае две). В Pentium Pro количество инструкций может доходить до трех. Такая архитектура получила название суперскалярной.

Входная часть конвейера общая, а затем он разделяется на две ветви, они называются U- и V-конвейеры, последний имеет некоторую ограниченность по сравнению с первым.
|
|
При исполнении программы процессор проверяет две очередные инструкции программы на совместимость и, если они таковые, запускает оба конвейера. В противном случае первая инструкция запускается в U-конвейер, а V-конвейер простаивает.
В процессоре Pentium существует специальный блок предсказания ветвлений, направленный на уменьшение эффекта потерь времени при очистке конвейера из-за переходов. Опираясь на некоторую встроенную в процессор вероятность переходов и статистику данной команды перехода в предыдущих случаях, он принимает решение о том, насколько вероятно, что переход состоится. Если получается, что перехода скорее всего не будет, то выборка продолжается обычным образом; в противном случае дальнейшая выборка производится начиная с адреса перехода. В случаях, когда переход удалось "угадать" (а их заметно более половины!), предварительная выборка оказывается правильной. В противном случае конвейер сбрасывается.
Pentium не просто пытается предсказать переходы, но и способен выполнять следующие после перехода инструкции. Подобное явление имеет техническое название исполнение по предположению.
Процессору "разрешено" при некоторых благоприятных условиях исполнять инструкции программы не в том порядке, в каком они следуют в программе! Процессор Pentium Pro при анализе программного кода и планировании порядка вычислений может просматривать программу на 20-30 шагов вперед! Результаты опережающего исполнения команд записываются в специальные временные регистры, и когда процессор доходит до выполненной досрочно инструкции, не обнаружив каких-либо оснований для аннулирования ее результата, то просто копирует подготовленное ранее содержимое соответствующего регистра.
Выводы
1. Важным элементом устройства управления в машине фоннеймановской архитектуры является счетчик команд. Его назначение состоит в постоянном хранении адреса команды программы, которую необходимо выполнять.
2. Каждая команда программы реализуется согласно стандартному алгоритму: выборка команды из памяти, модификация значения счетчика, выполнение команды и повторение сначала.
3. Выборка команд и данных из памяти производится одинаковым образом.
4. Для реализации переходов в разветвляющихся и циклических программах в ходе выполнения команд данного типа содержимое счетчика команд изменяется.
5. При переходе к байтовой структуре памяти счетчик стал увеличиваться не на единицу, а на количество байт в очередной команде. Длины команд не во всех машинах являются постоянными.
6. Одно из наиболее существенных усовершенствований основного алгоритма выполнения команд программы состоит в организации конвейерного способа их выполнения. Благодаря данному способу удается существенно повысить эффективность работы процессора.
7. Ради повышения производительности в современных моделях процессоров при выполнении команд программы используются все усложняющиеся алгоритмы. Совершенствование технологий производства также позволяет модифицировать этот процесс (например, использовать несколько конвейеров и т.д.).
|
|
Многоуровневая память.
Многоуровневая память (англ. multilevel memory) — организация памяти, состоящая из нескольких уровней запоминающих устройств с различными характеристиками и рассматриваемая со стороны пользователей как единое целое. Для многоуровневой памяти характерна страничная организация, обеспечивающая «прозрачность» обмена данными между ЗУ разных уровней.
Локальность
Оказывается, при таком способе организации по мере снижения скорости доступа к уровню памяти снижается также и частота обращений к нему.
Ключевую роль здесь играет свойство реальных программ, в течение ограниченного отрезка времени способных работать с небольшим набором адресов памяти. Это эмпирически наблюдаемое свойство известно как принцип локальности или локализации обращений.
Свойство локальности (соседние в пространстве и времени объекты характеризуются похожими свойствами) присуще не только функционированию ОС, но и природе вообще. В случае ОС свойство локальности объяснимо, если учесть, как пишутся программы и как хранятся данные, то есть обычно в течение какого-то отрезка времени ограниченный фрагмент кода работает с ограниченным набором данных. Эту часть кода и данных удается разместить в памяти с быстрым доступом. В результате реальное время доступа к памяти определяется временем доступа к верхним уровням, что и обусловливает эффективность использования иерархической схемы. Надо сказать, что описываемая организация вычислительной системы во многом имитирует деятельность человеческого мозга при переработке информации. Действительно, решая конкретную проблему, человек работает с небольшим объемом информации, храня не относящиеся к делу сведения в своей памяти или во внешней памяти (например, в книгах).
Кэш процессора обычно является частью аппаратуры, поэтому менеджер памяти ОС занимается распределением информации главным образом в основной и внешней памяти компьютера. В некоторых схемах потоки между оперативной и внешней памятью регулируются программистом (см. например, далее оверлейные структуры), однако это связано с затратами времени программиста, так что подобную деятельность стараются возложить на ОС.
Адреса в основной памяти, характеризующие реальное расположение данных в физической памяти, называются физическими адресами. Набор физических адресов, с которым работает программа, называют физическим адресным пространством.
Логическая память
Аппаратная организация памяти в виде линейного набора ячеек не соответствует представлениям программиста о том, как организовано хранение программ и данных. Большинство программ представляет собой набор модулей, созданных независимо друг от друга. Иногда все модули, входящие в состав процесса, располагаются в памяти один за другим, образуя линейное пространство адресов. Однако чаще модули помещаются в разные области памяти и используются по-разному.
Схема управления памятью, поддерживающая этот взгляд пользователя на то, как хранятся программы и данные, называется сегментацией. Сегмент – область памяти определенного назначения, внутри которой поддерживается линейная адресация. Сегменты содержат процедуры, массивы, стек или скалярные величины, но обычно не содержат информацию смешанного типа.
По-видимому, вначале сегменты памяти появились в связи с необходимостью обобществления процессами фрагментов программного кода (текстовый редактор, тригонометрические библиотеки и т. д.), без чего каждый процесс должен был хранить в своем адресном пространстве дублирующую информацию. Эти отдельные участки памяти, хранящие информацию, которую система отображает в память нескольких процессов, получили название сегментов. Память, таким образом, перестала быть линейной и превратилась в двумерную. Адрес состоит из двух компонентов: номер сегмента, смещение внутри сегмента. Далее оказалось удобным размещать в разных сегментах различные компоненты процесса (код программы, данные, стек и т. д.). Попутно выяснилось, что можно контролировать характер работы с конкретным сегментом, приписав ему атрибуты, например права доступа или типы операций, которые разрешается производить с данными, хранящимися в сегменте.
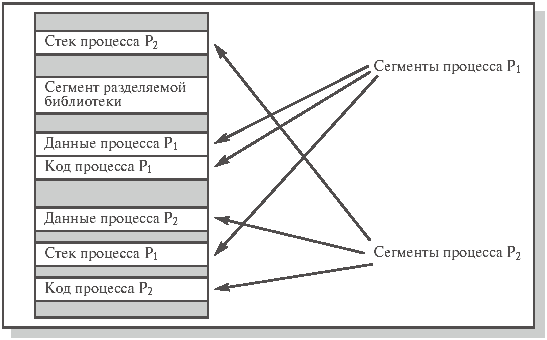
Рис. 8.2. Расположение сегментов процессов в памяти компьютера
Некоторые сегменты, описывающие адресное пространство процесса, показаны на рис. 8.2. Более подробная информация о типах сегментов имеется в лекции 10.
Большинство современных ОС поддерживают сегментную организацию памяти. В некоторых архитектурах (Intel, например) сегментация поддерживается оборудованием.
Адреса, к которым обращается процесс, таким образом, отличаются от адресов, реально существующих в оперативной памяти. В каждом конкретном случае используемые программой адреса могут быть представлены различными способами. Например, адреса в исходных текстах обычно символические. Компилятор связывает эти символические адреса с перемещаемыми адресами (такими, как n байт от начала модуля). Подобный адрес, сгенерированный программой, обычно называют логическим (в системах с виртуальной памятью он часто называется виртуальным) адресом. Совокупность всех логических адресов называется логическим (виртуальным) адресным пространством.
Связывание адресов
Итак логические и физические адресные пространства ни по организации, ни по размеру не соответствуют друг другу. Максимальный размер логического адресного пространства обычно определяется разрядностью процессора (например, 232) и в современных системах значительно превышает размер физического адресного пространства. Следовательно, процессор и ОС должны быть способны отобразить ссылки в коде программы в реальные физические адреса, соответствующие текущему расположению программы в основной памяти. Такое отображение адресов называют трансляцией (привязкой) адреса или связыванием адресов (см. рис. 8.3).
Связывание логического адреса, порожденного оператором программы, с физическим должно быть осуществлено до начала выполнения оператора или в момент его выполнения. Таким образом, привязка инструкций и данных к памяти в принципе может быть сделана на следующих шагах [Silberschatz, 2002].
- Этап компиляции (Compile time). Когда на стадии компиляции известно точное место размещения процесса в памяти, тогда непосредственно генерируются физические адреса. При изменении стартового адреса программы необходимо перекомпилировать ее код. В качестве примера можно привести.com программы MS-DOS, которые связывают ее с физическими адресами на стадии компиляции.
- Этап загрузки (Load time). Если информация о размещении программы на стадии компиляции отсутствует, компилятор генерирует перемещаемый код. В этом случае окончательное связывание откладывается до момента загрузки. Если стартовый адрес меняется, нужно всего лишь перезагрузить код с учетом измененной величины.
- Этап выполнения (Execution time). Если процесс может быть перемещен во время выполнения из одной области памяти в другую, связывание откладывается до стадии выполнения. Здесь желательно наличие специализированного оборудования, например регистров перемещения. Их значение прибавляется к каждому адресу, сгенерированному процессом. Большинство современных ОС осуществляет трансляцию адресов на этапе выполнения, используя для этого специальный аппаратный механизм (см. лекцию 9).

Рис. 8.3. Формирование логического адреса и связывание логического адреса с физическим
Оверлейная структура
Техника оверлей (overlay) или организация структуры с перекрытием предполагает держать в памяти только те инструкции программы, которые нужны в данный момент.
Данная техника возникла исходя из того, что иногда размер логического адресного пространства процесса может быть больше, чем размер выделенного ему раздела (или больше, чем размер самого большого раздела), иногда
Страничная память.
Описанные выше схемы недостаточно эффективно используют память, поэтому в современных схемах управления памятью не принято размещать процесс в оперативной памяти одним непрерывным блоком.
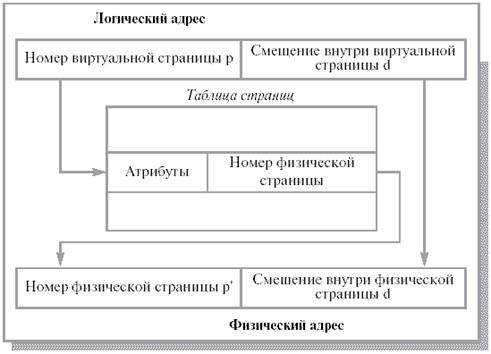
При страничной организации памяти (или paging) логическое и физическое адресные пространства представляются состоящими из наборов блоков или страниц одинакового размера. При этом образуются логические страницы (page), а соответствующие единицы в физической памяти называют физическими страницами или страничными кадрами (page frames). Страницы (и страничные кадры) имеют фиксированную длину, обычно являющуюся степенью числа 2, и не могут перекрываться. Каждый кадр содержит одну страницу данных. При такой организации внешняя фрагментация отсутствует, а потери из-за внутренней фрагментации, ограничены частью последней страницы процесса.
Логический адрес в страничной системе – это упорядоченная пара (p,d), где p – номер страницы в виртуальной памяти, а d – смещение в рамках страницы p, на которой размещается адресуемый элемент.
Разбиение адресного пространства на страницы осуществляется вычислительной системой незаметно для программиста. Поэтому адрес является двумерным лишь с точки зрения операционной системы, а с точки зрения программиста адресное пространство процесса остается линейным.
Описываемая схема позволяет загрузить процесс, даже если нет непрерывной области кадров, достаточной для размещения процесса целиком.
Система отображения логических адресов в физические сводится к системе отображения логических страниц в физические и представляет собой таблицу страниц, которая хранится в оперативной памяти.
Раздел 1. Введение в архитектуру ЭВМ.



