Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Часть III. Введение в хранилища данныхСодержание книги
Поиск на нашем сайте
Хранилища данных – это специальным образом сконструированные базы данных, которые предназначены не столько для хранения информации, сколько для быстрого получения сложных аналитических данных. Перечислим основные характерные моменты, связанные с проектированием и эксплуатацией хранилищ данных, построенных на реляционной модели: 1. Хранилища данных строятся на особой модели базы данных, которая пренебрегает многими аспектами нормализации. В основном, используются схемы типа «Снежинка» и «Звезда». В обеих схемах выделяется центральная таблица фактов, которая и содержит данные для анализа, и множество таблиц измерений (обычно сильно ненормализованных), содержащие информацию об объектах, в разрезе которых осуществляется анализ, и которые соединены с таблицей фактов связью типа «один-ко-многим». 2. Хранилища не предназначены для большого количества операций модификации данных. Обычно в хранилищах дублируются данные из операционных баз данных (базы, в которые попадают первичные данные). Зато они существенно зависят от операций экспорта из различных источников (не обязательно из баз данных). 3. Большая часть запросов к хранилищу данных связана с таблицей фактов, соединенной только с теми измерениями, которые необходимы для целей анализа. В качестве учебного примера рассмотрим особенности проектирования и использования хранилища для примера базы с данными об учебном процессе. Для определенности будем использовать в качестве СУБД MS SQL Server. Рассмотрим основные этапы проектирования и использования хранилищ данных. ПРОЕКТИРОВАНИЕ СХЕМЫ ХРАНИЛИЩА
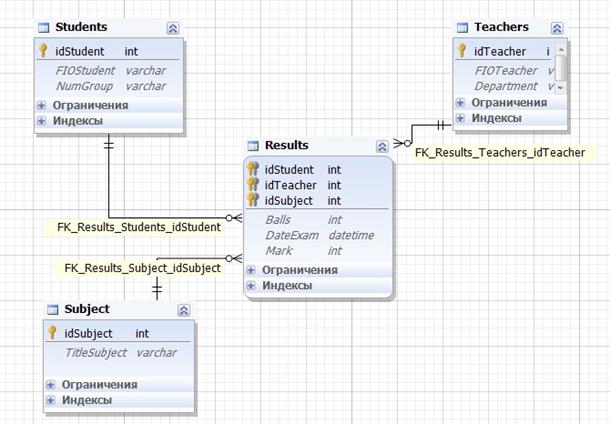
Рассмотрим схему «Звезда». В качестве таблицы фактов будем использовать таблицу результатов сдачи экзаменов студентами. В качестве таблиц измерений будут фигурировать таблицы «Студенты», «Преподаватели», «Дисциплины». Итак, у нас получилась довольно простая модель данных с тремя таблицами измерений. Отметим денормализацию на уровне таблицы измерений «Преподаватели» (в нее включается название кафедры, а не ее номер, как это было ранее). Кроме того, отметим наличие еще одного измерения, для которого таблица не создается. Этим измерением является дата сдачи экзамена. Фактами же в данном случае являются набранные баллы и соответствующая им оценка.
Рис. 49. Схема «Звезда» для хранилища данных. ЗАГРУЗКА ДАННЫХ
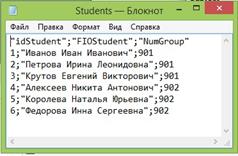
Произведем загрузку данных из базы данных через файлы различного текстового формата. Начнем с загрузки данных в таблицы измерений. Таблица «Students». Таблица студентов должна быть загружена в том же виде, что и хранится в базе данных деканата. Используем для загрузки файл формата CSV. Этот формат определяет текстовый файл, в котором в первой строке задаются имена столбцов, а каждая следующая строка содержит данные об одной записи, поля разделяются с помощью специального символаразделителя. Чтобы создать такой файл оболочка dbForge Studio содержит специальный конструктор экспорта данных. Доступ к нему можно получить, например, с помощью вкладки «Миграция данных» и опции «Экспорт данных». При экспорте придется указать источник данных для экспорта (таблицы или представления) и файл, в который произойдет сохранение информации. В результате будет получен следующий файл:
Рис. 50. Файл «Student.csv».
При импорте данных в базу хранилища данных следует воспользоваться той же вкладкой «Миграция данных» и опцией «Импортировать внешние данные». Сначала потребуется выбрать формат и файл с данными, затем определить таблицу, в которую осуществляется импорт, далее будет показан источник данных и можно будет сделать необходимые настройки (пропустить строки, установить символы-разделители), далее устанавливается соответствие между столбцами источника и приемника данных (в нашем случае они называются одинаково) и далее следуют уточнения по поводу операций импорта (какие операции произвести – добавление новых записей, модификация старых), интерпретация типов данных и прочее. Таблица «Subjects». Таблица дисциплин также должна быть загружена в том же виде. Используем для ее загрузки файл формата XML. Этот формат определяет текстовый файл, в котором структура и данные размечены с помощью специальных тегов. Как и в предыдущем случае следует использовать опции «Экспорт данных» и «Импортировать внешние данные». В результате будет сгенерирован следующий файл: <?xml version="1.0" encoding="utf-8" standalone="yes"?> <Root xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <xs:schema id="Root" xmlns="" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"> <xs:element name="Root" msdata:IsDataSet="true" msdata:UseCurrentLocale="true"> <xs:complexType> <xs:choice minOccurs="0" maxOccurs="unbounded"> <xs:element name="Table"> <xs:complexType> <xs:attribute name="idSubject" type="xs:int" /> <xs:attribute name="TitleSubject" type="xs:string" /> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> </xs:element> </xs:schema> <Table idSubject="1" TitleSubject="Математический анализ" /> <Table idSubject="2" TitleSubject="Алгебра и геометрия" /> <Table idSubject="3" TitleSubject="Теория вероятностей" /> <Table idSubject="4" TitleSubject="Методы оптимизации" /> <Table idSubject="5" TitleSubject="Вычислительная математика" /> <Table idSubject="6" TitleSubject="Алгоритмизация" /> <Table idSubject="7" TitleSubject="Программирование" /> <Table idSubject="8" TitleSubject= "Объектно-ориентированное программирование" /> <Table idSubject="9" TitleSubject="Базы данных" /> <Table idSubject="10" TitleSubject="Web-программирование" /> </Root>
Таблица «Teachers». При экспорте таблицы преподавателей мы должны на самом деле экспортировать результат его естественного соединения с таблицей кафедр. Для этого придется создать специальное представление данных, так как запрос не может быть использован в качестве источника данных для экспорта. CREATE VIEW Teacher_for_export AS SELECT idTeacher, FIOTeacher, TitleDepartment FROM Teachers INNER JOIN Departments ON Teachers.idDepartment=Departments.idDepartment;
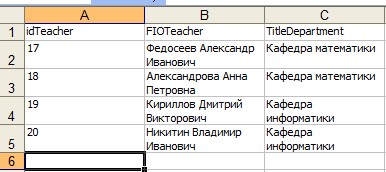
Используем для загрузки данных о преподавателях файл формата Excel, указав при экспорте в качестве источника данных созданное представление. При импорте этих данных следует обратить внимание на настройки относительно строки с заголовками столбцов – требуется явно указать, что первая строка является строкой с именами столбцов, тогда данные будут считываться только со следующей строки. Не забудьте при импорте настроить соответствие для имен столбцов с названием кафедры.
Рис.51. XLS-файл с данными о преподавателях.
Отметим, что экспортировать данные можно и в другие форматы: RTF, PDF и т.д., но для импорта в другую базу эти форматы не будут пригодными. Вполне естественно, что файл для импорта не обязательно должен быть сгенерирован каким-либо СУБД. Так как таблицу результатов сдачи зачетовэкзаменов в базе данных мы практически не заполняли, экспортировать в таблицу фактов нам пока нечего. Напишем приложение, которое генерирует файл с оценками, и далее импортируем его в нашу базу данных. Для простоты не будет рассматривать ситуацию, когда разные группы должны сдавать разный набор дисциплин. Будем предполагать, что у каждого студента имеются оценки по всем дисциплинам, которые есть в таблице измерений. Программный код такого проекта по генерации данных будет следующим. Комментариев в коде должно быть достаточно для понимания алгоритма генерации: using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Data; using System.Data.Odbc; using System.IO;
namespace generator { class Program { // в набор данных будут загружены измерения // для правильной генерации кодов объектов static DataSet ds = new DataSet();
// вспомогательная функция перевода баллов в оценку static int GetMark(int b) { if (b < 55) return 2; if (b < 71) return 3; if (b < 86) return 4; return 5; } static void Main(string[] args) { OdbcConnection con = new OdbcConnection("DSN=proba"); con.Open();
// загрузка таблицы студентов OdbcDataAdapter adapt1 = new OdbcDataAdapter("select * from Students", con); adapt1.Fill(ds, "Students");
// загрузка таблицы дисциплин OdbcDataAdapter adapt2 = new OdbcDataAdapter("select * from Subjects", con); adapt2.Fill(ds, "Subjects");
// загрузка таблицы преподавателей OdbcDataAdapter adapt3 = new OdbcDataAdapter("select * from Teachers", con); adapt3.Fill(ds, "Teachers");
con.Close();
//создание текстового файла для записи //сгенерированных данных StreamWriter tf = new StreamWriter (new FileStream("Results.csv", FileMode.Create));
// запись строки заголовка таблицы. // Для вывода кавычек используется \” tf.WriteLine("\"idStudent\";\"idSubject\"; \"idTeacher\";\"DateExam\"; \Balls\";\"Mark\"");
// вызов функции генерации данных GenerateData(tf);
// закрытие файла tf.Close(); }
// функция генерации оценок экзаменов по всем дисциплинам static void GenerateData(StreamWriter tf) { Random r = new Random();
// цикл перебора всех дисциплин foreach (DataRow dr_subj in ds.Tables["Subjects"].Rows) { // генерируем преподавателя, // которому сдается данный предмет int i = r.Next(ds.Tables["Teachers"].Rows.Count); int nom_teach = (int)ds.Tables["Teachers"].Rows[i]["idTeacher"];
//генерируем три даты для сдачи экзамена DateTime [] dates=new DateTime[3]; //определяем зимнюю или весенюю сессии if (r.Next(100) % 2 == 0) { // зимняя сессия dates[0] = new DateTime(2014, 1, 5 + r.Next(20)); dates[1] = new DateTime(2014, 1, 5 + r.Next(20)); dates[2] = new DateTime(2014, 1, 5 + r.Next(20)); } else { // весенняя сессия dates[0] = new DateTime(2014, 6, 3 + r.Next(24)); dates[1] = new DateTime(2014, 6, 3 + r.Next(24)); dates[2] = new DateTime(2014, 6, 3 + r.Next(24)); }
// цикл перебора всех студентов foreach (DataRow dr_stud in ds.Tables["Students"].Rows) { // генерируем оценку - будем оптимистами, // все оценки положительные int balls = 55 + r.Next(45); int mark = GetMark(balls);
// генерируем дату сдачи экзамена int nom_date = r.Next(120) % 3;
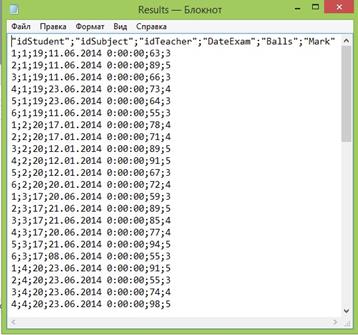
// формируем строку вывода сгенерированной // информации tf.WriteLine("{0};{1};{2};{3};{4};{5}", dr_stud["idStudent"], dr_subj["idSubject"], nom_teach, dates[nom_date], balls, mark); } } } } } Таким образом, получим следующий csv-файл, который импортируем в базу данных для организации хранилища:
Рис. 52.CSV-файл с оценками студентов.
|
||||
|
|
Последнее изменение этой страницы: 2021-04-12; просмотров: 165; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.248 (0.009 с.) |