Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сущности, отношения и связи в нотации ЧенаСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте СУЩНОСТЬ представляет собой множество экземпляров реальных или абстрактных объектов (людей, событий, состояний, идей, предметов и т.п.), обладающих общими атрибутами или характеристиками. Любой объект системы может быть представлен только одной сущностью, которая должна быть уникально идентифицирована. При этом имя сущности должно отражать тип или класс объекта, а не его конкретный экземпляр (например, АЭРОПОРТ, а не ВНУКОВО). ОТНОШЕНИЕ в самом общем виде представляет собой связь между двумя и более сущностями. Именование отношения осуществляется с помощью грамматического оборота глагола (ИМЕЕТ, ОПРЕДЕЛЯЕТ, МОЖЕТ ВЛАДЕТЬ и т.п.). Другими словами, сущности представляют собой базовые типы информации, хранимой в базе данных, а отношения показывают, как эти типы данных взаимоувязаны друг с другом. Введение подобных отношений преследует две основополагающие цели:
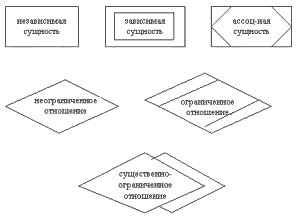
Символы ERD, соответствующие сущностям и отношениям, приведены на рис. 5.1.
Рис.5.1. Символы ERD в нотации Чена Независимая сущность представляет независимые данные, которые всегда присутствуют в системе. При этом отношения с другими сущностями могут как существовать, так и отсутствовать. В свою очередь зависимая сущность представляет данные, зависящие от других сущностей в системе. Поэтому она должна всегда иметь отношения с другими сущностями. Ассоциированная сущность представляет данные, которые ассоциируются с отношениями между двумя и более сущностями (см. 5.5). Неограниченное (обязательное) отношение представляет собой безусловное отношение, т.е. отношение, которое всегда существует до тех пор, пока существуют относящиеся к делу сущности. Ограниченное (необязательное) отношение представляет собой условное отношение между сущностями. Существенно-ограниченное отношение используется, когда соответствующие сущности взаимно-зависимы в системе. Для идентификации требований, в соответствии с которыми сущности вовлекаются в отношения, используются СВЯЗИ. Каждая связь соединяет сущность и отношение и может быть направлена только от отношения к сущности. ЗНАЧЕНИЕ связи характеризует ее тип и, как правило, выбирается из следующего множества: {"O или 1", "0 или более", "1", "1 или более", "p:q" (диапазон)}. Пара значений связей, принадлежащих одному и тому же отношению, определяет тип этого отношения. Практика показала, что для большинства приложений достаточно использовать следующие типы отношений:
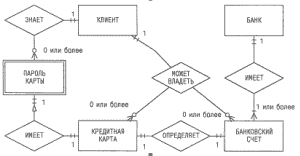
На рис.5.2 приведена диаграмма "сущность-связь", демонстрирующая отношения между объектами банковской системы (см. п.2.5). Согласно этой диаграмме каждый БАНК ИМЕЕТ один или более БАНКОВСКИХ СЧЕТОВ. Кроме того, каждый КЛИЕНТ МОЖЕТ ВЛАДЕТЬ (одновременно) одной или более КРЕДИТНОЙ КАРТОЙ и одним или более БАНКОВСКИМ СЧЕТОМ, каждый из которых ОПРЕДЕЛЯЕТ в точности одну КРЕДИТНУЮ КАРТУ (отметим, что у клиента может и не быть ни счета, ни кредитной карты). Каждая КРЕДИТНАЯ КАРТА ИМЕЕТ ровно один зависимый от нее ПАРОЛЬ КАРТЫ, а каждый КЛИЕНТ ЗНАЕТ (но может и забыть) ПАРОЛЬ КАРТЫ.
Рис 5.2. ER-диаграмма в нотации Чена.
Рис. 5.3. Диаграмма атрибутов. Диаграммы атрибутов Каждая сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности. При этом любой атрибут может быть определен как ключевой. Детализация сущности осуществляется с использованием диаграмм атрибутов, которые раскрывают ассоциированные с сущностью атрибуты. Диаграмма атрибутов состоит из детализируемой сущности, соответствующих атрибутов и доменов, описывающих области значений атрибутов. На диаграмме каждый атрибут представляется в виде связи между сущностью и соответствующим доменом, являющимся графическим представлением множества возможных значений атрибута. Все атрибутные связи имеют значения на своем окончании. Для идентификации ключевого атрибута используется подчеркивание имени атрибута. Пример диаграммы атрибутов, детализирующей сущность КРЕДИТНАЯ КАРТА (см. рис. 5.2) приведен на рис. 5.3. Категоризация сущностей Сущность может быть разделена и представлена в виде двух или более сущностей-категорий, каждая из которых имеет общие атрибуты и/или отношения, которые определяются однажды на верхнем уровне и наследуются на нижнем. Сущности-категории могут иметь и свои собственные атрибуты и/или отношения, а также, в свою очередь, могут быть декомпозированы своими сущностями-категориями на следующем уровне. Расщепляемая на категории сущность получила название общей сущности (отметим, что на промежуточных уровнях декомпозиции одна и та же сущность может быть как общей сущностью, так и сущностью-категорией). Для демонстрации декомпозиции сущности на категории используются диаграммы категоризации. Такая диаграмма содержит общую сущность, две и более сущности-категории и специальный узел-дискриминатор, который описывает способы декомпозиции сущностей (см. рис. 5.4).
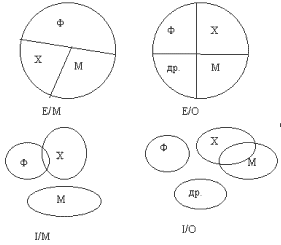
Рис. 5.4. Диаграмма категоризации Существуют 4 возможных типа дискриминатора (рис.5.5):
Рис 5.5. Типы дискриминаторов. Нотация Баркера Дальнейшее развитие ER-подход получил в работах Баркера, предложившего оригинальную нотацию, которая позволила на верхнем уровне интегрировать предложенные Ченом средства описания моделей. В нотации Баркера используется только один тип диаграмм - ERD. Сущность на ERD представляется прямоугольником любого размера, содержащим внутри себя имя сущности, список имен атрибутов (возможно, неполный) и указатели ключевых атрибутов (знак "#" перед именем атрибута). Все связи являются бинарными и представляются линиями с двумя концами (соединяющими сущности), для которых должно быть определено имя, степень множественности (один или много объектов участвуют в связи) и степень обязательности (т.е. обязательная или необязательная связь между сущностями). Для множественной связи линия присоединяется к прямоугольнику сущности в трех точках, а для одиночной связи - в одной точке. При обязательной связи рисуется непрерывная линия до середины связи, при необязательной - пунктирная линия. На рис. 5.6 приведен фрагмент ERD для банковской задачи в нотации Баркера.
Рис. 5.6. Нотация Баркера. Читается связь отдельно для каждого конца, показывая, как сущность КЛИЕНТ связывается с сущностью КРЕДИТНАЯ КАРТА, и наоборот. При этом необходимо учитывать степень обязательности выбранного конца связи, для этой цели используются слова "должен (быть)" или "может (быть)". Так, диаграмма, приведенная на рис. 5.6, читается следующим образом: Каждый КЛИЕНТ может ВЛАДЕТЬ одной или более КРЕДИТНОЙ КАРТОЙ или Каждая КРЕДИТНАЯ КАРТА должна ПРИНАДЛЕЖАТЬ ровно одному КЛИЕНТУ. В заключение отметим, что понятия категория и общая сущность заменяются Баркером на эквивалентные понятия подтипа и супертипа, соответственно. Построение модели Разработка ERD включает следующие основные этапы:
Этап 1 является определяющим при построении модели, его исходной информацией служит содержимое хранилищ данных, определяемое входящими и выходящими в/из него потоками данных. На рис. 5.7 приведен фрагмент диаграммы потоков данных, моделирующей деятельность бухгалтерии предприятия. Его единственное хранилище ДАННЫЕ О ПЕРСОНАЛЕ должно содержать информацию о всех сотрудниках: их имена, адреса, должности, оклады и т.п.
Рис. 5.7. Деятельность бухгалтерии Первоначально осуществляется анализ хранилища, включающий сравнение содержимого входных и выходных потоков и создание на основе этого сравнения варианта схемы хранилища. Перечислим структуры данных, содержащиеся во входных и выходных потоках:
Сравнивая входные и выходные структуры, отметим следующие моменты:
С учетом этих моментов первый вариант схемы может выглядеть следующим образом:
На следующем шаге осуществляется упрощение схемы за счет устранения избыточности. Действительно, ТЕКУЩАЯ_З/ПЛ всегда является последней записью в ИСТОРИИ_З/ПЛ, а ДАТА_НАЙМА содержится в разделах ИСТОРИЯ_З/ПЛ и ИСТОРИЯ_КАРЬЕРЫ. Кроме того, несколько дат в последних разделах одни и те же, поэтому целесообразно создать на их основе структуру ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ и вводить в нее данные при изменении ДОЛЖНОСТИ и/или З/ПЛ.
Следующий шаг - упрощение схемы при помощи нормализации (удаления повторяющихся групп). Единственным способом нормализации является расщепление данной схемы на две, являющиеся более простыми. Первая схема содержит ФАМИЛИЮ и АДРЕС (которые, как правило, не меняются), вторая - каждое изменение З/ПЛ и ДОЛЖНОСТИ. Кроме того, каждая схема должна содержать ТАБ_НОМЕР - единственный элемент данных, уникально идентифицирующий каждого сотрудника. Для идентификации сущностей осталось определить ключевые атрибуты. Для первой схемы ключевым атрибутом является ТАБ_НОМЕР, для второй - ключом является конкатенация атрибутов ТАБ_НОМЕР и ДАТА_ИЗМЕНЕНИЯ (рис.5.8), т.к. для каждого сотрудника возможно несколько записей в схеме ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ.
Рис. 5.8. Сущности модели Концепции и методы нормализации были разработаны Коддом (Codd), установившим существование трех типов нормализованных схем, названных в порядке уменьшения сложности первой, второй и третьей нормальной формой (соответственно, 1НФ, 2НФ и 3НФ). Рассмотрим, как преобразовывать схемы к наиболее простой 3НФ. При этом будем представлять схемы в общепринятом виде, например, для сущностей, приведенных на рис.5.8, имеем:
Для примера построения 3НФ рассмотрим следующую схему, ключ которой выбран в предположении, что заказчик не заказывает одну и ту же книгу дважды в один и тот же день:
Согласно Кодду, любая нормализованная схема (схема без повторяющихся групп) автоматически находится в 1НФ независимо от того, насколько сложен ее ключ и какая взаимосвязь может существовать между ее элементами. Отметим, что в последней схеме атрибуты НАЗВАНИЕ, АВТОР, ЦЕНА могут быть идентифицированы частью ключа (а именно, ISBN), тогда как атрибут КОЛИЧЕСТВО зависит от всего ключа (соответственно, полная и частичная функциональная зависимость от ключа). По определению схема находится в 2НФ если все ее неключевые атрибуты полностью функционально зависят от ключа. После избавления от частичной функциональной зависимости последняя схема будет выглядеть следующим образом:
Заметим, что возможно упростить ситуацию и дальше: атрибуты КОЛИЧЕСТВО и СУММА_ЗАКАЗА являются взаимно-зависимыми. По определению схема находится в 3НФ если она находится в 2НФ и никакой из неключевых атрибутов не является зависимым ни от какого другого неключевого атрибута. Поскольку в нашем примере атрибут СУММА_ЗАКАЗА фактически является избыточным, для получения 3НФ его можно просто удалить. Иногда для построения 3НФ необходимо выразить зависимость между неключевыми атрибутами в виде отдельной схемы. Так для сотрудников, работающих по различным проектам, возможна следующая схема:
Очевидно, что данная схема находится в 2НФ. Однако N_ПРОЕКТА и ДАТА_ОКОНЧАНИЯ являются зависимыми атрибутами. После расщепления схемы получим 3НФ:
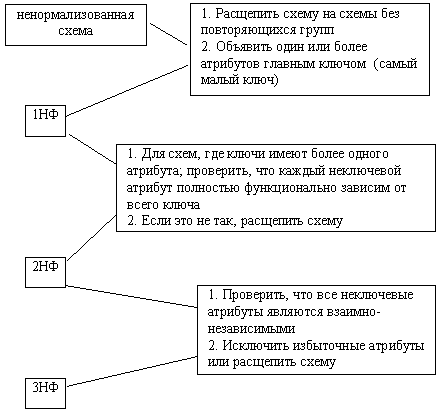
На практике отношения 1НФ и 2НФ имеют тенденцию возникать при попытке описать несколько реальных сущностей в одной схеме (заказ и книга, проект и сотрудник). 3НФ является наиболее простым способом представления данных, отражающим здравый смысл. Построив 3НФ, мы фактически выделяем базовые сущности предметной области. В заключание зафиксируем алгоритм приведения ненормализованных схем в третью нормальную форму (рис. 5.9). Этап 2 служит для выявления и определения отношений между сущностями, а также для идентификации типов отношений. На данном этапе некоторые отношения могут быть неспецифическими (n*m - многие-ко-многим). Такие отношения потребуют дальнейшей детализации на этапе 3.
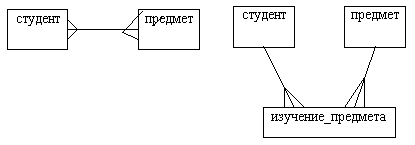
Рис. 5.9. Алгоритм приведения в 3НФ Определение отношений включает выявление связей, для этого отношение должно быть проверено в обоих направлениях следующим образом: выбирается экземпляр одной из сущностей и определяется, сколько различных экземпляров второй сущности может быть с ним связано, и наоборот. Для примера на рис. 5.8 рассмотрим отношение между сущностями СОТРУДНИК и ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ. У отдельного сотрудника должность и/или зарплата может меняться ноль, один или много раз, порождая соответствующее число экземпляров сущности ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ. Анализируя в другом направлении, видим, что каждый экземпляр сущности ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ соответствует ровно одному конкретному сотруднику. Поэтому между этими двумя сущностями имеется отношение типа 1*n (один ко многим) со связью "один" на конце отношения у сущности СОТРУДНИК и со связью "ноль, один или много" на конце у сущности ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ. Этап 3 предназначен для разрешения неспецифических (многие ко многим) отношений. Для этого каждое неспецифическое отношение преобразуется в два специфических отношения с введением новых (а именно, ассоциативных) сущностей. Рассмотрим пример на рис. 5.10.
Рис. 5.10. Разрешение неспецифического отношения Неспецифическое отношение на рис 5.10 указывает, что СТУДЕНТ может изучать много ПРЕДМЕТОВ, а ПРЕДМЕТ может изучаться многими СТУДЕНТАМИ. Однако мы не можем определить, какой СТУДЕНТ изучает какой ПРЕДМЕТ, пока не введем для разрешения этого неспецифического отношения третью (ассоциативную) сущность ИЗУЧЕНИЕ_ПРЕДМЕТА. Каждый экземпляр введенной сущности связан с одним СТУДЕНТОМ и с одним ПРЕДМЕТОМ. Таким образом, ассоциативные сущности по своей природе являются представлениями пар реальных объектов и обычно появляются на этапе 3.
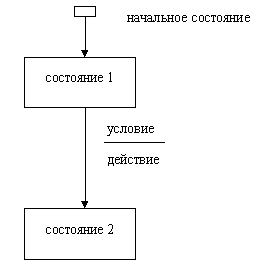
ГЛАВА 6 СПЕЦИФИКАЦИИ УПРАВЛЕНИЯ Спецификации управления предназначены для моделирования и документирования аспектов систем, зависящих от времени или реакции на событие. Они позволяют осуществлять декомпозицию управляющих процессов и описывают отношения между входными и выходными управляющими потоками на управляющем процессе-предке. Для этой цели обычно используются диаграммы переходов состояний (STD). С помощью STD можно моделировать последующее функционирование системы на основе ее предыдущего и текущего функционирования. Моделируемая система в любой заданный момент времени находится точно в одном из конечного множества состояний. С течением времени она может изменить свое состояние, при этом переходы между состояниями должны быть точно определены. STD состоит из следующих объектов: СОСТОЯНИЕ - может рассматриваться как условие устойчивости для системы. Находясь в определенном состоянии, мы имеем достаточно информации о прошлой истории системы, чтобы определить очередное состояние в зависимости от текущих входных событий. Имя состояния должно отражать реальную ситуацию, в которой находится система, например, НАГРЕВАНИЕ, ОХЛАЖДЕНИЕ и т.п. НАЧАЛЬНОЕ СОСТОЯНИЕ - узел STD, являющийся стартовой точкой для начального системного перехода. STD имеет ровно одно начальное состояние, соответствующее состоянию системы после ее инсталляции, но перед началом реальной обработки, а также любое (конечное) число завершающих состояний. ПЕРЕХОД определяет перемещение моделируемой системы из одного состояния в другое. При этом имя перехода идентифицирует событие, являющееся причиной перехода и управляющее им. Это событие обычно состоит из управляющего потока (сигнала), возникающего как во внешнем мире, так и внутри моделируемой системы при выполнении некоторого условия (например, СЧЕТЧИК=999 или КНОПКА НАЖАТА). Следует отметить, что, вообще говоря, не все события необходимо вызывают переходы из отдельных состояний. С другой стороны, одно и то же событие не всегда вызывает переход в то же самое состояние. Таким образом УСЛОВИЕ представляет собой событие (или события), вызывающее переход и идентифицируемое именем перехода. Если в условии участвует входной управляющий поток управляющего процесса-предка, то имя потока должно быть заключено в кавычки, например, " ПАРОЛЬ "=666, где ПАРОЛЬ - входной поток. Кроме условия с переходом может связываться действие или ряд действий, выполняющихся, когда переход имеет место. То есть ДЕЙСТВИЕ - это операция, которая может иметь место при выполнении перехода. Если действие необходимо для выбора выходного управляющего потока, то имя этого потока должно заключаться в кавычки, например: "ВВЕДЕННАЯ КАРТА" = TRUE, где ВВЕДЕННАЯ КАРТА - выходной поток. Кроме того, для спецификации A-, T-, E/D-потоков имя запускаемого или переключаемого процесса также должно заключаться в кавычки, например: A: "ПОЛУЧИТЬ ПАРОЛЬ" - активировать процесс ПОЛУЧИТЬ ПАРОЛЬ. Фактически условие есть некоторое внешнее или внутреннее событие, которое система способна обнаружить и на которое она должна отреагировать определенным образом, изменяя свое состояние. При изменении состояния система обычно выполняет одно или более действий (производит вывод, выдает сообщение на терминал, выполняет вычисления). Таким образом, действие представляет собой отклик, посылаемый во внешнее окружение, или вычисление, результаты которого запоминаются в системе (обычно в хранилищах данных на DFD), для того, чтобы обеспечить реакцию на некоторые из планируемых в будущем событий. На STD состояния представляются узлами, а переходы - дугами (рис. 6.1). Условия (по-другому называемые стимулирующими событиями) идентифицируются именем перехода и возбуждают выполнение перехода. Действия или отклики на события привязываются к переходам и записываются под соответствующим условием. Начальное состояние на диаграмме должно иметь входной переход, изображаемый потоком из подразумеваемого стартового узла (иногда этот стартовый узел изображается небольшим квадратом и привязывается к входному состоянию).
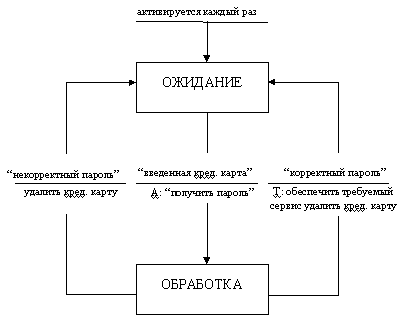
Рис. 6.1. Символы STD Диаграмма переходов состояний для примера банковской задачи приведена на рис. 6.2. Она содержит два состояния - ОЖИДАНИЕ и ОБРАБОТКА. Переход из состояния ОЖИДАНИЕ в состояние ОБРАБОТКА осуществляется при условии ввода кредитной карты (ВВЕДЕННАЯ КРЕДИТНАЯ КАРТА). При этом выполняется действие по запуску процесса 1.1 на рис. 2.8 (ПОЛУЧИТЬ ПАРОЛЬ). Отметим, что для запуска используется A-поток, обеспечивающий непрерывность процесса 1.1, т.е. возможность повторного ввода пароля. Переход из состояния ОБРАБОТКА в состояние ОЖИДАНИЕ осуществляется двумя различными способами. При условии трехкратного ввода неверного пароля (см. спецификацию процесса 1.1) кредитная карта удаляется из системы, при этом она переходит в режим ожидания очередного клиента. При условии КОРРЕКТНЫЙ ПАРОЛЬ выполняются действия по обеспечению требуемого сервиса (последовательное включение процессов 1.2 и 1.3) и удалению кредитной карты, и затем переход в режим ожидания очередного клиента.
Рис.6.2. STD для банковской задачи При построении STD рекомендуется следовать нижеперечисленным правилам:
Применяются два способа построения STD. Первый способ заключается в идентификации всех возможных состояний и дальнейшем исследовании всех не бессмысленных связей (переходов) между ними. По второму способу сначала строится начальное состояние, затем следующие за ним и т.д. Результат (оба способа) - предварительная STD, для которой затем осуществляется контроль состоятельности, заключающийся в ответе на следующие вопросы:
Таблица 6.1
В ситуации, когда число состояний и/или переходов велико, для проектирования спецификаций управления могут использоваться таблицы и матрицы переходов состояний. Обе эти нотации позволяют зафиксировать ту же самую информацию, что и диаграммы переходов состояний, но в другом формате. В качестве примера таблицы переходов состояний приведена таблица 6.1, соответствующая рассмотренной выше диаграмме переходов состояний (рис. 6.2). Первая колонка таблицы содержит список всех состояний проектируемой системы, во второй колонке для каждого состояния приведены все условия, вызывающие переходы в другие состояния, а в третьей колонке - совершаемые при этих переходах действия. Четвертая колонка содержит соответствующие имена состояний, в которые осуществляется переход из рассматриваемого состояния при выполнении определенного условия. Матрица переходов состояний содержит по вертикали перечень состояний системы, а по горизонтали список условий. Каждый ее элемент содержит список действий, а также имя состояния, в которое осуществляется переход. Используется и другой вариант данной нотации: по вертикали указываются состояния, из которых осуществляется переход, а по горизонтали - состояния, в которые осуществляется переход. При этом каждый элемент матрицы содержит соответствующие условия и действия, обеспечивающие переход из “вертикального” состояния в “горизонтальное”.
ГЛАВА 7
|
||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-04-04; просмотров: 1021; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.38 (0.016 с.) |