Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основы проектирования баз данныхСтр 1 из 15Следующая ⇒
ОСНОВЫ ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ КРАТКИЙ КУРС ЛЕКЦИЙ
Задание: Прочитать лекции и ответить на вопросы для самоконтроля и высылайте мне на почту ivanova_o_n20@mail.ru или загружайте в облако по ссылке https://cloud.mail.ru/public/2uY4/3VLX6UDMo Каждое занятие это новая лекция изучаете и отвечаете на вопросы и отправляете на проверку в файле например: Л1_Фамилия_Имя.doc. С уважением Иванова О.Н.
Содержание
Пояснительная записка 4 Лекция 1. Основные понятия теории баз данных 5 Лекция 2-3. Технологии работы с базами данных 10 Лекция 4. Логическая и физическая независимость данных 14 Лекция 5. Типы моделей данных. Реляционная модель данных 17 Лекция 6. Реляционная алгебра 22 Лекция 7. Основные этапы проектирования БД 24 Лекция 8. Концептуальное проектирование БД 29 Лекция 9. Нормализация БД 34 Лекция 10. Средства проектирования структур БД 36 Лекция 11. Организация интерфейса с пользователем 42 Лекция 12. Основные понятия языка SQL 46 Лекция 13. Синтаксис операторов, типы данных 49 Лекция 14. Создание, модификация и удаление таблиц 52 Лекция 15. Операторы манипулирования данными 55 Лекция 16-17. Организация запросов на выборку данных при помощи языка SQL 56 Лекция 18. Сортировка и группировка данных при помощи языка SQL 58 Лекция 19. Функции в запросах SQL 59 Литература 61
Лекция 1. Основные понятия теории баз данных План:
Компьютеры были созданы для решения вычислительных задач, однако со временем они все чаще стали использоваться для построения систем обработки документов, а точнее, содержащейся в них информации. Такие системы обычно и называют информационными. Информационные системы имеют следующие особенности:
Другими словами, информационная система требует создания в памяти ЭВМ динамически обновляемой модели внешнего мира с использованием единого хранилища - базы данных (БД). Предметная область - часть реального мира, подлежащая изучению с целью организации управления и, в конечном счете, автоматизации.
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными. В ряде современных систем метаданные, содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения, хранятся в словаре базы данных. Таким образом, система управления базой данных (СУБД) - важнейший компонент информационной системы. Для создания и управления информационной системой СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор. Основные функции СУБД:
История возникновения БД В истории вычислительной техники можно проследить развитие двух основных областей ее использования. Первая область — применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Характерной особенностью данной области применения вычислительной техники является наличие сложных алгоритмов обработки, которые применяются к простым по структуре данным, объем которых сравнительно невелик. Вторая область — это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Информационная система представляет собой программно-аппаратный комплекс, обеспечивающий выполнение следующих функций:
Обычно такие системы имеют дело с большими объемами информации, имеющей достаточно сложную структуру.
Важным шагом в развитии именно информационных систем явился переход к использованию централизованных систем управления файлами. С точки зрения прикладной программы, файл — это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным, хранящимся в файле, и структура этих данных зависят от конкретной системы управления файлами и, возможно, от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным. Пользователи видят файл как линейную последовательность записей и могут выполнить над ним ряд стандартных операций:
В разных файловых системах эти операции могли несколько отличаться, но общий смысл их был именно таким. Главное, что следует отметить, это то, что структура записи файла была известна только программе, которая с ним работала, система управления файлами не знала ее. И поэтому для того, чтобы извлечь некоторую информацию из файла, необходимо было точно знать структуру записи файла с точностью до бита. Каждая программа, работающая с файлом, должна была иметь у себя внутри структуру данных, соответствующую структуре этого файла. Поэтому при изменении структуры файла требовалось изменять структуру программы, а это требовало новой компиляции, то есть процесса перевода программы в исполняемые машинные коды. Такая ситуация характеризовалась как зависимость программ от данных. Для информационных систем характерным является наличие большого числа различных пользователей (программ), каждый из которых имеет свои специфические алгоритмы обработки информации, хранящейся в одних и тех же файлах. Изменение структуры файла, которое было необходимо для одной программы, требовало исправления и перекомпиляции и дополнительной отладки всех остальных программ, работающих с этим же файлом. Это было первым существенным недостатком файловых систем, который явился толчком к созданию новых систем хранения и управления информацией. Поскольку файловые системы являются общим хранилищем файлов, принадлежащих, вообще говоря, разным пользователям, системы управления файлами должны обеспечивать авторизацию доступа к файлам. В общем виде подход состоит в том, что по отношению к каждому зарегистрированному пользователю данной вычислительной системы для каждого существующего файла указываются действия, которые разрешены или запрещены данному пользователю. И отсутствие централизованных методов управления доступом к информации послужило еще одной причиной разработки СУБД. Следующей причиной стала необходимость обеспечения эффективной параллельной работы многих пользователей с одними и теми же файлами. В общем случае системы управления файлами обеспечивали режим многопользовательского доступа. Если операционная система поддерживает многопользовательский режим, вполне реальна ситуация, когда два или более пользователя одновременно пытаются работать с одним и тем же файлом. Если все пользователи собираются только читать файл, ничего страшного не произойдет. Но если хотя бы один из них будет изменять файл, для корректной работы этих пользователей требуется взаимная синхронизация их действий по отношению к файлу.
В системах управления файлами обычно применялся следующий подход. В операции открытия файла (первой и обязательной операции, с которой должен начинаться сеанс работы с файлом) среди прочих параметров указывался режим работы (чтение или изменение). Если к моменту выполнения этой операции некоторым пользовательским процессом PR1 файл был уже открыт другим процессом PR2 в режиме изменения, то в зависимости от особенностей системы процессу PR1 либо сообщалось о невозможности открытия файла, либо он блокировался до тех пор, пока в процессе PR2 не выполнялась операция закрытия файла. При подобном способе организации одновременная работа нескольких пользователей, связанная с модификацией данных в файле, либо вообще не реализовывалась, либо была очень замедлена. Эти недостатки послужили тем толчком, который заставил разработчиков информационных систем предложить новый подход к управлению информацией. Этот подход был реализован в рамках новых программных систем, названных впоследствии Системами Управления Базами Данных (СУБД), а сами хранилища информации, которые работали под управлением данных систем, назывались базами или банками данных (БД и БнД).
История развития БД
Концепция БД сложилась в конце 60-х годов прошлого столетия и с тех пор постоянно развивалась. Первый этап сложился к началу 60-х годов прошлого века и характеризуется следующими признаками:
Второй этап относится к середине 60-х годов и имеет следующие особенности:
Третий этап начался с конца 60-х годов. Основным достижением можно считать осознание необходимости централизации данных для доступа к ним различных приложений. При этом уменьшается избыточность и противоречивость информации, приложения используют стандартные средства доступа к данным. На этом этапе возросла сложность организации данных, был реализован эффективный поиск записей по многим ключам.
Именно на этом этапе появились первые СУБД. Прежде всего развивались теория и практика построения иерархических и сетевых СУБД. В этих моделях связи данных описываются с помощью деревьев и графов общего вида. Четвертый этап датируется второй половиной 70-х годов. На этом этапе были реализованы следующие основные характеристики СУБД:
С начала 70-х годов после публикаций Э.Кодда начались активные исследования реляционной модели данных. Основу реляционной СУБД составляют таблицы. Вплоть до 80-х годов реляционные СУБД считались перспективными, но трудными для реализации. Новый этап в развитии СУБД наступил при появлении персональных компьютеров. На этом этапе на передний план вышли такие особенности СУБД, как:
Классификация БД
Классификация БД может быть произведена по различным признакам, среди которых выделяют:
Классификация не является полной. Различные источники предоставляют разнообразную классификацию. Вопросы для самоконтроля:
Архитектура базы данных
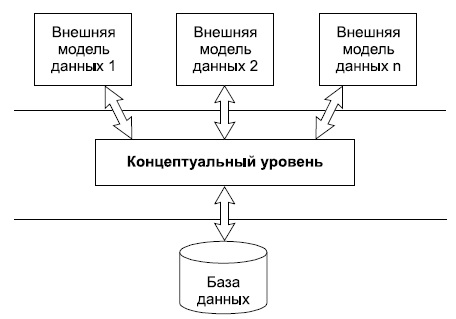
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рисунке 5.
Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое "видение" данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира. Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации. Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Сетевая модель базы данных
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1:N. Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения.
Типы связей между объектами
Все информационные объекты предметной области связаны между собой. Соответствия, отношения, возникающие между объектами предметной области, называются связями. Связанные отношениями таблицы взаимодействуют по принципу главная, подчиненная. Возможны следующие отношения между таблицами: 1. Отношение «один – ко – многим» (обозначают 1:М): одной записи из главной таблицы может соответствовать ноль, одна или несколько записей подчинённой таблицы. 2. Отношение «один – к - одному» (обозначают 1:1): одной записи из главной таблицы соответствует только одна запись из подчинённой таблицы. 3. Отношение «многие – ко – многим» (обозначают 1:1):одной записи из главной таблицы может соответствовать ноль, одна или несколько записей подчинённой таблицы и наоборот.
Одним из правил ссылочной целостности (referential integrity) является то, что первичный ключ любой таблицы должен содержать уникальные непустые значения для данной таблицы. Некоторые СУБД могут контролировать уникальность первичных ключей. Если СУБД контролирует уникальность первичных ключей, то при попытке присвоить первичному ключу значение, уже имеющееся в другой записи, СУБД сгенерирует диагностическое сообщение, обычно содержащее словосочетания primary key violation. Это сообщение в дальнейшем может быть передано в приложение, с помощью которого конечный пользователь манипулирует данными. Если две таблицы связаны соотношением главная-подчиненная, внешний ключ подчинённой таблицы должен содержать только те значения, которые имеются среди значений первичного ключа главной таблицы. Если корректность значений внешних ключей не контролируется СУБД, можно говорить о нарушении ссылочной целостности. Если же СУБД контролирует корректность значений внешних ключей, то при попытке присвоить внешнему ключу значение, отсутствующее среди значений первичных ключей главной таблицы, либо при удалении или модификации записей главной таблицы, приводящих к нарушению ссылочной целостности, СУБД сгенерирует сообщение, о котором говорилось выше.
Вопросы для самоконтроля:
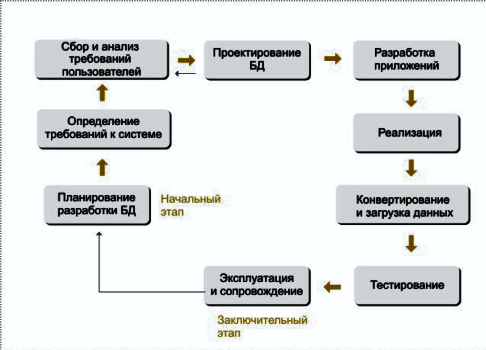
Жизненный цикл БД Как и любой программный продукт, база данных обладает собственным жизненным циклом (ЖЦБД). Главной составляющей в жизненном цикле БД является создание единой базы данных и программ, необходимых для ее работы. ЖЦБД включает в себя следующие основные этапы (рисунок 7):
Рисунок 7 - Жизненный цикл БД
Планирование разработки базы данных
Содержание данного этапа — разработка стратегического плана, в процессе которой осуществляется предварительное планирование конкретной системы управления базами данных. Планирование разработки базы данных состоит в определении трех основных компонентов: объема работ, ресурсов и стоимости проекта. Важной частью разработки стратегического плана является проверка осуществимости проекта, состоящая из нескольких частей. Первая часть — проверка технологической осуществимости. Она состоит в выяснении вопроса, существует ли оборудование и программное обеспечение, удовлетворяющее информационным потребностям фирмы. Вторая часть — проверка операционной осуществимости — выяснение наличия экспертов и персонала, необходимых для работы БД. Третья часть — проверка экономической целесообразности осуществления проекта. При исследовании этой проблемы весьма важно дать оценку ряду факторов, в том числе и таким:
Определение требований к системе
На данном этапе необходимо определить диапазон действия приложения базы данных, состав его пользователей и области применения. Определение требований включает выбор целей БД, выяснение информационных потребностей различных отделов и руководителей фирмы и требований к оборудованию и программному обеспечению.
Сбор и анализ требований пользователей
На данном этапе необходимо создать для себя модель движения важных материальных объектов и уяснить процесс документооборота. По каждому документу необходимо установить периодичность использования, определить данные, необходимые для выполнения выделенных функций (анализируя существующую и планируемую документацию, выясняют, как получается каждый элемент данных, кем получается, где в дальнейшем используется, кем контролируется. Собранная информация о каждой важной области применения приложения и пользовательской группе должна включать следующие компоненты: исходную и генерируемую документацию, подробные сведения о выполняемых транзакциях, а также список требований с указанием их приоритетов. Формализация собранной на этом этапе информации может быть повышена с помощью методов составления спецификаций требований, к числу которых относятся, например, технология структурного анализа и проектирования, диаграммы потоков данных и графики "вход — процесс — выход".
Проектирование базы данных
Полный цикл разработки базы данных включает концептуальное, логическое и физическое ее проектирование. Разработка приложений
Параллельно с проектированием системы базы данных выполняется разработка приложений. Главные составляющие данного процесса — это проектирование транзакций и пользовательского интерфейса. Проектирование транзакций Транзакции представляют некоторые события реального мира. Транзакция может состоять из нескольких операций, однако с точки зрения пользователя эти операции представляют собой единое целое, переводящее базу данных из одного непротиворечивого состояния в другое. Реализация транзакций опирается на тот факт, что СУБД способна обеспечивать сохранность внесенных во время транзакции изменений в БД и непротиворечивость базы данных даже в случае возникновения сбоя. Проектирование транзакций заключается в определении:
Реализация
На данном этапе осуществляется физическая реализация базы данных и разработанных приложений, позволяющих пользователю формулировать требуемые запросы к БД и манипулировать данными в БД. База данных описывается на языке определения данных выбранной СУБД. В результате компиляции его команд и их выполнения создаются схемы и пустые файлы базы данных. На этом же этапе определяются и все специфические пользовательские представления. Прикладные программы реализуются с помощью языков третьего или четвертого поколений. Кроме того, на этом этапе создаются другие компоненты проекта приложения — например, экраны меню, формы ввода данных и отчеты. Реализация этого, а также и более ранних этапов проектирования БД может осуществляться с помощью инструментов автоматизированного проектирования и создания программ, которые принято называть CASE-инструментами (Computer-Aided Software Engineering).
Загрузка данных
На этом этапе созданные в соответствии со схемой базы данных пустые файлы, предназначенные для хранения информации, должны быть заполнены данными. Наполнение базы данных может протекать по-разному, в зависимости от того, создается ли база данных вновь или новая база данных предназначена для замены старой.
Тестирование
Для оценки законченности и корректности выполнения приложения базы данных может использоваться несколько различных стратегий тестирования:
Вопросы для самоконтроля:
Формулирование сущностей На этом этапе необходимо указать типы объектов, о которых нужно хранить информацию. Иногда это сложно сделать, так как отдельный объект можно представить и в виде сущности, и в виде атрибута и в виде связи. Тогда следует проработать несколько вариантов моделей и выбрать наиболее гибкий. Каждой выбранной сущности должно быть присвоено четкое наименование. Общее их количество не должно быть большим. Спецификация связей Выявляются зависимости между двумя и более сущностями. Определяется какие из них необходимые, какие избыточные. Каждый тип связи именуется. Рассмотрим понятие класс принадлежности сущности. Если каждый экземпляр сущности А связан с экземпляром сущности В, то класс принадлежности сущности А является обязательным. Это отмечается на ER-диаграмме черным кружком, помещённым в прямоугольник, смежный с прямоугольником сущности А. Если не каждый экземпляр сущности А связан с экземпляром сущности В, то класс принадлежности сущности является необязательным. Это отмечается на ER-диаграмме черным кружком, помещённым на линии связи возле прямоугольника сущности А.
Правила преобразования ER-диаграмм в реляционные таблицы
Концептуальные модели позволяют более точно представить предметную область, чем реляционные и другие более ранние модели. Но в настоящее время существует немного СУБД, поддерживающих эти модели. На практике наиболее распространены системы, реализующие реляционную модель. Поэтому необходим метод перевода концептуальной модели в реляционную. Такой метод основывается на формировании набора предварительных таблиц из ER-диаграмм. Для каждой сущности создается таблица. Причем каждому атрибуту сущности соответствует столбец таблицы. Правила генерации таблиц из ER-диаграмм опираются на два основных фактора – тип связи и класс принадлежности сущности. Изложим их. Правило 1: Если связь типа 1:1 и класс принадлежности обеих сущностей является обязательным, то необходима только одна таблица. Первичным ключом этой таблицы может быть первичный ключ любой из двух сущностей. Правило 2: Если связь типа 1:1 и класс принадлежности одной сущности является обязательным, а другой - необязательным, то необходимо построить таблицу для каждой сущности. Первичный ключ сущности должен быть первичным ключом соответствующей таблицы. Первичный ключ сущности, для которой класс принадлежности является необязательным, добавляется как атрибут в таблицу сущности с обязательным классом принадлежности. Правило 3: Если связь типа 1:1 и класс принадлежности обеих сущностей необязательный, то необходимо построить три таблицы - по одной для каждой сущности и одну для связи. Первичный ключ сущности должен быть первичным ключом соответствующей таблицы. Таблица для связи среди своих атрибутов должна иметь ключи обеих сущностей. Правило 4: Если связь типа 1:М и класс принадлежности сущности на стороне М является обязательным, то необходимо построить таблицу для каждой сущности. Первичный ключ сущности должен быть первичным ключом соответствующей таблицы. Первичный ключ сущности на стороне 1 добавляется как атрибут в таблицу для сущности на стороне М. Правило 5: Если связь типа 1:М и класс принадлежности сущности на стороне М является необязательным, то необходимо построить три таблицы - по одной для каждой сущности и одну для связи. Первичный ключ сущности должен быть первичным ключом соответствующей таблицы. Таблица для связи среди своих атрибутов должна иметь ключи обеих сущностей. Правило 6: Если связь типа М:N, то необходимо построить три таблицы - по одной для каждой сущности и одну для связи. Первичный ключ сущности должен быть первичным ключом соответствующей таблицы. Таблица для связи среди своих атрибутов должна иметь ключи обеих сущностей.
Вопросы для самоконтроля:
Лекция 9. Нормализация БД План:
При проектировании БД могут появиться нежелательные свойства, такие как избыточность, аномалии обновления, аномалии включения, аномалии удаления и др. Для уменьшения нежелательных характеристик БД к схемам отношений применяют процедуры нормализации. Нормализация - это разбиение таблицы на две или более, обладающие лучшими свойствами при включении, изменении и удалении данных. Окончательная цель нормализации сводится к получению такого проекта базы данных, в котором каждый факт появляется лишь в одном месте, т.е. исключена избыточность информации. Это делается не столько с целью экономии памяти, сколько для исключения возможной противоречивости хранимых данных. Нормализация – это процесс разделения информации на структурные единицы, т.е. таблицы. Нормализация БД должна быть выполнена с учётом следующего правила: таблицы, которые содержат повторяющуюся информацию, для устранения дублирования значений должны быть разделены на отдельные таблицы, что приводит к сокращению размеров БД. В теории реляционных баз данных вводятся понятия так называемых “нормальных форм” — требований к организации данных в таблицах. Нормальные формы нумеруются последовательно, по мере ужесточения требований. В правильно спроектированной БД таблицы находятся как минимум в третьей нормальной форме. Так же можно сказать, что процесс нормализации представляет собой приведение таблиц к требуемому уровню нормальности: первый, второй и третий. Каждый уровень нормальности соответствует определённой нормальной форме. Теория нормализации основана на концепции нормальных форм. Говорят, что таблица находится в данной нормальной форме, если она удовлетворяет определенному набору требований. Теоретически существует пять нормальных форм, но на практике обычно используются только первые три. Первые две нормальные формы являются промежуточными шагами для приведения базы данных к третьей нормальной форме.
Высшие нормальные формы
В теории реляционных баз данных рассматриваются и формы высших порядков — нормальная форма Бойса — Кодда, 4НФ, 5НФ и даже выше. Большого практического значения эти формы не имеют, и разработчики, как правило, всегда останавливаются на 3НФ.
Вопросы для самоконтроля:
Классификация СУБД
Классифицировать СУБД можно по следующим признакам:
Требования к СУБД
Выбор СУБД является одним из важных этапов при разработке приложений баз данных. Выбранный программный продукт должен удовлетворять как текущим, так и будущим потребностям предприятия, при этом следует учитывать финансовые затраты на приобретение необходимого оборудования, самой системы, разработку необходимого программного обеспечения на ее основе, а также обучение персонала. Кроме того, необходимо убедиться, что новая СУБД способна принести предприятию реальные выгоды. Очевидно, наиболее простой подход при выборе СУБД основан на оценке того, в какой мере существующие системы удовлетворяют основным требованиям создаваемого проекта информационной системы. Более сложным и дорогостоящим вариантом является создание испытательного проекта на основе нескольких СУБД и последующий выбор наиболее подходящего. Но и в этом случае используются определенные критерии отбора. Перечень требований к СУБД может изменяться в зависимости от поставленных целей. Тем не менее, можно выделить несколько групп критериев:
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-02-07; просмотров: 1725; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.105.108 (0.148 с.) |