
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Особенности алгоритмов управления ресурсамиСодержание книги
Поиск на нашем сайте Основные понятия и концепция операционных систем. Режимы работы ОС. Системные вызовы В любой операционной системе поддерживается механизм, который позволяет пользовательским программам обращаться к услугам ядра ОС. В операционных системах наиболее известной советской вычислительной машины БЭСМ-6 соответствующие средства "общения" с ядром назывались экстракодами, в операционных системах IBM они назывались системными макрокомандами и т.д. В ОС Unix такие средства называют системными вызовами. Системные вызовы (system calls) – это интерфейс между операционной системой и пользовательской программой. Они создают, удаляют и используют различные объекты, главные из которых – процессы и файлы. Пользовательская программа запрашивает сервис у операционной системы, осуществляя системный вызов. Имеются библиотеки процедур, которые загружают машинные регистры определенными параметрами и осуществляют прерывание процессора, после чего управление передается обработчику данного вызова, входящему в ядро операционной системы. Цель таких библиотек – сделать системный вызов похожим на обычный вызов подпрограммы. Основное отличие состоит в том, что при системном вызове задача переходит в привилегированный режим или режим ядра (kernel mode). Поэтому системные вызовы иногда еще называют программными прерываниями, в отличие от аппаратных прерываний, которые чаще называют просто прерываниями. В этом режиме работает код ядра операционной системы, причем исполняется он в адресном пространстве и в контексте вызвавшей его задачи. Таким образом, ядро операционной системы имеет полный доступ к памяти пользовательской программы, и при системном вызове достаточно передать адреса одной или нескольких областей памяти с параметрами вызова и адреса одной или нескольких областей памяти для результатов вызова. В большинстве операционных систем системный вызов осуществляется командой программного прерывания (INT). Программное прерывание – это синхронное событие, которое может быть повторено при выполнении одного и того же программного кода. Прерывания Прерывание (hardware interrupt) – это событие, генерируемое внешним (по отношению к процессору) устройством. Посредством аппаратных прерываний аппаратура либо информирует центральный процессор о том, что произошло какое-либо событие, требующее немедленной реакции (например, пользователь нажал клавишу), либо сообщает о завершении асинхронной операции ввода-вывода (например, закончено чтение данных с диска в основную память). Важный тип аппаратных прерываний – прерывания таймера, которые генерируются периодически через фиксированный промежуток времени. Прерывания таймера используются операционной системой при планировании процессов. Каждый тип аппаратных прерываний имеет собственный номер, однозначно определяющий источник прерывания. Аппаратное прерывание – это асинхронное событие, то есть оно возникает вне зависимости от того, какой код исполняется процессором в данный момент. Обработка аппаратного прерывания не должна учитывать, какой процесс является текущим. Исключительные ситуации Исключительная ситуация (exception) – событие, возникающее в результате попытки выполнения программой команды, которая по каким-то причинам не может быть выполнена до конца. Примерами таких команд могут быть попытки доступа к ресурсу при отсутствии достаточных привилегий или обращения к отсутствующей странице памяти. Исключительные ситуации, как и системные вызовы, являются синхронными событиями, возникающими в контексте текущей задачи. Исключительные ситуации можно разделить на исправимые и неисправимые. К исправимым относятся такие исключительные ситуации, как отсутствие нужной информации в оперативной памяти. После устранения причины исправимой исключительной ситуации программа может выполняться дальше. Возникновение в процессе работы операционной системы исправимых исключительных ситуаций считается нормальным явлением. Неисправимые исключительные ситуации чаще всего возникают в результате ошибок в программах (например, деление на ноль). Обычно в таких случаях операционная система реагирует завершением программы, вызвавшей исключительную ситуацию. Файлы Файлы предназначены для хранения информации на внешних носителях, то есть принято, что информация, записанная, например, на диске, должна находиться внутри файла. Обычно под файлом понимают именованную часть пространства на носителе информации. Главная задача файловой системы (file system) – скрыть особенности ввода-вывода и дать программисту простую абстрактную модель файлов, независимых от устройств. Для чтения, создания, удаления, записи, открытия и закрытия файлов также имеется обширная категория системных вызовов (создание, удаление, открытие, закрытие, чтение и т.д.). Пользователям хорошо знакомы такие связанные с организацией файловой системы понятия, как каталог, текущий каталог, корневой каталог, путь. Для манипулирования этими объектами в операционной системе имеются системные вызовы
Монолитное ядро По сути дела, операционная система – это обычная программа, поэтому было бы логично и организовать ее так же, как устроено большинство программ, то есть составить из процедур и функций. В этом случае компоненты операционной системы являются не самостоятельными модулями, а составными частями одной большой программы. Такая структура операционной системы называется монолитным ядром (monolithic kernel). Монолитное ядро представляет собой набор процедур, каждая из которых может вызвать каждую. Все процедуры работают в привилегированном режиме. Таким образом, монолитное ядро – это такая схема операционной системы, при которой все ее компоненты являются составными частями одной программы, используют общие структуры данных и взаимодействуют друг с другом путем непосредственного вызова процедур. Для монолитной операционной системы ядро совпадает со всей системой. Во многих операционных системах с монолитным ядром сборка ядра, то есть его компиляция, осуществляется отдельно для каждого компьютера, на который устанавливается операционная система. При этом можно выбрать список оборудования и программных протоколов, поддержка которых будет включена в ядро. Так как ядро является единой программой, перекомпиляция – это единственный способ добавить в него новые компоненты или исключить неиспользуемые. Следует отметить, что присутствие в ядре лишних компонентов крайне нежелательно, так как ядро всегда полностью располагается в оперативной памяти. Кроме того, исключение ненужных компонентов повышает надежность операционной системы в целом. Монолитное ядро – старейший способ организации операционных систем. Примером систем с монолитным ядром является большинство Unix-систем. Даже в монолитных системах можно выделить некоторую структуру. Как в бетонной глыбе можно различить вкрапления щебенки, так и в монолитном ядре выделяются вкрапления сервисных процедур, соответствующих системным вызовам. Сервисные процедуры выполняются в привилегированном режиме, тогда как пользовательские программы – в непривилегированном. Для перехода с одного уровня привилегий на другой иногда может использоваться главная сервисная программа, определяющая, какой именно системный вызов был сделан, корректность входных данных для этого вызова и передающая управление соответствующей сервисной процедуре с переходом в привилегированный режим работы. Иногда выделяют также набор программных утилит, которые помогают выполнять сервисные процедуры. Begin while истина do Begin первомувходитьнельзя: = истина; while первомувходитьнельзя do testandset (первомувходитьнельзя, активный); критическийучастокодин; активный: = ложь; прочиеоператорыодин End end; procedure процессдва; var второмувходитьнельзя: логический; Begin while истина do Begin второмувходитьнельзя: = истина; while второмувходитьнельзя do testandset (второмувходитьнельзя, активный); критическийучастокдва; активный: = ложь; прочиеоператорыдва end end; Begin активный: = ложь; Parbegin процессодин; процессдва parend end; Рис. 1. Реализация взаимоисключения при помощи команды testandsef (ПРОВЕРИТЬ И УСТАНОВИТЬ).
Переменная «активный» логического типа имеет значение «истина», когда любой из процессов находится в своем критическом участке, и значение «ложь» в противном случае. «Процессодин» принимает решение о входе в критический участок в зависимости от значения своей локальной логической переменной «первомувходитьнельзя». Он устанавливает для переменной «первомувходитьнельзя» значение «истина», а затем многократно выполняет команду проверки и установки для глобальной логической переменной «активный». Если «процессдва» находится вне критического участка, переменная «активный» будет иметь значение «ложь». Команда проверки и установки запишет это значение в «первомувходитьнельзя» и установит] значение «истина» для переменной «активный». При проверке в цикле while будет получен результат «ложь», и «процессодин» войдет в свой критический участок. Поскольку для переменной «активный» установлено значение «истина», «процессдва» в свой критический участок войти не может. Предположим теперь, что «процессдва» уже находится в своем критическом участке, когда «процессодин» хочет войти в критический участок. «Процессодин» устанавливает значение «истина» для переменной «первомувходитьнельзя», а затем многократно проверяет значение переменной «активный» по команде testandset. Поскольку «процессдва» находится в своем критическом участке, это значение остается истинным. Каждая команда проверки и установки обнаруживает, что «активный» имеет значение «истина», и устанавливает это значение для переменных «первомувходитьнельзя» и «активный». Таким образом, «процессодин» продолжает находиться в цикле активного ожидания, пока «процессдва» в конце концов не выйдет из своего критического участка и не установит значение «ложь» для переменной «активный». В этот момент команда проверки и установки, обнаружив это значение переменной «активный» (и установив для нее истинное значение, чтобы «процессдва» не мог больше войти в свой критический участок), установит значение «ложь» для переменной «первомувходитьнельзя», что позволит, чтобы «процессодин» вошел в свой критический участок. Этот способ реализации взаимоисключения не исключает бесконечного откладывания, однако здесь вероятность такой ситуации весьма мала, особенно если в системе имеется несколько процессоров. Когда процесс, выходя из своего критического участка, устанавливает значение «ложь» переменной «активный», команда проверки и установки testandset другого процесса, вероятнее всего, сможет «перехватить» переменную «активный» (установив для нее значение «истина») до того, как первый процесс успеет пройти цикл, чтобы снова установить значение «истина» для этой переменной. Семафоры
Все описанные выше ключевые понятия, относящиеся к взаимоисключению, Дейкстра суммировал в своей концепции семафоров (Di65). Семафор — это защищенная переменная, значение которой можно опрашивать и менять только при помощи специальных операций Р и V и операции инициализации, которую мы будем называть «инициализациясемафора». Двоичные семафоры могут принимать только значения 0 и 1. Считающие семафоры (семафоры со счетчиками) могут принимать неотрицательные целые значения. Операция Р над семафором записывается как P(S) и выполняется следующим образом: если S > О то S: =S— 1 иначе (ожидать на S)
Операция V над семафором S записывается как V(S) и выполняется следующим образом; если (один или более процессов ожидают на S) то (разрешить одному из этих процессов продолжить работу) иначе S: = S + 1
Будем предполагать, что очередь процессов, ожидающихна обслуживается в соответствии с дисциплиной «первый пришедший обслуживается первым» (FIFO). Подобно операции проверки и установки testandset, операции Р и V являются неделимыми. Участки взаимоисключения по семафору S в процессах обрамляются операциями P(S) и V(S). Если одновременно несколько процессов попытаются выполнить операцию P(S), это будет разрешено только одному из них, а остальным придется ждать. Семафоры и операции над ними могут быть реализованы как программно, так и аппаратно. Как правило, они реализуются в ядре операционной системы, где осуществляется управление сменой состояния процессов. На рис. 2 приводится пример того, каким образом можно обеспечить взаимоисключение при помощи семафоров. Здесь примитив Р (активный) — эквивалент для «входвзаимоисключения», а примитив V (активный) — для «выходвзаимоисключения». program примерсемафораодин; var активный: семафор; procedure процессодин; Begin while истина do begin предшествующиеоператорыодин; Р(активный); критическийучастокодин; V(активный); прочиеоператорыодин; end end; procedure процессдва; Begin while истина do begin предшествующиеоператорыдва Р(активный); критическийучастокдва; V(активный); прочиеоператорыдва еnd end; Begin инициализациясемафора(активный,1); Parbegin процессодин; процессдва parend end; Рис. 2. Обеспечение взаимоисключения при помощи семафора и примитивов Р и V. Begin предшествующиеоператорыодин; Р(событие); прочиеоператорыодин end; procedure процессдва; Begin предшествующиеоператорыдва; V(событие); прочиеоператорыдва end; Begin инициализациясемафора(событие,0); Parbegin процессодин; процессдва parend end; Рис. 3. Синхронизация блокирования/возобновление процессов при помощи семафоров.
Здесь «процессодин» выполняет некоторые «предшествующие операторыодин», а затем операцию Р (событие). Ранее при инициализации семафор был установлен в нуль, так что «процессодин» будет ждать. Со временем «процессдва» выполнит операцию V (событие), сигнализируя о том, что данное событие произошло. Тем самым «процессодин» получает возможность продолжить свое выполнение. Отметим, что подобный механизм будет выполнять свои функции даже в том случае, если «процессдва» обнаружит наступление события и просигнализирует об этом еще до того, как «процессодин» выполнит операцию Р (событие); при этом семафор переключится из 0 в 1, так что операция Р (событие) просто произведет обратное Переключение, из 1 в 0, и «процессодин» продолжит свое выполнение без ожидания.
Операции над семафорами
Системный вызов semop(2) производит операции над одним или более семафорами из набора. Операции увеличивают или уменьшают значение семафора на заданную величину, или ожидают, пока семафор не станет нулевым.
Аргументы этого системного вызова таковы:
semid Идентификатор набора семафоров, полученный от semget(2).
sops Адрес массива с элементом типа struct sembuf, задающих операции над семафорами. По этому адресу должно размещаться nsops таких структур. Эта структура определена следующим образом:
sys/sem.h: struct sembuf { ushort sem_num; /* semaphore */ short sem_op; /* semaphore operation */ short sem_flg; /* operation flags */ };
Поля этой структуры имеют следующий смысл:
sem_num Индекс семафора, над которым производится операция, в наборе.
sem_op Если это значение положительно, оно добавляется к текущему значению семафора. Обычно это означает разблокировку или освобождение соответствующего количества ресурсов. Если sem_op отрицательно, и его абсолютное значение больше текущего значения семафора, операция обычно блокируется. Иначе, из семафора просто вычитается абсолютное значение этого поля. Обычно это означает блокировку или захват соответствующего количества ресурсов. Если sem_op равен нулю, операция блокируется, пока семафор не станет нулевым.
sem_flg Это поле задает дополнительные флаги. Нулевое значение означает, что не задано никаких флагов.Допустимы следующие флаги:
IPC_NOWAIT Если установлен этот флаг, и операция не может быть выполнена, semop(2) возвращает неуспех вместо блокировки, которая происходит обычно. Этот флаг может быть использован для анализа и изменения значения семафора без блокировки. SEM_UNDO Если этот флаг установлен, при завершении программы (как нормальном, так и ненормальном), значение семафора будет установлено таким, какое оно было до операции. Это защищает от "посмертной" блокировки ресурса программой, которая ненормально завершилась, не успев освободить ресурс. Замечание: При выполнении операции над несколькими семафорами, значения семафоров не меняются, пока не окажется, что все требуемые операции могут быть успешно выполнены. Помните, что блокировка может произойти при работе без IPC_NOWAIT, когда программа ожидает нулевого значения или пытается выполнить вычитание.
nsops Количество структур в массиве, на который указывает sops. nsops должен всегда быть больше или равен 1. ОПЕРАЦИИ НАД СЕМАФОРАМИ semop(2)
ИМЯ
semop - операции над семафорами
ИСПОЛЬЗОВАНИЕ
#include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h>
int semop(int semid, struct smbuf *sops, unsigned nsops);
ВОЗВРАЩАЕМОЕ ЗНАЧЕНИЕ
успех - ноль
неуспех - -1 и errno установлена
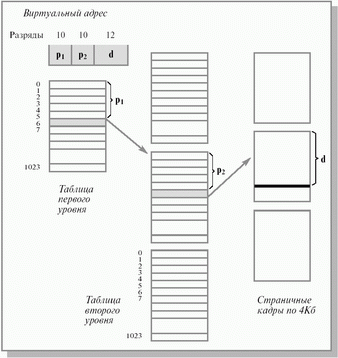
Система управления памятью. Структура таблицы страниц Организация таблицы страниц – один из ключевых элементов отображения адресов в страничной и сегментно-страничной схемах. Рассмотрим структуру таблицы страниц для случая страничной организации более подробно. Итак, виртуальный адрес состоит из виртуального номера страницы и смещения. Номер записи в таблице страниц соответствует номеру виртуальной страницы. Размер записи колеблется от системы к системе, но чаще всего он составляет 32 бита. Из этой записи в таблице страниц находится номер кадра для данной виртуальной страницы, затем прибавляется смещение и формируется физический адрес. Помимо этого запись в таблице страниц содержит информацию об атрибутах страницы. Это биты присутствия и защиты (например, 0 – read/write, 1 – read only...). Также могут быть указаны: бит модификации, который устанавливается, если содержимое страницы модифицировано, и позволяет контролировать необходимость перезаписи страницы на диск; бит ссылки, который помогает выделить малоиспользуемые страницы; бит, разрешающий кэширование, и другие управляющие биты. Заметим, что адреса страниц на диске не являются частью таблицы страниц. Основную проблему для эффективной реализации таблицы страниц создают большие размеры виртуальных адресных пространств современных компьютеров, которые обычно определяются разрядностью архитектуры процессора. Самыми распространенными на сегодня являются 32-разрядные процессоры, позволяющие создавать виртуальные адресные пространства размером 4 Гбайт (для 64-разрядных компьютеров эта величина равна 264 байт). Кроме того, существует проблема скорости отображения, которая решается за счет использования так называемой ассоциативной памяти (см. следующий раздел). Подсчитаем примерный размер таблицы страниц. В 32-битном адресном пространстве при размере страницы 4 Кбайт (Intel) получаем 232/212=220, то есть приблизительно миллион страниц, а в 64-битном и того более. Таким образом, таблица должна иметь примерно миллион строк (entry), причем запись в строке состоит из нескольких байтов. Заметим, что каждый процесс нуждается в своей таблице страниц (а в случае сегментно-страничной схемы желательно иметь по одной таблице страниц на каждый сегмент). Понятно, что количество памяти, отводимое таблицам страниц, не может быть так велико. Для того чтобы избежать размещения в памяти огромной таблицы, ее разбивают на ряд фрагментов. В оперативной памяти хранят лишь некоторые, необходимые для конкретного момента исполнения фрагменты таблицы страниц. В силу свойства локальности число таких фрагментов относительно невелико. Выполнить разбиение таблицы страниц на части можно по-разному. Наиболее распространенный способ разбиения – организация так называемой многоуровневой таблицы страниц. Для примера рассмотрим двухуровневую таблицу с размером страниц 4 Кбайт, реализованную в 32-разрядной архитектуре Intel. Таблица, состоящая из 220 строк, разбивается на 210 таблиц второго уровня по 210 строк. Эти таблицы второго уровня объединены в общую структуру при помощи одной таблицы первого уровня, состоящей из 210 строк. 32-разрядный адрес делится на 10-разрядное поле p1, 10-разрядное поле p2 и 12-разрядное смещение d. Поле p1 указывает на нужную строку в таблице первого уровня, поле p2 – второго, а поле d локализует нужный байт внутри указанного страничного кадра (см. рис. 9.1).
При помощи всего лишь одной таблицы второго уровня можно охватить 4 Мбайт (4 Кбайт x 1024) оперативной памяти. Таким образом, для размещения процесса с большим объемом занимаемой памяти достаточно иметь в оперативной памяти одну таблицу первого уровня и несколько таблиц второго уровня. Очевидно, что суммарное количество строк в этих таблицах много меньше 220. Такой подход естественным образом обобщается на три и более уровней таблицы. Наличие нескольких уровней, естественно, снижает производительность менеджера памяти. Несмотря на то что размеры таблиц на каждом уровне подобраны так, чтобы таблица помещалась целиком внутри одной страницы, обращение к каждому уровню – это отдельное обращение к памяти. Таким образом, трансляция адреса может потребовать нескольких обращений к памяти. Количество уровней в таблице страниц зависит от конкретных особенностей архитектуры. Можно привести примеры реализации одноуровневого (DEC PDP-11), двухуровневого (Intel, DEC VAX), трехуровневого (Sun SPARC, DEC Alpha) пейджинга, а также пейджинга с заданным количеством уровней (Motorola). Функционирование RISC-процессора MIPS R2000 осуществляется вообще без таблицы страниц. Здесь поиск нужной страницы, если эта страница отсутствует в ассоциативной памяти, должна взять на себя ОС (так называемый zero level paging).
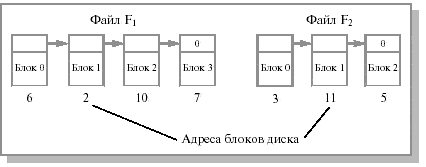
Управление внешней памятью Прежде чем описывать структуру данных файловой системы на диске, необходимо рассмотреть алгоритмы выделения дискового пространства и способы учета свободной и занятой дисковой памяти. Эти задачи связаны между собой. Связный список Внешняя фрагментация - основная проблема рассмотренного выше метода - может быть устранена за счет представления файла в виде связного списка блоков диска. Запись в директории содержит указатель на первый и последний блоки файла (иногда в качестве варианта используется специальный знак конца файла - EOF). Каждый блок содержит указатель на следующий блок (см.рис. 12.2).
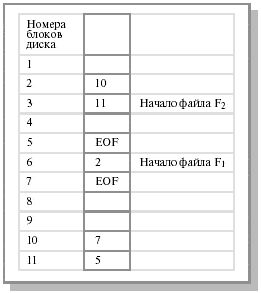
Внешняя фрагментация для данного метода отсутствует. Любой свободный блок может быть использован для удовлетворения запроса. Заметим, что нет необходимости декларировать размер файла в момент создания. Файл может расти неограниченно. Связное выделение имеет, однако, несколько существенных недостатков. Во-первых, при прямом доступе к файлу для поиска i-го блока нужно осуществить несколько обращений к диску, последовательно считывая блоки от 1 до i-1, то есть выборка логически смежных записей, которые занимают физически несмежные секторы, может требовать много времени. Здесь мы теряем все преимущества прямого доступа к файлу. Во-вторых, данный способ не очень надежен. Наличие дефектного блока в списке приводит к потере информации в оставшейся части файла и потенциально к потере дискового пространства, отведенного под этот файл. Наконец, для указателя на следующий блок внутри блока нужно выделить место, что не всегда удобно. Емкость блока, традиционно являющаяся степенью двойки (многие программы читают и пишут блоками по степеням двойки), таким образом, перестает быть степенью двойки, так как указатель отбирает несколько байтов. Поэтому метод связного списка обычно в чистом виде не используется. Таблица отображения файлов Одним из вариантов предыдущего способа является хранение указателей не в дисковых блоках, а в индексной таблице в памяти, которая называется таблицей отображения файлов (FAT - file allocation table) (см. рис. 12.3). Этой схемы придерживаются многие ОС (MS-DOS, OS/2, MS Windows и др.) По-прежнему существенно, что запись в директории содержит только ссылку на первый блок. Далее при помощи таблицы FAT можно локализовать блоки файла независимо от его размера. В тех строках таблицы, которые соответствуют последним блокам файлов, обычно записывается некоторое граничное значение, например EOF. Главное достоинство данного подхода состоит в том, что по таблице отображения можно судить о физическом соседстве блоков, располагающихся на диске, и при выделении нового блока можно легко найти свободный блок диска, находящийся поблизости от других блоков данного файла. Минусом данной схемы может быть необходимость хранения в памяти этой довольно большой таблицы.
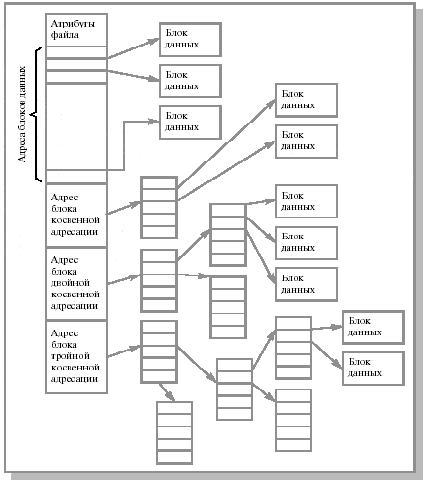
Индексные узлы Наиболее распространенный метод выделения файлу блоков диска - связать с каждым файлом небольшую таблицу, называемую индексным узлом (i-node), которая перечисляет атрибуты и дисковые адреса блоков файла (см. рис 12.4). Запись в директории, относящаяся к файлу, содержит адрес индексного блока. По мере заполнения файла указатели на блоки диска в индексном узле принимают осмысленные значения. Индексирование поддерживает прямой доступ к файлу, без ущерба от внешней фрагментации. Индексированное размещение широко распространено и поддерживает как последовательный, так и прямой доступ к файлу. Обычно применяется комбинация одноуровневого и многоуровневых индексов. Первые несколько адресов блоков файла хранятся непосредственно в индексном узле, таким образом, для маленьких файлов индексный узел хранит всю необходимую информацию об адресах блоков диска. Для больших файлов один из адресов индексного узла указывает на блок косвенной адресации. Данный блок содержит адреса дополнительных блоков диска. Если этого недостаточно, используется блок двойной косвенной адресации, который содержит адреса блоков косвенной адресации. Если и этого не хватает, используется блок тройной косвенной адресации.
Данную схему используют файловые системы Unix (а также файловые системы HPFS, NTFS и др.). Такой подход позволяет при фиксированном, относительно небольшом размере индексного узла поддерживать работу с файлами, размер которых может меняться от нескольких байтов до нескольких гигабайтов. Существенно, что для маленьких файлов используется только прямая адресация, обеспечивающая максимальную производительность.
Рис. 3. Использование буферов для организации информационного взаимодействия внешнего и программного процессов
Для устранения задержек в ожидании наполнения буфера используется несколько буферов. Например, с точки зрения временных затрат для операции чтения рационально использовать два буфера (рис. 4). Пока один из них наполняется, другой в это время освобождается.
б)
Рис. 4. Поочередное использование двух буферов
Определение размера буфера требует компромисса между эффективным использованием оперативной памяти и внешних запоминающих устройств (ВЗУ) при обмене данными между ними. Каналу и ВЗУ более выгодны большие порции информации, которые можно пересылать за одну операцию ввода-вывода, реализуемую в канале, и хранить непрерывными участками на внешних носителях устройств. Чем длинней блок информации, тем дольше канал работает автономно от ЦП и тем реже его «тревожит». Длинные блоки выгоднее для ВЗУ, так как в этом случае уменьшается число межблочных промежутков и количество памяти для их фиксации. Что касается ОП, то здесь требования противоположны – чем меньше размер блока (равный размеру буфера), тем лучше, так как больше памяти достанется программным процессам. Не всегда выгодна наиболее быстрая передача данных из заполненного буфера внешнему процессу. Иногда такую передачу искусственно задерживают на достаточно продолжительные интервалы времени, формируя тем самым программный аналог кэш-памяти при работе с ВЗУ. Физическая запись на ВЗУ заполненных буферов осуществляется только тогда, когда возникает необходимость в свободном буфере, а его в текущий момент нет. Создаваемая таким образом задержка предполагает возможность обращения со стороны программных процессов к информации, временно хранимой в буфере. Если бы эта информация была «сброшена» на ВЗУ сразу после заполнения буфера, то обращение к ней потребовало бы обращения к устройству. Другая важная функция супервизора ввода-вывода состоит в том, что по отношению к программным процессам он выступает в роли распределителя ресурсов, которыми в данном случае являются периферийные устройства. В соответствии с этим он должен воспринимать и интерпретировать запросы от программных процессов на использование ПУ и обеспечивать реализацию определенной стратегии распределения ПУ. Как правило, в запросах на ввод-вывод указываются символические имена или номера устройств. Супервизор ввода-вывода производит сопоставление символических имен устройств с конкретными их адресами, вызов и подготовку к работе соответствующих системных программ для обслуживания канала (канальных программ). В данном случае он выступает как транслятор запросов на ввод-вывод. При возникновении одновременно нескольких запросов от различных программных процессов супервизор помещает их в очередь к каналу, связанному с данным устройством. При освобождении канала супервизор извлекает из очереди запрос в соответствии с принятым правилом обслуживания очереди, после чего инициируется работа канала по программе, определенной в запросе.
Особенности алгоритмов управления ресурсами От эффективности алгоритмов управления локальными ресурсами компьютера во многом зависит эффективность всей сетевой ОС в целом. Поэтому, характеризуя сетевую ОС, часто приводят важнейшие особенности реализации функций ОС по управлению процессорами, памятью, внешними устройствами автономного компьютера. Так, например, в зависимости от особенностей использованного алгоритма управления процессором, операционные системы делят на многозадачные и однозадачные, многопользовательские и однопользовательские, на системы, поддерживающие многонитевую обработку и не поддерживающие ее, на многопроцессорные и однопроцессорные системы. Поддержка многозадачности. По числу одновременно выполняемых задач операционные системы могут быть разделены на два класса:
Однозадачные ОС в основном выполняют функцию предоставления пользователю виртуальной машины, делая более простым и удобным процесс взаимодействия пользователя с компьютером. Однозадачные ОС включают средства управления периферийными устройствами, средства управления файлами, средства общения с пользователем. Многозадачные ОС, кроме вышеперечисленных функций, управляют разделением совместно используемых ресурсов, таких как процессор, оперативная память, файлы и внешние устройства. Поддержка многопользовательского режима. По числу одновременно работающих пользователей ОС делятся на:
Главным отличием многопользовательских систем от однопользовательских является наличие средств защиты информации каждого пользователя от несанкционированного доступа других пользователей. Следует заметить, что не всякая многозадачная система является многопользовательской, и не всякая однопользовательская ОС является однозадачной. Вытесняющая и невытесняющая многозадачность. Важнейшим разделяемым ресурсом является процессорное время. Способ распределения процессорного времени между несколькими одновременно существующими в системе процессами (или нитями) во многом определяет специфику ОС. Среди множества существующих вариантов реализации многозадачности можно выделить две группы алгоритмов:
Основным различием между вытесняющим и невытесняющим вариантами многозадачности является степень централизации механизма планирования процессов. В первом случае механизм планирования процессов целиком сосредоточен в операционной системе, а во втором - распределен между системой и прикладными программами. При невытесняющей многозадачности активный процесс выполняется до тех пор, пока он сам, по собственной инициативе, не отдаст управление операционной системе для того, чтобы та выбрала из очереди другой готовый к выполнению процесс. При вытесняющей многозадачности решение о переключении процессора с одного процесса на другой принимается операционной системой, а не самим активным процессом. Поддержка многонитевости. Важным с
|
|||||
|
|
Последнее изменение этой страницы: 2021-03-10; просмотров: 177; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.137 (0.017 с.) |

 а)
а)



