
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Г етероскедастичность ошибок
Пусть ошибки не коррелированы по наблюдениям, и матрица Ω (а вслед за ней и матрица D) диагональна. Если эта матрица единична, т.е. дисперсии ошибок
8.2. Гетероскедастичность ошибок 259 одинаковы по наблюдениям (гипотеза g 4 не нарушена), то имеет место гомос - ке д астичность или однородность ошибок по дисперсии — «штатная» ситуация. В противном случае констатируют гетероске д астичность ошибок или их неодно- родность по дисперсии.
одинаковы, а гетероскедастичность — что среди них есть несовпадающие. Факт неоднородности остатков по дисперсии мало сказывается на качестве оце- нок регрессии, если эти дисперсии не коррелированы с независимыми факторами. Это — случай гетероскедастичности «без негативных последствий».
Данное утверждение можно проиллюстрировать в случае, когда в матрице Z все- го один столбец, т.е. n = 1 и свободный член отсутствует. Тогда формула (7.33) приобретает вид: σ2 2 E (s 2) = 1 σ2 i zi
i − z 2 i i i
ду N − 1 σ2, и N s 2 оказывается несмещенной оценкой σ2 , как и было пока-
1
N можно утверждать, что σ2, i σ2 2 2 2 i z, i σ
i i z, i
i i т.е. ситуация остается прежней. И только если σ i и zi положительно (или отрица- тельно) коррелированы, факт гетероскедастичности имеет негативные последствия. σ2 2 Действительно, в случае положительной корреляции i z i
i > σ2 и, следова- тельно, E N 2
< σ2 . Обычная «несмещенная» оценка остаточной диспер- сии оказывается по математическому ожиданию меньше действительного значе-
ния остаточной дисперсии, т.е. она (оценка остаточной дисперсии) дает основания для неоправданно оптимистичных заключений о качестве полученной оценки модели.
Следует заметить, что факт зависимости дисперсий ошибок от независимых факторов в экономике весьма распространен. В экономике одинаковыми по диспер- сии скорее являются относительные (ε z), а не абсолютные (ε) ошибки. Поэтому, когда оценивается модель на основе данных по предприятиям, которые могут иметь
260 Глава 8. Нарушение гипотез основной линейной модели
и, как правило, имеют различные масштабы, гетероскедастичности с негативными последствиями просто не может не быть. Если имеет место гетероскедастичность, то, как правило, дисперсия ошибки связана с одной или несколькими переменными, в первую очередь — с факторами регрессии. Пусть, например, дисперсия может зависеть от некоторой перемен- ной y i , которая не является константой:
(y i), i = 1 ,..., N.
Как правило, в качестве переменной yi берется один из независимых факторов или математическое ожидание изучаемой переменной, т.е. x 0 = Z α (в качестве его оценки используют расчетные значения изучаемой переменной Za). В этой ситуации желательно решить две задачи: во-первых, определить, имеет ли место предполагаемая зависимость, а во-вторых, если зависимость обнаружена, получить оценки с ее учетом. При этом могут использоваться три группы методов. Методы первой группы позволяют работать с гетероскедастичностью, которая за- дается произвольной непрерывной функцией σ2(·). Для методов второй группы функция σ2(·) должна быть монотонной. В методах третьей группы функция σ2(·) предполагается известной с точностью до конечного числа параметров. Примером метода из первой группы является критерий Бартлетта, который заключается в следующем. Пусть модель оценена и найдены остатки e i, i = 1 ,..., N. Для расчета b c — статистики, лежащей в основе применения этого критерия, все множество наблю- дений делится по какому-либо принципу на k непересекающихся подмножеств. В частности, если требуется выявить, имеется ли зависимость от некоторой пе- ременной y i, то все наблюдения упорядочиваются по возрастанию y i, а затем в соответствии с этим порядком делятся на подмножества. Пусть
k N l — количество элементов в l -м подмножестве, s 2 N l = N; l =1 l — оценка дисперсии остатков в l -м подмножестве, найденная на основе остатков e i ; k
bs = N
l — отношение средней арифметической дисперсий к сред- . k
l .1/ N l =1 ней геометрической; это отношение в соответствии со свойством мажорантности средних (см. п. 2.2) больше или равно единице, и чем сильнее различаются диспер- сии по подмножествам, тем оно выше.
8.2. Гетероскедастичность ошибок 261
i
2
1 4
Y i
Рис. 8.1
Тогда стат и ст и ка Барт ле тта равна
k
11
ln b s.
3(k − 1)
При однородности наблюдений по дисперсии (нулевая гипотеза) эта статистика
k −1 . Проверка нулевой гипотезы проводится по обычному ал- горитму. Если нулевую гипотезу отвергнуть не удалось, т.е. ситуация гомоскедастична, то исходная оценка модели удовлетворительна. Если же нулевая гипотеза отверг- нута, то ситуация гетероскедастична. Принцип построения статистики Бартлетта иллюстрирует рисунок 8.1. Классический метод второй группы заключается в следующем. Все наблюдения упорядочиваются по возрастанию некоторой переменной y i. Затем оцениваются две вспомогательные регрессии: по K «малым» и по K «большим» наблюдениям (с целью повышения мощности критерия средние N − 2 K наблюдения в расчете не участвуют, а K можно, например, выбрать равным приблизительно трети N). Пусть s 2 — остаточная дисперсия в первой из этих регрессий, а s 2 — во второй. 1 2 В случае гомоскедастичности ошибок (нулевая гипотеза) отношение двух дисперсий распределено как
1
Здесь следует применять обычный F -критерий. Нулевая гипотеза о гомос- кедастичности принимается, если рассчитанная статистика превышает 95%-ный квантиль F -распределения.
262 Глава 8. Нарушение гипотез основной линейной модели
i
2
Y i
Рис. 8.2
Такой подход применяется, если ожидается, что дисперсия может быть только по- ложительно коррелирована с переменной yi . Если неизвестно, положительно или отрицательно коррелирована дисперсия с рассматриваемым фактором, то следу- ет отклонять нулевую гипотезу как при больших, так и при малых значениях ста-
1 . Можно применить следующий прием: рассчитать статистику как
и s 2 к минимальной. Такая статисти-
Данный метод известен под названием метода Голдфельда — К вандта.
s 2 2 2 2 считаются на основе остатков из проверяемой регрессии. При этом s 1 и s 2 не будут независимы, и их отношение будет иметь F -распределение только прибли- женно. Этот метод иллюстрирует рисунок 8.2. Для того чтобы можно было применять методы третьей группы, требуется обладать конкретной информацией о том, какой именно вид имеет гетероскеда- стичность.
Так, например, если остатки прямо пропорциональны значениям фактора (n = 1): x = z α + β + z ε, и ε удовлетворяет необходимым гипотезам, то делением обеих частей уравнения на z ситуация возвращается в «штатную»:
Z Z
8.2. Г е тероскедастичность ошибок 263
i
2
Yi
Рис. 8.3
в которой, правда, угловой коэффициент и свободный член меняются местами. Тем самым применяется преобразование в пространстве наблюдений такое, что диаго- нальные элементы матрицы D равны 1 z i .
Если зависимость дисперсии от других переменных известна не точно, а только с точностью до некоторых неизвестных параметров, то для проверки гомоскеда- стичности следует использовать вспомогательные регрессии. Так называемый метод Глейзера состоит в следующем. Строится регрессия модулей остатков | e i | на константу и те переменные, которые могут быть коррели- рованными с дисперсией (например, это может быть все множество независимых факторов или какое-то их подмножество). Если регрессия оказывается статисти- чески значимой, то гипотеза гомоскедастичности отвергается. Построение вспомогательной регрессии от некоторой переменной yi показано на рисунке 8.3.
Если с помощью какого-либо из перечисленных критериев (или других анало- гичных критериев) проверены различные варианты возможной зависимости и ну- левая гипотеза во всех случаях не была отвергнута, то делается вывод, что ситуа- ция гомоскедастична или гетероскедастична без негативных последствий и что для оценки параметров модели можно использовать обычный МНК. Если же нуле- вая гипотеза отвергнута и поэтому, возможно, имеет место гетероскедастичность с негативными последствиями, то желательно получить более точные оценки, учи- тывающие гетероскедастичность. Это можно сделать, используя для оценивания обобщенный МНК (см. уравне- ние (8.2)). Соответствующее преобразование в пространстве наблюдений состоит
264 Глава 8. Нарушение гипотез основной линейной модели
в том, чтобы каждое наблюдение умножить на d i , т.е. требуется оценить обычным методом наименьших квадратов преобразованную регрессию с переменными d i Xi и d i Z i. При этом не следует забывать, что если матрица факторов Z содержит свободный член, то его тоже нужно умножить на d i , поэтому вместо свободного члена в регрессии появится переменная вида (d 1 ,..., d N ). Это приводит к тому, что стандартные статистические пакеты выдают неверные значения коэффициен- та детерминации и F -статистики. Чтобы этого не происходило, требуется поль- зоваться специализированными процедурами для расчета взвешенной регрессии. Описанный метод получил название взвешенного МНК, поскольку он равнозначен N минимизации взвешенной суммы квадратов остатков d 2 e 2. i i i =1 Чтобы это можно было осуществить, необходимо каким-то образом получить оценку матрицы D, используемой для преобразования в пространстве наблюдений. Перечисленные в этом параграфе методы дают возможность не только проверить гипотезу об отсутствии гетероскедастичности, но и получить определенные оценки матрицы D (возможно, не очень хорошие). Если S 2 — оценка матрицы σ2Ω, где S 2 — диагональная матрица, состав- ленная из оценок дисперсий, то S −1 (матрица, обратная к ее квадратному кор- ню) — оценка матрицы σ D. Так, после проверки гомоскедастичности методом Глейзера в качестве диа- гональных элементов матрицы S −1 можно взять 1 c , где | e i | c — расчетные | e i |
матрицы S −1 можно взять 1 s l . В методе Голдфельда—Квандта требуется дополнительно получить оценку дис- персии для пропущенной средней части наблюдений. Эту оценку можно получить непосредственно по остаткам пропущенных налюдений или как среднее (s 2 + s 2) / 2. 1 2
Если точный вид гетероскедастичности неизвестен, и, как следствие, взвешенный МНК неприменим, то, по крайней мере, следует скорректировать оценку ковариа- ционной матрицы оценок параметров, оцененных обычным МНК, прежде чем про- верять гипотезы о значимости коэффициентов. (Хотя при использовании обычного МНК оценки будут менее точными, но как уже упоминалось, они будут несмещенны- ми и состоятельными.) Простейший метод коррекции состоит в замене неизвестной
ковариационной матрицы ошибок σ2Ω на ее оценку S 2 , где S 2 — диагональная
ной матрицы a (о це нка Уа й та или устойчивая к гетероскедастичности оценка): (Z r Z)−1 Z r S 2 Z (Z r Z)−1 .
8.3. Автокорреляция ошибок 265
Автокорреляция ошибок
Если матрица ковариаций ошибок не является диагональной, то говорят об ав- токорреляции ошибок. Обычно при этом предполагают, что наблюдения однород- ны по дисперсии, и их последовательность имеет определенный смысл и жестко фиксирована. Как правило, такая ситуация имеет место, если наблюдения про- водятся в последовательные моменты времени. В этом случае можно говорить о зависимостях ошибок по наблюдениям, отстоящим друг от друга на 1, 2, 3 и т.д. момента времени. Обычно рассматривается частный случай автокорреляции, когда коэффициенты ковариации ошибок зависят только от расстояния во времени меж- ду наблюдениями; тогда возникает матрица ковариаций, в которой все элементы каждой диагонали (не только главной) одинаковы1. Поскольку действие причин, обуславливающих возникновение ошибок, доста- точно устойчиво во времени, автокорреляции ошибок, как правило, положительны. Это ведет к тому, что значения остаточной дисперсии, полученные по стандартным («штатным») формулам, оказываются ниже их действительных значений. Что, как отмечалось и в предыдущем пункте, чревато ошибочными выводами о качестве получаемых моделей.
Это утверждение иллюстрируется рисунком 8.4 (n = 1). На этом рисунке: a — линия истинной регрессии. Если в первый момент времени истинная ошибка отрицательна, то в силу положительной автокорреляции ошибок все облако наблю- дений сместится вниз, и линия оцененной регрессии займет положение b. Если в первый момент времени истинная ошибка положительна, то по тем же причи- нам линия оцененной регрессии сместится вверх и займет положение c. Поскольку
1 В теории временных рядов это называется слабой стационарностью.
A b
Время
Рис. 8.4
266 Глава 8. Нарушение гипотез основной линейной модели
ошибки случайны и в первый момент времени они примерно с равной вероятно- стью могут оказаться положительными или отрицательными, то становится ясно, насколько увеличивается разброс оценок регрессии вокруг истинных по сравнению с ситуацией без (положительной) автокорреляции ошибок.
Типичный случай автокорреляции ошибок, рассматриваемый в классической эконометрии, — это линейная авторегрессия ошибок первого порядка AR(1):
ε i = ρε i −1 + η i, где η — остатки, удовлетворяющие обычным гипотезам; ρ — коэффициент авторегрессии первого порядка. Коэффициент ρ вляется также коэффициентом автокорреляции (первого по- рядка).
Действительно, по определению, коэффициент авторегрессии равен (как МНК- оценка): cov (ε i , ε i − 1) ρ = v ar (ε , i −1)
ρ, также по определению, является коэффициентом автокорреляции.
Если ρ = 0, то ε i = η i и получаем «штатную» ситуацию. Таким образом, проверку того, что автокорреляция отсутствует, можно проводить как проверку нулевой гипотезы H 0: ρ = 0 для процесса авторегрессии 1-го порядка в ошибках. Для проверки этой гипотезы можно использовать критерий Дарбина — Уотсона или DW - критерий. Проверяется нулевая гипотеза о том, что автокорре- ляция ошибок первого порядка отсутствует. (При автокорреляции второго и более высоких порядков его мощность может быть мала, и применение данного критерия становится ненадежным.) Пусть была оценена модель регрессии и найдены остатки e i, i = 1 ,..., N. Значение статистики Дарбина—Уотсона (отношения фон Неймана), или DW -ста- тистики, рассчитывается следующим образом:
N 2 (e i − e i −1)
N
i
. (8.3) i =1
Оно лежит в интервале от 0 до 4, в случае отсутствия автокорреляции ошибок приблизительно равно 2, при положительной автокорреляции смещается в мень-
8.3. Автокорреляция ошибок 267
D L d U
D U
4 D L
Рис. 8.5
шую сторону, при отрицательной — в большую сторону. Эти факты подтвержда- ются тем, что при больших N справедливо следующее соотношение: d c ≈ 2(1 − r) , (8.4) где r — оценка коэффициента авторегрессии.
Минимального значения величина d c достигает, если коэффициент авторегрессии равен +1. В этом случае ei = e, i = 1 ,..., N, и d c = 0. Если коэффициент авторегрессии равен −1 и ei = (−1) i e, i = 1 ,..., N, то величина d c достигает
N (можно достичь и более высокого значения подбором остатков), которое с ростом N стремится к 4. Формула (8.4) следует непосредственно из (8.3) после элементарных преобразований:
N N
N
i −1 d c = i =2 − 2 i =2 + i =2, N
i i =1 N
i i =1 N
i i =1 поскольку первое и третье слагаемые при больших N близки к единице, а второе слагаемое является оценкой коэффициента автокорреляции (умноженной на −2).
Известно распределение величины d, если ρ = 0 (это распределение близко к нормальному), но параметры этого распределения зависят не только от N и n, как для t - и F -статистик при нулевых гипотезах. Положение «колокола» функции плотности распределения этой величины зависит от характера Z. Тем не менее, Дарбин и Уотсон показали, что это положение имеет две крайние позиции (рис. 8.5). Поэтому существует по два значения для каждого (двустороннего) квантиля, соответствующего определенным N и n: его нижняя d L и верхняя d U границы. Нулевая гипотеза H 0: ρ = 0 принимается, если d U ™ d c ™ 4 − d U ; она отвергается в пользу гипотезы о положительной автокорреляции, если dc < d L , и в пользу
268 Глава 8. Нарушение гипотез основной линейной модели
гипотезы об отрицательной автокорреляции, если d c > 4 − d L . Если d L ™ d c < d U или 4− d U < d c ™ 4− d L , вопрос остается открытым (это — зона неопределенности DW -критерия). Пусть нулевая гипотеза отвергнута. Тогда необходимо дать оценку матрицы Ω. Оценка r параметра авторегрессии ρ может определяться из приближенного равенства, следующего из (8. 4):
или рассчитываться непосредственно из регрессии e на него самого со сдвигом на одно наблюдение с принятием «круговой» гипотезы, которая заключается в том, что e N +1 = e 1. Оценкой матрицы Ω является
··· r N −1 r 1 r ··· r N −2
r 1 ··· r
... ... ... ..
r N −1 r N −2 r N −3 ··· 1 а матрица D преобразований в пространстве наблюдений равна
√
... ..
0 0 0 ··· 1
Для преобразования в пространстве наблюдений, называемом в данном слу- чае авторегрессионным, используют обычно указанную матрицу без 1-й строки, что ведет к сокращению количества наблюдений на одно. В результате такого пре- образования из каждого наблюдения, начиная со 2-го, вычитается предыдущее, умноженное на r, теоретическими остатками становятся η, которые, по предпо- ложению, удовлетворяют гипотезе g 4.
8.3. Автокорреляция ошибок 269
После этого преобразования снова оцениваются параметры регрессии. Если новое значение DW -статистики неудовлетворительно, то можно провести следую- щее авторегрессионное преобразование. Обобщает процедуру последовательных авторегрессионных преобразований метод Кочрена — Оркатта, который заключается в следующем. Для одновременной оценки r, a и b используется критерий ОМНК (в обозна- чениях исходной формы уравнения регрессии): 1 N
→ min, N i =2 где z i — n -вектор-строка значений независимых факторов в i -м наблюдении (i -строка матрицы Z). Поскольку производные функционала по искомым величинам нелинейны от- носительно них, применяется итеративная процедура, на каждом шаге которой сначала оцениваются a и b при фиксированном значении r предыдущего шага (на первом шаге обычно r = 0), а затем — r при полученных значениях a и b. Процесс, как правило, сходится. Как и в случае гетероскедастичности, можно не использовать модифицированные методы оценивания (тем более, что точный вид автокорреляции может быть неиз- вестен), а использовать обычный МНК и скорректировать оценку ковариационной матрицы параметров. Наиболее часто используемая оценка Ньюи — Уэста (устой- чивая к гетероскедастичности и автокорреляции) имеет следующий вид: (Z r Z)−1 Q (Z r Z)−1 , где
N L N Q = e 2 + λ k e i e i k (z z r + zi k z r), i i =1
k =1 i = k +1 − i i − k − i а λ k — понижающие коэффициенты, которые Ньюи и Уэст предложили рассчи- k . При k > L понижающие коэффициенты
становятся равными нулю, т.е. более дальние корреляции не учитываются Обоснование этой оценки достаточно сложно2. Заметим только, что если заменить попарные произведения остатков соответствующими ковариациями и убрать пони- жающие коэффициенты, то получится формула ковариационной матрицы оценок МНК. Приведенная оценка зависит от выбора параметра отсечения L. В настоящее вре- мя не существует простых теоретически обоснованных методов для такого выбора. На практике можно ориентироваться на грубое правило L = .
2/9. .
2 Оно связано с оценкой спектральной плотности для многомерного временного ряда.
270 Глава 8. Нарушение гипотез основной линейной модели
Ошибки измерения факторов
Пусть теперь нарушается гипотеза g 2, и независимые факторы наблюдаются с ошибками. Предполагается, что изучаемая переменная зависит от истинных зна- чений факторов (далее в этом пункте используется сокращенная форма уравнения регрессии), z ˆ0, а именно:
x ˆ = z ˆ0α + ε, но истинные значения неизвестны, а вместо этого имеются наблюдения над неко- торыми связанными с z ˆ0 переменными z ˆ: z ˆ = z ˆ0 + ε z, где ε z — вектор-строка длиной n ошибок наблюдений. В разрезе наблюдений:
где X ˆ = Z ˆ0α + ε, Z ˆ = Z ˆ0 + ε z, Z ˆ0 и ε z — соответствующие N × n -матрицы значений этих величин по на- блюдениям (т.е., в зависимости от контекста, ε z обозначает вектор или матрицу ошибок). Предполагается, что ошибки факторов по математическому ожиданию равны нулю, истинные значения регрессоров и ошибки независимы друг от друга (по край- ней мере не коррелированы друг с другом) и известны матрицы ковариации:
E (ε z ) = 0 , E (z ˆ0t , ε) = 0, E (z ˆ0t , ε z ) = 0, E (z ˆ0t , z ˆ0) = M 0, E (εt , ε z ) = Ω, E (εt , ε) = ω.
(8.5) z z
Важно отметить, что эти матрицы и вектора ковариации одинаковы во всех наблюдениях, а ошибки в разных наблюдениях не зависят друг от друга, т.е. речь, фактически, идет о «матричной» гомоскедастичности и отсутствии автокорреляции ошибок. Через наблюдаемые переменные x ˆ в следующей форме: и z ˆ уравнение регрессии записывается
x ˆ = z ˆα + ε − ε z α . (8.6) В такой записи видно, что «новые» остатки не могут быть независимыми от факто- ров-регрессоров z ˆ, т.е. гипотезы основной модели регрессии нарушены. В рамках
т.е. МНК-оценки теряют в такой ситуации свойства состоятельности и несмещен- ности3, если ω ƒ= Ωα (в частности, когда ошибки регрессии и ошибки факторов не коррелированны, т.е. когда ω = 0, а Ω и α отличны от нуля).
Для обоснования (8. 7) перейдем к теоретическому аналогу системы нормальных уравнений, для чего обе части соотношения (8. 6) умножаются на транспонирован- ную матрицу факторов: E (z ˆr x ˆ) = E (z ˆr z ˆ) α + E (z ˆrε) − E (z ˆrε z ) α. Здесь, как несложно показать, пользуясь сделанными предположениями, E (z ˆr z ˆ) = M 0 + Ω, E (z ˆrε) = ω, E (z ˆrε z ) = Ω,
Поэтому
или
E (z ˆr x ˆ) = E (z ˆr z ˆ) α + ω − Ωα
E (z ˆr z ˆ)−1 E (z ˆr x ˆ) = α +. M 0 + Ω.−1 (ω − Ωα).
ационные матрицы M и m по закону больших чисел с ростом числа наблюдений сходятся по вероятности к своим теоретическим аналогам:
p p
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-01-08; просмотров: 99; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.14.249.90 (0.462 с.) |
 i .
i . e N
e N 
 N N − 1 e
N N − 1 e 1 N l s 2
1 N l s 2 l =1
l =1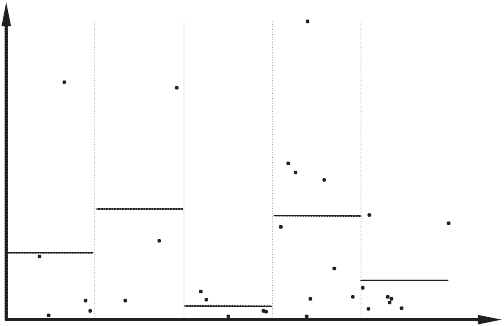
 bc = N
bc = N 1+ l =1 N l − N
1+ l =1 N l − N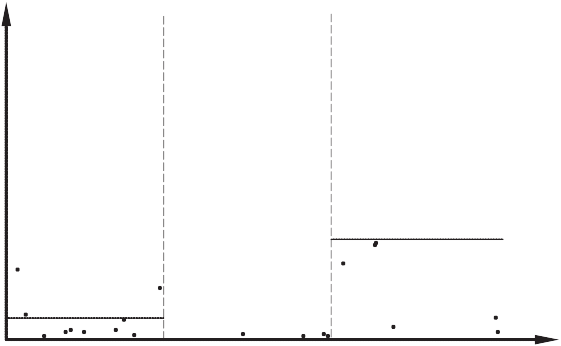








 x = α + 1 β + ε,
x = α + 1 β + ε,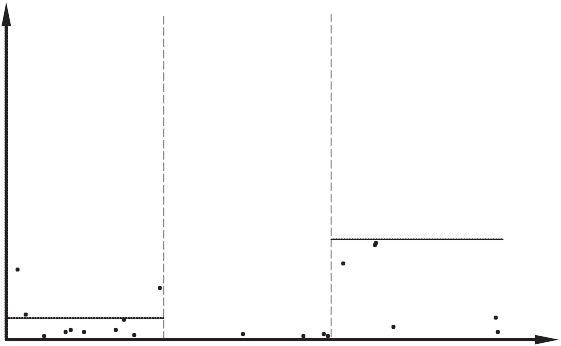

 x c
x c но, в силу гомоскедастичности, var (ε i −1) =, v ar (ε i) v ar (ε i −1) и, следовательно,
но, в силу гомоскедастичности, var (ε i −1) =, v ar (ε i) v ar (ε i −1) и, следовательно, d c = i =2
d c = i =2 0 2
0 2 d c r ≈ 1 − 2,
d c r ≈ 1 − 2, тывать по формуле λ k = 1 − L +1
тывать по формуле λ k = 1 − L +1 





