Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Корпоративные информационные системыСтр 1 из 7Следующая ⇒
Корпоративные информационные системы Методические указания к проведению лабораторных работ для студентов IV курса электромеханического факультета (направление 230200 «Информационные системы»)
Новосибирск 2011 ВВЕДЕНИЕ
Целью лабораторного практикума является закрепление знаний, получаемых студентами при изучении лекционного материала, а также приобретение практических навыков проектирования и разработки корпоративных информационных систем, выработка понимания сложности построения такого рода систем, умения использовать полученные знания при решении практических задач. Практикум состоит из 6 лабораторных работ, по окончании каждой лабораторной работы студентом оформляется отчет, а также проводится защита лабораторной работы. Л абораторная № 1 Тема: «Изучение основ XML»
Задание: Описать структуру реляционной БД, состоящую не менее чем из 3 таблиц, с помощью DTD. И создать XML–файл с заполненной БД. Ц ель: Изучить основы формата XML Теоретические основы: XML (англ. eXtensible Markup Language — расширяемый язык разметки; произносится [экс-эм-э́л]) — рекомендованный Консорциумом Всемирной паутины язык разметки, фактически представляющий собой свод общих синтаксических правил. XML — текстовый формат, предназначенный для хранения структурированных данных (взамен существующих файлов баз данных), для обмена информацией между программами, а также для создания на его основе более специализированных языков разметки (например, XHTML). XML является упрощённым подмножеством языка SGML. Стандартом определены два уровня правильности документа XML: Правильно построенный (англ. well-formed). Правильно построенный документ соответствует всем общим правилам синтаксиса XML, применимым к любому XML-документу. И если, например, начальный тег не имеет соответствующего ему конечного тега, то это неправильно построенный документ XML. Документ, который неправильно построен, не может считаться документом XML; XML-процессор (парсер) не должен обрабатывать его обычным образом и обязан классифицировать ситуацию как фатальная ошибка. Действительный (англ. valid). Действительный документ дополнительно соответствует некоторым семантическим правилам. Это более строгая дополнительная проверка корректности документа на соответствие заранее определённым, но уже внешним правилам, в целях минимизации количества ошибок, например, структуры и состава данного, конкретного документа или семейства документов. Эти правила могут быть разработаны как самим пользователем, так и сторонними разработчиками, например, разработчиками словарей или стандартов обмена данными. Обычно такие правила хранятся в специальных файлах — схемах, где самым подробным образом описана структура документа, все допустимые названия элементов, атрибутов и многое другое. И если документ, например, содержит не определённое заранее в схемах название элемента, то XML-документ считается недействительным; проверяющий XML-процессор (валидатор) при проверке на соответствие правилам и схемам обязан (по выбору пользователя) сообщить об ошибке.
XML (Extensible Markup Language) -- спецификация, определяющая базовый синтаксис XML; XSL (Extensible Style Language) -- спецификация, направленная на отделение визуального оформления страницы от ее содержимого за счет применения к документу стилей (style sheets), определяющих конкретные атрибуты форматирования; XLL (Extensible Linking Language) -- спецификация, определяющая представление ссылок на другие ресурсы. XML не только позволяет разработчикам создавать специализированные языки для Интернет-приложений; он также обеспечивает возможность проверки этих документов на соответствие спецификации XML. Более того, XML действительно реализует концепцию данных, не зависящих от реализации, поскольку формат отображаемого документа можно точно описать при помощи XSL. Допустим, вы переформатировали свой web-сайт, чтобы он хранился в формате XML. После этого вы сможете использовать один стиль для форматирования исходного текста XML на портативном компьютере типа Palm Pilot, а другой -- для форматирования на мониторе обычного компьютера. В обоих случаях код XML остается одним и тем же, изменяется только его форматирование в соответствии с используемым устройством. Примером популярного языка, созданного на базе XML, является WML (Wireless Markup Language). Синтаксис XML
Для большинства читателей, знакомых с SGML или HTML, структура документов XML не содержит ничего нового. Пример простого документа XML приведен в листинге 1.
Листинг 1. Пример документа XML <?xml version="1.0"?> <!DOCTYPE cookbook SYSTEM "cookbook.dtd"> <cookbook> <recipe category="italian"> <title>Spaghetti alla Carbonara</title> <description>This traditional Italian dish is sure to please even the most discriminating critic.</description> <ingredients> <ingredient>2 large eggs</ingredient> <ingredient>4 strips of bacon</ingredient> <ingredient>l clove garlic</ingredient> <ingredient>12 ounces spaghetti</ingredient> <ingredient>3 tablespoons olive oil</ingredient> </ingredients> <process> <step>Combine oil and bacon in large skillet over medium heat. Cook until bacon is brown and crisp.</step> <step>whisk eggs in bowl. Set aside.</step> <step>Cook pasta in large pot of boiling water to taste, stirring occasionally. Add salt as necessary.</step> <step>Drain pasta and return to pot. adding whisked eggs. Stir over medium-low heat for 2-3 minutes.</step> <step>Mix in bacon. Season with salt and pepper to taste.</step> </process> </recipe> </cookbook>
Обратите внимание на основные компоненты, из которых состоит документ XML: · пролог XML; · теги; · атрибуты; · ссылки на сущности; · инструкции по обработке; · комментарии. Пролог XML Все документы XML начинаются с пролога (prolog). Пролог сообщает, что документ написан на XML, а также указывает, какая версия XML при этом использовалась. Поскольку текущая версия XML имеет номер 1.0, все ваши документы XML должны начинаться со строки <?xml version="1.0"> Следующая строка в листинге 1 указывает на внешний DTD. Пока не обращайте на нее внимания -- DTD подробно рассматриваются в следующем разделе «Определение типа документа (DTD)»: <!DOCTYPE cookbook SYSTEM "cookbook.dtd"> Оставшаяся часть листинга 1 состоит из элементов, очень похожих на элементы документов HTML. Первый элемент, cookbook, называется корневым элементом (root element), поскольку в эту пару тегов заключены все остальные теги документа. Конечно, вы можете присвоить корневому элементу любое имя по своему усмотрению. Главное, о чем следует помнить, -- все остальные элементы должны находиться внутри пары корневых тегов. Пролог может содержать другие инструкции. Например, объявление можно расширить, указав, что документ является автономным: <?xml version="1.0" standalone="yes"> Присваивание yes атрибуту standalone сообщает механизму обработки XML-кода о том, что документ не импортирует других файлов (например, DTD). Элементы Оставшаяся часть документа состоит в основном из различных служебных элементов и соответствующих данных. Служебные элементы легко узнать по угловым скобкам (как в разметке HTML). Элемент может быть пустым или содержащим информацию; в этом случае элемент содержит открывающий и закрывающий теги. Если элемент не пуст, то в теги включаются имена, описывающие природу данных. Как видно из листинга 1, эти теги очень похожи на теги документов HTML. Впрочем, следует помнить о некоторых важных различиях: Непустые элементы должны содержать как открывающий, так и закрывающий тег. В элементах, которые логически не могут иметь закрывающего тега, используется альтернативная форма синтаксиса <элемент />. Возникает вопрос -- у каких элементов нет закрывающего тега? Достаточно вспомнить некоторые теги форматирования HTML -- например, <br>, <hr> и <img>, у них нет парных тегов. Теги этого формата могут создаваться и в документах XML Элементы XML должны находиться на правильном уровне вложенности. Документ XML, приведенный в листинге 1, синтаксически правилен; другими словами, теги элементов не встречаются там, где их быть не должно. Например, следующий фрагмент недопустим:
< title > Spaghetti alla Carbonara < ingredients ></ title > В элементах XML различается регистр символов. Некоторым читателям это наверняка не понравится. Например, в XML теги <tag>, <Tag> и <TAG> считаются разными тегами. Привыкайте поскорее -- с непривычки это может свести вас с ума. Атрибуты Теги XML, по аналогии с тегами HTML, могут обладать атрибутами. Атрибуты содержат дополнительную информацию о содержании, которая в дальнейшем используется при форматировании или обработке XML. Значения атрибутов присваиваются в формате «имя=значение», и, в отличие от HTML, атрибуты XML должны быть заключены в апострофы или кавычки. В листинге 1 встречается пример использования атрибута: <recipe category="italian"> Атрибут сообщает, что данный рецепт (recipe) относится к категории «итальянской кухни» (italian). Наличие такой информации упрощает дальнейшую группировку и обработку данных. Ссылки на сущности Концепция сущности (entity) упрощает сопровождение документа, обеспечивая возможность ссылки на некоторое содержание по ключевым словам. Ключевое слово может относиться как к простейшему фрагменту вроде расширения аббревиатуры, так и к совершенно новому фрагменту кода XML. Сущности удобны тем, что они могут многократно использоваться в документах XML. При последующей обработке документа все ссылки на сущность заменяются конкретным содержанием, указанным при объявлении сущности. Объявление сущности включается в DTD документа XML. Чтобы сослаться на некоторую сущность в документе HTML, следует указать ее имя с префиксом «амперсанд» (&) и суффиксом «точка с запятой» (;). Допустим, вы объявили сущность с информацией об авторских правах. После этого на данную сущность можно ссылаться следующим образом: &Соруright; При этом строка документа XML может выглядеть так: <footer> ...прочие данные колонтитула... &Copyright; </footer> Сущности, как и переменные и шаблоны, часто применяются в ситуациях, когда некоторая информация может измениться в будущем или документ содержит множество повторяющихся ссылок. Мы вернемся к проблемам объявления ссылок в разделе «Определение типа документа (DTD)». Инструкции по обработке Инструкции по обработке (processing instructions, PI) представляют собой внешние команды, которые выполняются приложением, работающим с документом XML.
В общем случае синтаксис PI выглядит так: <?приложение инструкции?> Атрибут приложение указывает, какой программе адресованы последующие инструкции. Например, для выполнения команды PHP в документе XML можно воспользоваться следующей конструкцией: <?php print "Today's date is:".date("m-d-Y");?> Инструкции по обработке удобны тем, что они позволяют нескольким приложениям совместно работать с одним документом. Комментарии Комментарии принадлежат к числу основных возможностей любого языка. В XML используется тот же синтаксис комментариев, что и в HTML: <!- комментарии -> Итак, мы проанализировали структуру типичного документа XML. Но у документов XML существует еще один важный аспект -- определение типа документа (DTD). Определение типа документа (DTD) DTD представляет собой совокупность синтаксических правил, на основе которых проверяется структура документа XML. В DTD явно определяется структура документа XML, указываются элементы и их атрибуты, а также приводится другая информация, распространяющаяся на все документы XML, созданные на основе данного DTD. Учтите, что наличие DTD не является обязательным. Если DTD существует, система XML руководствуется им при интерпретации документа XML. Если DTD отсутствует, предполагается, что система XML должна интерпретировать документ по собственным правилам. Впрочем, для документов XML все же рекомендуется создавать DTD, поскольку это упрощает их интерпретацию и проверку структуры. DTD можно включить непосредственно в документ XML, сослаться на него по URL или использовать комбинацию этих двух способов. При непосредственном включении DTD в документ XML определение DTD располагается сразу же после пролога: <!DOCTYPE имя_корневого_элемента [ ... прочие объявления... ] > Атрибут имя_корневого_элемента соответствует имени корневого элемента в тегах, содержащих весь документ XML. В секции «прочих объявлений» находятся определения элементов, атрибутов и т. д. Возможно, вы предпочитаете разместить DTD в отдельном файле, чтобы обеспечить модульную структуру программы. Давайте посмотрим, как выглядит ссылка на внешний DTD в документе XML. Задача решается одной простой командой: <!DOCTYPE имя_корневого_элемента SYSTEM "some_dtd.dtd"> Как и в случае с внутренним объявлением DTD, имя_корневого_элемента должно соответствовать имени корневого элемента в тегах, содержащих весь документ XML. Атрибут SYSTEM указывает на то, что some_dtd.dtd находится на локальном сервере. Впрочем, на файл some_dtd.dtd также можно сослаться по его абсолютному URL. Наконец, в кавычках указывается URL внешнего DTD, расположенного на локальном или на удаленном сервере. Как же создать DTD для листинга 1? Во-первых, мы собираемся создать в документе XML ссылку на внешний DTD. Как упоминалось в предыдущем разделе, ссылка на DTD выглядит так: <!DOCTYPE cookbook SYSTEM "cookbook.dtd"> Возвращаясь к листингу 1, мы видим, что cookbook является именем корневого элемента, a cookbook.dtd -- именем DTD-файла. Содержимое DTD показано в листинге 2, а ниже приведены подробные описания всех строк.
Листинг 2. DTD для листинга 1 (cookbook.dtd) <?xml version="1.0"?> <!DOCTYPE cookbook [ <!ELEMENT cookbook (recipe+)> <!ELEMENT recipe (title, description, ingredients, process)> <!ELEMENT title (#PCDATA)> <!ELEMENT description (#PCDATA)> <!ELEMENT ingredients (ingredient+)> <!ELEMENT ingredient (#PCDATA)> <!ELEMENT process Cstep+)> <!ELEMENT step (#PCDATA)> <!ATTLIST recipe category CDATA #REQUIRED> ] > Что же означает этот документ? Несмотря на внешнюю сложность, в действительности он довольно прост. Давайте переберем все содержимое листинга 2: <?xml version="1.0"?> Перед нами пролог XML, о котором уже говорилось выше. <!DOCTYPE cookbook [ Вторая строка сообщает, что далее следует DTD с именем cookbook. <!ELEMENT cookbook (recipe+)> Третья строка описывает элемент XML, в данном случае -- корневой элемент cookbook. После него следует слово recipe, заключенное в круглые скобки. Это означает, что в теги cookbook заключается вложенный тег с именем recipe. Знак + говорит о том, что в родительских тегах cookbook находится одна или несколько пар тегов recipe. <!ELEMENT recipe (title, description, ingredients. process)> Четвертая строка описывает тег recipe. В ней сообщается, что в тег recipe входят четыре вложенных тега: title, description, ingredients и process. Поскольку после имен тегов не указываются признаки повторения, внутри тегов recipe должна быть заключена ровно одна пара каждого из перечисленных тегов. <! ELEMENT title (#PCDATA)> Перед нами первое определение тега, который не содержит вложенных тегов. В соответствии с определением он содержит #PCDATA, то есть произвольные символьные данные, не считающиеся частью разметки. <!ELEMENT ingredients (ingredient+)> В соответствии с определением элемент ingredients содержит один или несколько тегов с именем ingredient. Обратитесь к листингу 1, и вы все поймете. <! ELEMENT ingredient (#PCDATA)> Поскольку элемент ingredient соответствует отдельному ингредиенту, вполне логично, что этот элемент содержит простые символьные данные. <! ELEMENT process (step+)> Элемент process содержит один или несколько экземпляров элемента step. <! ELEMENT step (#PCDATA)> Элемент step, как и элемент ingredient, соответствует отдельному пункту в списке более высокого уровня. Следовательно, он должен содержать символьные данные. <! ATTLIST recipe category CDATA # REQUIRED > Обратите внимание: элемент recipe в листинге 1 содержит атрибут. Этот атрибут, category, определяет общую категорию, к которой относится рецепт -- в приведенном примере это категория «итальянская кухня» (Italian). В определении ATTLIST указывается как имя элемента, так и имя атрибута. Кроме того, отнесение каждого рецепта к определенной категории упрощает классификацию, поэтому атрибут объявляется обязательным (#REQUIRED). ]> Последняя строка просто завершает определение DTD. Определение всегда должно быть должным образом завершено, иначе произойдет ошибка. В завершение этого раздела приведем сводку основных компонентов типичного DTD-файла: · объявления типов элементов; · объявления атрибутов; · ID, IDREF и IDREFS; · объявления сущностей. Некоторые из этих компонентов уже встречались нам в описании листинга 14.2. Далее каждый компонент будет описан более подробно. Объявления элементов Все элементы, используемые в документе XML, должны быть определены в DTD, прилагаемом к документу. Мы уже встречались с двумя распространенными разновидностями определений: для элемента, содержащего другие элементы, и элемента, содержащего символьные данные. Данное определение свидетельствует, что элемент содержит только символьные данные: <! ELEMENT описание (#РСDАТА)> Следующее определение элемента process говорит о том, что он содержит ровно один вложенный элемент с именем step: <!ELEMENT process (step)> Впрочем, процессы (process) из одного шага (step) встречаются довольно редко -- скорее всего, шагов будет несколько. Чтобы указать, что элемент содержит один или несколько экземпляров вложенного элемента step, следует воспользоваться признаком повторения: <!ELEMENT process (step+)> Количество вложенных элементов можно задать несколькими способами. Полный список операторов элементов приведен в таблице 1.
Таблица 1. Операторы элементов
Если элемент будет содержать несколько вложенных элементов, их следует перечислить через запятую в определении родительского элемента: <!ELEMENT recipe (title, description, ingredients, process)> Поскольку признаки повторения не указаны, каждый тег должен встречаться ровно один раз. Определение элемента уточняется при помощи логических операторов. Предположим, вы работаете с рецептами, в которые всегда входят макароны (pasta) с одним или несколькими типами сыра (cheese) или мяса (meat). В этом случае элемент ingredient определяется следующим образом: <! ELEMENT ingredient (pasta +, (cheese | meat)+)> Поскольку элемент pasta обязательно должен присутствовать в элементе ingredient, он указывается с признаком повторения +. Затем следует либо элемент cheese, либо элемент meat; мы разделяем альтернативы вертикальной чертой и заключаем их в круглые скобки со знаком +, поскольку в рецепт всегда входит либо одно, либо другое. Существуют и другие разновидности определений элементов. Мы рассмотрели лишь простейшие случаи. Тем не менее, приведенного материала вполне достаточно для понимания примеров, приведенных в оставшейся части этой главы. Объявления атрибутов Атрибуты элементов описывают значения, связываемые с элементами. Элементы XML, как и элементы HTML, могут иметь ноль, один или несколько атрибутов. Общий синтаксис объявления атрибутов выглядит следующим образом: <!ATTLIST имя_элемента имя_атри6ута1 тип_данных1 флаг1> Имя_элемента определяет имя элемента, включаемое в тег. Затем перечисляются атрибуты, связанные с данным элементом. Объявление каждого атрибута состоит из трех основных компонентов: имени, типа данных и флага, определяющего особенности данного атрибута. Вместо многоточия (...) могут быть расположены объявления других атрибутов. Простое объявление атрибута уже встречалось нам в листинге 2: <!ATTLIST recipe category CDATA #REQUIRED> Тем не менее, как видно из приведенного общего определения, допускается одновременное объявление нескольких атрибутов. Допустим, в дополнение к атрибуту category вы хотите связать с элементом recipe дополнительный атрибут difficulty (сложность приготовления). Оба атрибута объявляются в одном списке: <!ATTLIST recipe category CDATA #REQUIRED difficulty CDATA #REQUIRED> Форматировать объявления подобным образом необязательно; тем не менее, многострочные объявления нагляднее однострочных. Кроме того, поскольку оба атрибута являются обязательными, тег reciре не может ограничиться каким-нибудь одним атрибутом, он должен включать в себя оба атрибута сразу. Например, следующий тег будет считаться неверным: <recipe difficulty="hard"> Почему? Потому что в нем отсутствует атрибут category. Правильный тег должен содержать оба атрибута: <recipe category="Italian" difficulty="hard"> Особые условия обработки атрибута описываются тремя флагами, перечисленными в таблице 2.
Таблица 2. Флаги атрибутов
Перечисляемые атрибуты При объявлении атрибута можно перечислить все допустимые значения, принимаемые атрибутом. В нашем примере это было бы удобно, поскольку вы можете сразу определить список допустимых категорий. Приведенное выше объявление записывается в следующем виде: <! ATTLIST recipe category (Italian | French | Japanese | Chinese) # REQUIRED difficulty (easy | medium | hard) # REQUIRED) Обратите внимание: при использовании списков допустимых значений включать в объявление тип CDATA не нужно, поскольку все перечисленные значения относятся к формату CDATA. Типы атрибутов Атрибут элемента может объявляться с определенным типом, перечисленными в табл. 3.
Таблица 3. Типы атрибутов
Типы атрибутов описаны далее. Атрибуты CDATA Очень часто атрибуты содержат общие символьные данные. Такие атрибуты называются атрибутами CDATA. Следующий пример уже встречался в начале этого раздела: <! ATTLIST recipe category CDATA # REQUIRED > Атрибуты ID, IDREF и IDREFS Идея однозначного представления данных (например, информации о пользователе или товаре, хранящейся в базе данных) посредством идентификаторов неоднократно встречалась в предыдущих главах книги. Идентификаторы также часто используются в XML, поскольку перекрестные ссылки между документами применяются не только в общих задачах обработки данных, но и в World Wide Web (гиперссылки). Идентификаторы элементов присваиваются атрибуту ID. Допустим, вы хотите связать с каждым рецептом уникальный идентификатор. Соответствующий фрагмент DTD может выглядеть так: <!ELEMENT recipe (title, description, ingredients, process)> <!ATTLIST recipe recipe-id ID #REQUIRED> <!ELEMENT recipe-ref EMPTY> <!ATTLIST recipe-ref go IDREF #REQUIRED> После этого объявление элемента recipe в документе может выглядеть так: <recipe recipe-id="ital003"> <title>Spaghetti alla Carbonara</title> Рецепт однозначно определяется идентификатором ital003. Следует помнить, что атрибут redpe-id относится к типу ID, поэтому ital003 не может использоваться в качестве значения атрибута recipe-id другого элемента, в противном случае документ будет считаться синтаксически неверным. Теперь допустим, что позднее вы захотели сослаться на этот рецепт из другого документа -- скажем, из списка любимых рецептов пользователя. Именно здесь в игру вступают перекрестные ссылки и атрибут IDREF. Атрибуту IDREF присваивается идентификатор, используемый для ссылок на элемент, -- по аналогии с тем, как URL используется для идентификации страницы в гиперссылке. Рассмотрим следующий фрагмент кода XML: <favoriteRecipes> <recipe-ref go="ital003"> </favoriteRecipes> В процессе обработки документа XML элемент заменяется более наглядной ссылкой на рецепт с указанным идентификатором (например, названием рецепта). Вероятно, он будет отформатирован в виде гиперссылки, чтобы упростить переход к указанному рецепту. Атрибуты ENTITY и ENTITIES Данные в документах XML не всегда являются текстовыми -- документ может содержать и двоичную информацию (например, графику). На такие данные можно ссылаться при помощи атрибута entity. Например, в описании элемента description можно указать атрибут recipePicture с графическим изображением: <!ATTLIST description recipePicture ENTITY #IMPLIED> Также можно объявить сразу несколько сущностей, заменив ENTITY на ENTITIES. Значения разделяются пробелами. Атрибуты NMTOKEN и NMTOKENS Атрибуты NMTOKEN представляют собой строки из символов, входящих в ограниченный набор. Объявление атрибута с типом NMTOKEN предполагает, что значение атрибута соответствует установленным ограничениям. Как правило, значение атрибута NMTOKEN состоит из одного слова: <! ATTLIST recipe category NMTOKEN # REQUIRED > Можно объявить сразу несколько атрибутов, заменив NMTOKEN на NMTOKENS. Значения разделяются пробелами. Объявления сущностей Объявление сущности напоминает команду define в некоторых языках программирования, включая PHP. Ссылки на сущности кратко упоминались в предыдущем разделе «Знакомство с синтаксисом XML». На всякий случай напомню, что ссылка на сущность используется в качестве замены для другого фрагмента содержания. В процессе обработки документа XML все вхождения сущности заменяются содержанием, которое она представляет. Существует два вида сущностей: внутренние и внешние. Внутренние сущности Внутренние сущности напоминают строковые переменные, связывающие имя с фрагментом текста. Например, если вы хотите определить имя для ссылки на информацию об авторских правах, можно объявить сущность следующего вида: <!ENTITY Copyright "Copyright 2000 YourCompanyName. All Rights Reserved."> В процессе обработки документа все экземпляры &Соруright заменяются текстом «Copyright 2000 YourCompanyName. All Rights Reserved». Весь код XML в заменяющем тексте обрабатывается так, словно он присутствовал в исходном документе. Внутренние сущности удобны в ситуациях, когда вы планируете использовать сущность в относительно небольшом количестве документов XML. При большом количестве документов лучше воспользоваться внешними сущностями. Внешние сущности Внешние сущности используются для ссылок на содержание, находящееся в другом файле. Сущности этого типа могут содержать текстовую информацию, но также могут ссылаться и на двоичные данные (например, графику). Возвращаясь к предыдущему примеру, допустим, что вы решили сохранить информацию об авторских правах в отдельном файле, чтобы упростить ее редактирование в будущем. Ссылка на созданный файл выглядит следующим образом: <! ENTITY Copyright SYSTEM " http:// yoursite. com / administer / copyright. xml "> При последующей обработке документа XML все ссылки &Соруright заменяются содержимым документа copyright.xml. Весь код XML в заменяющем тексте обрабатывается так, словно он присутствовал в исходном документе. Внешние сущности также удобно использовать для ссылок на графические изображения. Например, если вы хотите включить в документ XML графический логотип, создайте внешнюю сущность: <!ENTITY food_picture SYSTEM http://yoursite.com/food/logo.gif> Как и в предыдущем примере, все ссылки &food_picture заменяются графическим изображением, на которое указывает ссылка. Поскольку данные являются двоичными, а не текстовыми, они не интерпретируются. Задание на лабораторную работу: 1. Изучить требования для создания корректного документа 2. Выучить виды XML–документов 3. Выучить назначение и структуру DTD 4. Изучить область применения DTD 5. Научиться использовать DTD 6. Изучить виды сущностей DTD и научиться применять их
Ст руктура отчёта: 1. Титульный 2. Содержание 3. Описание целей и задача 4. Описание системы 5. Структура нормализованной БД (IDEF1x) 6. XML и DTD файлы
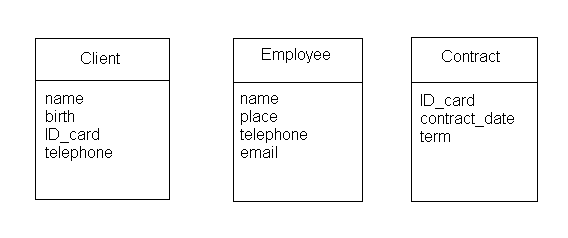
Пример лабораторной работы №1: Тема: В качестве примера в данном методическом указании будет рассмотрена КИС для Фитнес центра. XML файл: Описание: Создаем три таблицы: client(клиенты), employee(сотрудники) и contract(контракт) (см. рисунок 1) и описываем их с помощью XML.
Рис. 1. Структура БД
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE fitness SYSTEM "fit.dtd"> <list1> <client> <name>Ivan Vasil'evich Gagarin</name> <birth>25.01.1980</birth> <IDcard>011777</IDcard> <telephone>8913123213</telephone> </client> <client> <name>Pavel Sergeevich Kvasha</name> <birth>13.08.1991</birth> <IDcard>011888</IDcard> <telephone>8913523814</telephone> </client> </list1> <list2> <employee> <name>Gennadiy Vital'evich Kotov</name> <position>administrator</position> <telephone>89321312616</telephone> <email>devilcat666@mail.ru</email> </employee> <employee> <name>Alisa Dmitreevna Orehova</name> <position>administrator</position> <telephone>89609257643</telephone> <email>orehova7643@mail.ru</email> </employee> </list2> <list3> <contract> <IDcard>011777</IDcard> <contract_date>01.09.2012</contract_date> <term>30 days</term> </contract> <contract> <IDcard>011888</IDcard> <contract_date>24.11.2012</contract_date> <term>90 days</term> </contract> </list3> </ fitness > DTD файл: Описание: посредством набора объявлений описываем схему документа для XML, его класс с точки зрения синтаксических ограничений и объявляем конструкцию. <!DOCTYPE fitness [ <!ELEMENT fitness(list1, list2, list3)> <!ELEMENT list1(client+)> <!ELEMENT client(name, birth, IDcard, telephone) <!ELEMENT name(#PCDATA)> <!ELEMENT birth (#PCDATA)> <!ELEMENT IDcard(#PCDATA)> <!ELEMENT telephone(#PCDATA)> <!ATTLIST client id_cl ID #REQUIRED> <!ELEMENT list2(employee+)> <!ELEMENT employee(name, place,telephone, email)> <!ELEMENT name (#PCDATA)> <!ELEMENT position(#PCDATA)> <!ELEMENT telephone (#PCDATA)> <!ELEMENT email (#PCDATA)> <!ATTLIST employee id-emp ID #REQUIRED> <!ELEMENT list3(contract+)> <!ELEMENT contract(IDcard, contract_date, term)> <!ELEMENT IDcard(#PCDATA)> <!ELEMENT contract_date(#PCDATA)> <!ELEMENT term(#PCDATA)> <!ATTLIST contract id-contr ID #REQUIRED> ]> Л абораторная № 2
Т ема: «Изучение XML схем» Задание: Описать структуру реляционной БД, состоящую не менее чем из 3 таблиц, с помощью XML Schema. И создать XML–файл с заполненной БД. Цель: Изучить основы формата XML Schema Теоретические основы: Введение в XML Schema XML Schema – это основанная на XML альтернатива DTD. Она предназначена для описания структуры XML документа. XML Schema предназначена, подобно DTD, для определения строительных блоков XML документа. Она определяет: · представленные в документе элементы; · атрибуты, которые могут встречаться в документе; · какие элементы являются дочерними; · последовательность, в которой дочерние элементы представляются; · количество дочерних элементов; · являются ли документы пустыми или могут включать текст; · типы данных для элементов и атрибутов; · значение по умолчанию для элементов и атрибутов. Ограничение вхождений Значение параметра minOccurs равное 0 у элемента comment говорит о том, что он не обязательно будет присутствовать в составе элемента PurchaseOrderType. Вообще, элемент является обязательным, если значение minOccurs больше или равно 1. Максимальное число появлений элемента определяется значением, задаваемым параметром maxOccurs. Это значение может быть положительным целым числом типа 41, или термом unbounded, что означает отсутствие ограничения максимального числа появлений. Значение по умолчанию для minOccurs и для maxOccurs равно 1. Таким образом, когда элемент типа comment объявлен без maxOccurs, то это означает, что элемент может появиться не более одного раза. Если Вы определяете значение только для minOccurs, то убедитесь что это значение меньше или равно значению по умолчанию maxOccurs. То есть это значение должно быть 0 или 1. Точно так же, если Вы определяете значение только для maxOccurs, то это значение должно быть больше или равно значению по умолчанию minOccurs, то есть 1 или больше. Если оба значения опущены, элемент должен появиться в документе точно один раз. Атрибуты, в отличие от элементов, могут появиться только однажды или ни разу. Поэтому и синтаксис для определения появления атрибутов отличается от синтаксиса для определения числа появлений элементов. В частности атрибуты могут быть объявлены с параметром use. В зависимости от значения этого параметра атрибут обязателен (use="required"), необязателен (use="optional"), или запрещен (use="prohibited"). Например, объявление атрибута partNum в po.xsd. Значения по умолчанию и атрибутов и элементов могут быть объявлены с использованием параметра default, хотя этот параметр в том или ином случае работает по разному. Атрибут со значением, определенным по умолчанию, может появляться или не появляться в документе. Если атрибут не появляется в документе, то обработчик схемы обеспечивает, атрибут со значением равным значению default. Обратите внимание, что значения по умолчанию для атрибутов имеют смысл, только если сами атрибуты являются необязательными, поэтому будет ошибкой определить значение по умолчанию вместе с параметром use отличным от use="optional". Значение по умолчанию для элементов обрабатывается немного по-другому. Если элемент появляется в документе, но не содержит какого либо значения, то в качестве его значения подставляется значение по умолчанию. Однако если элемент не появляется в документе, то обработчик схемы не обеспечивает его значения вообще. В общем, различия между значениями по умолчанию элемента и атрибута в следующем: заданное по умолчанию значение атрибута применяется тогда, когда атрибут отсутствует, а заданное по умолчанию значение элемента применяются тогда, когда элемент присутствует в документе, но не имеет значения (пуст).
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-01-14; просмотров: 96; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.17.162.250 (0.277 с.) |