Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Паралельне програмування за технологією MPI . Процедури колективного обміну за схемою “усі-з усіма” без блокування.Содержание книги
Поиск на нашем сайте
Організація неблокуючих обмінів даних між процесами. Всі раніше розглянуті функції відправки і прийому повідомлень - блокуючі, тобто такими, що призупиняють виконання процесів до моменту завершення роботи викликаних функцій. В той же час при виконанні паралельних обчислень частина повідомлень може бути відправлена і прийнята завчасно, до моменту реальної потреби в даних, що пересилаються. В таких ситуаціях небажано мати можливість виконання функцій обміну даними без блокування процесів для суміщення процесів передачі повідомлень та обчислень. Такий неблокуючий спосіб виконання обмінів є складнішим для використання, але за правильного застосування може в значній мірі зменшити втрати ефективності паралельних обчислень внаслідок повільних (порівняно з швидкодією процесорів) комунікаційних операцій. МРІ забезпечує можливість неблокованого виконання операцій передачі даних між двома процесами. Найменування неблокуючих аналогів утворюється з назв відповідних функцій шляхом добавлення префікса І (Immediate). Список параметрів неблокуючих функцій містить звичайний набір параметрів вихідних функцій і один додатковий параметр request з типом MPI_Request (в функції MPI_Irecv відсутній також параметр status): int MPI_Isend(void *buf. int count, MPI_batatype type, int dest int tag, MPI_Comm comm, MPI_Request *request), int MPI_Inssent(void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request *request), int MPI_Ibsennd(void *buf, int count, MPI_Dftftipe tupe, int dest, int tag, MPI_Comm comm, MPI_Request *request), Int MPI_Irsend(void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm, MPI_Request *request), Int MPI_Irsend(void *buf, int count, MPI_Datatype type, int sourse, int tag, MPI_Comm comm, MPI_Request *request). Виклик неблокуючої функції приводить до ініціації запрошеної операції передачі, після чого виконання функції завершається і процес може продовжувати свої дії. Перед завершенням неблокуюча функція визначає змінну request, яка далі може використовуватися для перевірки завершення ініційованої операції обміну. Перевірка стану виконуваної неблокуючої операції передачі даних здійснюється з використанням функції: int MPI_Test(MPI_Request *request, int *flaq, MPI_status *status), де - request - дескриптор операції, визначений при визові неблокуючої функції; - flaq - результат перевірки (true, якщо операція завершена);
- status - результат виконання операції обміну (тільки для завершеної операції). Операція перевірки є неблокуючою, тобто процес може перевірити стан неблокуючої операції обміну і продовжити далі свої обчислення, якщо за результатами перевірки виявиться,що операція все ще не завершена. Можлива схема суміщення обчислень і виконання неблокуючої операції обміну може полягати в наступному: MPI_Isend(buf, count, type, dest, taq, comm, &request); ... do { ... MPI_Test(&request, &flaq, &status); } while (! flaq); Якщо за умови виконання неблокуючої операції виявиться, що продовження обчислень неможливе без отримання даних, що передаються, то може бути використана блокуюча операція очікування завершення операції: int MPI_Wait(MPI_Request *request, MPI_Status *status), де - request - дескриптор операції, визначений при виклику неблокуючої функції; - status - результат виконання операції обміну (тільки для завершеної операції). - Окрім розглянутих, МРІ містить ряд додаткових функцій перевірки і очікування неблокуючих операцій обміну: - MPI _ SNSTALL -перевірка завершення всіх перерахованих операцій оюміну; - MPI _ Waitall - очікування завершення всіх операцій обміну; - MPI _ Testany - перевірка завершення хоча б однієї з перерахованих операцій обміну; - MPI _ Waitany - перевірка завершення будь-якої з перерахованих операцій обміну; - MPI _ Testsome - перевірка завершення кожної з перерахованих операцій обміну; - MPI _ Waitsome - очікування завершення хоч однієї з перерахованих операцій обміну та оцінка стану за всіма операціями. Наведення простого прикладу використання неблокуючих функцій достатньо складно. Доброю можливістю засвоєння розглянутих функцій можуть бути алгоритми матричного множення, які будуть розглянуті далі. Одночасне виконання передачі і прийому. Однією з часто виконуваних форм інформаційної взаємодії в паралельних програмах є обмін даними між процесами, коли для продовження обчислень процесам необхідно відправити дані одним процесам і в той же час отримати повідомлення від інших. Найпростіший варіант цієї ситуації полягає в обміні даними між двома процесами. Реалізація таких обмінів з використанням звичайних парних операцій передачі даних може бути неефективна, крім того, така реалізація повинна гарантувати відсутність тупикових ситуацій, які можуть виникати, наприклад, коли два процеси починають передавати повідомлення один одному з використанням блокуючих функцій передачі даних. Досягнення ефективного і гарантованого одночасного виконання операцій передачі і прийому даних може бути забезпечено з використанням функції МРІ:
int MPI_Sendrecv(void *sbuf, int scount, MPI_Datatype stype. int dest, int stag, void *rbuf, int rcount, MPI_Datatype etype, int source, int rtag, MPI_Comm comm, MPI_Status *status) де - sbuf, scount, stype, dest, stag - параметри повідомлення, що передається; - rbuf, rcount, rtype, source, rtag - параметри повідомлення, що приймається4 - comm - комунікатор, в рамках якого виконується передача даних; - status - структура даних з інформацією про результат виконання операції. Як випливає з опису функція MPI_Sendrecv передає повідомлення, яке описується параметрами (sbuf, scount, stype, dest, stag), процесу з рангом dest і приймає повідомлення до буфера, який визначається параметрами (rbuf, rcount, кtype, source, rtag), від процесу з рангом source. В функції MPI_Sendrecv для передачі і прийому повідомлень застосовуються різні буфери. У випадку, коли повідомлення, що відсилається більше не потрібно на процесі - відправнику, в МРІ є можливість використання буфера: int MPI_Sendrecv_replace(void *buf, int count, MPI_Datatyp type, int dest, int stag, int source, int rtaq, MPI_Comm comm, MPI_Status* status), - buf, count, type - параметри повідомлення, що передається; - dest - ранг процесу, якому відправляється повідомлення; - stag - тег для ідентифікації повідомлення, що відправляється; - source - ранг процесу, від якого виконується прийом повідомлення; - rtag - тег для ідентифікації повідомлення, що приймається; - comm - комунікатор, в рамках якого виконується передача даних; - status - структура даних з інформацією про результат виконання операції. Приклад використання функції для одночасного виконання операцій передачі і прийому наведений далі. Колективні операції передачі даних. Під колективними операціями в МЗШ розуміють операції над даними, в яких приймають участь всі процеси використовуваного комунікатора. виділення основних типів колективних операцій буде виконаний далі.
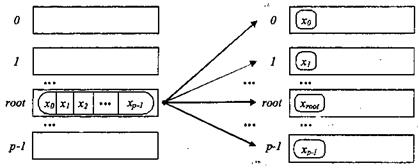
процеси процеси а) до початку операції б) після завершення операції Рис. 3.4. Загальна схема узагальненої передачі даних від одного процесу всім процесам Загальна передача даних від всіх процесів всім процесам. Передача даних від всіх процесів всім процесам є найбільш загальною операцією передачі даних, рис. 3.6.
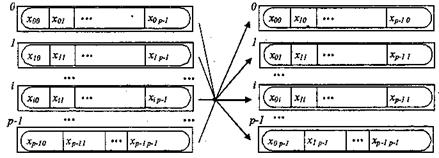
процеси процеси а) до початку операції б) після закінчення операції Рис. 3.6. Загальна схема операції передачі даних від всіх процесів всім процесам Виконання цієї операції забезпечується з використанням функції: int MPI_Alltoall(void *sbuf, int scount, MPI_Datatype stype, vjid *rbuf, int rcount, MPI_Datatype rtype, MPI_Comm comm), де - sbuf, scount, stype - параметри повідомлень, що передаються; - rbuf, rcount, rtype - параметри повідомлень, що приймаються; - comm - комунікатор, в рамках якого виконується передача даних. При виконанні функції MPI _ Alltoall кожний процес в комунікаторі передає дані з scount елементів кожному процесу (спільний розмір повідомлень, що відправляються, в процесах повинен дорівнювати scount * p елементів, де p є кількістю процесів в комунікаторі comm) і приймає повідомлення від кожного процесу. Виклик функції MPI _ Alltoall при виконанні операції загального обміну даними повинен бути виконаний в кожному процесі комунікатора. Варіант операції загального обміну даними, коли розміри повідомлень, що передаються процесами, можуть бути різними, забезпечується з використанням функції MPI _ Alltoallv.
Приклад використання функції MPI _ Alltoall буде розглянутий далі, при розробці паралельних програм множення матриці на вектор.
|
||||||||
|
|
Последнее изменение этой страницы: 2020-10-24; просмотров: 114; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.137.177.204 (0.011 с.) |