
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Цель и задачи проектированияСодержание книги
Поиск на нашем сайте
Цель курсового проектирования по дисциплине «Структуры и алгоритмы обработки данных» – развитие навыков самостоятельной творческой работы по анализу информационных потоков, конструированию рациональных структур данных, разработка, применение и программирования функциональных алгоритмов обработки данных. Основные задачи: закрепление и улучшение теоретических знаний по проектированию разнообразных структур данных, алгоритмов поиска и сортировки данных, методов доступа к данным; дальнейшее развитие навыков программирования на языках высокого уровня; использование полученных знаний для создания фрагментов информационно-поисковых систем. Курсовая работа выполняется в соответствии с заданием, в котором приводятся конкретные формы ввода-вывода информации в различных производственных системах, а также варианты алгоритмов поиска, сортировки данных, методов доступа, необходимых для организации файловой системы и её функционирования. Информационная система реализуется на ЭВМ в виде комплекса программ.
Задание к курсовой работе Разработать структуру хранения информации во внешней памяти ПЭВМ, представленной в формах (см. Приложение). Разработать программы формирования полученных файлов и печати данных форм для заданной группы лиц. Предусмотреть возможность индексного (прямого и др.) доступа к файлам, сортировки и поиска записей файлов. Разработать программу ведения[1] индексных файлов (для индексного доступа). Реализовать три запроса к файловой системе. Предусмотреть типы отношений между записями файлов.
В таблице 1 представлены варианты заданий. Таблица 1 Варианты заданий
* Коды методов даны в приложении Пояснения к работе
Физическая организация данных Любое упорядоченное расположение данных на диске называется структурой хранения. Можно организовать самые разные структуры хранения, обладающие различной производительностью, и оптимальные для различных способов использования. Однако не существует идеальной структуры хранения, которая была бы оптимальна для любых задач. Исходя из этого можно заключить, что совершенная СУБД должна содержать несколько разных структур хранения для различных частей системы. Кроме того, следует также предусмотреть возможность изменения структуры хранения по мере изменения требований к производительности системы. Методы доступа В зависимости от способа хранения записей методы доступа можно объединить в следующие 4 группы: 1) последовательные методы; 2) индексные методы; 3) адресные методы; 4) мультисписковые методы. Группа последовательных методов включает в себя физически последовательный метод доступа и связанную последовательную организацию. Отличие этих методов заключается в том, что с использованием первого метода возможно размещение файла в одном непрерывном участке памяти, а с использованием второго файл размещается в нескольких физически несмежных участках внешней памяти. Группа индексных методов отличается тем, что кроме файла данных для выборки и занесения записей создается дополнительный, так называемый индексный файл. В адресных методах доступа значение записи несет в себе физический адрес ее хранения, что позволяет достичь высокой скорости как занесения данных, так и выборки. В четвертую группу объединяются мультисписковые и другие методы. Их особенность заключается в том, что они используют для хранения данные более одного служебного файла (или списков), как правило, базируются на методах доступа, включенных в первые три группы. Зададим два основных критерия оценки методов организации данных: ЭД = 1\N, ЭХ = 1\k, где ЭД – эффективность доступа – величина, обратная среднему числу N обращений, необходимых для осуществления запроса конкретной записи БД. Например, если система для поиска нужной записи обращается к двум записям, то ЭД = 0,5; ЭХ – эффективность хранения – величина, обратная среднему числу k байтов поля вторичной памяти, требуемого для хранения одного байта исходных данных. Кроме исходных данных, память занимают таблицы, управляющая информация, свободная область, резервируемая для расширений, и область, не используемая из-за фрагментации.
Последовательные методы доступа
Наиболее эффективной для последовательной обработки больших объемов данных является физически последовательная структура. Последовательное смежное размещение записей допускает физическое блокирование, тем самым минимизируя время доступа к данным. Обработка небольших объемов данных, особенно при высокой степени изменчивости, часто оказывается наиболее эффективной при структуре хранения в виде последовательно соединенных участков (связанная последовательная структура). Физически последовательная и связанная последовательная структуры являются базовыми для очень большого класса методов доступа: индексно-последовательного, мультиспискового, инвертированного и различных механизмов поиска с использованием деревьев. Физически последовательные структуры представляют собой простейший вид организации (рис. 1).
Рис. 1. Физически последовательная организация данных
Физически последовательный метод доступа предполагает хранение физических записей в логической последовательности. При использовании магнитной ленты программист должен предоставить системе физические записи в логической последовательности. В том случае, когда носителем служит память прямого доступа, система связывает физические записи таким образом, что они образуют логическую последовательность, даже если они не передавались ей в этой последовательности (т.е. при использовании устройства прямого доступа каждой следующей представляемой физической записи система отводит следующий доступный участок физической памяти). Затем между записями базы данных организуются связи, обеспечивающие возможность логически последовательной выборки. При необходимости вести последовательную обработку данных, которые расположены в физически несмежных участках памяти, используют модификацию данного метода, которая получила название связанной последовательной организации (рис. 2). Основное различие между связанной последовательной и физически последовательной организациями заключается в применении в первом случае специальных указателей вместо смежного размещения данных в памяти.
Рис. 2. Связанная последовательная организация данных
Эффективность доступа последовательного физического метода крайне низка. Для выборки нужной записи необходимо просмотреть все предшествующие ей записи. Чтобы включить запись, её необходимо поместить в последний блок, если в нем имеется место, либо получить новый блок. Удаления записей осуществляются установкой бита удаления в удаляемой записи.
Индексные методы доступа Структуры типа Б-дерева. Одним из наиболее важных и распространенных индексов является структура типа Б-дерева (B-tree). Хотя не существует универсальной структуры хранения, оптимальной для любых приложений, все же нет сомнений, что для использования в простых системах следует выбирать индекс бинарного типа. Благодаря тому, что бинарные индексы обладают в большинстве случаев сравнительно высокой производительностью, их использование предусмотрено почти во всех СУБД, а некоторые СУБД работают только на основе такого индекса. Прежде чем дать описание структуры типа Б-дерева, следует разъяснить суть таких основных понятий, как многоуровневый или древовидный индекс. Причина необходимости создания структуры типа Б-дерева заключается в желании избежать обязательного просмотра всего содержимого индексированного файла согласно его физической последовательности. Дело в том, что если индексированный файл имеет большой размер, то и его индекс также очень велик. Поэтому последовательный просмотр даже одного только индекса требует больших затрат времени. Разрешить эту проблему можно тем же способом, что и раньше: рассмотреть индексный файл как обычный хранимый файл и создать для него еще один индекс. Эту операцию можно осуществлять повторно нужное количество раз (обычно она применяется трижды, поскольку создание большого количества иерархических уровней индексирования требуется для очень больших файлов). При этом индекс на каждом из уровней будет неплотным по отношению к нижнему индексируемому уровню (он обязательно должен быть неплотным, иначе такая структура бессмысленна, так как уровень п содержал бы такое же количество записей, что и уровень п+ 1, а для просмотра потребовалось бы такое же длительное время). Согласно терминологии VSAM, в варианте Кнута индекс состоит из двух частей: набора последовательностей и набора индексов. Набор последовательностей включает одноуровневый индекс для реальных данных, который обычно является плотным, но может быть и неплотным, если в индексированном файле проведена кластеризация на основе индекса. Записи внутри индекса сгруппированы по страницам, а страницы связаны в цепочку таким образом, чтобы логическое упорядочение на основе индекса осуществлялось внутри первой страницы, затем с помощью физической последовательности записей - внутри второй страницы этой последовательной цепочки и т.д. Таким образом, с помощью набора последовательностей можно организовать быстрый последовательный доступ к индексированным данным. Набор индексов, в свою очередь, обеспечивает быстрый непосредственный доступ к набору последовательностей (а значит, и к данным). По сути, набор индексов является древовидным индексным файлом для набора последовательностей или, строго говоря, индексом со структурой Б-дерева. Комбинация набора индексов и набора последовательностей называется структурой типа Б-плюс-дерева (B-plus tree или B^tree). На самом верхнем уровне такого индекса находится только один элемент структуры (страница, содержащая множество записей), который называется корневым (root). Индексные Б–деревья. Верхний (первый) уровень индекса делит весь диапазон возможных значений ключа на m крупных интервалов (3). Каждая ячейка 1–го уровня связана с блоком (страницей) ячеек 2–го уровня индекса. Каждая ячейка каждого блока 2–го уровня связана с блоком ячеек 3–го уровня и т. д. Блок каждого уровня, лежащего ниже, делит соответствующий диапазон значений ключа на m более мелких интервалов. Ячейки самого нижнего уровня связаны указателями с записями основного массива. Все уровни индекса упорядочены по возрастанию значений ключа. На рис. 3 изображено индексное дерево (3 уровня, построенные для упорядоченного основного массива, записи которого имеют диапазон значений ключа от 6 до 99).
Рис. 3. Пример структуры типа Б-дерева
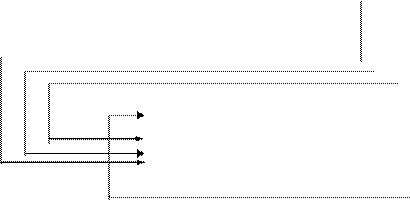
Индексно-последовательная организация файла Записи располагаются на внешнем запоминающем устройстве (ВЗУ) в конкретной физической последовательности. Последовательность расположения данных часто совпадает с последовательностью их обработки. Например, еженедельная обработка счетов клиентов фирмы (или банка) в последовательности, соответствующей порядковым номерам обрабатываемых счетов. Обработка данных усложняется, если последовательность записей файла не соответствует последовательности их обработки. При этом возникает необходимость сортировки записей, что требует значительных временных затрат (особенно когда данные хранятся на МЛ). Применение устройств с прямым доступом в совокупности с выбором наиболее приемлемой последовательности расположения записей файла существенно ускоряет процесс обработки данных. Наиболее общий метод упорядочения записей заключается в размещении записей в соответствии с возрастанием их ключей (ключи используются для адресации записей). Если же ключи следуют не в строго определенном порядке, то прямая адресация затруднительна и для выполнения поиска какой-нибудь записи требуется специальный индекс, чтобы не просматривать весь файл (последовательно с самого начала). Индекс представляет собой таблицу, в которой выполняются операции поиска. Для работы с индексно-последовательным файлом можно использовать два режима обработки: 1. Последовательная обработка, при которой записи обрабатываются в последовательности их размещения в ВЗУ. 2. Произвольная обработка, при которой записи обрабатываются в произвольной последовательности, не связанной с физической организацией записей на внешнем устройстве. В зависимости от того, какой режим обработки записей преобладает, выбирают ту или иную разновидность индексно-последовательной организации. Одни файлы используются в основном в режиме последовательной обработки записей, и только в редких случаях требуется произвольная обработка, для других файлов может преобладать режим произвольной обработки. Преобладание одного из режимов обработки отражается в используемых методах организации файлов. Для первого типа файлов записи организованы последовательно и имеется дополнительный индекс, позволяющий обращаться к записям в произвольном порядке. Для второго типа файлов стремятся максимизировать эффективность использования файла при произвольном обращении к записям, не заботясь об удобстве последовательной обработки записей. Если записи упорядочены в соответствии с возрастанием их ключей, то затраты памяти на индекс для этих ключей могут быть существенно меньше, чем в случае, когда записи не упорядочены. Индекс для непоследовательного (произвольного) файла более чем в N раз превышает индекс для последовательного файла (N – число элементов в каждом индексном блоке). Ведение индексно-последовательного файла. Хотя последовательная организация данных (рис.3) требует меньший индекс, она более сложна для эксплуатации файла. При включении новых записей возникает необходимость либо пересортировки файла, либо внесения новых записей в отдельную область и организации указателей на эти записи. При включении новых записей в последовательный файл они помещаются в область переполнения. Недостаток хранения записей в области переполнения заключается в том, что при всяком обращении к этим записям требуются дополнительные операции чтения и, возможно, перемещение головок чтения-записи на внешнем устройстве. Поэтому файлы, имеющие область переполнения, периодически реорганизуются, т.е. записи файла заново сортируются и производятся соответствующие изменения в индексе. Эта операция называется ведением файла. На рис. 4 показано включение новых записей в файл с последовательным расположением записей. Новые записи просто включаются в конец файла, и при этом не требуются указатели на область переполнения и выполнение специальных программ поддержки включения записей. Однако в данном случае возникает необходимость некоторой перегруппировки элементов индекса. Если файл очень большой или записи в него добавляются очень часто (изменчивый файл), то такой режим работы позволяет обойтись без сложных процедур ведения, и записи данных могут храниться в произвольном порядке. При последовательном расположении записей можно избежать частого выполнения процедуры ведения, предусматривая в файле позиции с пустыми записями (рис. 4). Этот метод, основанный на включении пропусков в файле для ожидаемого включения новых элементов данных, называется методом распределения свободнойпамяти (distributed free space). Однако данный метод не позволяет полностью избежать выполнения процедуры ведения.
  
Рис. 4. Индексно-последовательная организация файла. Ведение файла (использование области переполнения)
1. Бунин 2.
3. 4. Минаев 5.
6. Анохин 7. Доценко 8.

9. 10. Ященко 11.
12. 13.
14. 15. Егоров 16.
17.
18.
19. 20. Зинченко 21.
Рис.5. Индексно-произвольная организация файла
В случае индексно-произвольной организации файла индексный аппарат более сложный по сравнению с индексно-последовательной организацией (рис. 5).
Поиск: Воробьева à А нохин - В асильев - В оробьева (последовательно) (ближайшее максимальное значение меньше заданного).
Поиск. Поиск записи с определённым значением ключа начинается с просмотра верхнего уровня индекса. В блоке индекса ищется значение ключа, меньшее или равное искомому, причем предыдущая запись блока должна иметь меньший ключ. От найденной записи по указателю спускаются в порождённый блок второго уровня индекса и в нём отыскивают запись с меньшим или равным искомому значением ключа. От этой записи переходят в порождённый блок 3-го уровня и т. д., вплоть до нахождения нужной записи в основном массиве или до выработки сообщения об отсутствии нужной записи:
где Xi – i-е значение индексируемого поля; Pi – указатель на вершину, создающую значение индексируемого поля, меньший или равный Xi; Pi+1 – указатель на вершину, создающую значение индексируемого поля, больший Xi; Pn – указатель последнего поля.
Адресные методы доступа Суть прямого метода доступа состоит во взаимно однозначном соответствии между ключом записи и её физическим адресом. Физическое местоположение записи определяется непосредственно из значения ключа в том случае, если проектировщик БД в состоянии предусмотреть в памяти для каждой записи место, определяемое уникальным значением её первичного ключа. Тогда можно построить простую функцию преобразования ключа в адрес, обеспечивающую запоминание и выборку каждой записи в точности за один произвольный доступ к блоку. С этой целью каждой совокупности ключевых значений записей, расположенных в одном и том же физическом блоке, можно присвоить относительный номер блока (относительный физический адрес). На самом деле данные хранятся в соответствии с порядком ключей, но при этом им неявно последовательно присвоены относительные номера блоков.
Рис. 6. Организация хранения и выборки записей, данных файла “Группа” методом прямого доступа
На рис. 6 приведен простой пример организации записей файла “Группа” БД “Факультет”. При вычислении адреса хранения записи в этом примере используется следующий алгоритм: если предположить, что номера студенческих групп на факультете начинаются с буквы, то далее следует цифра не более 10. У всех исходных ключей, начинающихся с литеры “К”, взять последние цифры, использовать их в качестве целевого ключа и адреса хранения; у “Л”– взять цифры, прибавить 10 -> адрес; у “М”- взять цифры, прибавить 20 -> адрес и т. д. Если некоторые физические записи (например, с ключом М03 и М05) отсутствуют, то память для этих записей резервируется. Эффективность доступа. Если между значением ключа и физическим адресом существует взаимно однозначное соответствие, то Эд = 1 (всегда). Эффективность хранения зависит от плотности ключей. При низкой плотности память расходуется нерационально, поскольку резервируются адреса, соответствующие отсутствующим ключам. Этот метод отличается простотой, и если бы во всех приложениях существовала бы возможность управлять значениями ключей, то этот метод доступа был бы распространен значительно шире. Однако “неуправляемость” ключа является обычной проблемой, присущей большинству БД. Произвольный метод доступа. Хеширование Этот метод, как и прямой, основан на алгоритмическом определении адреса физической записи по значению её ключа. Различие состоит в том, что при прямом методе доступа имеет место взаимно однозначное отображение ключа в адрес, а метод доступа посредством хеширования допускает возможность отображения многих ключей в один адрес. Идентификатор – атрибут, уникально определяющий запись. Хеширование идентификатора – метод доступа, обеспечивающий прямую адресацию данных путем преобразования значения ключа в относительный или абсолютный физический адрес. Алгоритм получения адреса называется функцией хеширования, или функцией преобразования ключа. При использовании хеш-функции возможно преобразование двух или более значений ключа в один и тот же физический адрес. Коллизия – случай преобразования ключа в уже занятый собственный адрес. Хешированием, хеш-адресацией или хеш-индексированием называется технология быстрого прямого доступа к хранимой записи на основе заданного значения некоторого поля. При этом необязательно, чтобы поле было ключевым. Ниже перечислены основные черты этой технологии. • Каждая хранимая запись базы данных размещается по адресу (RID-указателю или номеру страницы), который вычисляется с помощью специальной хеш-функции на основе значения некоторого поля данной записи, т.е. хеш-поля, или хеш-ключа. Вычисленный адрес называется хеш-адресом. • Для сохранения записи в СУБД сначала вычисляется хеш-адрес новой записи, а затем диспетчер файлов помещает эту запись по вычисленному адресу. • Для извлечения нужной записи по заданному значению хеш-поля в СУБД сначала вычисляется хеш-адрес, а затем диспетчеру файлов посылается запрос для извлечения записи по вычисленному адресу. Пример: хеш-адрес (т.е. номер страницы) = остаток от деления на 13 числа, содержащегося в поле номера записи S# Это простейший пример общего класса хеш-функций типа деление/остаток. В качестве делителя следует выбирать простое натуральное число. В этом примере номерами страниц для заданных записей будут 9, 5, 1, 10 и 6 соответственно. Из вышеизложенного ясно, что хеширование отличается от индексирования тем, что в файле может быть любое количество индексов, но только одна структура хеширования или, иначе говоря, одно хеш-поле. (В этом замечании предполагается, что хеширование является прямым, однако в файле можно задать любое количество косвенных хеширований.) Кроме демонстрации принципа работы хеширования, в данном примере также показано, почему возникает необходимость использовать для хеш-функции специальную функцию. Теоретически можно было бы для определения адреса вместо функции использовать непосредственно значение ключевого поля (если это поле имеет числовой тип). Однако практически такой способ неприемлем, поскольку количество значений может быть большим. Таким образом, во избежание неэффективного использования дискового пространства следует найти такую хеш-функцию, чтобы можно было сузить диапазон, например от 000-999 до 0-9. Для того чтобы зарезервировать дополнительное пространство (размером 20 % от исходной величины), диапазон 0-9 в данном примере расширен до 0-12. В этом примере также наглядно проявляется недостаток хеширования. Дело в том, что физическая последовательность записей внутри хранимого файла почти всегда отличается от последовательности ключевого поля, а также любой другой логически заданной последовательности. Еще одним недостатком хеширования является возможность возникновения коллизий, т.е. ситуаций, когда две или более различных записи ("синонимы") имеют одинаковые адреса. Допустим, что файл поставщиков из предыдущего примера содержит также запись с номером S1400. При использовании хеш-функции типа "остаток от деления на 13" возникнет коллизия (по адресу 9) с записью S100. Ясно, что такая хеш-функция неадекватна и для устранения коллизий необходимо ее исправить. В рассматриваемом примере одним из вариантов исправления могло быть использование остатка от деления на 13 не в качестве адреса, а в качестве стартовой точки для дополнительного просмотра и поиска. Таким образом, для вставки записи с номером поставщика S1400 (допуская, что в файле уже содержатся записи S100-S500) следует перейти к странице 9, а затем найти первую свободную страницу. В данном примере это будет страница 11. Для извлечения этой записи придется проделать такую же последовательность действий. Кроме того, если на одной странице располагается несколько записей (как обычно бывает на практике), можно воспользоваться методом последовательного перебора. Допустим, что на странице р (пустой) может поместиться п записей. Тогда при размещении записей и возникновении первых п коллизий по некоторому хеш-адресу р все такие записи будут размещены на этой странице и найдены при необходимости с помощью последовательного перебора. Однако при размещении следующей п+1 записи и возникновении очередной коллизии запись придется разместить на дополнительной странице переполнения, для чего понадобится дополнительная дисковая операция ввода-вывода. Другим способом разрешения коллизий, который чаще применим на практике, может быть использование значения хеш-функции в качестве адреса а не какой-либо записи с данными, а точки привязки. Точка привязки — это начальный адрес а цепочки указателей (цепочки коллизи й), связывающей вместе все записи или все страницы с записями, которые вызывают коллизии по адресу а. Внутри цепочки коллизий записи также могут быть упорядочены согласно хеш-полю для упрощения последующего поиска. Таблица называется таблицей с прямым доступом, если для определения местоположения каждой записи используется её ключ. Функция хеширования определяется как отображение Н: К → А, где К – пространство или множество ключей, которые могут идентифицировать записи в таблице с прямым доступом, а А – адресное пространство {c+1, с+2, …, с+m}. Предположим, что адресное пространство имеет вид {1, 2, …, m}. Если адреса в этом пространстве определяются функцией Н(х), то для перехода к приведенному выше адресному пространству может быть применена функция Н(х) + с. Мерой использования памяти в таблицах с прямым доступом служит коэффициент заполнения, определяемый как отношение числа записей к числу мест в таблице. В таком случае коэффициент заполнения а = n/m, где n- число записей. Прежде чем описывать отдельные функции хеширования, исследуем более подробно пространство ключей К. Каждый элемент пространст
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-10-24; просмотров: 111; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.186.156 (0.014 с.) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



 Иванов
Иванов


 100
100
 101
101
 102
102
 103
103












 Юшина
Юшина Ушакова
Ушакова
 Тарасов
Тарасов Васильев
Васильев Федоров
Федоров

 Зуева
Зуева

 Номер группы
Номер группы



