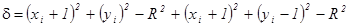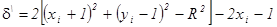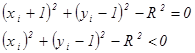Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Трёхмерная компьютерная графикаСтр 1 из 6Следующая ⇒
Процедура разложения в растр отрезка по методу цифрового дифференциального анализатора (ЦДА) предполагается, что концы отрезка (x1,y1) и (x2,y2) не совпадают Integer – функция преобразования вещественного числа в целое. Примечание: во многих реализациях функция Integer означает взятие целой части, т.е. Integer (- 8.5) = - 9, а не - 8. В алгоритме используется именно такая функция. Sign - функция, возвращающая - 1, 0, 1 для отрицательного нулевого и положительного аргумента соответственно. if abs (x2 -x1 ) ³ abs (y2 - y1 ) then Длина = abs (x2 - x1 ) Else Длина = abs (y2 - y1 ) End if полагаем большее из приращений D x или D y равным единице растра Dx = (x2 -x1 ) / Длина Dy = (y2 - y1 ) / Длина округляем величины, а не отбрасываем дробную часть использование знаковой функции делает алгоритм пригодным для всех квадрантов x = x1 + 0.5 * Sign (Dx) y = y1 + 0.5 * Sign (Dy) начало основного цикла i =1 while (i £ Длина) Plot (Integer (x), Integer (y)) x = x + Dx y = y + Dy i = i + 1 End while Finish С помощью этого алгоритма получают прямые, вполне удовлетворительного вида, но у него есть ряд недостатков. Во-первых, плохая точность в концевых точках. Во-вторых, результаты работы алгоритма зависят от ориентации отрезка. Вдобавок предложенный алгоритм использует вещественную арифметику, что заметно снижает скорость выполнения. Алгоритм Брезенхема Алгоритм Брезенхема выбирает оптимальные растровые координаты для представления отрезка. В процессе работы одна из координат - либо x, либо у (в зависимости от углового коэффициента) - изменяется на единицу. Изменение другой координаты (либо на нуль, либо на единицу) зависит от расстояния между действительным положением отрезка и ближайшими координатами сетки. Такое расстояние называется ошибкой. Алгоритм построен так, что требуется проверять лишь знак этой ошибки. На рис.2.1 это иллюстрируется для отрезка в первом
½ £ Dy £ 1 (ошибка ³ 0) 0 £ Dy/Dx < ½ (ошибка <0) Инициировать ошибку в – ½ ошибка = ошибка + Dy/Dx
2.1 Основная идея алгоритма Брезенхема
октанте, т. е. для отрезка с угловым коэффициентом, лежащим в диапазоне от нуля до единицы. Из рисунка можно заметить, что если угловой коэффициент отрезка из точки (0,0) больше чем 1/2, то его пересечение с прямой x = 1 будет расположено ближе к прямой у = 1, чем к прямой у = 0. Следовательно, точка растра (1,1) лучше аппроксимирует ход отрезка, чем точка (1,0). Если угловой коэффициент меньше 1/2, то верно обратное. Для углового коэффициента равного 1/2 нет какого-либо предпочтительного выбора. В данном случае алгоритм выбирает точку (1,1).
Быстродействие алгоритма можно существенно увеличить, если использовать только целочисленную арифметику и исключить деление. Т.к. важен лишь знак ошибки, то приняв
можно добиться хорошей скорости выполнения алгоритма.
2.2 Разбор случаев для обобщённого алгоритма Брезенхема.
Чтобы реализация алгоритма была полной необходимо обрабатывать отрезки во всех октантах. Когда абсолютная величина углового коэффициента больше 1, y постоянно изменяется на единицу, а критерий ошибки Брезенхема используется для принятия решения об изменении величены x. Выбор постоянно изменяющейся (на +1 или –1) координаты зависит от квадранта (рис. 2.2). Алгоритм Брезенхема может быть оформлен в следующем виде.
Else Обмен = 0 End if инициализация
основной цикл for i = 1 to Dx Plot (x,y) While ( If Обмен = 1 then x = x + s1 Else y = y + s2 End if
End while if Обмен = 1 then y = y + s2 Else x = x + s1 End if
next i Finish Этот алгоритм удовлетворяет самым строгим требованиям. Он имеет приемлемую скорость и может быть легко реализован на аппаратном или микропрограммном уровне. Алгоритм Брезенхема для генерации окружностей В растр нужно разлагать не только линейные, но и другие, более сложные функции. Разложению конических сечений, т. е. окружностей, эллипсов, парабол, гипербол посвящено значительное число работ.Наибольшее внимание, разумеется, уделено окружности. Один из наиболее эффективныхи простых для понимания алгоритмов генерации окружности принадлежит
2.3 Генерация полной окружности из дуги в первом октанте
Брезенхему. Для начала заметим, что необходимо сгенерировать только одну восьмую часть окружности. Остальные её части могут быть получены последовательными отражениями, как это показано на рис. 2.3. Если сгенерирован первый октант (от 0° до 45° против часовой стрелки), то второй октант можно получить зеркальным отражением относительно прямой у = x, что дает в совокупности первый квадрант. Первый квадрант отражается относительно прямой x = 0 для получения соответствующей части окружности во втором квадранте. Верхняя полуокружность отражается относительно прямой у = 0 для завершения построения. На рис.2.3. приведены двумерные матрицы соответствующих преобразований.
Для вывода алгоритма рассмотрим первую четверть окружности с центром в начале координат. Заметим, что если работа алгоритма начинается в точке x = 0, у = R, то при генерации окружности по часовой стрелке в первом квадранте у является монотонно убывающей функцией аргумента x (рис. 2.4). Аналогично, если исходной точкой является y = 0, x = R, то при генерации окружности против часовой стрелки x будет монотонно убывающей функцией аргумента у. В нашем случае выбирается генерация по часовой стрелке с началом в точке x = 0, у = R. Предполагается, что центр окружности и начальная точка находятся точно в точках растра. Для любой заданной точки на окружности при генерации по часовой стрелке существует только три возможности выбрать следующий пиксел, наилучшим образом приближающий окружность: горизонтально вправо, по диагонали вниз и вправо, вертикально вниз. На рис.2.5 эти направления обозначены соответственно mH, mD, mV.
2.4 Окружность в первом квадранте. 2.5 Выбор пикселов в первом квадранте
Алгоритм выбирает пиксел, для которого минимален квадрат расстояния между одним из этих пикселов и окружностью, т. е. минимум из mH = | (xi + 1)2 + (yi )2 – R2 | mH = | (xi + 1)2 + (yi - 1)2 – R2 | mH = | (xi)2 + (yi - 1)2 – R2 | Вычисления можно упростить, если заметить, что в окрестности точки (xi, yi ) возможны только пять типов пересечений окружности и сетки растра, приведенных на рис.2.6. Разность между квадратами расстояний от центра окружности до диагонального пиксела (xi + 1, yi- 1) и от центра до точки на окружности R2 равна
Как и в алгоритме Брезенхема для отрезка, для выбора соответствующего пиксела желательно использовать только знак ошибки, а не её величину.
2.6 Пересечение окружности и сетки растра
При D < 0 диагональная точка (xi + 1, yi- 1) находится внутри реальной окружности, т. е. это случаи 1 или 2 на рис.2.6. Ясно, что в этой ситуации следует выбрать либо пиксел (xi + 1, yi )т. е. mH, либо пиксел (xi + 1, yi- 1), т. е. mD. Для этого сначала рассмотрим случай 1 и проверим разность квадратов расстояний от окружности до пикселов в горизонтальном и диагональном направлениях:
При d < 0 расстояние от окружности до диагонального пиксела (mD)больше, чем до горизонтального (mH). Напротив, если d > 0, расстояние до горизонтального пиксела (mH)больше. Таким образом, при d < 0 выбираем mH (xi + 1, уi ) при d > 0 выбираем mD (xi + 1, уi – 1)
При d = 0, когда расстояния от окружности до обоих пикселов одинаковы, выбираем горизонтальный шаг. Количество вычислений, необходимых для оценки величины d, можно сократить, если заметить, что в случае 1
так как диагональный пиксел (xi + 1, уi – 1) всегда лежит внутри окружности, а горизонтальный (xi + 1, уi ) - вне ее. Таким образом, d можно вычислить по формуле
Дополнение до полного квадрата члена (yi )2 с помощью добавления и вычитания - 2уi + 1 дает
В квадратных скобках стоит по определению Di, и его подстановка
d = 2(Di + yi) – 1
существенно упрощает выражение. Рассмотрим случай 2 на рис.2.6 и заметим, что здесь должен быть выбран горизонтальный пиксел (xi + 1, уi ), так как у является монотонно убывающей функцией. Проверка компонент d показывает, что
поскольку в случае 2 горизонтальный (xi + 1, уi ) и диагональный (xi + 1, уi – 1) пикселы лежат внутри окружности. Следовательно, d < 0, и при использовании того же самого критерия, что и в случае 1, выбирается пиксел (xi + 1, уi ). Если Di > 0, то диагональная точка (xi + 1, уi – 1) находится вне окружности, т. е. это случаи З и 4 на рис.2.6. В данной ситуации ясно, что должен быть выбран либо пиксел (xi + 1, уi – 1), т. е. mD, либо (xi, уi – 1), т. е. mV. Аналогично разбору предыдущего случая критерий выбора можно получить, рассматривая сначала случай З и проверяя разность между квадратами расстояний от окружности до диагонального mD и вертикального mV пикселов, т. е.
При d\ < 0 расстояние от окружности до вертикального пиксела (xi, уi – 1) больше и следует выбрать диагональный шаг mD, к пикселу (xi + 1, уi – 1). Напротив, в случае d\ > 0 расстояние от окружности до диагонального пиксела больше и следует выбрать вертикальное движение к пикселу (xi, уi – 1). Таким образом,
при d £ 0 выбираем mD в (xi + 1, уi – 1) при d < 0 выбираем mV в (xi, уi – 1)
Здесь в случае d = 0, т. е. когда расстояния равны, выбран диагональный шаг. Проверка компонент d\ показывает, что
поскольку для случая З диагональный пиксел (xi + 1, уi – 1) находится вне окружности, тогда как вертикальный пиксел (xi, уi – 1) лежит внутри ее. Это позволяет записать d\ в виде
Дополнение до полного квадрата члена (xi )2 с помощью добавления и вычитания 2xi + 1 дает
Использование определения Di приводит выражение к виду
Теперь, рассматривая случай 4, снова заметим, что следует выбрать вертикальный пиксел (xi, уi – 1), так как y является монотонно убывающей функцией при возрастании x. проверка компонент d\ для случая 4 показывает, что
поскольку оба пиксела находятся вне окружности. Следовательно, d\ > 0 и при использовании критерия, разработанного для случая 3, происходит верный выбор mV. Осталось проверить только случай 5 на рис.2.7, который встречается, когда диагональный пиксел (xi + 1, уi – 1) лежит на окружности, т. е. Di = 0. Проверка компонент d показывает, что
Следовательно, d > 0 и выбирается диагональный пиксел (xi + 1, уi – 1). Аналогичным образом оцениваем компоненты d\:
и d < 0, что является условием выбора правильного диагонального шага к (хi + 1, уi – 1). Таким образом, случай Di = 0 подчиняется тому же критерию, что и случай Di < 0 или Di > 0. Подведем итог полученных результатов: Di < 0 d £ 0 выбираем пиксел (хi + 1, уi ) ® mH d > 0 выбираем пиксел (хi + 1, уi – 1) ® mD Di > 0 d\ £ 0 выбираем пиксел (хi + 1, уi – 1) ® mD d\ > 0 выбираем пиксел (хi, уi – 1) ® mV Di = 0 выбираем пиксел (хi + 1, уi – 1) ® mD Легко разработать простые рекуррентные соотношения дня реализации пошагового алгоритма. Сначала рассмотрим горизонтальный шаг mH к пикселу (хi + 1, уi ). Обозначим это новое положение пиксела как (i + 1). Тогда координаты нового пиксела и значение Di равны
Аналогично координаты нового пиксела и значения Di для шага mD к пикселу (хi + 1, уi – 1) таковы:
То же самое для шага mV к (хi, уi – 1)
Реализация алгоритма Брезенхема для окружности приводиться ниже.
Else присвоить пикселу в x значение цвета фона End if next x
В данном алгоритме каждый пиксел обрабатывается только один раз, так что затраты на ввод/вывод значительно меньше, чем в алгоритме со списком рёбер, в результате чего, при его аппаратной реализации, он работает на один-два порядка быстрее чем алгоритм с упорядоченным списком рёбер. Алгоритмы заполнения с затравкой В обсуждавшихся выше алгоритмах заполнение происходит в порядке сканирования. Иной подход используется в алгоритмах заполнения с затравкой. В них предполагается, что известен хотя бы один пиксел из внутренней области многоугольника. Алгоритм пытается найти и закрасить все другие пикселы, принадлежащие внутренней области. Области могут быть либо внутренние, либо гранично-определенные.
Рис. 2.10. Внутренне - определённая область Рис. 2.11. Гранично-определённая область
Если область относится к внутренне - определенным, то все пикселы, принадлежащие внутренней части, имеют один и тот же цвет или интенсивность, а все пикселы, внешние по отношению к области, имеют другой цвет. Это продемонстрировано на рис. 2.10. Если область относится к гранично-определенным, то все пикселы на границе области имеют выделенное значение или цвет, как это показано на рис. 2.11. Алгоритмы, заполняющие внутренне - определенные области, называются внутренне - заполняющими, а алгоритмы для гранично-определённых областей – гранично-заполняющими. Далее будут обсуждаться гранично-заполняющие алгоритмы, однако соответствующие внутренне заполняющие алгоритмы можно получить аналогичным образом. Внутренне- или гранично-определённые области могут быть 4- или 8- связными. Если область 4-связная, то любой пиксел в области можно достичь с помощью комбинаций движений только в 4-х направлениях: налево, направо, вверх, вниз. Для 8-и связной области добавляются ещё и диагональные направления. Алгоритм заполнения 8-связной области заполнит и 4-связную, но обратное не верно. Однако в ситуации, когда требуется заполнить разными цветами две отдельные 4-связные области, использование 8-связного алгоритма даст не верный результат. Далее речь пойдёт об алгоритмах для 4-связных областей, однако их легко адаптировать и для 8-связных.
Построчный алгоритм заполнения с затравкой Используя стек, можно разработать алгоритм заполнения гранично-определенной области. Стек - это просто массив или другая структура данных, в которую можно последовательно помещать значения и из которой их можно последовательно извлекать. Как показывает практика, стек может быть довольно большим. Зачастую в нём содержится дублирующаяся информация. В построчном алгоритме заполнения с затравкой стек минимизируется за счёт хранения только затравочного пиксела для любого непрерывного интервала на сканирующей строке. Непрерывный интервал - это группа примыкающих друг к другу пикселов (ограниченная уже заполненными или граничными пикселами). Мы для разработки алгоритма используем эвристический подход, однако также возможен и теоретический подход, основанный на теории графов. Данный алгоритм применим гранично-определённым 4-связным областям, которые могут быть как выпуклыми, так и не выпуклыми, а также могут содержать дыры. В области, внешней и примыкающей к нашей, не должно быть пикселов с цветом, которым область или многоугольник заполнятся. Схематично работу алгоритма можно разбить на четыре этапа.
Построчный алгоритм заполнения с затравкой Затравочный пиксел на интервале извлекается из стека, содержащего затравочные пикселы.
Интервал с затравочным пикселом заполняется влево и вправо от затравки вдоль сканирующей строки до тех пор пока не будет найдена граница.
В переменной Xлев и Xправ запоминаются крайний левый и крайний правый пикселы интервала
В диапазоне Xлев £ x £ Xправ проверяются строки расположенные непосредственно над в под текущей строкой. Определяется, есть ли на них еще не заполненные пикселы. Если такие пикселы есть (т. е. не все пикселы граничные, или уже заполненные), то в указанном диапазоне крайний правый пиксел в каждом интервале отмечается как затравочный и помещается в стек.
При инициализации алгоритма в стек помешается единственный затравочный пиксел, работа завершается при опустошении стека. Ниже приводится более подробное описание алгоритма на псевдокоде.
End while сохраняем крайний справа пиксел Xправ = x -1 восстанавливаем x- координату затравки x = Врем_х заполняем интервал слева от затравки x = x -1 while Пиксел (x, y) ¹ Гран_значение Пиксел (x, y) = Нов_значение x = x -1 End while сохраняем крайний слева пиксел Xлев = x +1 восстанавливаем x- координату затравки x = Врем_х проверим, что строка выше не является ни границей многоугольника, ни уже полностью заполненной; если это не так, то найти затравку, начиная с левого края подинтервала сканирующей строки x = Xлев y = y +1 while x £ Xправ ищем затравку на строке выше Флаг = 0 while (Пиксел (x, y) ¹ Гран_значение and Пиксел (x, y) ¹ Нов_значение and x < Xправ) if Флаг = 0 then Флаг = 1 x = x + 1 End while помещаем в стек крайний справа пиксел if Флаг =1 then if (x = Xправ and Пиксел (x, y) ¹ Гран_значение and Пиксел (x, y) ¹ Нов_значение) then Push Пиксел (x, y) Else Push Пиксел (x - 1, y) End if Флаг = 0 End if продолжим проверку, если интервал был прерван Xвход = x while ((Пиксел (x, y) = Гран_значение or Пиксел (x, y) = Нов_значение) and x < Xправ) x = x + 1 End while удостоверимся что координата пиксела увеличена if x = Xвход then x = x + 1 End while проверим, что строка ниже не является ни границей многоугольника, ни уже полностью заполненной Эта часть алгоритма совершенно аналогична проверке для строки выше, за исключением, того что вместо y = y + 1 надо подставить y = y - 1 endwhile Finish Удаление невидимых линий и поверхностей Задача удаления невидимых линий и поверхностей является одной из наиболее сложных в машинной графике. Алгоритмы удаления невидимых линий и поверхностей служат для определения линий ребер, поверхностей или объемов, которые видимы или невидимы для наблюдателя, находящегося в заданной точке пространства.
3.1 Необходимость удаления невидимых линий
Необходимость удаления невидимых линий, ребер, поверхностей или объемов проиллюстрирована рис.3.1. На рис.3.1, а приведен типичный каркасный чертеж куба. Его можно интерпретировать двояко: как вид куба сверху, слева или снизу, справа. Удаление тех линий или поверхностей, которые невидимы с соответствующей точки зрения, позволяют избавиться от неоднозначности. Результаты показаны на рис.3.1, b и c. Сложность задачи удаления невидимых линий и поверхностей привела к появлению большого числа, различных способов ее решения. Многие из них ориентированы на специализированные приложения. Наилучшего решения общей задачи удаления невидимых линий и поверхностей не существует. Для моделирования процессов в реальном времени, например, для авиа тренажеров, требуются быстрые алгоритмы, которые могут порождать результаты с частотой видео генерации (30 кадр/с). Для машинной мультипликации требуются алгоритмы, которые могут генерировать сложные реалистические изображения, в которых представлены тени, прозрачность и фактура, учитывающие эффекты отражения и преломления цвета в мельчайших оттенках. Подобные алгоритмы работают медленно, и зачастую на вычисления требуется несколько минут или даже часов. Строго говоря, учет эффектов прозрачности, фактуры, отражения и т. п. не входит в задачу удаления невидимых линий или поверхностей. Естественнее считать их частью процесса визуализации изображения. Процесс визуализации является интерпретацией или представлением изображения или сцены в реалистической манере. Однако многие из этих эффектов встроены в алгоритмы удаления невидимых поверхностей и поэтому будут затронуты. Существует тесная взаимосвязь между скоростью работы алгоритма и детальностью его результата. Ни один из алгоритмов не может достигнуть хороших оценок для этих двух показателей одновременно. По мере создания все более быстрых алгоритмов можно строить все более детальные изображения. Реальные задачи, однако, всегда будут требовать учета еще большего количества деталей. Алгоритмы удаления невидимых линий или поверхностей можно классифицировать по способу выбора системы координат или пространства, в котором они работают. Алгоритмы, работающие в объектном пространстве, имеют дело с физической системой координат, в которой описаны эти объекты. При этом получаются весьма точные результаты, ограниченные, вообще говоря, лишь точностью вычислений. Полученные изображения можно свободно увеличивать во много раз. Алгоритмы, работающие в объектном пространстве, особенно полезны в тех приложениях, где необходима высокая точность. Алгоритмы же, работающие в пространстве изображения, имеют дело с системой координат того экрана, на котором объекты визуализируются. При этом точность вычислений ограничена разрешающей способностью экрана. Результаты, полученные в пространстве изображения, а затем увеличенные во много раз, не будут соответствовать исходной сцене. Алгоритмы, формирующие список приоритетов работают попеременно в обеих упомянутых системах координат. Объем вычислений для любого алгоритма, работающего в объектном пространстве, и сравнивающего каждый объект сцены со всеми остальными объектами этой сцены, растет теоретически как квадрат числа объектов (n2 ). Аналогично, объем вычислений любого алгоритма, работающего в пространстве изображения и сравнивающего каждый объект сцены с позициями всех пикселов в системе координат экрана, растет теоретически, как nN. Здесь nобозначает количество объектов (тел, плоскостей или ребер) в сцене, а N - число пикселов. Теоретически трудоемкость алгоритмов, работаюoих в объектном пространстве, меньше трудоемкости алгоритмов, работающих в пространстве изображения, при n < N. Поскольку N обычно равно (512)2, то теоретически большинство алгоритмов следует реализовывать в объектном пространстве. Однако на практике это не так. Дело в том, что алгоритмы, работающие в пространстве изображения, более эффективны потому, что для них легче воспользоваться преимуществом когерентности при растровой реализации. Далее дается изложение некоторых алгоритмов, работающих как в объектном пространстве, так и в пространстве изображения. Каждый из них иллюстрирует одну или несколько основополагающих идей теории алгоритмов удаления невидимых линий и поверхностей. Алгоритм плавающего горизонта Алгоритм плавающего горизонта чаще всего используется для удаления невидимых линий трехмерного представления функций, описывающих поверхность в виде F (x, у, z) = 0 Подобные функции возникают во многих приложениях в математике, технике, естественных науках и других дисциплинах. Существует много алгоритмов, использующих этот подход. Поскольку в приложениях в основном нас интересует описание поверхности, этот алгоритм обычно работает в пространстве изображения. Главная идея данного метода заключается в сведении трехмерной задачи к двумерной путем пересечения исходной поверхности последовательностью параллельных секущих плоскостей, имеющих постоянные значения координат x, y или z.
Секущие плоскости с постоянной координатой
На рис. 3.2 приведен пример, где указанные параллельные плоскости определяются постоянными значениями z. Функция F (x, у, z) = 0 сводится к последовательности кривых, лежащих в каждой из этих параллельных плоскостей, например к последовательности y = f (x, z) или y = g (y, z) где z постоянно на каждой из заданных параллельных плоскостей. Итак, поверхность теперь складывается из последовательности кривых, лежащих в каждой из этих плоскостей, как показано на рис. 3.3. Здесь предполагается, что полученные кривые являются однозначными функциями независимых переменных. Если спроецировать полученные кривые на плоскость z = 0, то сразу становится ясна идея алгоритма удаления невидимых участков исходной поверхности. Алгоритм сначала упорядочивает плоскости z = const по возрастанию расстояния до них от точки наблюдения. Затем для каждой плоскости, начиная с ближайшей к точке наблюдения, строится кривая, лежащая на ней. Алгоритм удаления невидимой линии заключается в следующем:
Если на текущей плоскости при некотором заданном значении x соответствующее значение y на кривой больше значения y для всех предыдущих кривых при этом значении x, то текущая кривая видима в этой точке; в противном случае она невидима.
Реализация данного алгоритма достаточно проста.
3.4 Обработка нижней стороны поверхности
Для хранения максимальных значений y при каждом значении x используется массив, длина которого равна числу различимых точек (разрешению) по оси x в пространстве изображения. Значения, хранящиеся в этом массиве, представляют собой текущие значения “горизонта”. Поэтому по мере рисования каждой очередной кривой этот горизонт “всплывает”. Фактически этот алгоритм удаления невидимых линий работает каждый раз с одной линией. Алгоритм работает очень хорошо до тех пор, пока какая-нибудь очередная кривая не окажется ниже самой первой из кривых. Как показано на рис.3.4,а. Подобные кривые, естественно, видимы и представляют собой нижнюю сторону исходной поверхности. Однако алгоритм будет считать их невидимыми. Нижняя сторона поверхности делается видимой, если модифицировать этот алгоритм, включив в него нижний горизонт, который опускается вниз по ходу работы алгоритма. Это реализуется при помощи второго массива, длина которого равна числу различимых точек по оси x в пространстве изображения. Этот массив содержит наименьшие значения y для каждого значения x. Алгоритм теперь становится таким:
Если на текущей плоскости при некотором заданном значении x соответствующее значение y на кривой больше максимума или меньше минимума по y для всех предыдущих кривых при этом x, то текущая кривая видима. В противном случае она невидима.
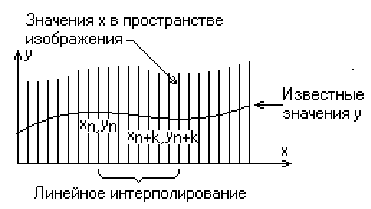
Полученный результат показан на рис. 3.4, b. В изложенном алгоритме предполагается, что значение функции, т. е. y, известно для каждого значения x в пространстве изображения. Однако если для каждого значения x нельзя указать (вычислить) соответствующее ему значение у, то невозможно поддерживать массивы верхнего и нижнего плавающих горизонтов. В таком случае используется линейная интерполяция значений у между известными значениями для того, чтобы заполнить массивы верхнего и нижнего плавающих горизонтов, как показано на рис. 3.5.
3.5 Линейная интерполяция между заданными точками
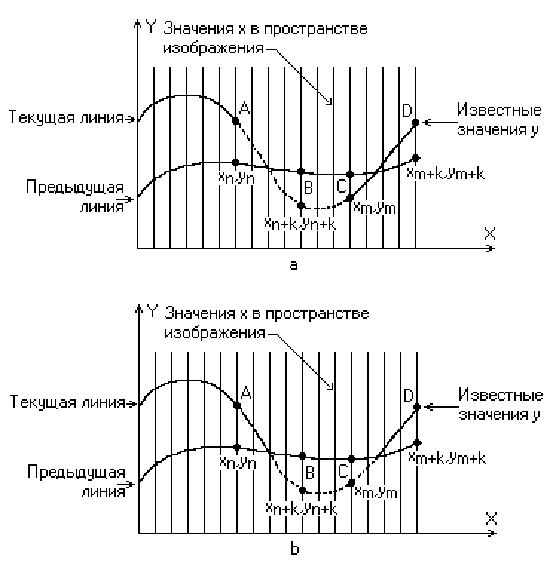
3.6. Эффект пересекающихся кривых
Если видимость кривой меняется, то метод с такой простой интерполяцией не даст корректного результата. Этот эффект проиллюстрирован рис. 3.6,а. Предполагая, что операция по заполнению массивов проводится после проверки видимости, получаем, что при переходе текущей кривой от видимого к невидимому состоянию (сегмент АВ на рис. 3.6,а), точка (xn+k, yn+k )объявляется невидимой. Тогда участок кривой между точками (xn, yn) и (xn+k, yn+k ) не изображается и операция по заполнению массивов не производится. Образуется зазор между текущей и предыдущей кривыми Если на участке текущей кривой происходит переход от невидимого состояния к видимому (сегмент CDна рис. 3.6,а), то точка (xm+k, ym+k ) объявляется видимой, а участок кривой между точками (xm, ym)и (xm+k, ym+k ) изображается и операция по заполнению массивов проводится. Поэтому изображается и невидимый кусок сегмента CD. Кроме того, массивы плавающих горизонтов не будут содержать точных значений у. А это может повлечь за собой дополнительные нежелательные эффекты для последующих кривы. Следовательно, необходимо решать задачу о поиске точек пересечения сегментов текущей и предшествующей кривых. Существует несколько методов получения точек пересечения кривых. На растровых дисплеях значение координаты x можно увеличивать на 1, начиная с xn или xm (рис. 3.6,а). Значение у, соответствующее текущему значению координаты х в пространстве изображения, получается путем добавления к значению у, соответствующему предыдущему значению координаты x, вертикального приращения Dy вдоль заданной кривой. Затем определяется видимость новой точки с координатами (x + 1, y + Dy). Если эта точка видима, то активируется связанный с ней пиксел. Если невидима, то пиксел не активируется, а x увеличивается на 1. Этот процесс продолжается до тех пор, пока не встретится xn+k или xm+k. Пересечения для растровых дисплеев определяются изложенным методом с достаточной точностью. Близкий и даже более элегантный метод определения пересечений основан на двоичном поиске. Точное значение точки пересечения двух прямолинейных отрезков, которые интерполируют текущую и предшествующую кривые, между точками (xn, yn) и (xn+k, yn+k ) (рис. 3.6) задается формулами:
где
а индексы cи p соответствуют текущей и предшествующей кривым. Полученный результат показан на рис. 3.6,b. Теперь алгоритм излагается более формально.
Если на текущей плоскости при некотором заданном значении x соответствующее значение y на кривой больше максимума или меньше минимума по y для всех предыдущих кривых при этом x, то текущая кривая видима. В противном случае она невидима.
Если на участке от предыдущего (xn) до текущего (xn+k) значения x видимость кривой изменяется, то вычисляется точка пересечения (xi).
Если на участке от xn до xn+k сегмент кривой полностью видим, то он изображается целиком; если он стал невидимым, то изображается фрагмент от xn до xi; если же он стал видимым, то изображается фрагмент от xi до xn+k.
Заполнить массивы верхнего и нижнего плавающих горизонтов.
Изложенный алгоритм приводит к некоторым дефектам, когда кривая, лежащая в одной из более удаленных от точки наблюдения плоскостей, появляется слева или справа из-под множества кривых, лежащих в плоскостях, которые ближе к указанной точке наблюдения. Этот эффект продемонстрирован на рис. 3.7, где уже обработанные плоскости n - 1 и n расположены ближе к точке наблюдения. На рисунке показано, что получается при обработке плоскости n + 1. После обработки кривых n - 1 и n верхний горизонт для значений x = 0 и 1 равен начальному значению у; для значений x от 2 до 17 он равен ординатам кривой n; а для значений 18, 19, 20 - ординатам кривой n - 1. Нижний горизонт для значений x = 0 и 1 равен начальному значению у; для значений x = 2, 3, 4 – ординатам кривой n; а для значений x от 5 до 20 - ординатам кривой n - 1. При обработке текущей кривой (n + 1) алгоритм объявляет ее видимой при x = 4. Это показано сплошной линией на рис. 3.7.
3.7 Эффект зазубренного ребра
Аналогичный эффект возникает и справа при x = 18. Такой эффект приводит к появлению зазубренных боковых ребер. Проблема с зазубренностью боковых ребер решается включением в массивы верхнего и нижнего горизонтов ординат, соответствующих штриховым линиям на рис. 3.7. Это можно выполнить эффективно, создав ложные боковые ребра. Приведем алгоритм, реализующий эту идею для обеих ребер.
Обработка левого бокового ребра: Если Pnявляется первой точкой на первой кривой, то запомним Pn в качестве Pn-1 и закончим заполнение. В противном случае создадим ребро, соединяющее Pn и Pn-1. Занесем в массивы верхнего и нижнего горизонтов ординаты этого ребра и запомним Pn в качестве Pn-1.
Обработка правого бокового ребра: Если Pn является последней точкой на первой кривой, то запомним Pn в качестве Pn-1 и закончим заполнение. В противном случае создадим ребро, соединяющее Pn и Pn-1. Занесем в массивы верхнего и нижнего горизонтов ординаты этого ребра и запомним Pn в качестве Pn-1.
Теперь полный алгоритм выглядит так:
Для каждой плоскости z = const. Обработать левое боковое ребро. Для каждой точки, лежащей на кривой из текущей плоскости: Если при некотором заданном значении x соответствующее значение у на кривой больше максимума или меньше минимума по у для всех предыдущих кривых при этом x, то кривая видима (в этой точке). В противном случае она невидима
|
|||||||||
|
|
Последнее изменение этой страницы: 2020-03-26; просмотров: 167; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.136.154.103 (0.171 с.) |



 с поправкой на половину пиксела
с поправкой на половину пиксела