Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Налаштування Total CommanderСодержание книги
Поиск на нашем сайте
Після отримання інформації з реквізитами доступу до хостинг-акаунту, можна створювати FTP-з'єднання з сервером. Виклик FTP-клієнта в програмах Total Commander / Windows Commander здійснюється за допомогою комбінації клавіш CTRL+F, або через меню Net (Мережа) | FTP Connect (FTP зв’язок).
У вікні, що відкрилося, вибирається пункт «New connection» (Нове з’єднання):
У вікні, що з'явилося, заповнюються поля відповідно до наданої інформації
Session (Ім’я сесії) — назва з'єднання Host name (Ім’я хосту) — адреса FTP-сервера, наприклад, «ftp.domain.com» User name (Користувач) — системний користувач, наприклад, «login» Password (Пароль)— системний пароль При роботі через проксі-сервер, або у разі коли FTP-клієнт успішно проходить авторизацію, але видає порожній перелік файлів, слід в обов'язковому порядку вказати пасивний режим з'єднання — відзначити пункт «Use passive mode for transfers (like а WWW browser)» (Пасивний режим обміну (як у WWW броузері). Після заповнення форми натискають «OK», в результаті в списку серверів з'являється нове з'єднання:
Для установки з’єднання з сервером натискають кнопку «Connect» (З’єднати). ПОРЯДОК РОБОТИ 1. Ознайомитись з довідковою інформацію стосовно служби FTP. 2. Обрати FTP-клієнт. 3. Обрати публічний відкритий FTP-сайт. 4. Ввійти в FTP-архів як анонімний користувач (anonymous). 5. Ознайомитись з структурою та змістом обраного FTP-архіву. 6. Завантажити обраний файл. 7. Повторити дії в іншому FTP-клієнті. ЗМІСТ ЗВІТУ 1. Назва та мета виконання лабораторної роботи. 2. Використання протоколу FTP. 3. Процес входження у віддалену систему за допомогою FTP-клієнта. 4. Опис основних FTP-клієнтів. 5. Структура обраного FTP-архіва. 6. Висновки.
Лабораторна робота №5 IP-адресація міської комп'ютерної мережі відділень комерційного банку
Мета роботи: одержати навички призначення IP-адрес і розподілу міської мережі на підмережі.
Методичні вказівки Порядок призначення IP-адрес. За визначенням схема IP-адресації повинна забезпечувати унікальність нумерації мереж, а також унікальність нумерації вузлів у межах кожної з мереж. Отже, процедури призначення номерів як мережам, так і вузлам мереж повинні бути централізованими. Коли справа стосується мережі, яка є частиною Інтернету, унікальність нумерації може бути забезпечена тільки зусиллями спеціально створених для цього центральних органів. У невеликій же автономній IP-мережі умова унікальності номерів мереж і вузлів може бути виконана силами мережевого адміністратора.
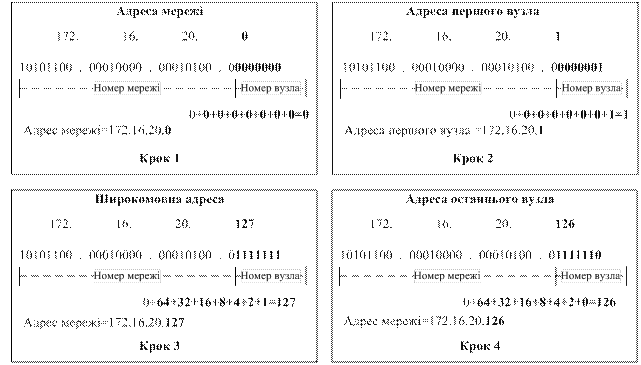
У цьому випадку в розпорядженні адміністратора є весь адресний простір, тому що збіг IP-адрес у незв'язаних між собою мережах не викличе ніяких негативних наслідків. Адміністратор може вибирати адреси довільно, дотримуючись лише синтаксичних правил, ураховуючи обмеження на особливі адреси. Однак, при такому підході виключена можливість у майбутньому приєднати дану мережу до Інтернету. Дійсно, довільно обрані адреси даної мережі можуть збігтися із централізовано призначеними адресами Інтернету. Для того щоб уникнути колізій, пов'язаних з такого роду збігами, у стандартах Інтернету визначено декілька так званих приватних адрес, які рекомендують для автономного використання: – у класі А – мережа 10.0.0.0; – у класі В – діапазон з 16 мереж – 172.16.0.0-172.31.0.0; – у класі С – діапазон з 255 мереж – 192.168.0.0-192.168.255.0. Ці адреси виключені з адрес, які розподіляються централізовано, і становлять величезний адресний простір, достатній для нумерації вузлів автономних мереж практично будь-яких розмірів. Варто також відзначити, що приватні адреси, як і при довільному виборі адрес, у різних автономних мережах можуть збігатися. У той же час використання приватних адрес для адресації автономних мереж робить можливим коректне підключення їх до Інтернету. Розглянемо приклад призначення IP-адрес у мережі. Припустимо, що необхідно призначити IP-адреси для всіх інтерфейсів в мережі, використовуючи для цього діапазон 172.16.20.0/25. На рис. 1 представлений приклад IP-адресації. На першому кроці призначається адреса мережі. Маска мережі в цьому випадку включає 25 біт, а 7 останніх біт – це біти адрес робочих станцій. В адресі мережі останні 7 біт повинні приймати значення 0. У результаті була отримана адреса мережі 172.16.20.0 з маскою 255.255.255.128. На другому кроці призначається адреса першого вузла в мережі. Адреса першого вузла в мережі є наступною адресою після адреси мережі. Для призначення першої, самої нижньої адреси вузла в мережі останній сьомий біт повинен прийняти значення 1. У результаті ми маємо адресу 172.16.20.1 з маскою 255.255.255.128.
Рисунок1 – Приклад IP-адресації
На третьому кроці визначається широкомовна адреса. У широкомовній адресі необхідно, щоб розряди вузла були встановлені в 1, тобто в даному прикладі сім останніх бітів повинні бути встановлені в 1. У такий спосіб в останньому октеті ми одержимо значення 127, що дає нам широкомовну адресу 172.16.20.127. На четвертому кроці призначається адреса останнього вузла в мережі. Адреса останнього вузла в мережі завжди менше широкомовної адреси. Це означає, що в адресі останнього вузла мережі останній біт повинен бути встановлений в 0, а при широкомовному запиті в 1. У такий спосіб адреса останнього вузла в мережі буде 172.16.20.126. Кількість вузлів даної мережі дорівнює 2n-2, де n – кількість бітів, виділених для адресації вузлів. Одна адреса віднімається, оскільки вона призначається широкомовному запитові, а одна – оскільки вона призначається адресі мережі. Тобто у нашому випадку кількість вузлів буде 27-2, що дорівнює 126. Завдання для роботи
Необхідно розробити схему IP-адресації для міської комп'ютерної мережі, яка об’єднує три відділення комерційного банку: - відділення №1 знаходиться в одноповерховому будинку; - відділення №2 – у триповерховому; - відділення №3 – у десятиповерховому будинку. Кожне відділення – це окрема підмережа. План кожного поверху відділень, а також структура комп'ютерних мереж ідентичні між собою та відповідають плану, спроектованому у лабораторній роботі №1. Також необхідно призначити IP-адресу для кожного інтерфейсу маршрутизатора або комутатора третього рівня. Для кожної підмережінеобхідно призначити: IP-адресу, маску підмережі та адресу широкомовного запиту. Після цього необхідно в рамках визначених підмереж визначити початкову й кінцеву адреси для робочих станцій. Також необхідно розрахувати кількість вузлів кожної підмережі. Для адресації використовувати мережу 192.168.0.0/16 та змінну довжину маски підмережі. Обов’язковою умовою є використання мінімальної можливої довжини хостової частини.
План виконання роботи
Для виконання даної лабораторної роботи необхідно виконати наступні дії: – визначити кількість підмереж, пам'ятаючи, що підмережі розділяються маршрутизаторами або комутаторами третього рівня; – для кожної підмережі призначити: IP-адресу, маску підмережі, адресу широкомовного запиту; – призначити IP-адресу для кожного інтерфейсу маршрутизатора або комутатора третього рівня; – у рамках підмереж для робочих станцій призначити початкову та кінцеву IP-адреси; – розрахувати максимальну кількість вузлів кожної підмережі.
Результат розрахунків оформити у вигляді таблиці (див. табл.6).
Таблиця 6 Зразок таблиці
Питання до захисту роботи 1. Дайте характеристику класу комп'ютерних мереж – «міська мережа». Які відмінні ознаки має даний клас у порівнянні із класами локальні та глобальні мережі? 2. Які апаратні пристрої дозволяють розділити мережу на підмережі? На якому рівні моделі OSI вони працюють? 3. Що таке IP-адреса? Для чого вона необхідна?
4. Які класи мереж Вам відомі? За якою ознакою розділені ці мережі? 5. Що таке маска підмережі? Яку функцію вона виконує? 6. Опишіть процедуру призначення IP-адрес. Лабораторна робота №6 ПОШУКОВИЙ СЕРВІС В ІНТЕРНЕТ Сучасний інтернет представляє унікальне безмежне сховище знань, де можна отримати відповідь практично на будь-яке питання. Фактично, тут зібрано все краще, що винайдено і створено людством як за всю його довгу історію, а також новинки, що з'явилися щойно. Проте поява такої величезної і обширної бібліотеки не може не привести до перевантаженості інформаційного простору. Фахівці по-різному оцінюють розміри Інтернету, проте в більшості сходяться на думці, що зараз тут знаходяться мільярди сторінок, причому велика частина їх зникає або оновлюється протягом нетривалого періоду часу. Чи існує яка-небудь можливість орієнтуватися в цьому практично нескінченному невичерпному швидкозмінному потоці інформації? Частково цю проблему вирішують спеціальні інформаційно-пошукові системи, які вміють самостійно збирати інформацію. Якщо розумно використати пошукову систему, можна на протязі достатньо короткого часу знайти інформацію, на пошук якої без використання Інтернет можна витратити місяці і навіть роки. Але, практика доводить, що зараз ефективно і правильно використовувати пошукові системи вміють не більше 3% чоловік і в результаті на запит з 1-2 слів отримують абсолютно даремну для себе інформацію. СКЛАДОВІ ПОШУКОВИХ СИСТЕМ Пошукові cистеми зазвичай мають три компоненти: · агент (павук, кроулер або робот), який переміщується по мережі і збирає інформацію; · база даних, яка містить інформацію, що зібрано павуками; · пошуковий механізм, який користувачі використовують як інтерфейс для взаємодії з базою даних. Засоби пошуку типу агентів, павуків, кроулерів і роботів використовуються для збору інформації про документи, які знаходяться в мережі Інтернет. Це спеціальні програми, які займаються пошуком сторінок в мережі, збирають гіпертекстові посилання з цих сторінок і автоматично індексують інформацію, яку вони знаходять для побудови бази даних. Кожний пошуковий механізм має власний набір правил, якими визначається збір документів. · Агенти є найінтелектуальнішими з пошукових засобів. Вони можуть робити більше, ніж просто шукати: вони можуть виконувати транзакції від імені користувача. Вже зараз вони можуть шукати сайти специфічної тематики і повертати списки сайтів, відсортованих за їх відвідуваністю. Агенти можуть обробляти вміст документів, знаходити та індексувати інші види ресурсів, не лише сторінки. Вони можуть бути запрограмовані для витягання інформації з вже існуючих баз даних. Незалежно від інформації, яку агенти індексують, вони передають її назад до бази даних пошукового механізму.
· Павуки здійснюють загальний пошук інформації в Інтернет. Павуки повідомляють про зміст знайденого документа, індексують його і добувають підсумкову інформацію. Вони також переглядають заголовки, деякі посилання і відправляють проіндексовану інформацію до бази даних пошукового механізму. · Кроулери переглядають заголовки і повертають тільки перше посилання. · Роботи можуть бути запрограмовані таким чином, щоб переходити по різним посиланням різної глибини вкладеності, виконувати індексацію і перевіряти посилання в документі. Але, вони можуть застрягати в циклах, адже, проходячи за посиланнями, їм потрібні значні ресурси мережі. Існують методи, що забороняють роботам пошук по сайтах, власники яких не бажають, щоби вони були проіндексовані. Агенти збирають та індексують різні види інформації. Деякі, наприклад, індексують кожне окреме слово у документі, в той час як інші індексують тільки 100 найбільш важливих слів в кожному документі, індексують розмір документу і кількість слів в ньому, назву, заголовки і підзаголовки і так далі. Вигляд побудованого індексу визначає, який пошук може бути проведений пошуковим механізмом і як отримана інформація буде інтерпретована. Агенти знаходять інформацію, після чого її розміщують в базі даних пошукового механізму. Адміністратори пошукових систем визначають, які сайти або типи сайтів агенти мають відвідати та проіндексувати. Проіндексована інформація відправляється до бази даних пошукового механізму. Користувачі можуть розміщувати інформацію прямо в індексі, заповнюючи особливу форму для того розділу, в який вони хотіли б помістити свою інформацію. Ці дані передаються базі даних. Коли користувач хоче знайти інформацію, доступну в Інтернет, він відвідує сторінку пошукової системи і заповнює форму, що деталізує потрібну йому інформацію. Тут можуть використовуватись ключові слова, дати та інші критерії. Критерії в формі пошуку повинні відповідати критеріям, які використовуються агентами при індексації інформації, яку вони знайшли при переміщені по мережі. База даних відшукує предмет запиту, що базується на інформації, яка вказана в заповненій формі, і виводить відповідні документи, що підготовані базою даних. Для того, щоб визначити порядок, в якому перелік документів буде показано, база даних застосовує алгоритм ранжування. В ідеальному випадку, розташованими першими в списку будуть документи, що є найбільш релевантними до запиту користувача. Релевантність – основне поняття при індексації документа в пошукових системах. Релевантність – міра відповідності, тобто це відповідність змісту знайденої сторінки до запиту користувача. Але комп'ютер - не людина, і тому пошукові системи використовують спеціальні алгоритми для визначення релевантности. Теоретичних методів визначення релевантності більш ніж 20. Але виділяють два основні напрями: лінгвістичне (Рамблер, Яндекс) і статистичне (Google).
Основні російські пошукові системи (зокрема Рамблер) використовують лінгвістичний напрям, тобто пошуковий робот, переглядаючи сторінку, звертає увагу на "літературність" її написання ("чом ти не прийшов" буде більш релевантною, ніж "чом ти не травень прийшов"). Різні пошукові системи використовують різні алгоритми ранжування, однак основними принципами визначення релевантності є наступні: · Кількість слів запиту у текстовому вмісті документу (тобто в html-коді). · Теги, в яких ці слова розташовуються. · Місцеположення шуканих слів у документі. · Питома вага слів, відносно яких визначається релевантність, у загальній кількості слів документу. Ці принципи застосовуються всіма пошуковими системами. А наведені нижче використовуються деякими, але достатньо відомими (наприклад, AltaVista). · Час - як довго сторінка знаходиться в базі пошукового сервера. Спочатку здається, що це недолугий принцип. Але в Інтернет існує багато сайтів, час життя яких складає близько місяця. Якщо ж сайт існує досить довго, це значить, що його власник є досвідченим за даною темою і користувачу більше підійде сайт, що існує вже кілька років, ніж той, який з'явився тиждень тому за цією ж темою. · Індекс цитованості - як багато посилань на дану сторінку веде з інших сторінок, що зареєстровані у базі пошуковика. База даних виводить ранжований таким чином перелік документів з HTML і повертає його користувачу, який зробив запит. Різні пошукові механізми вибирають різні способи показу отриманого переліку - деякі відображають лише посилання, інші виводять посилання з декількома першими реченнями документу або заголовок документу разом з посиланням. Коли користувач звертається до посилання на один з документів, цей документ завантажується з сервера, на якому він знаходиться. Велика частина цільових відвідувачів приходить саме з пошукових систем. Тому важливо знати деякі особливості найбільш популярних з них. УКРАЇНСЬКА ПОШУКОВА СИСТЕМА "МЕТА" Українська пошукова система "МЕТА" є найвідомішим проектом компанії - ЗАТ «МЕТА» - розробника пошукових і інформаційних рішень. Сьогодні "МЕТА" — один з найбільш відвідуваних українцями сайтів і найбільший рекламний майданчик України. «Мета.ua» – проект український, він створений і працюватиме тільки для України. А технології, які були створені в процесі роботи, цілком можуть бути використані в інших країнах. Пошукові технології компанії працюють у внутрішніх мережах Верховної Ради і кабінету міністрів України, на сайтах національного банку України, фонду Разумкова, сайті Віктора Ющенка. За 2005 рік аудиторія збільшилася більш ніж в два рази. «Мета» – це безкоштовний сервіс, який не має ніяких зобов'язань перед власниками сайтів і не гарантує «правильного» місця видачі. Нові сервіси пошукової системи "МЕТА" можна поділити на три типи: пошукові, інформаційні і комунікаційні. З пошукових сервісів хочеться відзначити «Метановини». Це найпопулярніший розділ після великого пошуку і каталогу. Зараз там збираються новини від більше як 200 українських інтернет-джерел, близько 10 000 новин в день. Весь цей масив в режимі реального часу індексується, групується по темах і стає доступним для пошуку. «Пошук рефератів». Практично єдиний сервіс в СНД, що дозволяє шукати не тільки по назві і опису, але і по всьому тексту. В період сесій і іспитів студенти і школярі активно користуються цим сервісом. З останніх пошукових проектів – інтерфейс до бази законодавства України, що розроблено спільно з апаратом Верховної Ради. У базі більш як 80 000 різних юридичних документів. Автоматичний переклад запитів дає можливість задавати запит на російській або українській мовах. З інформаційних сервісів цікавими є «Карти» і «Розклади потягів». В «Картах» зібрано найбільшу кількість карт по містах і областях України, що є доступними в Інтернеті, а «Розклади» – є найповнішими та найточнішими. Комунікаційні сервіси – форум, який став найбільшим українським неполітичним форумом. Поштовий сервіс розроблявся значно пізніше за тих, що є зараз на ринку, тому в ньому вдалося обійти відомі недоліки і він вийшов зручним і функціональним. Пошта зараз самий швидкозростаючий сервіс на «Мете». Пошуковому сервісу доводиться збільшувати потужність одночасно в двох площинах – з одного боку збільшується кількість запитів, з іншої - зростає об'єм індексу. З схожими проблемами працює всього декілька компаній в світі, і тому на вирішення технічних проблем, пов'язаних з швидким зростанням витрачається багато зусиль. Впроваджено і відпрацьовано технологію, що дозволяє швидко масштабувати систему, Мета може без проблем збільшити розмір індексу і обробити число запитів на порядок більше. З останніх вдосконалень – «перевірка» правопису в запитах і додавання нових форматів документів – doc, pdf, xls, ppt. «Повільна індексація» - це вже легенда, яка залишилася у минулому. Черги на розміщення в каталог зараз немає, бо технічних потужностей вистачає. Якщо сайт через 4-5 днів після додавання в каталог не потрапив в індекс, це означає, що він є або недоступним, або не піддається індексації. Окрім цього є спеціальний кластер, документи в якому оновлюються двічі у день. ПОРАДИ ПО ПОШУКУ Пошукова система "МЕТА" надає цілий ряд сервісних можливостей, які дозволяють вести більш прицільний пошук. Проте, пошукова система - тільки інструмент, і головний внесок в швидке отримання точних результатів робить користувач, коли формулює свій запит. Нижче наведено перелік пошукових прийомів, які дозволять ефективніше організувати пошук і оперативно знайти те, що потрібне.
|
|||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-10; просмотров: 199; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.85.123 (0.012 с.) |