Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Триггеры в диалекте Oracle PL/SQLСодержание книги
Поиск на нашем сайте
В Oracle возможности создания триггеров шире, чем в Informix и Transact-SQL. В этой СУБД для создания триггеров тоже используется инструкция create trigger, но структура ее иная. Подобно Informix, она позволяет связать триггер с различными этапами обработки запроса, но на трех разных уровнях: • Триггер уровня инструкции (statement) вызывается один раз для каждой инструкции SQL. Он может быть вызван до или после ее выполнения. • Триггер уровня записи (row) вызывается один раз для каждой модифицируемой записи. Он также может вызываться до или после модификации; • Замещающий триггер (instead OF) выполняется вместо инструкции SQL. С помощью такого триггера можно отслеживать попытки приложения или пользователя обновить, добавить или удалить записи и вместо этих действий выполнять свои собственные. Вы можете определить триггер, который должен выполняться вместо некоторой инструкции или вместо каждой попытки изменения строки таблицы. Всего получается 14 различных типов триггеров. Двенадцать из них — это комбинации операций insert, update и delete с опциями before или after на уровне row или statement (3x2*2) плюс еще два триггера типа instead of уровня row и statement. Однако на практике в реляционных базах данных Oracle триггеры типа instead OF применяются редко; они были введены в Oracle8 для поддержки ее некоторых новейших объектно-ориентированных функций.
Дополнительные вопросы, связанные с использованием триггеров В базах данных с триггерами могут быть связаны те же деловые правила, что и с инструкциями update и delete. Например, триггер может вызвать серию каскадных операций. Предположим, что триггер активизируется в ответ на попытку пользователя обновить содержимое таблицы. В теле этого триггера выполняется инструкция update, обновляющая другую таблицу. Триггер этой второй таблицы может обновить еще одну таблицу и т.д. Ситуация ухудшается, когда один из этих триггеров пытается обновить исходную таблицу, обновление которой и вызвало всю серию операций. В этом случае получается бесконечный цикл активизации триггеров. Вразличных СУБД эта проблема решается по-разному, водних системах ограничивается набор действий, которые могут выполняться триггерами. В других предусмотрены встроенные функции, которые позволяют триггеру определить уровень вложенности, на котором он работает. В-третьих, имеются системные установки, определяющие, допустимо ли "каскадирование" триггеров. А есть системы, которые ограничивают уровень вложенности каскадно выполняемых триггеров. Вторая проблема триггеров состоит в том, что при пакетных операциях с базой данных, например при внесении в нее больших объемов информации, триггеры сильно замедляют работу базы данных. Поэтому некоторые СУБД позволяют избирательно отключать триггеры в таких ситуациях. В Oracle, например, предусмотрена такая форма инструкции alter trigger: ALTER TRIGGER TEST DISABLE; Аналогичную возможность обеспечивает инструкция create trigger в Informix. Рассмотри пример создания триггера в СУБД Sybase SQL Anywhere.
Процедуры и триггеры хранят операторы SQL и управляющие операторы в базе данных для их использования любыми приложениями. Они улучшают безопасность, эффективность и стандартизацию баз данных.
Пример триггера уровня записи INSERT Показанный ниже триггер проверяет, что бы дата рождения (birthdate) введенная для нового сотрудника была приемлема.
CREATE TRIGGER check_birth_date
AFTER INSERT ON Employee REFERENCING NEW AS new_employee FOR EACH ROW BEGIN DECLARE err_user_error EXCEPTION FOR SQLSTATE ‘99999’; IF new_employee.birth_date > ‘June 6, 1994’ THEN SIGNAL err_user_error; END IF; END
Триггер вызывается сразу после добавления любой записи в таблицу. Он обнаруживает и не допускает новые записи в которых дата рождения позднее чем 6 июня 1994. Конструкция REFERENCING NEW AS new_employee позволяет операторам в тексте триггера ссылаться на данные в новой записи используя алиас new_employee.
Для оператора INSERT который добавляет несколько записей в таблицу employee, триггер check_birth_date вызывается для каждой новой записи. Если триггер завершается неудачно хотя бы на одной записи, все изменения сделанные оператором INSERT отменяются.
Можно определить триггер срабатывающий до того как запись будет добавлена, для этого достаточно изменить первую строку примера:
CREATE TRIGGER mytrigger BEFORE INSERT ON Employee
Выражение REFERENCING NEW позволяет ссылаться на значения добавляемой записи; и эта ссылка не зависит от типа триггера (BEFORE or AFTER).
Пример триггера уровня записи для операции DELETE.
CREATE TRIGGER mytrigger BEFORE DELETE ON employee
REFERENCING OLD AS oldtable FOR EACH ROW BEGIN ... END
Выражение REFERENCING OLD позволяет ссылаться в модуле триггера на значения в удаляемой записи с помощью алиаса oldtable. Триггер легко преобразовать к типу after путем изменения первой строки примера.
CREATE TRIGGER mytrigger BEFORE DELETE ON employee
Выражение REFERENCING OLD не зависит от типа триггера (BEFORE or AFTER).
Пример триггера уровня оператора для операции UPDATE.
CREATE TRIGGER mytrigger AFTER UPDATE ON employee
REFERENCING NEW AS table_after_update OLD AS table_before_update FOR EACH STATEMENT BEGIN ... END
Выражения REFERENCING NEW и REFERENCING OLD позволяют в тексте триггра ссылаться на старые и новые значения записи, для которой выполняется операция UPDATE. Столбцы с новыми значениями доступны через алиас table_after_update, столбцы со старыми значениями через алиас table_before_update. Выражения REFERENCING NEW и REFERENCING OLD имеют разный смысл для триггеров уровня оператора и триггеров уровня записи. Для триггеров уровня оператора REFERENCING OLD или NEW являются алиасами таблиц, в триггере уровня записи они ссылаются на изменяемую запись.
Лекция 18 Триггеры выполняются автоматически при выполнении операций INSERT, UPDATE, или DELETE для таблиц, с которыми они связаны. Триггеры уровня записи выполняются для каждой изменяемой записи, триггеры уровня оператора выполняются один раз для соответствующего оператора вне зависимости от количества изменяемых записей. Когда срабатывают INSERT, UPDATE, или DELETE триггеры, порядок выполнения операций следующий:
1 Выполняется какой-либо BEFORE триггер. 2 Выполняются действия определенные правилами ссылочной целостности. 3 Выполняется соответствующая операция. 4 Выполняются триггеры типа AFTER.
Если на любом шаге обнаруживается ошибка, которая не обрабатывается процедурой или триггером все сделанные изменения отменяются, последующие шаги не выполняются и операция, вызвавшая срабатывание триггера завершается неудачей.
Лекция 19
Концепции хранилищ данных В основе технологии хранилищ данных лежит идея о том, что базы данных ориентированные на оперативную обработку транзакций (Onlinе Transaction Рrocessing – OLTP), и базы данных, предназначенные для делового анализа, используются совершенно по-разному и служат разным целям. Первые – это средство производства, основа каждодневного функционирования предприятия. На производственном предприятии подобные базы данных поддерживают процессы принятия заказов клиентов, учета сырья, складского учета и оплаты продукции, т.е. выполняют главным образом учетные функции. С такими базами данных, как правило, работают клиентские приложения, используемые производственным персоналом, работниками складов т.п. В противоположность этому базы данных второго типа используются для принятия решений на основе сбора и анализа информации. Их главные пользователи – это менеджеры, служащие планового отдела и отдела маркетинга. Ключевые отличия аналитических и OLTP-приложений, с точки зрения взаимодействия с базами данных, перечислены в табл.
Рабочая нагрузка баз данных, используемых в аналитических и OLTP - приложениях, настолько различна, что очень трудно или даже невозможно подобрать одну СУБД, которая наилучшим образом удовлетворяла бы требованиям приложений обоих типов.
Компоненты хранилища данных
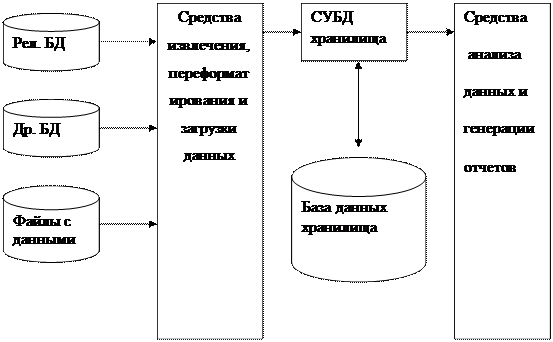
На рис. изображена архитектура хранилища данных. Выделим три ее основных компонента: средства наполнения хранилища – это программный комплекс, отвечающий за извлечение данных из корпоративных OLTP-систем (реляционных баз данных, и других систем, их обработку и загрузку в хранилище; этот процесс обычно требует предварительной обработки извлекаемых данных, их фильтрации и переформатирования, причем записи загружаются в хранилище не по одной, а целыми пакетами; база данных хранилища – обычно это реляционная база данных, оптимизированная для хранения огромных объемов данных, их очень быстрой пакетной загрузки и выполнения сложных аналитических запросов; средства анализа данных – это программный комплекс, выполняющий статистический и временной анализ, анализ типа "что если" и представление результатов в графической форме. Современные хранилища преимущественно управляются специализированными реляционными СУБД ведущих производителей рынка корпоративных баз данных.
Архитектура баз данных для хранилищ.
Структура базы данных для хранилища обычно разрабатывается таким образом, чтобы максимально облегчить анализ информации, ведь это основная функция хранилища. Данные должно быть удобно "раскладывать" по разным направлениям (называемым измерениями). Структура базы данных должна обеспечивать проведен всех типов анализа, позволяя выделять данные, соответствующие заданному набору измерений.
Кубы фактов
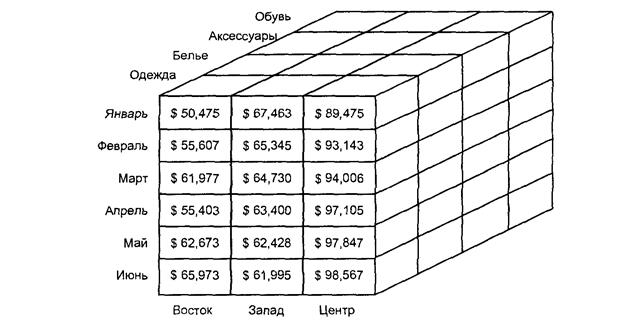
В большинстве случаев информация в базе данных хранилища может быть представлена в виде N-мерного куба фактов, отражающих деловую активность компании в течение определенного времени: Простейший трехмерный куб данных о продажах изображен на рис.
Каждая его ячейка представляет один "факт" - объем продаж в стоимостном или натуральном выражении. Вдоль одной грани куба (одного измерения) располагаются месяцы, в течение которых выполнялись отражаемые кубом продажи. Второе измерение составляют категории товаров, а третье – регионы продаж. В каждой ячейке содержится объем продаж для соответствующей комбинации значений по всем трем измерениям. В реальных приложениях используются гораздо более сложные кубы с десятью и более измерений.
Схема "звезда"
Для большинства хранилищ данных самым эффективным способом моделирования N-мерного куба фактов является схема "звезда". На рис. изображено, как выглядит такая схема для хранилища данных коммерческой компании, описанного выше. Для каждого значения измерения, таблице имеется отдельная строка.
Многоуровневые измерения
В схеме "звезда", каждое измерение имеет только один уровень. На практике же довольно распространена более сложная структура базы данных, в которой измерения могу иметь по несколько уровней.
Расширения SQL для хранилищ данных
Теоретически реляционная база данных звездообразной структуры обеспечивает хороший фундамент для выполнения запросов из области делового анализа. Возможность находить не представленную в базе данных в явном виде информацию на основе анализа содержащихся в ней значений как нельзя лучше подходит для произвольных, непрограммируемых запросов, свойственных аналитическим приложениям. Однако между типичными аналитическими запросами и возможностями базового языка SQL имеются серьезные несоответствия. Например: Сортировка данных. Многие аналитические запросы явно или неявно требуют предварительной сортировки данных. Возможны такие критерии отбора информации, как "первые десять процентов", "первая десятка", и т.п. Однако SQL оперирует неотсортированными наборами записей. Единственным средством сортировки данных в нем является предложение order by в инструкции select, причем сортировка выполняется в самом конце процесса, когда данные уже отобраны и обработаны.
Хроно логические последовательности. Многие запросы к хранилищам данных предназначены для анализа изменения некоторых показателей во времени: они сравнивают результаты этого года с результатами прошлого, результаты этого месяца с результатами того же месяца в прошлом году, показывают динамику роста годовых показателей в течение ряда лет и т.п. Однако очень трудно, а иногда и просто невозможно получить сравнительные данные за разные периоды времени в одной строке, возвращаемой стандартной инструкцией SQL. В общем случае это зависит от структуры базы данных. Сравнениение с итоговыми данными. Многие аналитические запросы сравнивают значения отдельных элементов (например, объемы продаж отдельных офисов) с итоговыми данными (например, объемами продаж по регионам). Такой запрос трудно выразить на стандартном диалекте SQL. Пытаясь решить все этих проблемы, производители СУБД для хранилищ данных обычно расширяют в своих продуктах возможности языка SQL, добавляя такие расширения: диапазоны — позволяют формулировать запросы вида "отобрать первые десять записей"; перемещение итогов и средних – используется для хронологического анализа, требующего предварительной обработки исходных данных; расчет текущих итогов и средних – позволяет получать данные по отдельны месяцам, плюс годовой итог на текущую дату и выполнять другие подобные запросы; сравнительные коэффициенты – позволяют создавать запросы, выражающие отношение отдельных значений к общим и промежуточным итогам без использования сложных подчиненных запросов; декодирование – упрощает замену кодов из таблиц измерений понятными именами (например, замену кодов товаров их названиями); промежуточные итоги – позволяют получать результаты запросов, в которых объединена детализированная и итоговая информация, причем с несколькими уровнями итогов.
Многие разработчики СУБД для хранилищ данных используют аналогичные расширения или встраивают в свои продукты специальные функции для получения нетипичных для SQL. данных. Как и в случае с другими расширениями SQL., их концептуальные возможности, предлагаемые различными разработчиками, сходны, а реализация зачастую совершенно разная.
Контрольные вопросы 1. Концепция хранилищ данных. OLTP системы и OLAP системы. 2. Сравните рабочие нагрузки OLTP и OLAP систем. 3. Перечислите типовые компоненты хранилища данных. 4. Какая архитектура БД используется для организации хранилища данных. 5. Расширения языка SQL используемые в хранилищах данных.
Литература
1) К.Дж. Дейт Введение в системы баз данных, 8-е издание.: Пер. с англ. — Москва: Издательский дом "Вильяме", 2005. 2)М. Ричардс и др. “ORACLE 7.3 Энциклопедия пользователя”. Киев, изд. Диасофт, 1997г 3)Омельченко Л. Н., Шевякова Д. А. Самоучитель Visual FoxPro 9.0. СПб: БХВ-Петербург, 2005г. 4)Дж. Грофф, П. Вайнберг. SQL: Полное руководство; Пер. с англ., Киев: Издательская группа BHV, 2001г.
Лекция 1. 2 Лекция 2. 13 Лекция 3. 25 Лекция 4. 50 Лекция 5. 61 Лекция № 6. 71 Лекция 7. 81 Лекция 8. 101 Лекция 9. 106 Лекция 10. 114 Лекция 11. 119 Лекция 12. 128 Лекция 13. 134 Лекция 14. 143 Лекция 15. 148 Лекция 16. 164 Лекция 17. 181 Лекция 18. 190 Лекция 19. 191 Литература.. 197
|
||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 472; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.21.46.129 (0.009 с.) |