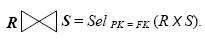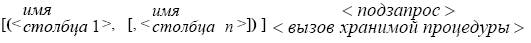Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Структура данных в РБД. Свойства столбца и ограничения таблицы. Использование ключей для идентификации строк, ссылочной целостности и логической связи строк. Индексы таблиц.
Ключ отношения – подмножество атрибутов, значения которых однозначно определяют кортеж. Один из них первичный, остальные – вторичные. Схема отношения: - имя отношения; - перечень имен атрибутов. Свойства РБД задаются через свойства тблиц и свойства(ограничения) столбцов. Поскольку отношение – множество кортежей, взятых из произведения множеств, то оно по определению не может содержать повторений, а значит, в любом отношении существует такое подмножество атрибутов, значения которых уникальны, а значит, однозначно определяют кортеж. Такое подмножество атрибутов, значения которых однозначно определяют кортеж, называют ключом отношения. В отношении может существовать несколько ключей, их называют возможными ключами. Один из возможных ключей, как правило, самый короткий, называют первичным ключом. Для отношения, можно определить структуру в виде схемы. Схема отношения R состоит из имени отношения, перечня имен атрибутов и выделенного среди атрибутов первичного ключа. В общем виде схему отношения можно записать в виде C(A1, A2,....., An), где С – имя отношения, A1, A2,..., An – имена его атрибутов. Таблицы (отношения), образующие РБД, должны обеспечивать задание ряда свойств, отражающих специфику и ограничения данных в предметной области. Свойствами таблиц РБД являются: • размещаемые в клетках таблицы данные, являющиеся неделимыми (атомарными) с точки зрения БД значениями; • значения в каждом столбце таблицы должны принадлежать одному заранее определенному множеству – домену. Домен может задаваться типом, форматом данных и ограничениями на возможные значения в пределах типа. Например, целые значения от 1 до 1000; • обязательность (NOT NULL) или необязательность (NULL) присутствия значения данного в определенном столбце; • некоторые подмножества атрибутов не допускают повторяющихся в таблице значений, например фамилия, имя, отчество и дата рождения сотрудника. Контроль выполнения этого требования также возлагается на БД; • умалчиваемое значение атрибута – данное, автоматически заносимое в таблицу, если в исходной добавляемой к таблице строке это значение отсутствует; • логические условия, которым должны удовлетворять данные в строке таблицы. Например, дата рождения меньше даты поступления в УГТУ-УПИ;
• в таблице может быть определен, а часто бывает и необходим первичный ключ – Primary Key (PK), значения которого обязательны и уникальны. Первичный ключ однозначно идентифицирует строку. Например, атрибут Название в отношении ЛАБОРАТОРИЯ можно считать первичным ключом; • в таблице могут быть определены внешние ключи – атрибуты, предназначенные для задания соответствия данных в строках из разных таблиц (ссылочной целостности). Набор атрибутов некоторой таблицы, значениями которых могут быть значения первичного ключа другой таблицы, называются внешними ключами – Foreign Key (FK). Внешние ключи обычно связывают строки вспомогательной (дочерней или детализирующей) таблицы со строками главной таблицы. • Внешние ключи образуют ссылки на другие таблицы создавая связи между ними. Множество связанных таблиц составляет схему данных. • Индексы – служебные, создаваемые СУБД таблицы для ускорения доступа к таблице БД. Индексы создаются из значений в указанных полях таблицы. Индексные значения в индексе отсортированы и поэтому ускоряют поиск данных по значению в индексе. Таким образом, схема РБД состоит из множества схем отношений, дополненных свойствами для атрибутов, а сама база является множеством отношений – таблиц с фиксированной структурой. Свойства столбцов: уникальное в пределах таблицы имя, алиас – дополнительное имя (подпись), Обязательность или необязательность присутствия значения, принадлежность значения определенному множеству (домену), умалчиваемое значение, подстановка при отображении поля списком значений Язык запросов к РБД, основанный на реляционном исчислении. Примеры запросов. Реляционное исчисление над переменными кортежами. Выражение РИ определяет новое отношение, являющееся результатом запроса к исходным отношениям. Для определения множества кортежей, создающих результат запроса, предлагается использовать определяющую функцию, записываемую в виде предиката первого порядка. Кортежи исходных отношений, для которых определяющая функция принимает значение истина, и образуют результат запроса. n –местным предикатом первого порядка называется выражение, содержащее n переменных из предметной области и обращающееся в высказывание (логическое выражение) при задании значений этим переменным. Предметные переменные связываются с кортежами исходных отношений Те кортежи отношений, для которых предикат принимает значение истина, формируют результат запроса. Выражения для запроса в РИ использует форму записи элементов множества с определяющей функцией:
{<элемент множества >| < определяющая функция – условие для элемента множества >}. Например, { x | x mod (2) ≡ 0}. Здесь x mod (2) ≡ 0 - предикат (определяющая функция). Операция x mod (2) вычисляет остаток от деления. Поэтому x mod (2) ≡ 0 является одноместным предикатом, принимающим истинное значение при четных x. Таким образом, запись { x | x mod (2) ≡ 0} определяет множество четных чисел. Общая форма записи запроса в РИ имеет вид: { t | φ (t) }, где φ(t) – формула (предикат), являющаяся условием (определяющей функцией) для t, а t – переменная, принимающая значения кортежей результирующего отношения. Формула φ(t) строится из следующих элементарных (атомарных) условий: 1. R (t) – предикат, принимающий значения истина, если переменная t является кортежом в отношении R. Тогда запись { t | R(t) } является запросом, возвращающим все кортежи отношения R; 2. u [ i ] Θ v [ j ] или u [ i ] Θ u [ j ], логическое выражение с переменными u, v, областью возможных значений которых являются кортежи каких-либо отношений, i, j – номера или имена атрибутов в отношении, тогда u [ i ] и v [ j ] - поля i -го и j -го атрибутов кортежей отношений. u [ i ] и [ j ] выполняют роль предметных переменных в предикатах определяющей функции. Как и в РА, Θ – операция бинарного сравнения элементов кортежей разных отношений (u [ i ] Θ v [ j ]) или элементов кортежа одного отношения (u [ i ] Θ u [ j ]), Θ ∈ { >, <, <=, >=, =, # }; 3. u [ i ] Θ < константное выражение > - логическое выражение для сравнения значения элемента u [ i ] (поля) кортежа в отношении со значением выражения, построенного на константах и скалярных функциях. Из перечисленных элементарных условий по следующим правилам рекурсивно строятся определяющие функции: 1 каждое элементарное условие является функцией; 2) если ψ1 и ψ2 - являются определяющими функциями, то выражения вида: ψ1 ∧ ψ2, ψ1 ∨ ψ2 и ψ1 – также являются определяющими функциями, в которых: ∧ - операция конъюнкции (логическое И), ∨ - операция дизъюнкции (логическое ИЛИ), - одноместная операция отрицания (логическое НЕ); 3) если ψ - определяющая функция, то ( ∃ s) (ψ(s)) и ∀ s () (ψ(s)) являются определяющими функциями, в которых s – обозначает предметную переменную, являющуюся кортежом отношения, связанную квантором существования - ∃или общности - ∀. Предикат ( ∃ s) (ψ (s)) принимает значения истина, если существует хотя бы одно значение предметной переменной s, для которого ψ (s) имеет значение истина. Предикат ( ∀ s (ψ(s)) принимает значения истина, если для всех значений предметной переменной s выражение ψ(s) имеет значение истина. При вычислении значений предиката первыми выполняются операции связывания переменных кванторами ∃ и ∀, затем операции сравнения (Θ), затем по старшинству, ∧, ∨ – обычные логические операции Порядок выполнения операций можно задавать скобками.
С помощью приведенных правил могут быть построены запросы, приводящие к практически бесполезным, но при этом весьма объемным результатам. Например, если правильным являетя выражение { t | R(t) }, то формально правильным в соответствии с правилом 2 является выражение { t | R (t)}. Данное выражение требует возвратить все кортежи, отсутствующие в отношении R. Ответ на такой запрос можно представить в виде разности отношения, получаемого декартовым произведением доменов, используемых атрибутами отношения R (всеми возможными кортежами) и существующими кортежами отношения R. Поскольку многие домены реальных баз задаются допустимыми типами данных, например, фамилия – строка фиксированной длины, дата рождения – произвольная дата из заданного интервала, то большинство кортежей, полученное декартовым произведением таких доменов, не имеет смысла. Поэтому в запросах { t | φ t)} РИ рассматривают подмножества определяющих функций φ(t), называемых безопасными. Безопасные определяющие функции не позволяют создавать в результате запроса данные которые не представлены в используемых отношениях БД или в самой определяющей функции. Безопасные выражения для запросов оказываются всегда вычислимы по БД.
8. Язык запросов к РБД, основанный на реляционной алгебре, примеры запросов. Носителем реляционной алгебры – объектами, над которыми выполняются операции, являются отношения. Сигнатура алгебры содержит пять основных операций. Доказано, что эти операции обладают реляционной полнотой, т.е. позволяют записать в одном выражении запрос, который определяет любое новое отношение из исходного набора отношений. Поскольку отношения являются множествами, часть операций реляционной алгебры заимствована из теории множеств. Другие операции основаны на использовании структуры кортежа, являющегося элементом отношения. Основными операциями реляционной алгебры (РА) являются: 1. Объединение отношений. Объединением отношений RUS называется отношение, состоящее из кортежей r, принадлежащих первому или второму операнду RS = { r | r ∈ R r ∈ S }. U∨ Операция объединения является коммутативной, но применима только к отношениям, имеющим одинаковые схемы (структуры). Например, если сведения по учебным лабораториям разных факультетов (1) представлены следующими, имеющими одинаковые структуры, отношениями
ЛАБОРАТОРИЯ_РТФ (Название, Изучаемый предмет, Используемое оборудование), ЛАБОРАТОРИЯ_ФТФ (Название, Изучаемый предмет, Используемое оборудование), то выражение ЛАБОРАТОРИЯ_РТФ U ЛАБОРАТОРИЯ_ФТФ создаст общий перечень учебных лабораторий на этих двух факультетах. 2. Разность отношений. Разностью отношений R \ S называется отношение, состоящее из кортежей r, принадлежащих первому отношению (R), но отсутствующих во втором отношении (S) R \ S = { r | r ∈ R r ∉ S }. ∧ Операция разности также применима к отношениям, имеющим одинаковые схемы. Например, чтобы найти лаборатории, имеющиеся на радиотехническом, но отсутствующие на физико-техническом факультете, надо выполнить запрос ЛАБОРАТОРИЯ_РТФ \ ЛАБОРАТОРИЯ_ФТФ. 3. Декартово произведение отношений. Данная операция выполняет сцепление (конкатенацию) кортежей исходных отношений. Декартовым произведением отношения R со схемой СR (A1, A2,..., An) и отношения S со схемой С S (B1, B2,..., Bm ) называется отношение со схемой С (A1, A2,..., An , B1, B2,..., Bm), кортежи которого < a, b > образованы сцеплением каждого кортежа отношения R с каждым кортежом отношения S: R × S = { < a, b > | a ∈ R b ∧∈ S }. 4. Селекция строк в отношении. Селекция отношения (Sel) - унарная операция, выполняющая фильтрацию кортежей - «горизонтальную выборку» по условию на значения данных. Операция селекции кроме отношения (R) использует параметр (F), являющийся условием фильтрации и задаваемый булевой функцией, построенной из высказываний (сравнений) вида: <атрибут в R > < сравнение > <атрибут в R > и/или <атрибут в R > < сравнение > <константа>. Здесь < сравнение > ∈ { >, <, <=, >=, =, # }. Результатом селекции является множество кортежей отношения, для которых функция F выполняется – принимает значение истина: SelF(R) = { r | r ∈ R ∧ F }. Примером операции селекции может служить запрос: Получить из отношения СТУДЕНТ все сведения о студентах радиотехнического факультета: Sel Факультет = ‘Радиотехнический’ (СТУДЕНТ). 5. Проекция отношения. Проекция отношения (Pr ) - унарная операция, реализующая выбор подмножества атрибутов (столбцов) из отношения. Операция проекции кроме отношения (R) использует параметры (i1, i2, i3,..., ik), являющиеся именами или номерами атрибутов отноше- ния R. Результатом проекции являются кортежи отношения R, в которых представлены атрибуты, заданные параметрами i1, i2, i3,..., ik: Pr i1, i2, i3,..., ik (R) = {< a1, a2, a3,..., ak > | a1 = r i1 ∧ a2 = r i2 .... a ∧∧ k = r ik }. Таким образом, проекция выполняет выборку заданных столбцов (вертикальную выборку) из таблицы – отношения. Проектирование результата предыдущего запроса позволит вывести только специальности и фамилии И.О. студентов радиотехнического факультета: Pr Специальность, Фамилия И.О. (Sel Факультет = ‘Радиотехнический’ (СТУДЕНТ)). Для сокращения длины запроса в РА вводится две дополнительные операции.
1. Условное или Θ-соединение(тэта). Θ-соединение является бинарной операцией, сцепляющей кортежи двух отношений – операндов R и S, но не каждого кортежа R с каждым кортежом S, а только, удовлетворяющих определенному условию. Для задания условия сцепления операция имеет параметр F, задаваемый булевой функцией, построенной из высказываний вида: < атрибут в R > < сравнение Θ > < атрибут в S >.
Θ - соединением отношения R со схемой СR (A1, A2,..., An ) и множеством кортежей вида a = <a1, a2, a3,..., an> с отношением S со схемой СS (B1, B2,..., Bm ) и кортежами вида b = < b1, b2, b3,..., bm > называется отношение со схемой С (A1, A2,..., An , B1, B2,..., Bm), кортежи которого
2. Естественное соединение является бинарной операцией, развивающей Θ - соединение. В естественном соединении условие связывания кортежей соответствует ограничению ссылочной целостности отношений. Одно из отношений, участвующих в операции, должно иметь внешний ключ (FК), ссылающийся на первичный ключ (РК) в другом операнде естественного соединения. Результат естественного соединения вычисляется как Θ - соединение по условию равных значений атрибутов первичного и внешнего ключей соединяемых отношений:
3. Деление отношений. R÷S=T R=R(X,Y) S=S(Y) X,Y – последовательности атрибутов T(X)=R(X,Y)÷S(Y) – частное, если T(X)×S(Y)≤R(X,Y), т.е. T(X)принадл.Px(R)
Назначение и общая структура оператора Select в SQL. Общая схема выполнения оператора Select. Примеры. Поиск и извлечение информации из таблиц базы данных выполняет оператор SELECT. Основой для оператора SELECT являются выражения реляционного исчисления. Результат запроса представляет собой набор кортежей – таблицу, построенную путем извлечения и обработки данных из строк таблиц, участвующих в запросе. Параметрами оператора задаются выражения, определяющие столбцы результирующей таблицы, исходные таблицы, способы соединения и фильтрации и строк. В первом приближении оператор SELECT имеет вид:
Список вывода: * - все столбцы из всех строк, участвующих в запросе. <Имя таблицы>.* - столбцы из этой таблицы <Имя столбца таблицы> <имя столбца>=<Выражение> <выражение>[[AS]<новое имя столбца>] Сохранение результата: SELECT Distinct State INTO States FROM authors
Select[цена]*[количество]AS[Стоимость], ‘руб.’AS[Единица изм.] From...
10. Элементы списка вывода в операторе Select Transact SQL. Назначение и использование параметра Order by. Примеры. Список вывода: * - все столбцы из всех строк, участвующих в запросе. <Имя таблицы>.* - столбцы из этой таблицы <Имя столбца таблицы> <имя столбца>=<Выражение> <выражение>[[AS]<новое имя столбца>] выполняет вычисления значения заданного выражения для каждой строки и выводит его в отдельном столбце под указанным именем.
ORDER BY – порядок сортировки строк результата -выражения; -имена; -Номера столбцов.
SELECT State, Count(*) AS [Число авторов] FROM authors ORDER BY count(*) DESC
Последний параметр оператора SELECT – ORDER BY задает порядок сортировки строк результата. Элементами ORDER BY могут быть выражения, имена или номера столбцов в списке результата запроса. Сортировка выполняется ступенчато, последовательно по элементам, перечисленным в ORDER BY. Сначала строки упорядочиваются по значениям первого элемента, заданного в ORDER BY. Затем строки с одинаковым значением первого элемента упорядочиваются по второму и т.д. Для задания порядка в каждом элементе сортировки используются опции: ASC – сортировка по возрастанию значения элемента, DESC – по убыванию. Например, для расчета числа авторов в штатах и сортировки штатов по убыванию числа авторов можно применить оператор SELECT STATE As [Штат], count(*) As [Число авторов] FROM authors GROUP BY STATE ORDER BY count(*) DESC
Типы табличных источников в операторах управления данными в SQL. Способы соединения строк в параметре From. Примеры соединений. Параметр FROM < список используемых таблиц базы > определяет источники данных, используемые для извлечения информации.Стандарт SQL предусматривает не только перечисление используемых в запросе таблиц, но и определяет способы связывания (сцепления) их строк. Спецификация таблиц, участвующих в запросе, задается следующими вариантами: 1) простое перечисление используемых таблиц, приводящее к полному перебору и сцеплению всех строк перечисленных таблиц: < таблица > [,......]; - Оператор SELECT * FROM authors, titleauthor, titles заставит сцепить каждую строку таблицы authors с каждой строкой таблицы titleauthor, а затем их с каждой строкой таблицы titles и вывести все столбцы этих трех таблиц; 2) заданием таблиц одновременно с указанием способа сцепления их строк: • < таблица > [CROSS JOIN < таблица >.......] - Данный вариант эквивалентен предыдущему и выполняет сцепление каждой строки первой таблицы с каждой строкой второй и т.д.; • < таблица 1> [INNER JOIN< таблица 2> ON<условие соединения строк>] - Здесь ключевыми словами INNER JOIN задается внутреннее соединение строк, приводящее к сцеплению только тех строк первой таблицы с теми строками второй, для которых истинно < условие соединения строк>. Условие соединения задается логическим выражением, в котором участвуют поля соединяемых таблиц. Пример внутреннего соединения Select * From Titles INNER JOIN Sales on Titles.Title_id = Sales .Title_id Запрос выведет все сведения о книгах и их продажах, но только для книг, по которым существовали продажи LEFT • < таблица 1> [RIGHT [OUTER] JOIN < таблица 2> FULL ON < условие соединения строк >....] LEFT [OUTER] JOIN − левое внешнее соединение. Строки, соединенные по правилу внутреннего соединения, дополняются строками первой (левой) таблицы, не соединяющимися со строками второй таблицы, т.е. не имеющего ни одной строки во второй таблице, для которой истинно < условие соединения строк >. При этом в полях дополняющих строк из правой таблицы выводятся значения NULL. Таким образом, при левом соединении все строки из левой таблицы обязательно включаются в результат. Те из них, которым по условию соединения не находятся соответствующие строки правого источника, однократно включаются в результат со значением NULL в полях правой таблицы. Пример левого внешнего соединения Select * From Titles LEFT JOIN Sales on Titles.Title_id = Sales .Title_id Запрос выведет все сведения о книгах и их продажах, включая и те, по которым не было существовали продаж RIGHT JOIN − правое внешнее соединение, выполняется аналогично левому соединению, только таблицы меняются ролями. В результат запроса включаются строки внутреннего соединения, дополненные строками правой таблицы, не соединившиеся по условию со строками левой таблицы. Пример правого внешнего соединения Select * From Sales RIGHT JOIN Titles on Titles.Title_id = Sales .Title_id Запрос выведет все сведения о книгах и их продажах, включая и те, по которым не было продаж FULL JOIN − полное внешнее соединение, создает соединенные строки, являющиеся объединением результатов правого и левого внешнего соединения. В качестве исходной таблицы в параметре FROM могут использоваться таблицы и представления БД, подзапросы к БД – внутренний оператор SELECT и специальные функции, создающие наборы строк. Синтаксис определения табличного источника в параметре FROM имеет следующие варианты записи: − < имя таблицы > [[AS] < алиас >]. Здесь алиас – новое имя таблицы, действующее только в пределах данного оператора. Если для таблицы в данном запросе задан алиас, то действительное имя таблицы не должно использоваться ни в каком другом параметре данного оператора. Оно повсюду должно заменяться алиасом. Использование алиаса служит двум целям: сокращению имени таблицы в тексте запроса и неоднократному использованию одной таблицы в запросе. Применяя различные алиасы, одну таблицу можно многократно использовать в операторе под разными именами, что эквивалентно созданию дубликатов таблицы перед исполнением запроса; − другой тип табличного источника – подзапрос – записывается следующим образом: <подзапрос> [AS] <алиас> [(<список из имен столбцов>)]. Здесь <подзапрос> это отдельный оператор SELECT, который создает на время выполнения запроса динамическую таблицу с именем, определяемым алиасом. Опция <список из имен столбцов> используется в подзапросе, если его столбцы в списке вывода определяются выражениями. Например, SELECT a1.* FROM (SELECT au_lname, au_fname, phone FROM authors) AS a1. Здесь а1 – псевдоним подзапроса. Данный запрос просто возвратит результат, сформированный подзапросом; − <функция набора строк> [[AS] <алиас>]. Функции набора строк используются для обращения к данным, созданным под управлением другой СУБД. Набор таких функций зависит от используемой СУБД.
Критерий отбора строк в параметре Where операторов SQL. Примеры фильтрующих запросов. Следующий параметр оператора SELECT − параметр WHERE – содержит критерий, по которому фильтруются строки, созданные параметром FROM. Критерий для отбора строк задается логическим выражением, построенным из отдельных условий (высказываний), соединяемых логическими операциями NOT, AND и OR. Используются следующие выражения для логических условий: < выражение 1 > < операция сравнения > < выражение 2>, где < выражение 1 > и < выражение 2 > могут быть любых, но одинаковых типов, для которых определены операции сравнения из множества { =, >,!>, <,!<, >=, <=, <>,!= }. Условие принимает значение истина, если выполняется сравнение для значений операндов, заданных < выражением 1 > и < выражением 2 >. 2. < выражение > [NOT] BETWEEN < выражение 1 > AND < выражение 2 > Данное условие истинно (при отсутствии NOT), если значение, вычисленное для первого параметра (< выражение >), попадает в отрезок, образованный значениями параметров < выражение 1 > и < выражение 2>. Все выражения должны принадлежать одному типу. NOT инвертирует результат операции. 3. <выражение> LIKE ‘<шаблон для проверки>’. В MS SQL Server ограничителями шаблона являются одиночные, а СУБД ACCESS двойные кавычки. Значение данного условия истинно, если значение выражения соответствует заданному шаблону. Проверка соответствия шаблону выполняется над строковыми данными, поэтому значение заданного выражения должно предварительно приводиться к строковому типу. Шаблоном является строка, содержащая обычные символы в сочетании с метасимволами. В шаблоне используются метасимволы, имеющие следующие значения: • * (для ACCESS) или % (для MS SQL Server) – любая последовательность символов. Например, шаблонам «ЗАО*» и ‘ЗАО%’ соответствуют все строки, начинающиеся на ЗАО; •? (для ACCESS) или _ (подчеркивание для MS SQL Server) – разрешает любой единственный символ в позиции, занятой данным символом; • [< символ >-< символ >] – любой символ из заданного диапазона символов используемой кодовой таблицы. Здесь знаки ‘[‘ и ‘]’ являются элементом синтаксиса, например, запись [d-f] означает любой символ из множества {d, e, f}; • [ ^ < символ >-< символ >] – инвертирование диапазона символов (только для MS SQL Server). Условие истинно, если в позиции, определяемой заданным шаблоном, стоит любой символ кроме символов приведенного диапазона. 4. < строковое выражение > [NOT] IN (< список строковых констант >). При отсутствии NOT условие истинно, если значение выражения хотя бы однократно встречается в заданном множестве констант. Например, WHERE color IN (‘Красный’, ‘Желтый’, ‘Зеленый’). 5. < строковое выражение > [NOT] IN (< подзапрос >) Подзапрос должен возвращать таблицу из одного столбца. В отсутствие NOT условие истинно, если значение выражения хотя бы однократно встречается в столбце, созданном подзапросом. В подзапросе также могут использоваться поля табличных источников основного запроса. 6. < выражение > IS NULL/NOT NULL проверяет, имеет ли выражение какое-либо значение. Данное условие обычно используется для проверки, присутствует (введено) ли какое-либо значение в поле таблицы. Проверка отсутствия данных путем сравнения (‘=’) со значением NULL вместо операции IS в общем случае неверна. 7. EXISTS (< подзапрос >) Проверяет факт наличия результата подзапроса. Принимает значение истина, если подзапрос возвращает хотя бы одну строку. Поскольку данные подзапроса значения не имеют, в списке столбцов подзапроса обычно используют символ * в следующем виде: SELECT * FROM …. 8. < выражение > < операция сравнения> ALL/ANY (< подзапрос >) Подзапрос должен возвращать таблицу, состоящую из одного столбца. Для опции ALL (все) условие истинно, если сравнение выполняется для всех значений, возвращаемых подзапросом. Для опции ANY (любой) условие истинно, если сравнение выполняется хотя бы для одного значения, формируемого подзапросом. 9. < выражение > < операция сравнения > (< подзапрос >) Подзапрос должен возвращать единственное значение – таблицу, имеющую один столбец и одну строку. Результат подзапроса, содержащий несколько строк, будет генерировать ошибку времени выполнения. Условие истинно, если сравнение истинно для значения, созданного подзапросом. Назначение и использование агрегатных функций, параметров Group by и Having оператора Select. Примеры группирующих запросов.
Следующий параметр оператора SELECT − параметр GROUP BY – требует группировки строк в результате запроса. Группировка – объединение нескольких строк результата запроса, составляющих группу, в одну строку. Условием образования группы является совпадение значений в заданных столбцах (группирующих выражениях) оператора SELECT. Общая структура оператора SELECT с группировкой строк такова: SELECT < групп.выр.1 >,….,< групп.выр. n >, < агр.выр.1 >, …,< агр.выр. m > FROM.... WHERE... GROUP BY [All] < групп. выр.1 >,…. < групп. выр.n > Список элементов в параметре GROUP BY должен быть согласован со списком столбцов самого оператора SELECT. Параметр GROUP BY должен содержать элементы из списка столбцов, по которым образуются группы строк. Кроме группирующих элементов (< групп.выр.1 >,..) в списке вывода могут содержаться элементы, задающие групповую обработку – агрегатные выражения (агр. выр. 1,...), приводящие к вычислениям на множестве строк, попадающих в одну группу. Агрегатные выражения строятся с помощью агрегирующих функций, которые вычисляют общий результат на множестве значений для группы. Основные агрегирующие функции: COUNT (*) – подсчитывает количество строк в группе; COUNT ALL\DISTINCT <выражение> - подсчитывает количество всех (ALL) или только разных (DISTINCT) значений выражения на строках группы. По умолчанию действует опция ALL; SUM ALL\DISTINCT <выражение> - вычисляет суммарное значение заданного выражения на строках каждой группы; AVG ALL\DISTINCT <выражение> - вычисляет среднее значение выражения на всех строках группы (ALL) или только на различающихся значениях выражения (DISTINCT). DISTINCT предварительно удаляет дубликаты значений; MAX ALL\DISTINCT <выражение> – вычисляет максимальное значение выражения для каждой группы; MIN ALL\DISTINCT <выражение> – вычисляет минимальное значение в группе. Примером использования группировки может служить запрос, вычисляющий по таблице authors количество авторов, проживающих в каждом штате SELECT STATE As [Штат], count(*) As [Число авторов] FROM authors GROUP BY STATE. Если в параметре GROUP BY используется опция ALL совместно с агрегирующими выражениями, то будут выводиться все возможные группы, даже не удовлетворяющие критерию, заданному параметром WHERE, со значением NULL агрегирующих выражений, соответствующих группам, не удовлетворяющим критерию. Агрегатные функции могут применяться и без использования группировки. В этом случае они вычисляют значения на всем множестве строк таблицы. Например, оператор Select Count(*) From authors возвратит число строк в таблице authors. Следующий параметр HAVING в операторе SELECT предназначен для селекции групп перед выдачей результата запроса. Поэтому параметр HAVING без GROUP BY не используется. Он содержит критерий для фильтрации групповых строк. Критерий представляет собой логическое выражение, аналогичное WHERE, но применяемое к образованным в запросе группам.
14. Операторы UNION [ALL], EXCEPT, INTERSECT. Примеры. Оператор UNION Объединяет в общий результат множества строк, созданных отдельными операторами SELECT, и поэтому используется только за предшествующим оператором SELECT или UNION. Оператор UNION содержит запрос SELECT, результирующие строки которого присоединяются к результату предыдущих операторов. Схема использования оператора UNION имеет вид: SELECT … UNION [ALL] SELECT … [ UNION [ALL] SELECT … ........................... ] Опция ALL сохраняет в объединенном результате запроса повторяющиеся строки. По умолчанию дубликаты строк удаляются. Поскольку UNION добавляет строки к предыдущему набору, все операторы SELECT должны создавать строки одинаковой структуры с одинаковыми или автоматически конвертируемыми форматами данных. При этом имена столбцов результата берутся из первого оператора SELECT, а параметры ORDER BY и GROUP BY, задающие общий порядок и группировку результата, разрешено использовать только в последнем операторе UNION SELECT
EXCEPT – разность запросов <запрос1> EXCEPT <запрос2> Строки первого запроса, отсутствующие во втором запросе. INTERSECT – пересечение запросов <запрос1> INTERSECT <запрос2> Строки, присутствующие и в первом, и во втором запросах.
15. Структура, назначение параметров и примеры использования оператора INSERT. Примеры применения.
Оператор INSERT Оператор INSERT добавляет новую строку (строки) в таблицу БД. Включение новых строк можно выполнить непосредственно в таблицу, представление БД или функцию набора строк, но данные, тем не менее, помещаются в физически хранящуюся таблицу базы. Одним оператором можно добавить строку только в одну таблицу. INSERT <имя дополняемой таблицы>
Первым параметром в операторе INSERT указывается имя дополняемой таблицы. Далее в операторе INSERT в круглых скобках через запятую могут быть перечислены имена столбцов, значения которых определяются следующим параметром оператора. Если имена столбцов в операторе не заданы, то они выбираются из структуры таблицы. Следующий параметр VALUES определяет значения полей добавляемой строки. Через запятую задаются значения для каждого столбца в последовательности их перечисления в операторе. Отдельное значение поля добавляемой строки может быть представлено вычисляемым выражением, признаком NULL или ключевым словом DEFAULT. DEFAULT заносит в поле умалчиваемое значение, заданное для столбца в структуре таблицы. Последовательность и количество значений в VALUES должны соответствовать списку имен столбцов. С помощью параметра VALUES одним оператором можно добавить только одну строку. В другой форме оператора INSERT добавляемые строки вместо параметра VALUES определяются подзапросом или хранимой процедурой базы (для MS SQL Server). INSERT <имя таблицы>
Например, чтобы добавить записи об авторах, живущих в Калифорнии (state = ‘CA’), из таблицы authors в существующую таблицу new_authors можно применить следующий оператор SQL: INSERT new_authors SELECT * from authors WHERE state = ‘CA’ Структуры таблиц authors и new_authors должны совпадать. Используя подзапрос или хранимую процедуру, одним оператором INSERT можно добавлять в таблицу сразу несколько строк. При этом структура строк, созданных подзапросом или процедурой, должна соответствовать заданному в операторе списку из имен столбцов дополняемой таблицы. При любом способе добавления строк столбцы со свойством NOT NULL обязательно требуют наличия данных, а столбцы со свойством IDENTITY (инкрементное поле - счетчик), напротив, не должны иметь данных.
16. Структура, назначение параметров и примеры использования операторов DELETE, TRUNCATE. Оператор DELETE Оператор DELETE используется для удаления строк из таблицы БД. Одним оператором можно удалить строки только из одной таблицы. DELETE [FROM] <имя таблицы> [ FROM< список используемых таблиц базы
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 212; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.67.251 (0.225 с.) |