
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Распределенные архитектуры БД принято подразделять по типам наСодержание книги
Поиск на нашем сайте
Распределенные базы данных (РБД) Термины и определения: 1) Системы управления удаленными (распределенными) базами данных – СУБД, обеспечивающие возможность одновременного доступа к информации различным пользователям. 2) Архитектура БД – организация взаимодействия аппаратных средств. 3) Модели данных – схемы, характеризующие базы данных с различных сторон с целью определить оптимальное построение информационной системы. 4) Ядро базы данных – внутренняя структура СУБД, обеспечивающая доступ ко всем компонентам базы данных. 5) Логическая структура БД – определение БД на физическом независимом уровне. 6) Топология БД – схема распределения физической организации базы данных в сети. Классификация баз данных К концу 80-х годов возникли новые условия работы для БД: большие объемы информации возникают во многих местах (например, розничная торговля, полиграфическое и другие производства); источником большого количества данных мог быть и центр, но к этим данным требуется быстрый доступ с периферии (географически распределенное производство, работающее по одному графику). К тому же данные могут запрашиваться и центром, и удаленными потребителями в удаленных местах. Имеется большое количество данных, которые используются в срочных запросах, чаще всего местного характера (продажа авиа- и железнодорожных билетов). По технологии обработки данных базы данных подразделяются на централизованные и распределенные. Централизованные БД, особенно построенные на классическом подходе, не могли удовлетворить новым требованиям. Быстрое распространение сетей передачи данных, резкое увеличение объема внешней памяти ПК при ее удешевлении в 80-е годы способствовали широкому внедрению РБД. Решением этой проблемы являются распределенные базы данных (РБД), которые сегментируют хранимую информацию и перемещают отдельные ее блоки ближе к нужным клиентам. Доступ к базе данных от прикладной программы или пользователя производится путем обращения к клиентской части системы Распределенная база данных (РБД) - система логически интегрированных и территориально распределенных БД, языковых, программных, технических и организационных средств, предназначенных для создания, ведения и обработки информации. К достоинствам РБД относятся: 1) соответствие структуры РБД структуре организаций; 2) гибкое взаимодействие локальных БД; 3) широкие возможности централизации узлов; 4) непосредственный доступ к информации, снижение стоимости передач (за счет уплотнения и концентрации данных); 5) высокие системные характеристики (малое время отклика за счет распараллеливания процессов, высокая надежность); 6) модульная реализация взаимодействия, расширения аппаратных средств, возможность использования объектно-ориентированного подхода в программировании; 7) возможность распределения файлов в соответствии с их активностью; 8) независимые разработки локальных БД через стандартный интерфейс. К недостаткам распределенных баз данных можно отнести то, что возрастает сложность управления ими, т.к. РБД обладают более сложной структурой, что вызывает появление дополнительных проблем (избыточность, несогласованность данных по времени, согласование процессов обновления и запросов, использования телекоммуникационных ресурсов, учет работы дополнительно подсоединенных локальных БД, стандартизация общего интерфейса) согласования работы элементов. Серьезные проблемы возникают при интеграции в рамках РБД однородных (гомогенных) локальных БД с одинаковыми, чаще всего реляционными, моделями данных. Проблемы значительно усложняются, если локальные БД построены с использованием различных моделей данных (неоднородные, гетерогенные РБД). Но преимуществ все же больше. Главное из них — повышение производительности. Данные быстрее обрабатываются несколькими серверами, а кроме того, данные располагаются ближе к тем пользователям, которые чаще с ними работают. Система становится более устойчивой, если она способна выдержать сбой одного из своих компонентов. Пример. В компьютерном интегрированном полиграфическом производстве необходимой является РБД (рис.1), связывающая в единое целое процесс управления комплексом различных технологических процессов. Здесь осуществляется работа не с одним, а с системой приложений.
Рис.1 РБД должна обладать (требования):
Состав и работа РБД Схема РБД может быть представлена в виде, показанном на рис.4. В ней выделяют пользовательский, глобальный (концептуальный), фрагментарный (логический) и распределенный (локализационный) уровни представления данных, определяющие сетевую СУБД.
Рис.4. Схема РБД
Общий набор (система таблиц) данных, хранимых в РБД, показан в табл.2. Таблица 2.
Это глобальный уровень, который определяется при проектировании теми же методами, что и концептуальная модель централизованной БД. Не все данные глобального уровня доступны конкретному пользователю. Наиболее полные данные (пользовательский, внешний уровень) имеются в узле 1 головного предприятия. В узлах (участках) 2, 3 данные менее полные. Так, в узле 3 они имеют вид, показанный в табл.3.
Таблица 3
Пользовательский уровень состоит из фрагментов (например, строки A, B, C, 1, 2, 3 или столбцы табл. 12.1) глобального уровня, которые составляют фрагментарный, логический уровень. Выделяют горизонтальную и вертикальную фрагментацию (расчленение). Горизонтальное фрагментирование связано с делением данных по узлам. Горизонтальные фрагменты не перекрываются. Вертикальная фрагментация связана с группированием данных по задачам. Фрагментация чаще всего не предполагает дублирования информации в узлах. В то же время при размещении фрагментов по узлам (локализации) распределенного уровня в узлах разрешается иметь копии той или иной части РБД. Так, например, локализация для примера в табл. 12.1. может иметь вид, показанный в табл. 4. Таблица 4. Локализация данных
Очевидно, что для таблицы «Завод» осуществляется дублирование, а для таблицы «Сырье» - расчленение. После размещения каждый узел имеет локальное, узловое представление (локальная логическая модель). Физическую реализацию (логического) фрагмента называют хранимым фрагментом. Иначе говоря, РБД можно представить в виде, показанном на рис. 5. Сеть в РБД образуют сетевые операционные системы (например, Windows NT, Novell NetWare). В качестве СУБД, изначально предназначавшихся для использования в сети, следует назвать BTrieve, Oracle, Interbase, Sybase, Informix. В силу распределенности данных особую значимость приобретает словарь данных (справочник) РБД, который в отличие от словаря централизованной БД, имеет распределенную, многоуровневую структуру. В общем случае могут быть выделены сетевой, общий внешний, общий концептуальный, локальные внешние, локальные концептуальные и внутренние составляющие словаря РБД.
Рис. 5. Уровни представления данных в РБД
Естественно, что для работы в РБД необходимы администраторы РБД и локальных БД, рабочими инструментами которых являются перечисленные словари. Схема работы РБД показана на рис. 6. Пользовательский запрос, определяемый приложением, поступает в систему управления распределенной базы данных (СУРБД) и через сетевую и локальную операционные системы попадает в локальную СУБД. Если запрос связан с локализованными данными, СУБД осуществляет вызов данных из локальной БД, которые поступают пользователю. Если часть данных для выполнения приложения находится в другой локальной БД, локальная СУБД дополнительно через локальные и сетевые операционные системы осуществляет удаленный вызов процедуры (Remote Procedure Call - PRC), после выполнения, которой данные передаются пользователю. Важнейшей является задача распределения функций. По самой сути технологии на сервере расположена БД, а на компьютерах-клиентах - приложения. Однако при прямолинейных процедурах обеспечения целостности и запросах в сети может возникнуть объемный сетевой трафик. Чтобы его снизить, возможно, использовать следующие рекомендации. 1. Обеспечение целостности для всех приложений лучше централизовать и осуществлять на сервере. Это позволит не только сократить трафик, но и рационально использовать СУРБД, улучшив управление целостностью (ссылочной, ограничений, триггеров) данных. 2. Целесообразно использовать на сервере хранимые процедуры, совокупность которых можно инкапсулировать в виде пакета (модуля). В результате трафик уменьшится: клиент будет передавать только вызов процедуры и ее параметры, а сервер - результаты выполнения процедуры. 3. В ряде случаев клиентам следует получать уведомления базы данных (например, заведующему складом - о нижнем уровне запасов, при котором следует выполнять новый заказ). Если уведомление производится по запросу клиента, трафик увеличивается. Проще эту (хранимую) процедуру разместить на сервере, который будет автоматически уведомлять клиента о возникновении события. В то же время клиент при необходимости может получать информацию с помощью простых вызовов процедур.
Рис. 6. Схема работы РБД
Контрольные вопросы 1. Каковы новые требования к БД? 2. Что такое «распределенная база данных - РБД»? 3. Что такое локальный и удаленный доступ? 4. Каковы сетевые уровни представления данных? 5. Перечислите стратегии хранения, их достоинства и недостатки, рекомендации по выбору стратегии. Что такое однородные и неоднородные РБД? Особенности интеграции локальных БД в РБД. 6. Задачи администратора системы. Распределенные базы данных трудно проектировать и обслуживать. Порядок работы в системе может со временем поменяться что повлечет за собой изменение схемы хранения данных. Как клиенты, так и серверы должны уметь обрабатывать запросы к данным, которые не расположены в ближайшей системе. Плохо спроектированная РБД может демонстрировать меньшую производительность, чем одиночный сервер. Принципы построения РБД.
Критерии построения РБД.
В рассмотрении РБД возможно выделить два случая работы: с одним приложением и с системой приложений. Возможно нисходящее и восходящее проектирование. Восходящее проектирование используется обычно в случае, когда РБД создается из уже работающих, локальных БД. Восходящее проектирование может быть этапом нисходящего проектирования, которое в силу того, что оно применяется гораздо чаще, обсудим подробнее. В общем случае целостность данных может нарушаться по следующим основным причинам: 1) ошибки в создании структуры локальных БД и их заполнении; 2) просчеты в построении структуры РБД (процедуры фрагментации и локализации); 3) системные ошибки в программном обеспечении взаимодействия локальных БД (одновременный доступ); 4) аварийная ситуация (неисправность технических средств) и восстановление РБД. Специфика позиций для РБД может быть зафиксирована в виде совокупности проблем (рис. 7). Иногда к нарушению целостности относят умышленное искажение информации, т.е. несанкционированный доступ. Эти вопросы будут рассмотрены позднее.
Рис. 7. Проблемы РБД
Использование РБД В использовании РБД возможно выделить управление работой БД (одновременный доступ, защита, восстановление), определяемые используемой СУБД, и доступ к данным (запросы). Одновременный доступ Особенностью РБД является многопользовательский распределенный доступ к данным. Сложность доступ к данным для РБД состоит в том, что механизм управления в одном узле не может в общем случае знать в каждый момент времени о взаимодействии с другими узлами. К тому же в узлах могут находиться и копии данных других локальных БД. Взаимодействие элементов в РБД осуществляется посредством транзакции, которая становится распределенной (рис. 8) и, воздействуя на целостную БД, после своего завершения оставляет БД целостной. В транзакции выделяют две команды: читать (R) и писать-обновлять (W). Здесь справедливы: синхронизация, расписание, последовательностноподобное расписание (ППР), конфликт, рестарт. Напомним, что две транзакции вступают в конфликт, если они работают с одним и тем же общим элементом данных и по крайней мере одна из них реализуется операцией «писать» (запись). В СУРБД в каждом узле ведется свое расписание. Вектор расписаний всех узлов назовем распределенным расписанием (РР). Последовательное РР (ПРР) - это РР, в котором каждая составляющая последовательна. Последовательностноподобное РР (ППРР) эквивалентно ПРР.
Рис. 8.. Распределенная модель транзакции: Ti (суб) транзакции Существует несколько методов синхронизации. I. Блокировка, которая может быть: 1) с главным узлом; 2) с заданием блокировки с помощью предикатов; 3) с главной копией. II. Голосование по большинству. III. Метод предварительного анализа конфликтов. Восстановление РБД Если РБД обеспечивает целостные, непротиворечивые данные, говорят об ее корректном состоянии (корректности). Восстановление (управление восстановлением) связано с приведением системы в корректное состояние после (аппаратного) сбоя. Любой конкретный метод восстановления реагирует на определенный отказ РБД. В РБД возможны отказы узлов или сети связи. Поскольку над помехоустойчивостью сетей работают давно и успешно, чаще всего при рассуждениях считают сеть надежной. Воспользуемся пока этим предположением, считая ненадежными узлы. Система восстановления решает две группы задач: 1) при незначительной неисправности - откат в выполнении текущей транзакции; 2) при существенных отказах - минимизация работы по восстановлению РБД. Наиболее часто для целей восстановления используется системный журнал регистрации. При применении двухфазной транзакции вводится точка фиксации, когда принимается решение о фиксации транзакции. Для выполнения фиксации или отката используется информация журнала регистрации (блокировок, отмен и повторов). Копирование изменений возможно после закрытия БД. Однако для РБД с интенсивными обновлениями копирование (архивацию) следует проводить в процессе работы РБД. Журнал может содержать одну или более групп файлов регистрации и членов групп для физического сохранения изменений РБД. Любая группа включает один или более файлов, которые могут храниться на разных дисках, как это делается в СУБД Oracle. Процедура восстановления проводится следующим образом. 1. Устраняется аппаратный сбой. 2. Восстанавливаются испорченные файлы данных путем копирования архивных копий и групп регистрации транзакций. 3. Запускается процесс восстановления: а) с применением транзакций (применение к архивным копиям испорченных данных необходимых групп журнала транзакций); б) с отменой - отмена незавершенных транзакций, оставшихся после восстановления с применением транзакций. Нетрудно видеть, что процесс восстановления тесно связан с процедурой одновременного доступа (параллельного выполнения), который чаще всего организуется с помощью двухфазной транзакции. Условия работы РБД и система запоминаний транзакций определяют систему восстановления пропущенных (отказавшим узлом) транзакций и их последующее выполнение. Оптимизация запросов Если структура запросов заранее известна (стандартна), то эффективность процесса запроса определяется на описанных ранее этапах фрагментации и локализации. Если же структура запросов неизвестна, возникает необходимость оптимизации процесса запросов. Это особенно актуально при наличии параллельной обработки данных. Целями (целевыми функциями) оптимизации могут быть: 1) минимум времени передачи данных; 2) минимум времени обработки данных в узлах; 3) увеличение параллельности при обработке и передачах данных; 4) улучшение трафика и загрузки процессоров в сети; 5) минимум стоимости (задержки) только передачи данных (если имеются низкоскоростные каналы связи); 6) минимум стоимости локальной обработки (если скорость передачи данных соизмерима с быстродействием процессора); 7) выравнивание нагрузки компьютеров. Для характеристики затрат на запросы используются два параметра: стоимость обработки и задержку данных. Стоимость ТС обработки данных объема x, пересылаемой в узел i из узлов j и связанной с эксплуатацией физических каналов связи, составляет
где Задержка TD(x) - время между началом и окончанием обработки запроса:
где Примем такие предположения: 1) каналы связей однородны ( 2) стоимость передачи высока и затратами на локальную обработку можно пренебречь (учитываются параметры только передачи данных). Оптимизация запроса может быть разделена на два этапа: 1) глобальная оптимизация, которую далее будем называть просто оптимизацией; 2) локальная оптимизация, Для описания сути оптимизации используется аппарат реляционной алгебры (РА) с ее эквивалентными преобразованиями, позволяющими в результате сократить время ответа на запрос. Переменными оптимизации могут служить выбор физических копий и назначение узлов при выполнении операций РА. Используем дерево запросов, в котором каждому из листов соответствует отношение, каждой вершине - операция РА. Конечной вершине соответствует узел РБД (локальная БД), а ответу на вопрос - корневая вершина. Возможно строгое решение задачи оптимизации, чаще всего сводящееся к задаче целочисленного программирования. Однако при ее решении встречаются серьезные затруднения (большой объем данных задачи и потребность значительного свободного ресурса, дефицит времени решения) и выигрыш по сравнению с эвристическими алгоритмами, как правило, невелик. К тому же на решение влияют такие трудно учитываемые факторы, как топология сети, протоколы передачи данных, модели и схема размещения данных. В связи с этим используем эвристический подход к оптимизации. Стоимость и время пересылки данных можно сокращать за счет снижения объема передаваемой информации. В этой связи возможны следующие рекомендации. 1. Унарные операции необходимо выполнить как можно ранее (в узлах). Это иллюстрирует рис. 9.
Рис. 9. Использование унарных операций 2. Многократно встречающиеся выражения лучше выполнить один раз. Для этого в дереве запроса проводится слияние листьев-отношений, затем - слияние одинаковых промежуточных операций (рис. 10).
Рис. 10. Выделение общих подвыражений: а - исходный; в - преображенный запрос Здесь используется очевидное выражение DF(T, SNF (T))=SF (T), NF=NOT F. 3. Использование полусоединения. Идея полусоединения иллюстрируется на рис. 11.
Рис. 11. Использование полусоединения При традиционной схеме либо R надо пересылать в узел 2, либо S - в узел 1 (пунктирная линия). Можно пересылать лишь один раз S, сокращенную в помощью проекции, в узел 1 и затем осуществлять полусоединение. Покажем сказанное на примере. Пусть даны следующие отношения:
Имеются следующие возможности. Переслать S из узла 2 в узел 1 (24 значения). Вычислить r'=Рв (r) в узле 1 и переслать его в узел 2, где вычислить s'=J(r', s) и отправить в узел 1. Там найти J(r, s) как J(r, s'), т.е. получить полусоединение. Передается уже 9 + 6 = 15 значений. Напомним, что полусоединение r и s или SJ(r, s) есть РR (J(r, s)), Rеr. Если отношения r и s находятся в разных узлах, то вычисление полусоединения уменьшает объем передаваемых данных. Заметим, что для полусоединения справедливо J(SJ(r, s), s). Иногда полусоединение может полностью заменить соединение. Отметим, что полусоединение чаще применяется при вертикальной фрагментации. 4. Стратегия использования копий (доступа). Она осуществляется на физическом уровне. Определить лучший вариант при их значительном количестве возможно только с помощью моделирования. Пусть учитываются только затраты передачи данных и имеются матрицы стоимости или времени передач. Значения матрицы могут быть определены точно, а размеры отношений - приближенно. Здесь, следовательно, необходимо использовать приближенные методы. Вводят понятие «профиль», который включает: 1) мощность (количество полей) отношения R; 2) «ширину» (число байтов) любого атрибута; 3) число различных значений атрибута в отношении R. Используют метод оценки размеров промежуточных отношений для каждой операции реляционной алгебры. Для решения вопроса о выборе копий и назначении узлов выполнения удобно строить граф оптимизации, который не содержит унарных операций, выполняемых в узлах. Операции декартова произведения и разности встречаются редко, чаще имеют место операции объединения и соединения. Таким образом, задача оптимизации запроса отличается неоднозначностью решения. Следует заметить, что задача оптимизации должна решаться регулярно и оперативно. Это требует от разработчика построения специальных программ и потому делается далеко не всегда. Чаще отработанный алгоритм оптимизации закладывается при проектировании разработчиками СУРБД: непосредственно в системе управления, при создании специальных программных продуктов в виде приложений или утилит.
Контрольные вопросы 1. Как осуществляется локализация? по каким критериям? как определить количество необходимых копий в узлах? 2. Что такое интеграция в РБД? однородная? неоднородная? 3. Какой математический аппарат можно использовать для анализа интеграции? 4. В чем отличие математического описания физической системы и системы локальных БД? 5. Какие вы знаете программные средства для обеспечения однородной интеграции? 6. Как обеспечивается неоднородная интеграция?
Система клиент/сервер Совместно с термином «клиент/сервер» используются три понятия. 1. Архитектура: речь идет о концепции построения варианта РБД. 2. Технология: говорят о последовательности действий в РБД. 3. Система: рассматриваются совокупность элементов и их взаимодействие. Технология клиент/сервер позволяет повысить производительность труда: 1) сокращается общее время выполнения запросов за счет мощного сервера; 2) уменьшается доля и увеличивается эффективность использования клиентом (для вычислений) центрального процессора; 3) уменьшается объем использования клиентом памяти «своего» компьютера; 4) сокращается сетевой трафик. К таким крупномасштабным системам предъявляются следующие требования: 1) гибкость структуры; 2) надежность; 3) доступность данных; 4) легкая обслуживаемость системы; 5) масштабируемость приложений; 6) переносимость приложений (на разные платформы); 7) многозадачность (возможность выполнения многих приложений). В системе клиент/сервер, возможно, выделить следующие составляющие: сервер, клиент, интерфейс между клиентом и сервером, администратор. Средство передачи данных между клиентом и сервером - сеть (коаксиальный кабель, витая пара) с сетевым (сетевая операционная система - СОС) и коммуникационным программным обеспечением. В качестве СОС могут использоваться Windows NT, Novell NetWare (чаще всего при применении DOS). Коммуникационное программное обеспечение позволяет компьютерам взаимодействовать на языке специальных программ - коммуникационных протоколов. Система клиент/сервер своеобразна: с одной стороны, ее можно считать разновидностью централизованной многопользовательской БД, с другой стороны, она является частным случаем РБД. Характерная особенность архитектуры клиент-сервер является перенос вычислительной нагрузки на сервер БД(SQL сервер), а также максимальная разгрузка клиента от вычислительной работы и существенное укрепление данных В основе архитектуры клиент-сервер лежит идея разделения ресурсов, что приводит к функциональному выделению компонентов сети: Рабочая станции (клиент ) предназначена для непосредственной работы пользователей, запрашивающий услуги у некоторого сервера. Клиент в типичной конфигурации клиент/сервер - это автоматизированное рабочее место, использующее графический интерфейс (Graphical User Interface - GUI). Сервер предназначен для хранения, передачи и распределения информации между клиентами. Сервер локальной сети предоставляет ресурсы (услуги) рабочим станциям и/или другим серверам. Сервер БД — информационная система, осуществляющая работу с данными, регламентирующая доступ к ним и призванная обеспечить их сохранность при помощи резервирования. Сервер БД обслуживает базу данных и отвечает за целостность и сохранность данных, а также обеспечивает операции ввода-вывода при доступе клиента к информации. Чтобы прикладная программа, выполняющаяся на рабочей станции, могла запросить услугу у некоторого сервера, требуется некоторый интерфейсный программный слой, поддерживающий такого рода взаимодействие. Из этого и вытекают основные принципы системной архитектуры "клиент-сервер". Технология “клиент-сервер” применительно к СУБД сводится к разделению системы на две части – приложение-клиент (front-end) и сервер базы данных (back-end). Графический интерфейс пользователя стал стандартом для систем “клиент-сервер”. Кроме того, архитектура “клиент-сервер” значительно упрощает и ускоряет разработку приложений за счет того, что правила проверки целостности данных, находятся на сервере. Неправильно работающее клиентское приложение не может привести к потере или искажению данных Логическая модель РБД Логическая модель РБД строится на 3-х уровнях (слоях) абстракции данных: представления информации, обработки (бизнес-логики) и хранения. Слои образуют строгую иерархию: слой бизнес -- логики взаимодействует со слоями хранения и представления. Физически, слои могут входить в состав одного программного модуля, или же распределяться на нескольких параллельных процессах в одном или нескольких узлах сети. Каждый слой обрабатывается соответственно функциями стандартного интерактивного приложения. На верхнем уровне абстрагирования взаимодействия клиента и сервера достаточно четко можно выделить следующие компоненты: · слой представления информации; функции ввода и отображения данных или презентационная логика (Presentation Layer- PL); -- Обеспечивает интерфейс с пользователем. Как правило, получение информации от пользователя происходит посредством различных форм. А выдача результатов запросов - посредством отчетов. · слой бизнес-логики; прикладные функции, характерные для данной предметной области или бизнес-логика (Business Layer- BL); -- Связующий, именно он определяет функциональность и работоспособность системы в целом. Блоки программного кода распределены по сети и могут использоваться многократно (CORBA, DCOM) для создания сложных распределенных приложений. · слой хранения данных; фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т.д.) или логика доступа к ресурсам (Accesss Layer – AL) -- Обеспечивает физическое хранение, добавление, модификацию и выборку данных. На данный слой также возлагается проверка целостности и непротиворечивости данных, а также реализацию разделенных транзакций. · служебные функции, играющие роль связок между функциями первых трех групп. В соответствии с этим в любом приложении выделяются следующие логические компоненты: · компонент представления, реализующий функции первой группы; · прикладной компонент, поддерживающий функции второй группы; · компонент доступа к информационным ресурсам, поддерживающий функции третьей группы; · протокол взаимодействия. Различия в реализациях технологии определяются четырьмя факторами. · в какие виды программного обеспечения интегрирован каждый из этих компонентов. · тем, какие механизмы программного обеспечения используются для реализации функций всех четырех групп. · как логические компоненты распределяются между компьютерами в сети. · какие механизмы используются для связи компонентов между собой.
Слои распределенной системы могут быть по-разному реализованы и исполняться в разных узлах сети. Обычно рассматриваются следующие архитектуры
Таким образом, можно придти к нескольким моделям клиент-серверного взаимодействия: Классификация архитектур информационных систем не является абсолютно жесткой, наиболее типичная классификация: 1. Система совместного использования файлов – FS-модель Архитектура системы БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут также создавать на рабочих станциях локальные БД, которые используются ими монопольно. В соответствии с этой моделью один из компьютеров в сети считается файловым сервером и предоставляет услуги по о
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-12-28; просмотров: 2216; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.33 (0.014 с.) |









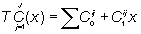 ,
, ,
, 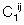 - определяемые системой матрицы стоимости установления связи и передачи единицы информации (
- определяемые системой матрицы стоимости установления связи и передачи единицы информации ( ,
, ,
,  - матрицы времени установления связи и передачи единицы информации.
- матрицы времени установления связи и передачи единицы информации. );
);





