Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Лекция №3. Структурное и неструктурное программирование. Основы алгоритмизацииСодержание книги
Поиск на нашем сайте
Цель – получить представление об особенностях структурного и неструктурного программирования; изучить особенности представления алгоритмов, а также основные алгоритмические структуры.
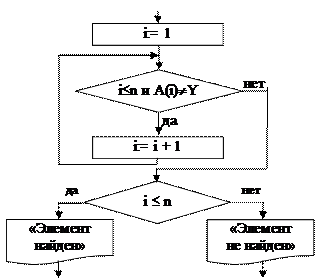
Одним из способов обеспечения высокого уровня качества разрабатываемого программного обеспечения является структурное программирование. В основе любой программы лежит алгоритм. Понятие «алгоритм» происходит от имени математика IX в. Аль Хорезми, который сформулировал правила выполнения арифметических действий. Первоначально под алгоритмом понимали только правила выполнения четырех арифметических действий над числами. В дальнейшем это понятие стали использовать вообще для обозначения последовательности действий, приводящих к решению любой поставленной задачи. Алгоритм решения вычислительной задачи - это формальное описание способа решения задачи путем разбиения ее на конечную по времени последовательность действий (этапов), понятных исполнителю. При этом должны быть четко указаны как содержание каждого этапа, так и порядок выполнения этапов. Отдельный этап алгоритма либо представляет собой другую, более простую задачу, алгоритм которой разработан ранее, либо должен быть достаточно простым и понятным без пояснений. Основными свойствами алгоритма являются: 1) детерминированность (определенность) - получение однозначного результата вычислительного процесса при заданных исходных данных, поэтому процесс выполнения алгоритма носит механический характер; 2) результативность - реализуемый по заданному алгоритму вычислительный процесс должен через конечное число шагов остановиться и выдать из исходных данных искомый результат; 3) массовость - алгоритм должен быть пригоден для решения всех задач данного типа; 4) дискретность - расчлененность вычислительного процесса на отдельные этапы. Существует несколько способов записи алгоритмов: словесный, формульно-словесный, графический, язык операторных схем, алгоритмический язык. Наибольшее распространение благодаря своей наглядности получил графический способ записи алгоритмов с помощью блок-схем. Блок-схемой называется графическое изображение логической структуры алгоритма, в котором каждый этап процесса обработки информации представляется в виде геометрических символов (блоков), имеющих определенную конфигурацию в зависимости от характера выполняемых операций. Графические символы, их размеры и правила построения схем алгоритмов определены Единой системой программной документации (ЕСПД), являющейся государственным стандартом (ГОСТ). Перечень символов, их наименование, отображаемые ими функции, форма и размеры определяются ГОСТами (таблица Б.1). Все формулы в блок-схеме записываются на языке математики, а не конкретном языке программирования. Различают три вида вычислительного процесса, реализуемого программами: линейный, разветвленный и циклический. Линейная структура процесса вычислений предполагает, что для получения результата необходимо выполнить операции в определенной последовательности. При разветвленной структуре процесса вычислений конкретная последовательность операций зависит от значений одной или нескольких переменных. Для получения результата при циклической структуре некоторые действия необходимо выполнить несколько раз. Для реализации этих вычислительных процессов в программах используют соответствующие управляющие операторы. Программы, написанные с использованием только структурных операторов передачи управления, называют структурными, чтобы подчеркнуть их отличие от программ, разрабатываемых с использованием низкоуровневых способов передачи управления. После того, как в 60-х годах XX в. было доказано, что любой сложный алгоритм можно представить, используя три основные управляющие конструкции, в языках программирования высокого уровня появились управляющие операторы для их реализации [3, 4]. К базовым относят: а) следование - обозначает последовательное выполнение действий; б) ветвление - выбор одного из двух вариантов действий; в) цикл-пока - определяет повторение действий, пока не будет нарушено некоторое условие, выполнение которого проверяется в начале цикла. Кроме базовых, процедурные языки программирования высокого уровня используют три дополнительные конструкции, реализуемые через базовые: а) выбор - выбор одного варианта из нескольких в зависимости от значения некоторой величины; б) цикл-до - повторение действий до выполнения заданного условия, проверка которого осуществляется после выполнения действий в цикле; в) цикл с заданным числом повторений (счетный цикл) - повторение некоторых действий указанное количество раз. Перечисленные конструкции были положены в основу структурного программирования. Программы, написанные с использованием только структурных операторов передачи управления, называют структурными, чтобы подчеркнуть их отличие от программ, разрабатываемых с использованием низкоуровневых способов передачи управления. Недостатки схем: а) низкий уровень детализации, что скрывает суть сложных алгоритмов; б) использование неструктурных способов передачи управления, которые на схеме выглядят проще, чем эквивалентные структурные. Пример 3.1 – Использование блок-схемы для описания алгоритма поиска в массиве А(n) элемента, равного заданному (рисунок 3.1).
Рисунок 3.1 – Фрагмент блок-схемы алгоритма поиска В приведенном примере используется структурный вариант алгоритма (цикл-пока). Элементы массива перебираются и поочередно сравниваются с заданным значением Y. В результате выводится соответствующее сообщение. К недостаткам блок-схем можно отнести следующие: а) низкий уровень детализации, что скрывает суть сложных алгоритмов; б) использование неструктурных способов передачи управления, которые на схеме выглядят проще, чем эквивалентные структурные. Кроме схем, для описания алгоритмов можно использовать псевдокоды, Flow-формы и диаграммы Насси-Шнейдермана, которые базируются на тех же основных структурах, допускают разные уровни детализации и делают невозможным описание неструктурных алгоритмов [1, 3, 8]. Псевдокод - формализованное текстовое описание алгоритма (текстовая нотация внескольких вариантах, таблица В.1). Изначально ориентирует проектировщика только на структурные способы передачи управления, не ограничивают степень детализации проектируемых операций, позволяют соизмерять степень детализации действия с рассматриваемым уровнем абстракции и хорошо согласуются с методом пошаговой детализации. Пример 3.2 – Использование псевдокода для описания алгоритма поиска в массиве А(n) элемента, равного заданному (фрагмент). i:=1 Цикл-пока i £ n и A(i) ¹ Y i:= i + 1 Все-цикл Если i £ n то Вывести «Элемент найден» иначе Вывести «Элемент не найден» Все-если
Flow-формы - графическая нотация описания структурных алгоритмов, иллюстрирующая вложенность структур. Каждому символу Flow-формы соответствует управляющая структура, изображаемая в виде прямоугольника и содержащая текст в математической нотации или на естественном языке. Для демонстрации вложенности структур символ Flow-формы вписывается в соответствующую область прямоугольника любого другого символа. В таблице В.1 приведены символы Flow-форм, соответствующие основным и дополнительным управляющим конструкциям. Пример 3.3 – Использование Flow-форм для описания алгоритма поиска в массиве А(n) элемента, равного заданному (рисунок 3.2).
Рисунок 3.2 – Flow-форма алгоритма поиска (фрагмент)
Диаграммы Насси-Шнейдермана являются развитием Flow-форм лишь с той разницей, что область обозначения условий и вариантов ветвления изображают в виде треугольников (таблица В.1), обеспечивающих большую наглядность представления алгоритма. Пример 3.4 – Использование диаграмм Насси-Шнейдермана для описания алгоритма поиска в массиве А(n) элемента, равного заданному (рисунок 3.3).
Рисунок 3.3 – Фрагмент диаграммы Насси-Шнейдермана Так же, как при использовании псевдокодов описать неструктурный алгоритм, применяя Flow-формы или диаграммы Насси-Шнейдермана, невозможно (отсутствуют условные обозначения). В то же время, являясь графическими, эти нотации лучше отображают вложенность конструкций, чем псевдокоды. Недостаток: сложность построения изображений символов усложняет их практическое применение для описания больших алгоритмов.
Лекция №4. Алгоритмические языки и предъявляемые к ним требования. Процедурные языки
Цель – получить представление об основных характеристиках алгоритмических языков и их классификации; изучить особенности использования процедурных языков.
Языки программирования, которые используются при записи алгоритмов, обладают рядом характеристик, которые позволяют классифицировать, сравнивать и выбирать их с учетом целей разработки программы. К таким характеристикам относятся мощность, уровень и целостность [11]. Мощность языка характеризуется разнообразием задач, алгоритмы которых можно записать, используя этот язык. Поэтому, очевидно, что самым мощным является язык процессора, так как любая задача в конечном итоге записывается на языке компьютера. Уровень языка определяется сложностью решения задач с использованием этого языка. Чем проще записывается решение, тем более непосредственно выражаются сложные операции и понятия, тем меньше объем получаемых исходных программ и, наконец, тем выше уровень языка. Целостность языка обусловлена свойствами экономии, независимости и единообразия понятий. Экономия понятий предполагает достижения максимальной мощности языка при условии использования минимального числа понятий. Независимость понятий означает, что правила использования одного и того же понятия в разных контекстах также должны быть одними и теми же, кроме того, между ними не должно быть взаимного влияния. Единообразие понятий требует единого согласованного подхода к описанию и использованию всех понятий. Традиционно при классификации языков программирования используется такая характеристика, как уровень языка (рисунок 4.1). На нижних уровнях размещаются машинно-ориентированные языки, а на верхних – машинно-независимые.
Рисунок 4.1 – Классификация языков программирования по уровню Машинно-ориентированные языки позволяют в полной мере учитывать особенности процессора и получать программы с высокой степенью быстродействия. Однако они не способны обеспечить мобильность (переносимость) программ между разнотипными компьютерами. Под мнемокодами подразумеваются языки ассемблера без макросредств, к макроязыкам относятся языки ассемблера с макросредствами. Машинно-независимые языки еще называются языками высокого уровня. Процедурные языки - это алгоритмические языки, которые предназначены для описания процедуры решения задачи, то есть программист должен указать компьютеру, что и как следует сделать для решения задачи. Среди процедурных выделяют группу универсальных языков, пригодных для решения любых задач (например, Паскаль, С/С++, Ада). Непроцедурные (проблемные) языки позволяют указать компьютеру, что нужно сделать для решения задачи, а как это сделать - система программирования решает автоматически. Среди проблемных языков выделяют языки СУБД, объектно-ориентированные, веб-программирования, функциональные, логические и другие. Каждая из этих групп отличается от других не уровнем, а принципами программирования. Таким образом, классификация, которая показана на рисунке 4.1, содержит 5 уровней языков: 0 – машинные, 1 – мнемокоды, 2 – макроязыки, 3 – процедурные, 4 – проблемные языки. Но в связи с тенденцией универсализации языков, эта классификация уже не является строгой, поскольку языки ассемблеров приобрели средства, присущие языкам высокого уровня, а язык С++ вообще имеет признаки как высокоуровневого, так и низкоуровневого языка. Поэтому класс языка имеет смысл определять по уровню его основополагающих средств. При использовании любого языка необходимо следить за тем, чтобы все записываемые с его помощью предложения (строки) были корректны с точки зрения алфавитных конструкций (синтаксически) и имело определенный смысл (семантику). Переводом программы с исходного языка, на котором она написана, на машинный занимается программа - транслятор. В исходных текстах программ, как правило, используются комментарии, т. е. пояснительный текст, оформленный определенным образом и никоим образом не влияющий на ход выполнения программы. Для идентификации (обозначения) всех объектов, вводимых в программу, используются имена (идентификаторы). Под объектами понимаются переменные, константы, типы данных, функции и т. д. Для каждого языка четко определены правила, согласно которым вводятся обозначения. Ключевые (служебные) слова имеют однозначно определенный смысл и могут использоваться только так, как это задано в языке. Ключевые слова не могут быть переопределены, т. е. их нельзя использовать в качестве имен, вводимых программистом [1, 6, 7]. Лекция №5. Введение в язык С++. Структура и этапы создания программы на языке С++. Стандарты языка С++
Цель – получить представление о языке программирования С++, его особенностях, структуре программ и процессе их создания.
Язык программирования высокого уровня C++ был разработан в США в начале 80-х годов сотрудником компании Bell Laboratories Бьерном Страуструпом (Bjarne Stroustrup) в результате расширения и дополнения языка С средствами, необходимыми для объектно-ориентированного программирования. Среди современных языков С++ относится к классу универсальных и по праву считается господствующим языком, используемым для разработки коммерческих программных продуктов. Пожалуй, лишь такой язык программирования, как Java может составлять ему конкуренцию. Разновидностью С++ является С# - новый язык, разработанный Microsoft для сетевой платформы. Несмотря на ряд принципиальных отличий, языки С++ и С# совпадают примерно на 90%. Особенно эффективно применение С++ в написании системных программ-трансляторов, операционных систем, экранных интерфейсов. В этом языке сочетаются лучшие свойства Ассемблера и языков программирования высокого уровня. Программы, выполненные на языке С++, по быстродействию сравнимы с программами, написанными на Ассемблере, но более наглядны, просты в сопровождении и легко переносимы с одного компьютера на другой. К основным особенностям языка относят следующие: - С++ предлагает большой набор операций, многие из которых соответствуют машинным командам и поэтому допускают прямую трансляцию в машинный код, а их разнообразие позволяет выбирать различные наборы для минимизации результирующего кода; - базовые типы данных С++ совпадают с типами данных Ассемблера, на преобразования типов налагаются незначительные ограничения; - объем С++ невелик, т.к. практически все выполняемые функции оформлены в виде подключаемых библиотек, также C++ полностью поддерживает технологию структурного программирования и обеспечивает полный набор соответствующих операторов; - С++ широко использует указатели на переменные и функции, кроме того, поддерживает арифметику указателей, и тем самым позволяет осуществлять непосредственный доступ и манипуляции с адресами памяти; удобным средством для передачи параметров являются ссылки; - C++ содержит в себе все основные черты объектно-ориентированных языков программирования: наличие объектов и инкапсуляцию данных, наследование, полиморфизм и абстракцию типов. При написании программ на языке С++ используются следующие понятия: алфавит, константы, идентификаторы, ключевые слова, комментарии, директивы [2, 5]. Алфавитом называют присущий данному языку набор символов, из которых формируются все конструкции языка. Язык C++ оперирует со следующим набором символов: латинские прописные и строчные буквы (А, В, С,..., х, у, z); арабские цифры (0, 1, 2,..., 7, 8, 9); символ подчеркивания («_»); специальные символы (список специальных символов языка C++ приведен в таблице Г.1); символы-разделители (пробелы, комментарии, концы строк и т.д.). С помощью перечисленных символов формируются имена, ключевые (служебные) слова, числа, строки символов, метки. Идентификаторы (имена) обязательно начинаются с латинской буквы или символа подчеркивания «_», за которыми могут следовать в любой комбинации латинские буквы и цифры. C++ различает прописные и строчные буквы. Не допускается использование для написания имен специальных символов и символов-разделителей. Например, _х, В12, Stack - правильно; Label.4, Root-3 - неправильно. Существуют некоторые соглашения относительно использования прописных и строчных букв в идентификаторах. Например, имена переменных содержат только строчные буквы, константы и макросы – прописные. С символа подчеркивания обычно начинаются имена системных зарезервированных переменных и констант, а также имена, используемые в библиотечных функциях. Поэтому во избежание возможных конфликтов и взаимопересечений с множеством библиотечных имен не рекомендуется использовать знак подчеркивания в качестве первого символа имени. Некоторые идентификаторы, имеющие специальное значение для компилятора, употребляются как ключевые слова. Их употребление строго определено, и они не могут использоваться иначе. Список зарезервированных слов в C++ приведен в таблице Г.2. Числа, обозначающие целые и вещественные значения, записываются в десятичной системе счисления. Перед любым числом может стоять знак «+» или «-». В вещественном числе целая часть числа отделяется от его дробной части точкой. Вещественные числа, содержащие десятичную точку, должны иметь перед ней или после нее, по крайней мере, по одной цифре. Имя метки перехода представляет собой символьно-цифровую конструкцию, например, metkal, pass, cross15, и в программе не объявляются. Строка символов — это последовательность символов, заключенная в кавычки. Например, «Строка символов». Различают два вида комментариев. Любая последовательность символов, заключенная в ограничивающие скобки /* */, в языках С/С++ рассматривается как многострочный комментарий, например, /*Главная программа*/. В языке С++ дополнительно имеется еще один вид комментария – однострочный: все символы, следующие за знаком // (двойной слеш) до конца строки, рассматриваются как комментарий, например, // Главная программа. В основном, используют комментарий стиля С++ (//), а комментарий стиля C (/* */) применяют для временного отключения больших участков программы. Следует помнить, что комментарии должны пояснять, не что это за операторы, а для чего они здесь используются. Программа, записанная на языке С/C++, обычно состоит из одной или нескольких функций. Функция – это самостоятельная единица программы, созданная для решения конкретной задачи, которая может оперировать данными и возвращать значение. Структура программы представлена на рисунке 5.1. Каждая программа на языке C++ начинается с директивы препроцессора #include, которая подключает заголовочный файл (*.h), содержащий прототипы функций, которые сообщают компилятору информацию о синтаксисе функции, например, # include <iostream.h> Заголовочный файл обычно содержит определения, предоставляемые компилятором для выполнения различных операций. Заголовочные файлы записаны в формате ASCII, их содержимое можно вывести для просмотра с помощью любого текстового редактора из каталога INCLUDE. Препроцессор просматривает программу до компилятора, подключает необходимые файлы, заменяет символические аббревиатуры в программе на соответствующие директивы и даже может изменить условия компиляции. Каждая программа на C++ содержит, по крайней мере, одну функцию – main(), которая автоматически вызывается при запуске, может вызывать другие имеющиеся в программе функции и обычно имеет вид:
void main ()
Рисунок 5.1 – Структура программы на языке С++ Обычную функцию необходимо вызывать (обращаться к ней) программно, в ходе выполнения кода. Функция main() вызывается операционной системой, и обратиться к ней из кода программы невозможно. Слово void служит признаком того, что программа не возвращает конкретного значения. В случае возврата значения операционной системе перед функцией main() указывается слово int, а в конце тела этой функции помещается выражение return() или return0. После определения главной функции следуют операторы программы, которые заключены в группирующие фигурные скобки { }. Каждый оператор оканчивается точкой с запятой (;), указывающей на его завершение. Программа выполняется по строкам, в порядке их расположения в исходном коде, до тех пор, пока не встретится вызов какой-нибудь функции, тогда управление передается строкам этой функции. После выполнения функции управление возвращается той строке программы, которая следует за вызовом функции [2, 5, 10].
Лекция №6. Представление данных в языке С++. Оператор присваивания. Арифметические операции. Директивы препроцессора
Цель – получить представление о стандартных типах данных, порядке выполнения операций, изучить особенности оператора присваивания и использования препроцессора. Определяя данные, необходимо предоставить компилятору информацию об их типе, тогда ему будет известно, сколько места нужно выделить (зарезервировать) для хранения информации и какого рода значение в ней будет находиться. В С++ определены пять базовых типов данных: символьные (char), целые (int), вещественный с плавающей точкой (float), вещественный с плавающей точкой двойной длины (double), а также пустой, не имеющий значения тип (void). На основе перечисленных типов строятся все остальные. Простейшим приемом является использование модификаторов типа, которые ставятся перед соответствующим типом: знаковый (signed), беззнаковый (unsigned), длинный (long) и короткий (short). В таблице Г.3 приведены все возможные типы с различными комбинациями модификаторов с указанием диапазона изменения и занимаемого размера в байтах. При многократном использовании в программе типов данных с различными комбинациями модификаторов, например, unsigned short int, легко сделать синтаксические ошибки, во избежание которых в С++ предусмотрена возможность создания псевдонима (синонима) с помощью ключевого слова typedef. Например, строка typedef unsigned short int USHORT; создает новый псевдоним USHORT, который может использоваться везде, где нужно было бы написать unsigned short int. Переменная – это имя, связанное с областью памяти, которая отведена для временного размещения хранимого значения и его последующего извлечения. Для длительного (постоянного) хранения значений переменных используются базы данных или файлы. В С++ все переменные должны быть объявлены до их использования. Объявление предполагает наличие имени переменной и указание ее типа. Однако следует иметь в виду, что нельзя создать переменную типа void. Основная форма объявления переменных имеет вид тип <список_переменных>; В этом объявлении: тип – один из существующих типов переменных; < список_переменных > может состоять из одной или нескольких переменных, разделенных запятыми. Например, int x, e, z; float radius; long double integral; Можно объявлять переменные и одновременно присваивать им начальные значения, т.е. инициализировать их. Например, int min=15; float p1=1.35; Переменная называется глобальной, если она объявлена вне каких-либо функций, в том числе функции main(). Такая переменная может использоваться в любом месте программы (за исключением глобальных статических переменных), а при запуске программы ей присваивается нулевое значение. Переменная, объявленная внутри тела функции (одного блока), является локальной и может использоваться только внутри этого блока. Вне блока она неизвестна. Важно помнить, что: - две глобальные переменные не могут иметь одинаковые имена; - локальные переменные разных функций могут иметь одинаковые имена; - локальные переменные в одном блоке не могут иметь одинаковые имена. Данные в языках программирования могут представляться также в виде констант. Константы используются в тех случаях, когда программе запрещено изменять значение какой-либо переменной. Для определения константы традиционным способом используется #define, которая просто выполняет текстовую подстановку. Например, #define StudentsOfGroup 15 В данном случае константа StudentsOfGroup не имеет конкретного типа и каждый раз, когда препроцессор встречает имя StudentsOfGroup, он заменяет его литералом 15. Поскольку препроцессор запускается раньше, компилятор никогда не увидит константу, а будет видеть только число 15. Наиболее удобным способом определения констант является следующий: const тип имя_константы = значение_константы; Этот способ облегчает дальнейшее сопровождение программы и предотвращает появление ошибок. Так как определение константы содержит тип, компилятор может проследить за ее применением только по назначению (в соответствии с объявленным типом). Например, const int Diapazon=20; Литеральные константы (литералы) – это значения, которые вводятся непосредственно в текст программы. Поскольку после компиляции нельзя изменить значения литералов, их также называют константами. Например, в выражении int MyAge=19; имя MyAge является переменной типа int, а число 19 – литеральной константой, которой нельзя присвоить никакого иного значения. Символьная константасостоит из одного символа, заключенного в апострофы: ‘q’, ‘2’, ‘$’. Например, const char month=’December’;. К символьным константам относятся специальные символы (в том числе управляющие, список приведен в таблице Г.1). Строковые константы состоят из последовательности символов кода ASCII, заключенной в кавычки, оканчивающейся нулевым байтом. Конец символьной строки (нулевой байт) обозначается символом NULL ('\0'). Перечислимые константы позволяют создавать новые типы данных, а затем определять переменные этих типов, значения которых ограничены набором значений константы. Для создания перечисляемой константы используется ключевое слово enum, а запись имеет вид: enum имя_константы {список_значений_константы}; Значения константы в списке значений разделяются запятыми. Например, enum COLOR {RED, BLUE, GREEN, WHITE, BLACK}; Каждому элементу перечисляемой константы соответствует определенное значение. По умолчанию, первый элемент имеет значение 0, а каждый последующий - на единицу большее. Каждому элементу константы можно присвоить произвольное значение, тогда последующие инициализируются значением на единицу больше предыдущего. Например, enum COLOR {RED=100, BLUE, GREEN=200, WHITE=300, BLACK}; В этом примере значение BLUE=101, BLACK=301. Существует механизм явного задания типов констант с помощью суффиксов. Для констант целого типа в качестве суффиксов могут использоваться буквы u, l, h, L,H, а для чисел с плавающей точкой – l, L, f, F. Например, 12h 34H - short int 23L -273l - long int 23.4f 67.7E-24F - float 89uL 89Lu 89ul 89 LU - unsigned short Выражение в языке С++ представляет собой некоторую допустимую комбинацию операций и операндов (констант, переменных или функций). Перечень операций языка C++ приведен в таблице Г.4. Все перечисленные операции выполняются традиционным способом, за исключением операции деления. Особенность операции деления заключается в том, что если оба операнда целого типа, то она даст целый результат, например, 3/2 даст 1. Для получения действительного результата необходимо иметь хотя бы один действительный операнд, например, 3/2.0 даст 1.5. Для каждой операции языка определено количество операндов: а) один операнд – унарная операция, изменяющая знак, например, унарный минус –х; б) два операнда – бинарная операция, например, операция сложения х+у; в) три операнда – операция условие?:, она единственная. Каждая операция может иметь только определенные типы операндов. Каждая бинарная операция имеет определенный порядок выполнения: слева направо или справа налево. Наконец, каждая операция имеет свой приоритет. Приоритет и порядок выполнения операций приводятся в таблице Г.4. Часто в выражениях используются математические функции языка C++, которые находятся в библиотеке math. Чтобы воспользоваться этими функциями в начало программы необходимо включить заголовочный файл <math.h>. Основные математические функции приводятся в таблице Г.5. Все выражения являются операторами, которые в языке предназначены для описания действий. Любой оператор может быть помечен меткой. Операторы отделяются друг от друга точкой с запятой (;). В любом месте программы, где может быть размещен один оператор, можно разместить составной оператор, называемый блоком. Блок содержит несколько операторов, которые выполняются как одно выражение, ограничивается фигурными скобками {}, но не заканчивается точкой с запятой (;). Объявление переменной в программе означает всего лишь выделение места в памяти компьютера для ее размещения. Программа же должна позволять оперировать данными. В этом процессе наиболее важна операция присваивания, которая выглядит следующим образом: переменная = выражение. Операция присваивания заменяет значение операнда, расположенного слева от знака «=», значением, вычисляемым справа от него. При этом могут выполняться неявные преобразования типа. Знак «=» в С/С++ - это знак присваивания, а не равенства. В отличие от других языков, где присваивание – оператор по определению, в С/С++ существуют понятия «операция присваивания» и «оператор присваивания». Операция «превращается» в оператор, если в конце выражения поставить точку с запятой, например, ++x – это выражение, а ++х; - это оператор. Оператор присваивания удобно использовать при инициализации переменных, например, j=k;. Кроме того, в С/C++ операция присваивания может использоваться в выражениях, которые включают в себя операторы сравнения или логические операторы, например, if ((x=x+5)>0) cout<<"Вывод";. Еще одной особенностью использования операции присваивания в С/С++ является возможность многократного присваивания, которое выполняется справа налево. Например, для того, чтобы присвоить значение 2*k нескольким переменным, можно воспользоваться операцией: x=y=z=2*k. В языке С/C++ имеются дополнительные операции присваивания +=, -=, *=, /= и % =. При этом величина, стоящая справа, добавляется (вычитается, умножается, делится или делится по модулю) к значению переменной, стоящей слева. Например, вместо оператора х=х+5; можно записать х+=5;. Причем, операция х+=5 выполняется быстрее, чем операция х=х+5. Очень часто в программах к переменным добавляется (или вычитается) единица. Увеличение значения на 1 называется инкрементом (++), а уменьшение на 1 - декрементом (--). Например, оператор с=с+1; эквивалентен оператору с++;, оператор с=с-1; эквивалентен оператору с--;. Операторы инкремента и декремента существуют в двух вариантах: префиксном и постфиксном. Префиксные операции увеличивают (уменьшают) значение переменной на единицу, а затем используют это значение. Например, оператор х=++у; эквивалентен выполнению двух операторов у=у+1; х=у;. В этом примере сначала происходит увеличение на единицу значения переменной у, а затем присваивание этого значения переменной х. Постфиксные операции сначала используют значение переменной, после чего увеличивают (уменьшают) его. Например, оператор х=у--; эквивалентен выполнению двух операторов х=у; у=у-1;. В этом примере переменная х получает значение у, после чего значение у уменьшается на единицу. Вообще в выражениях лучше использовать операнды одного типа, но С++ допускает преобразование типов, то есть если операнды принадлежат к разным типам, то они приводятся к некоторому общему типу. Приведение выполняется в соответствии со следующими правилами: а) автоматически производятся лишь те преобразования, которые превращают операнды с меньшим диапазоном значений в операнды с большим диапазоном значений, т.к. это происходит без какой-либо потери информации; б) выражения, не имеющие смысла (например, число с плавающей точкой в роли индекса), не пропускаются компилятором еще на этапе трансляции; в) выражения, в которых могла бы потеряться информация (например, при присваивании длинных целых значений более коротким или действительных значений целым), могут вызвать предупреждение (warning), но они допустимы. В отличие от других языков программирования в С++ для любого выражения можно явно указать преобразование его типа, используя унарный оператор, называемый приведением типа. Выражение приводится к указанному типу по перечисленным правилам конструкцией вида (имя типа) выражение; Например, (int) i=2.5*3.2;. Однако пользоваться этим оператором можно лишь в том случае, если вполне осознаются цель и последствия такого преобразования [2, 5, 10]. Лекция №7. Функции ввода/вывода. Основные конструкции языка С++
Цель – получить представление о функциях «ввода-вывода», используемых в С++, а также ознакомиться с особенностями использования основных конструкций языка. В любой достаточно сложной программе можно выделить линейные фрагменты. Фрагмент программы имеет линейную структуру, если все операции в нем выполняются последовательно, друг за другом, и может содержать операторы присваивания, математические функции, арифметические операции, функции «ввода-вывода» данных и другие операторы, не изменяющие общего порядка следования операторов. Редкая программа обходится без операций «ввода-вывода». В языке С были реализованы две новаторские идеи: средства «ввода-вывода» были отделены от языка и вынесены в отдельную библиотеку stdio (стандартная библиотека «ввода-вывода»), а также была реализована концепция процесса «ввода-вывода», независимого от устройств. Именно поэтому язык С++, унаследовавший черты своего «прародителя», имеет большой набор функций «вв
|
|||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-09-20; просмотров: 1741; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.184.36 (0.019 с.) |