Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Два вида mimd: uma и numa, smp – подвид umaСодержание книги Поиск на нашем сайте
UMA — архитектура многопроцессорных компьютеров с общей памятью. Все микропроцессоры используют физическую память одновременно. Время запроса к данным из памяти не зависит ни от области памяти, к которой обращаются, ни от того, какой процессор обращается. Каждый микропроцессор может использовать свой собственный кэш, но у них есть и общий кэш. Проблемы кэширования: например, некоторое значение в ячейке памяти лежит в кэше 1 процессора. Потом другой процессор меняет значение по этому адресу, и получается, что в кэше первого уже неверное значение. Поэтому значения в первом кэше должны быть обновлены – лишняя затрата ресурсов. SMP архитектура - cимметричная многопроцессорная архитектура. Состоит из нескольких однородных процессоров. Отличие от UMA: остутствие общего кэша, работа собственных кэшей синхронизирована. Минусы: более дорогостоящее оборудование, сложно кодить под системы такого типа.
UMA и SMP: эффективный обмен данными между задачами, выполняющимися на разных процессорах. Но у нас есть ограничение на количество процессоров – 16.
Суть: особой организации памяти, когда память физически разделена, но логически общедоступна. Процессор может обратиться как к своей памяти, так и к памяти, находящейся в другом узле. Доступ не к своей памяти занимает длительное время. Памяти объединены с помощью высокоскоростного коммутатора. На каждой плате – UMA, целиком – NUMA. Кластер — группа компьютеров, объединённых высокоскоростными каналами связи и представляющая с точки зрения пользователя единый аппаратный ресурс. Не можем обратиться к памяти другого компьютера, но можем обмениваться сообщениями. · Виды кластеров: · Отказоустойчивые · Сбалансированные нагрузки · Вычислительные · Grid-системы (задачи на распараллеливание) Плюсы: эффективны при масштабных вычислениях. Минусы: медленно работают друг с другом, поэтому эффективней разбивать задачу на подзадачи для каждого компьютера.
Дисковые массивы (RAID 0-6), проблема write-hole RAID — избыточный массив независимых жёстких дисков — массив из нескольких дисков, управляемых контроллером, взаимосвязанных скоростными каналами и воспринимаемых ОС как единое целое. Служит для повышения надёжности хранения данных и/или для повышения скорости чтения/записи информации (RAID 0).
Много видов.
(+): повышается производительность (от количества дисков зависит кратность увеличения производительности). (-): низкая надежность, т. к. отказ любого из дисков приводит к неработоспособности всего массива.
Информация на всех дисках идентична друг другу. Скорость записи такая, как если бы у нас был 1 жесткий диск. Скорость чтения в n раз больше. (+): Имеет высокую надёжность — работает до тех пор, пока функционирует хотя бы один диск в массиве. (-): Приходится выплачивать стоимость двух жёстких дисков, получая полезный объём одного жёсткого диска.
RAID 2 Диски делятся на две группы — для данных и для кодов коррекции ошибок, причем если данные хранятся на 2n-n-1 дисках, то для хранения кодов коррекции необходимо n дисков. Данные записываются на соответствующие диски так же, как и в RAID 0. Оставшиеся диски хранят коды коррекции ошибок, по которым в случае выхода какого-либо жёсткого диска из строя возможно восстановление информации. Метод Хемминга давно применяется в памяти типа ECC и позволяет на лету исправлять однократные и обнаруживать двукратные ошибки. (-) для его функционирования нужна структура из почти двойного количества дисков
Данные разбиваются на байты и распределяются по дискам. Ещё один диск записывает побитово xor сумму остальных жестких дисков. Отличия RAID 3 от RAID 2: невозможность коррекции ошибок на лету и меньшая избыточность. (+)высокая скорость чтения и записи данных; минимальное количество дисков для создания массива – 3 один диск может сломаться (xor сумма восстановит его) (-) большая нагрузка на контрольный диск, и, как следствие, он часто ломается. Низкая скорость передачи маленьких файлов. Их проще было бы передавать без побайтового разбиения.
(+) удалось отчасти «победить» проблему низкой скорости передачи данных небольшого объёма. RAID 4 легко делать из RAID 0 (-) Запись производится медленно из-за записи на контрольный диск.
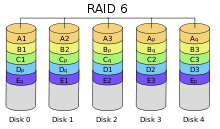
Решена проблема частой поломки RAID 3 и RAID 4. Запись контрольных сумм - диагональная. (+): Экономичность из-за редких поломок. При чтении выигрыш (потоки данных с разных жестких дисков обрабатываются параллельно) (-): Медленная запись из-за большого количества операций RAID 6 похож на RAID 5, но имеет более высокую степень надёжности — под контрольные суммы выделяется ёмкость 2-х дисков, рассчитываются 2 суммы по разным алгоритмам. (+) Обеспечивает работоспособность после одновременного выхода из строя двух дисков — защита от кратного отказа. Для организации массива требуется минимум 4 диска. (-) самый медленный из всех, требуется сильный контроллер RAID 10 – RAID 0 из RAID 1 (+) Надежность, скорость (-) Стоимость в 2 раза больше Сравнение:
Проблема write hole Возникает в RAID 3 – RAID 6 Если ОС отказывает в момент записи, то контрольная сумма может сбиться, и это необходимо исправить до поломки какого-либо из дисков. Иначе, если диск сломается, и мы начнем восстанавливать данные по xor сумме, то у нас будут неверные данные и мы не сможем понять, на каком этапе произошла ошибка.
ZFS строится поверх виртуальных пулов хранения данных. Каждый их них – жесткий диск или рейд. В ZFS нет проблемы write hole, т.к. это транзакционная файловая система. Транзакции не позволят записаться сумме неверно. При сбое транзакция не выполнится. Даже если не через транзакции, то по временным меткам мы поймем, в чем причина ошибки. 18. Планирование дисковых операций (кеширование, алгоритмы обхода дорожек диска) Кеширование Может происходить на разных уровнях. ОС использует часть ОП в качестве кэша дисковых операций. Уровни кэширования: · Уровень приложения: программа записывает промежуточные результаты работы, чтобы не считать их лишний раз. · Уровень ОС: храним разметку виртуальной памяти и все данные, которые часто требуются ОС · Уровень ЖД: скорость доступа к ОП больше. Некоторые блоки используются несколькими процессами одновременно, поэтому удобно их прочитывать один раз.
Алгоритмы обхода дорожек: Определяют, в каком порядке делать запись и чтение данных, накопленных в кэше. Типы: · Передача «как есть» - в том де порядке. Не целесообразно для наших стандартных файловых систем, т.к. головка будет постоянно перемещаться по разным участкам ЖД. Удобно для флэш-накопителей – у них нет головки. · Приоритетный тип. Административные данные важнее (например, записи в журналы), поэтому мы их обрабатываем раньше. · Приоритет + random. Пользовательские данные рандомно выберутся, и рано или поздно запишутся. · Random: данные на запись определяются случайным образом. Не используется. · Сканирование: берем самые близкие дорожки (проходим сектор слева направо и обратно). Поэтому если мы прошли один раз, а после этого что-то добавили, то при обратном проходе это будет обнаружено. · Цикличное сканирование: То же самое, но нет обратного хода. · Short: выбираем данные, расстояние между которыми наименьшее. Если очередь постоянно меняется, то этот способ эффективен.
|
||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 851; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.226.214.1 (0.011 с.) |

 NUMA — «неравномерный доступ к памяти» — схема реализации компьютерной памяти, когда время доступа к памяти определяется её расположением по отношению к процессору.
NUMA — «неравномерный доступ к памяти» — схема реализации компьютерной памяти, когда время доступа к памяти определяется её расположением по отношению к процессору. RAID 0 — дисковый массив из двух или более жёстких дисков без резервирования. Информация разбивается на блоки данных и записывается на оба/несколько дисков одновременно.
RAID 0 — дисковый массив из двух или более жёстких дисков без резервирования. Информация разбивается на блоки данных и записывается на оба/несколько дисков одновременно. RAID 1 (зеркалирование)
RAID 1 (зеркалирование) RAID 3
RAID 3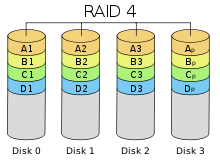 RAID 4 похож на RAID 3, но отличается от него тем, что данные разбиваются на блоки, а не на байты.
RAID 4 похож на RAID 3, но отличается от него тем, что данные разбиваются на блоки, а не на байты.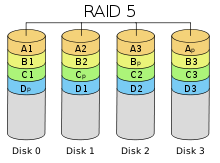 RAID 5
RAID 5