
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Логическая архитектура компьютера. Архитектуры: фон Неймана, гарвардская.Содержание книги
Поиск на нашем сайте
Работа компьютера: машинный код, вызов функций, прерывания, шины данных. 1) Машинный код — система команд вычислительной машины, которая интерпретируется процессором машины. Каждая инструкция выполняет определённое элементарное действие (сложение, копирование, …) или переход к другому участку кода (изменение порядка исполнения). Каждая программа состоит из последовательности таких атомарных инструкций. 2) Прерывания — это инструкция для процессора, некая исключительная ситуация, прерывающая работу процессора. Например, программа может приказать диску начать передачу информации и заставить диск произвести прерывание, как только передача данных завершится. Прерывание останавливает работу программы и передает управление обработчику прерываний, который выполняет определенное действие. Затем обработчик прерываний передает управление прерванной программе, которая должна быть в том же самом состоянии, в котором она находилась, когда произошло прерывание (состояние всех внутренних должно быть восстановлено. Поэтому в момент прерывания происходит их сохранение - малое упрятывание). Использование регистра прерываний: Каждый разряд этого регистра отвечает за появление того или иного. Когда ОС получает управление, то специальными командами она может определить причину прерывания, а после этого, в зависимости от причины, передать управление на ту или иную программу обработки прерывания. Использование вектора прерываний: В определенном фрагменте ОП размещается вектор прерываний. Это таблица, каждая строка которой соответствует определенному прерыванию, содержимое строки - адрес программы-обработчика соответствующего прерывания. При возникновении прерывания управление передается на точку которая соответствует конкретному прерыванию, т.е. сразу идет попадание на обработчик прерываний. Различают быстрые и медленные обработчики прерываний. Отличие: при выполнении быстрого обработчика прерываний запрещаются все прерывания на процессоре. То есть они не лишают процесса потока управления – после выполнения быстрого прерывания управление передается назад к процессу сразу.
3) Для вызова функции используется следующая последовательность: 1) функция помещается на вершину стека 2) аргументы функции помещаются в стэк в прямом порядке. 3) вызов функции 4) все аргументы и значение функции выбираются (pop) из стека. 5) результаты функции помещаются в стек в прямом порядке. Любая ошибка внутри функции помещается вверх (при помощи longjmp). Основное назначение стека вызовов — отслеживать место, куда вызванная процедура должна вернуть управление после завершения. Для этого при вызове процедуры в стек заносится адрес команды, следующей за командой вызова («адрес возврата»). По завершении вызванная процедура должна выполнить команду возврата для перехода по адресу из стека. Кроме адресов возврата в стеке могут сохраняться другие данные: значения регистров или локальные переменные. Стек растет вверх в сторону уменьшения адреса.
Системный вызов Это обращение программы к ядру ОС для выполнения операции. Т.е. она сама не модет получить доступ к памяти, аппаратуре и т.п. напрямую. И ядро в зависимости от прав процесса выполняет или нет этот процесс.
4) Шина — набор проводников, соединяющих различные устройства. Они могут быть внутренними по отношению к процессору (АЛУ <-> АЛУ), а могут быть внешними и связывать процессор с памятью или устройствами ввода-вывода. Основная характеристикой шины - ширина в битах. Ширина шины определяет количество информации, передаваемой за один такт. Для реализации режима прямого доступа к памяти, внешнее устройство должно отправить процессору запрос. Процессор программирует специальный контроллер (DMA) на обслуживание работы внешнего устройства в режиме прямого доступа к памяти. Он задает адрес памяти, размер передаваемого блока данных, направление передачи (чтение или запись), после чего дает команду на выполнение. Пересылкой данных управляет контроллер DMA. Процессор в это время может продолжить выполнение прерванной программы, но доступа к памяти он не имеет и не может вмешаться в процесс обмена, пока контроллер не закончит передачу данных и не выдаст соответствующего сообщения.
Задачи операционной системы Вычислительная система -взаимосвязанная совокупность аппаратных средств вычислительной техники и программного обеспечения, предназначенная для обработки информации ОС – комплекс управляющих и обрабатывающих программ, выступающих как интерфейс между устройствами вычислительной системы и прикладными программами и предназначенная для управления вычислительными процессами и устройствами. Физические/логические ресурсы Физические ресурсы – аппаратные компоненты вычислительной системы (реально присутствующие), внешние устройства, ЖД. Логическое/виртуальное устройство – устройство, некоторые характеристики которого (или все оно) реализованы программным образом. Драйвер логического устройства – программа, обеспечивающая существование и использование соотв. ресурса. Примеры логического устройтсва: · ФС – способ организации, хранения и именования данных на носителях информации виртуализировано ЖД -> Драйвер ЖД -> Драйвер ФС -> Файл Работа с абстракцией (неизвестно устройство файлов) · Память в каком-то смысле тоже ЛУ Она запрограммирована (требуется 8GB, а доступно 4GB – делаем swapping – наращивание ОП за счет ЖД (раздел подкачки)) · Процессор в каком-то роде тоже логический ресурс. Его инструкции виртуализированы. Например, если процессор не умеет работать с вещественными числами, то в ОС кидается исключение и ОС должна посчитать в целых числах (работа с несуществующим 387 процессором).
6. Структура операционной системы Диск, память -> аппаратный контроллер -> драйвер -> ФС -> ОС -> библиотеки для программ -> прилож -> user 1) Составные части Ядро́ — центральная часть ОС, обеспечивающая приложениям координированный доступ к ресурсам компьютера (процессорное время, память, устройство ввода и вывода). Примеры: Linux, Unix, Win NT Пользовательское окружение – минимальный набор программ для пользователя для взаимодействия с ОС, которые предоставляются пользователю сразу с ОС. Оно определет целевое использование ОС. Пример: командный интерпретатор, набор утилит, компилятор Одно ядро – много пользовательских окружений: Linux – Gnome, KDE, UNITY (среды рабочего стола) Разные ядра – одно пользовательское окружение: debian (универсальная ОС из свободного ПО с открытым исходным кодом) – Linux, FreeBSD 2) Этапы загрузки Загрузчик знает, как загрузить ядро. Загрузчик лежит в секторе 0 диска. Ядро в boot/kernel MBR - master boot record — код и данные, необходимые для последующей загрузки операционной системы и расположенные в первых физических секторах на жёстком диске. MBR содержит небольшой фрагмент исполняемого кода, таблицу разделов и специальную сигнатуру. Функция MBR — «переход» в тот раздел жёсткого диска, с которого загружать ОС. В процессе запуска компьютера, после окончания начального теста, базовая система ввода-вывода (BIOS) загружает «код MBR» в оперативную память и передаёт управление находящемуся в MBR загрузочному коду. BIOS – часть ПО, предназначенная для доступа к аппаратуре. GPT — GUID Partition Table. GPT позволяет создавать разделы диска размером до 9,4 ЗБ (9,4 × 1021 байт), в то время как MBR может работать только с 2,2 ТБ (2,2 × 1012 байт). Просто современнее и круче. MBR присутствует в самом начале диска (блок LBA 0) как для защиты, так и в целях совместимости. Собственно GPT начинается с Оглавления таблицы разделов. Loader - Загрузчик операционной системы, устраивающий диалог с пользователем (выбор ОС). Загружает ядро в ОП, готовит аппаратуру, передает управление ядру. Фактически – звено между MBR/GPT и ядром. Kernel – Ядро. swap – организует работу с паматью. Ответственность за подкачку. Хранит информацию об изменениях. Не обязателен. init организует и поддерживает всё пользовательское пространство (запуск нужных служб, программ и т.д.), затем переключение в пользовательскую среду, когда запуск системы завершится. Процесс – поток, порожденный нашей программой. Ядро порождает 2 процесса: 0-swap, 1-init Init запускает ect/ - настройки, /bin-бинарные файлы (), /sbin- бинарные файлы для суперпользователя и т.п. Init порождает все процессы (fork()). Они одинаковые. Чтобы изменить код – execlp Типы операционных систем 1) Пакетные. Наличие очереди программ на исполнение, которые будут выполняться по 1 отдельно. Главной критерий эффективности - максимальная пропускная способность, решение максимального числа задач в единицу времени. Переключение процессора с выполнения одной задачи на выполнение другой происходит только если задача сама отказывается от процессора, например, из-за необходимости выполнить операцию ввода-вывода. Одна задача может надолго занять процессор, что делает невозможным выполнение интерактивных задач. Снижается эффективность работы пользователя.
2) Разделения времени. Скорость ввода много ниже, чем скорость обработки данных -> при пакетном был бы простой компьютера В системах разделения времени каждой задаче выделяется только квант процессорного времени. Ни одна задача не занимает процессор надолго. Квант достаточно маленький - впечатление, что каждый из процессов единолично использует машину. Меньшая пропускной способность, чем у систем пакетной обработки, так как на выполнение принимается каждая запущенная пользователем задача. Критерием эффективности - удобство и эффективность работы пользователя. 3) Реального времени Применяются для управления различными техническими объектами (спутник, научная установка, самолет). В некоторых исключительных ситуациях надо выполнять процессы очень быстро, в пределах допустимого времени, не отвлекаясь на мелкие процессы (самолет попал в зону турбулентности). У аварийного процесса наибольший приоритет. Надо не отвлекаясь на другие процессы выполнить его. Критерий эффективности - способность выдерживать заранее заданные интервалы времени между запуском программы и получением результата. Это время называется временем реакции системы. 4) Сетевые. Главными задачами являются разделение ресурсов сети (например, дисковые пространства) и администрирование сети. Под сетевой операционной системой в широком смысле понимается совокупность операционных систем отдельных компьютеров, взаимодействующих с целью обмена сообщениями и разделения ресурсов. В узком смысле сетевая ОС - это операционная система отдельного компьютера, обеспечивающая ему возможность работать в сети.
Управление памятью 1) Одиночное распределение: ОП делится на 2 области. В одной находится ОС, другая предназначена для задач пользователя (предполагается однопроцессная система). Необходимые аппаратные средства: Регистр границ (в нем граница между ОС и пользовательской частью ОП) Если ЦП в режиме пользователя попытается обратиться в область ОС, то возникает прерывание. В режиме ОС мы можем обращаться в любую точку ОП, если мы находимся в пользовательском режиме, то запрошенный адрес сравнивается с содержимым регистра границ, и, если он окажется меньше, т.е. мы хотим обратиться в часть ОП, занятую под ОС, то выдается прерывание. Достоинства: простота. Недостатки: часть памяти просто не используется (область памяти, занятая процессом, занята на все время выполнения процесса, большие участки памяти простаивают). Ограничение на размеры процесса. Т.е. загрузить в эту систему процесс, превосходящий область памяти, мы не можем.
2) Страничное: Память разделена на области (страницы) размера. Типичный размер 4кб. Страница – минимальная единица выделенной памяти (даже запрос на 1 байт потребует выделения страницы). Процесс обращается к памяти через виртуальные адреса (содержат номер страницы и смещение в ней). ЦП преобразует этот виртуальный адрес в физический. Если не удалось, возможно, что страница была откачана на ЖД (страница, к которой давно не обращались). Тогда она загрузится в ОП. Таблица страниц хранит в себе виртуальные адреса страниц. Недостатки: для 2 кб требуется выделение целой страницы – большой расход памяти Преимущества: возможность изолировать процессы (создание для каждого процесса своего адресного пространства)
3) Сегментное: Память делится на части произвольного размера — сегменты. Этот механизм позволяет, к примеру, разбить данные процесса на логические блоки. Для каждого сегмента могут быть назначены права доступа к нему. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Система создает таблицу сегментов процесса, в которой для каждого сегмента указывается физический адрес сегмента в ОП, размер сегмента, правила доступа. Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту. Недостатки: более медленное по сравнению со страничной организацией преобразование адреса. Преимущества: произвольный размер сегмента.
4) Сегментно-страничное: Суть данного подхода состоит в следующем. Программа разбивается н сегменты, каждый из которых размещается на количестве страниц памяти. Перемещение данных осуществляется страницами. Разбиение на сегменты позволяет определять разные права доступа к разным частям программы. С каждым процессом связана одна таблица сегментов и несколько таблиц страниц. Первая компонента виртуального адреса содержит номер сегмента. Вторая компонента виртуального адреса состоит из двух полей: номера виртуальной страницы и смещения относительно начала страницы. Недостатки: ещё большая задержка доступа к памяти. Задержка примерно втрое больше, чем при простой прямой адресации. Достоинства: позволяет совместно использовать одни и те же сегменты в виртуальной памяти разными задачами, произвольный размер выделяемой памяти.
5) Своппинг Неактивные участки памяти помещаются на ЖД, освобождая ОП для загрузки других фрагментов памяти. Они хранятся на ЖД в swap-файле или swap-разделы. Когда приложение обратится к откаченной странице, произойдет исключительная ситуация. Обработчик этого события должен проверить, была ли ранее откачена запрошенная страница, и, если она есть в свопе, загрузить ее обратно в память.
mmap —системный вызов, позволяющий выполнить отображение файла или устройства на память. Создается несвопируемая страница, где происходит изменение файла. Затем, когда надо, он отгружается в ЖД. Фактически, мы работаем с файлами как с памятью – удобно кодить, но та же проблема, что и у страниц – под файл в 2 байта выделяется новая страница. Shared memory работает через mmap.
Файловые системы Файловая система – порядок, определяющий способ хранения, именования и организации данных на ЖД. FAT - «таблица размещения файлов» В файловой системе FAT секторы диска объединяются в кластеры. Количество секторов в кластере равно степени двойки. Выбирают золотую середину размера кластеров (не слишком большие и не слишком маленькие во избежание потери памяти впустую и большой адресации). ФС разделена на три смежные области: - Зарезервированная область. Содержит служебные структуры, которые принадлежат загрузочной записи раздела - Область таблицы FAT, содержащая массив индексных указателей ("ячеек"), соответствующих кластерам области данных. - Область данных, где записано собственно содержимое файлов.
Таблица FAT – массив указателей на кластеры. N-й указатель соответствует кластеру с тем же номером. Значение индексного указателя соответствует состоянию соответствующего кластера. Состояния: - кластер свободен – указатель обнулен; - кластер занят файлом и не является последним кластером файла – значение указателя — это номер следующего кластера файла; - кластер является последним кластером файла – указатель содержит метку - кластер поврежден; Папка/директория - файл, помеченный специальным атрибутом. Данными такого файла в любой версии является список файловых записей. Содержимое папок: таблица Размещение файлов: списком. Объем ФС <=8ТБ Объем файла <=4ГБ
NTFS Делит все полезное место на кластеры. Диск NTFS условно делится на две части. Первые 12% диска отводятся под так называемую MFT зону - пространство, в которое растет метафайл MFT. Остальные 88% диска представляют собой обычное пространство для хранения файлов. Каждый элемент системы представляет собой файл - даже служебная информация. Самый главный файл на NTFS называется MFT - общая таблица файлов. Именно он размещается в MFT зоне и представляет собой централизованный каталог всех остальных файлов диска и себя самого. MFT поделен на записи, и каждая запись соответствует какому либо файлу. Хранение файла: обязательный элемент - запись в MFT. В этом месте хранится вся информация о файле, за исключением данных. Имя файла, размер, положение на диске отдельных фрагментов, и т.д. Если для информации не хватает одной записи MFT, то используются несколько, причем не обязательно подряд. Каталог на NTFS представляет собой файл, хранящий ссылки на другие файлы и каталоги, создавая иерархическое строение данных на диске. Журналирование: NTFS - отказоустойчивая система, которая вполне может привести себя в корректное состояние при практически любых реальных сбоях. Содержимое папок: B-дерево. Размещение файлов списком.
Несколько блоков в начале раздела под загрузочную область. суперблок, описывающий настройку некоторых параметров файловой системы. Хранит размеры всех блоков. В ОП постоянно хранится копия суперблока. Индексный дескриптор (inode) описывает файл, содержит его мета-данные, а также содержит массив указателей на данные файла. Если нужно 16 указателей, то вместо 16-го мы делаем указатель на такой же inod и все продолжается. Каталог файлов содержит только список файлов в директории и индексный дескриптор, связанный с каждым файлом. Все метаданные файла хранятся в индексном дескрипторе. Содержимое папок: таблица Размещение файлов: inode (B-дерево) Журналируемая.
ExtFS2 — файловая система ядра Linux. Быстрая и производительная. Устройство такое же, как в UFS. В отличие от UFS, нет жуналируемости.
ExtFS3 Точно такая же, как ExtFS2, журналируемая.
FFS Такая же, как UFS, но диски еще разделены на цилиндр-группы – секторы жесткого диска. Когда мы добавляем файлы, файловая система размещает их таким образом, что они лежат в одной цилиндр-группе, чтобы уменьшить движение головки. За счет того, что головка мало двигается, она очень производительная и быстрая.
ZFS — copy-on-write (при копировании области данных создается реальная копия только тогда, когда ось обращается к данным с целью записи) 128-битная файловая система. Поддерживает большие объёмы данных, объединяет концепции файловой системы и менеджера логических дисков (томов) и физических носителей. Основное преимущество — полный контроль над физическими и логическими носителями. Зная расположения файла, ZFS обеспечивает высокую скорость доступа к ним, контроль их целостности. Переменный размер блока, параллельность чтения-записи, использование контрольных сумм. Содержимое папок: Расширяемая хэш-таблица Размещение файлов – это B-деревья, чтобы доступ к файлу был за логарифм. Это транзакционная файловая система.
Btrfs —copy-on-write файловая система, основанная на структурах Б-деревьев Содержимое папок: B-tree Сравнение
Сети 1) Уровни ISO/OSI, TCP/IP Абстрактная сетевая модель для коммуникаций и разработки сетевых протоколов. В настоящее время основным используемым стеком протоколов является TCP/IP. Протокол – описание правил и сообщений, по которым ВС осуществляет обмен информацией. Уровни ISO/OSI: 1. Физический: работа со средой передачи, сигналами и двоичными данными в битах. 2. Канальный: физическая адресация (передача по физическим линиям), в кадрах 3. Сетевой: определение маршрута и логическая адресация (связь между ВС), в пакетах. Маршрутизация по IP 4. Транспортный: прямая связь между конечными пунктами, надежность (корректная транспортировка 5. Сеансовый: управление сеансом связи 6. Представительский: представление и кодирование данных 7. Прикладной: доступ к сетевым службам, взаимодействие с прикладными системами (например, подключение к браузеру) На каждом уровне необходимо наличие протоколов
TCP — это транспортный механизм, дающий уверенность в достоверности получаемых данных. В отличие от UDP гарантирует целостность передаваемых данных и уведомление отправителя о результатах передачи. Уровни IP: 1. Доступа к сети: доступ к сети, эти протоколы обмениваются фреймами 2. Межсетевой: работа с датаграммами, адресами, маршрутизация. Нет установления соединения с другими машинами. 3. Транспортный: доставка данных от ВС к ВС, установка сеанса. TCP протокол – сегментами (гарантируется целостность файлов). 4. Прикладных программ: прикладные программы и процессы, использующие сеть. Программы сами стандартизируют представление данных (в отличие от ISO/OSI) Свойства TCP/IP протоколов: открытость, независимость от аппаратного обеспечения, стандартизация.
Соответствие уровней ISO/OSI – TCP/IP: 1,2 – 1 | 3 – 2 | 4,5 – 3 | 6,7 – 4
Установление соединения по протоколуTCP работает по принципу «трехшагового рукопожатия». Клиент посылает серверу запрос на соединение (SYN). Если сервер готов установить соединение, он отправляет клиенту SYN и ACK. После этого клиент подключается к серверу. Уже на этапе положительного ответа сервера клиенту сервер резервирует память под будущее соединение. Это недостаток, так как при достаточно большом количестве подключений к серверу возможен недостаток памяти.
2) Уровни до сетевого на примере IP (netmask, arp) MAC – адрес, уникальный идентификатор, присваиваемый каждому физическому устройству – 6 байт. IP —уникальный адрес узла в сети, построенной по протоколу TCP/IP. Представляет собой четырехбайтовое число. Маска сети – битовая маска, определяющая, какая часть IP-адреса узла сети относится к адресу сети, а какая — к адресу самого узла в этой сети. Например, узел с IP-адресом 12.34.56.78 и маской подсети 255.255.255.0 находится в сети 12.34.56.0/24 с длиной префикса 24 бита. С помощью маски модно определить, что один диапазон IP-адресов – в одной сети, а другой – в другой. IPv4-32 бита, IPv6-128 бит
DNS – компьютерная система о получении информации о домене. По DNS узнаем IP. У каждой машины есть таблица маршрутизации: адреса сетей, маски, шлюзы. (netstat –rn – показать таблицу)
ARP (протокол определения адреса) — протокол канального уровня, предназначенный для определения MAC-адреса по известному IP-адресу.
Узлы сети могут быть концентраторами и коммутаторами. Концентратор получает пакет и отдает его всем IP, которые хотят его получить Коммутатор получает пакет и пересылает его какому-то определенному IP Алгоритм пересылки пакета по протоколу TCP/IP: 1. Узел А с IP(A) и MAC(A) хочет отправить пакет данных узлу B c IP(B) на парт http(80) 2. Узел А посылает широковещательный запрос в локальной сети «Кто знает узел с IP(B)?» по протоколу ARP. 3. Когда узел А получил от узла С ответ «я знаю» или «это мой IP», он отсылает пакет данных узлу С 4. В случае, если узел С присылал ответ «я знаю», то передача пакета по протоколу все равно идет от имени IP(A), но уже с MAC(C). Сохранение IP нужно для того, чтобы процесс В смог узнать, от кого пришел пакет.
SCTP – транспортный протокол. Если кто-то отправил слишком много запросов к серверу TCP и сервер истратил все свои ресурсы, то SCTP от этого защищен – он не сразу резервирует память для будущего соединения (защита от ddos-атак). Это называется системой 4 рукопожатий. Первые 2 те же самые, но выделение памяти происходит только перед подключением клиента. RAID 2 Диски делятся на две группы — для данных и для кодов коррекции ошибок, причем если данные хранятся на 2n-n-1 дисках, то для хранения кодов коррекции необходимо n дисков. Данные записываются на соответствующие диски так же, как и в RAID 0. Оставшиеся диски хранят коды коррекции ошибок, по которым в случае выхода какого-либо жёсткого диска из строя возможно восстановление информации. Метод Хемминга давно применяется в памяти типа ECC и позволяет на лету исправлять однократные и обнаруживать двукратные ошибки. (-) для его функционирования нужна структура из почти двойного количества дисков
Данные разбиваются на байты и распределяются по дискам. Ещё один диск записывает побитово xor сумму остальных жестких дисков. Отличия RAID 3 от RAID 2: невозможность коррекции ошибок на лету и меньшая избыточность. (+)высокая скорость чтения и записи данных; минимальное количество дисков для создания массива – 3 один диск может сломаться (xor сумма восстановит его) (-) большая нагрузка на контрольный диск, и, как следствие, он часто ломается. Низкая скорость передачи маленьких файлов. Их проще было бы передавать без побайтового разбиения.
(+) удалось отчасти «победить» проблему низкой скорости передачи данных небольшого объёма. RAID 4 легко делать из RAID 0 (-) Запись производится медленно из-за записи на контрольный диск.
Решена проблема частой поломки RAID 3 и RAID 4. Запись контрольных сумм - диагональная. (+): Экономичность из-за редких поломок. При чтении выигрыш (потоки данных с разных жестких дисков обрабатываются параллельно) (-): Медленная запись из-за большого количества операций RAID 6 похож на RAID 5, но имеет более высокую степень надёжности — под контрольные суммы выделяется ёмкость 2-х дисков, рассчитываются 2 суммы по разным алгоритмам. (+) Обеспечивает работоспособность после одновременного выхода из строя двух дисков — защита от кратного отказа. Для организации массива требуется минимум 4 диска. (-) самый медленный из всех, требуется сильный контроллер RAID 10 – RAID 0 из RAID 1 (+) Надежность, скорость (-) Стоимость в 2 раза больше Сравнение:
Проблема write hole Возникает в RAID 3 – RAID 6 Если ОС отказывает в момент записи, то контрольная сумма может сбиться, и это необходимо исправить до поломки какого-либо из дисков. Иначе, если диск сломается, и мы начнем восстанавливать данные по xor сумме, то у нас будут неверные данные и мы не сможем понять, на каком этапе произошла ошибка.
ZFS строится поверх виртуальных пулов хранения данных. Каждый их них – жесткий диск или рейд. В ZFS нет проблемы write hole, т.к. это транзакционная файловая система. Транзакции не позволят записаться сумме неверно. При сбое транзакция не выполнится. Даже если не через транзакции, то по временным меткам мы поймем, в чем причина ошибки. 18. Планирование дисковых операций (кеширование, алгоритмы обхода дорожек диска) Кеширование Может происходить на разных уровнях. ОС использует часть ОП в качестве кэша дисковых операций. Уровни кэширования: · Уровень приложения: программа записывает промежуточные результаты работы, чтобы не считать их лишний раз. · Уровень ОС: храним разметку виртуальной памяти и все данные, которые часто требуются ОС · Уровень ЖД: скорость доступа к ОП больше. Некоторые блоки используются несколькими процессами одновременно, поэтому удобно их прочитывать один раз.
Алгоритмы обхода дорожек: Определяют, в каком порядке делать запись и чтение данных, накопленных в кэше. Типы: · Передача «как есть» - в том де порядке. Не целесообразно для наших стандартных файловых систем, т.к. головка будет постоянно перемещаться по разным участкам ЖД. Удобно для флэш-накопителей – у них нет головки. · Приоритетный тип. Административные данные важнее (например, записи в журналы), поэтому мы их обрабатываем раньше. · Приоритет + random. Пользовательские данные рандомно выберутся, и рано или поздно запишутся. · Random: данные на запись определяются случайным образом. Не используется. · Сканирование: берем самые близкие дорожки (проходим сектор слева направо и обратно). Поэтому если мы прошли один раз, а после этого что-то добавили, то при обратном проходе это будет обнаружено. · Цикличное сканирование: То же самое, но нет обратного хода. · Short: выбираем данные, расстояние между которыми наименьшее. Если очередь постоянно меняется, то этот способ эффективен. Логическая архитектура компьютера. Архитектуры: фон Неймана, гарвардская. 1) Архитектура фон Неймана Принцип совместного хранения программ и данных в памяти компьютера. Подразумевают физическое отделение процессорного модуля от устройств хранения программ и данных. Принципы фон Неймана: 1. Принцип двоичного кодирования. 2. Принцип однородности памяти. 3. Принцип адресуемости памяти. 4. Принцип последовательного программного управления. Предполагает, что программа состоит из набора команд, которые выполняются процессором автоматически друг за другом в определенной последовательности. 5. Принцип жесткости архитектуры. Неизменяемость в процессе работы топологии, архитектуры, списка команд.
2) Гарвардская архитектура Хранилище инструкций и хранилище данных представляют собой разные физические устройства. Канал инструкций и канал данных также физически разделены.
Отличие от архитектуры фон Неймана: В архитектуре фон Неймана процессор одновременно может либо читать инструкцию, либо читать/записывать единицу данных из памяти. То и другое не может происходить одновременно, поскольку инструкции и данные используют одну и ту же системную шину. В Гарвардской архитектуре процессор может читать инструкции и выполнять доступ к памяти данных в то же самое время, даже без кэш-памяти. Таким образом, компьютер с Гарвардской архитектурой может быть быстрее, поскольку доставка инструкций и доступ к данным не претендуют на один и тот же канал памяти. Также машина Гарвардской архитектуры имеет различные адресные пространства для команд и данных.
3. Средства распараллеливания/ускорения работы процессора: 1) Кэш — промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше идёт быстрее, чем выборка данных из ОЗУ и ЖД, за счёт чего уменьшается время доступа и увеличивается производительность компьютера. При доступе процессора в память сначала производится проверка, хранит ли кэш запрашиваемые из памяти данные. Если информация есть в кэше - попадание в кэш, обратный же случай называется кэш промахом. Попадание в кэш позволяет процессору немедленно произвести чтение или запись. В случае промаха в кэше новая запись из памяти (и то, что еще может потребоваться). Для добавления данных в кэш после кэш промаха может потребоваться вытеснение ранее записанных данных. Важно, чтобы в кэше лежали наиболее используемые данные.
2) Конвейер — это способ организации вычислений, используемый в современных процессорах.
Стадии работы процессора: - получение инструкции - декодирование инструкции - получение аргументов - выполнение - изменение регистра инструкций Минус: необходимость сбрасывать весь конвейер в случае, если ход программы изменился. Эту проблему пытаются решать предсказатели переходов.
3) Суперскалярность — архитектура вычислительного ядра, использующая несколько вычислителей (1 АЛУ складывает, другой умножает и т.п.) Если в процессе две команды не противоречат друг другу, и одна не зависит от результата другой, то может осуществляться параллельное выполнение команд.
4) Регистровые окна Регистры – участки "быстрой" памяти, расположенные в процессоре. Регистры делятся на специальные и общего назначения. Регистры общего назначения могут использоваться программой непосредственно (например, для хранения значений переменных). Регистры удобны
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 399; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.21.247.221 (0.013 с.) |

 Вызов функций
Вызов функций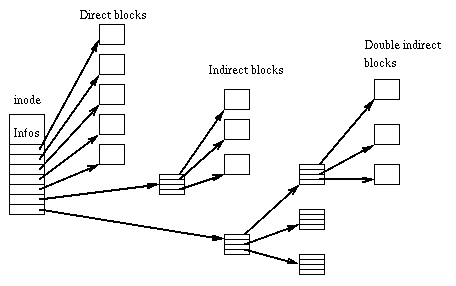 UFS
UFS RAID 3
RAID 3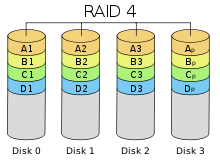 RAID 4 похож на RAID 3, но отличается от него тем, что данные разбиваются на блоки, а не на байты.
RAID 4 похож на RAID 3, но отличается от него тем, что данные разбиваются на блоки, а не на байты.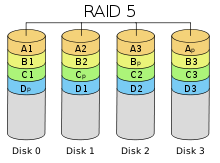 RAID 5
RAID 5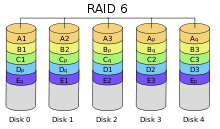
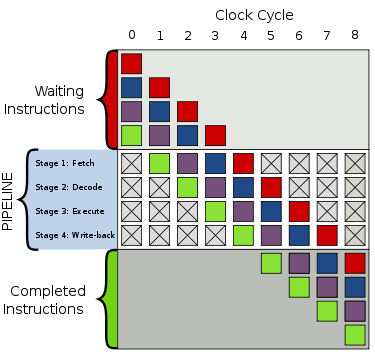 Идея: разделение обработки компьютерной инструкции на последовательность независимых.
Идея: разделение обработки компьютерной инструкции на последовательность независимых.


