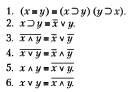Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Равносильные формулы алгебры логики. Основные равносильности.Содержание книги
Поиск на нашем сайте
Равносильные формулы – это две формулы алгебры логики, А и В, если они принимают одинаковые логические значения на любом наборе значений. Тождественно ложной называется формула, принимающая значение 0 при всех значениях входящих в нее переменных. Пример. Тождественно ложная формула: х ^ не х. конъюнкции, а отрицание относят к элементарным высказываниям. 18. Равносильности, выражающие одни логические операции через другие.
25. Классификация моделей данных Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними. В соответствии с рассмотренной ранее трехуровневой архитектурой приходится сталкиваться с понятием модели данных по отношению к каждому уровню Инфологические модели используются на ранних стадиях проектирования баз данных для формального описания предметной области. Они содержат информацию о классах объектов, их свойствах и взаимосвязях, описания структур данных без привязки к какой-либо конкретной СУБД. Инфологические (или семантические) модели отражают в естественной и удобной для разработчиков и других пользователей форме информацию о предметной области в процессе разработки структуры будущей базы данных. Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных списков. Кроме того, современные СУБД широко используют страничную организацию данных. В этом случае база данных представлена минимальным количеством файлов, а задачи поиска, чтения и записи данных выполняет сама СУБД, а не операционная система. Физические модели данных, основанные на страничной организации, являются наиболее перспективными. Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных. Даталогические модели являются моделями концептуального уровня и разрабатываются для конкретной СУБД. Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке. Модели, ориентированные на формат документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. Гораздо более простой и удобный, чем SGML, язык HTML (HyperText Markup Language – язык разметки гипертекста) позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. В настоящее время все большую популярность приобретает язык XML (eXtensible Markup Language – расширяемый язык разметки), позволяющий описывать документы произвольной структуры и содержания. Тезаурусные модели основаны на принципе организации словарей. Они содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям. Дескриптпорные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имеет жесткую структуру и описывает документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной базе данных. Например, для БД, содержащей описание патентов, дескриптор содержит название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных ведется исключительно по дескрипторам, то есть по тем параметрам, которые характеризуют патент, а не по самому тексту патента. Теоретико-графовые модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. Математической основой таких моделей является теория графов. Реляционная модель будет подробно рассмотрена далее.
26. Модель “СУЩНОСТЬ - СВЯЗЬ” Модель “сущность - связь” (МСС) (entity - relation diagram - ERD) является неформальной моделью предметной области (ПО) и используется на этапе инфологического проектирования БД. Моделируются объекты ПО и их взаимоотношения. Достоинства МСС: относительная простота; однозначность; применение естественного языка; доступность для понимания. Основное назначение МСС - семантическое описание ПО и представление информации для обоснования выбора видов моделей и структур данных, которые в дальнейшем будут использованы в информационной системе. Для построения МСС используются три основных конструктивных элемента для представления составляющих ПО - сущность, атрибут и связь. Информация о проекте представляется с использованием графических диаграмм. “Время” в составе конструктивных элементов отсутствует, но может быть представлено в модели посредством атрибутов (напр.: ГОД-РОЖДЕНИЯ-ПОЛУЧЕНО-В-ИЮНЕ,...). Сущность - собирательное понятие, некоторая абстракция реально существующего объекта, процесса или явления, о котором необходимо хранить информацию в системе.
Примеры сущностей: материальные: нематериальные: -предприятие; м -описание явления; н -изделие; м -рефераты научных статей; н -сотрудники; м -описание структур данных; н В моделях МСС каждая рассматриваемая сущность является основным местом сбора информации об этой сущности. “Тип сущности” определяет множество однородных объектов, а “экземпляр сущности” - конкретный объект из множества. Каждая сущность должна иметь имя. Например, сущность "СТУДЕНТ". “Атрибут” (А) - поименованнная характеристика сущности. При помощи атрибутов моделируются свойства сущностей: (сущность: КНИГА, атрибуты: НАЗВАНИЕ, АВТОР, ГОД-ИЗДАНИЯ). Основная роль атрибутов - описание свойств сущности. Другая роль - идентификация экземпляра сущности. То есть каждый экземпляр сущности должен иметь уникальное имя. В качестве имени выступает один или несколько атрибутов. Например, "НОМЕР ЗАЧЕТНОЙ КНИЖКИ" или "НОМЕР" и "СЕРИЯ ПАСПОРТА". “Связь” - средство представления отношений между сущностями в модели ПО. Тип связи рассматривается между типами сущностей, например, между сущностями СТУДЕНТ и ГРУППА может быть связь УЧИТЬСЯ. То есть введение связи между двумя сущностями отражает семантику некоторого предложения. В данном случае, это СТУДЕНТ УЧИТСЯ В ГРУППЕ. Конкретный экземпляр связи данного типа существует между конкретными экземплярами данных типов сущностей. Например, ИВАНОВ УЧИТСЯ КМ-31. В модели "сущность-связь" поддерживаются бинарные связи. В общем случае в ПО могут быть n - арные связи между сущностями.
27. Реляционная модель данных Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка. На реляционной модели данных строятся реляционные базы данных. Реляционная модель данных включает следующие компоненты: Структурный аспект (составляющая) — данные в базе данных представляют собой набор отношений. Аспект (составляющая) целостности — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных. Аспект (составляющая) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление). Кроме того, в состав реляционной модели данных включают теорию нормализации. Термин «реляционный» означает, что теория основана на математическом понятии отношение (relation). В качестве неформального синонима термину «отношение» часто встречается слово таблица. Необходимо помнить, что «таблица» есть понятие нестрогое и неформальное и часто означает не «отношение» как абстрактное понятие, а визуальное представление отношения на бумаге или экране. Некорректное и нестрогое использование термина «таблица» вместо термина «отношение» нередко приводит к недопониманию. Наиболее частая ошибка состоит в рассуждениях о том, что РМД имеет дело с «плоскими», или «двумерными» таблицами, тогда как таковыми могут быть только визуальные представления таблиц. Отношения же являются абстракциями, и не могут быть ни «плоскими», ни «неплоскими». Для лучшего понимания РМД следует отметить три важных обстоятельства: модель является логической, то есть отношения являются логическими (абстрактными), а не физическими (хранимыми) структурами; для реляционных баз данных верен информационный принцип: всё информационное наполнение базы данных представлено одним и только одним способом, а именно — явным заданием значений атрибутов в кортежах отношений; в частности, нет никаких указателей (адресов), связывающих одно значение с другим; наличие реляционной алгебры позволяет реализовать декларативное программирование и декларативное описание ограничений целостности, в дополнение к навигационному (процедурному) программированию и процедурной проверке условий. Принципы реляционной модели были сформулированы в 1969—1970 годах Э. Ф. Коддом (E. F. Codd). Идеи Кодда были впервые публично изложены в статье «A Relational Model of Data for Large Shared Data Banks»[1], ставшей классической. Строгое изложение теории реляционных баз данных (реляционной модели данных) в современном понимании можно найти в книге К. Дж. Дейта. «C. J. Date. An Introduction to Database Systems» («Дейт, К. Дж. Введение в системы баз данных»). Наиболее известными альтернативами реляционной модели являются иерархическая модель, и сетевая модель. Некоторые системы, использующие эти старые архитектуры, используются до сих пор. Кроме того, можно упомянуть об объектно-ориентированной модели, на которой строятся так называемые объектно-ориентированные СУБД, хотя однозначного и общепринятого определения такой модели нет.
Внешние ключи и связи
Внешний ключ – Foreign key - служит для связи таблиц. Это значения из одной таблицы, по которым можно однозначно привязаться к другой. Точнее говоря, для отношения внешний ключ - это опять-таки набор определенных заранее атрибутов. Например, в таблице точек наблюдений может быть атрибут «Административный Район», где для каждой точки проставлен код района, которому она принадлежит. Имеется таблица-справочник административных районов, в которой каждый район описан отдельной строкой. Для каждой точки по коду района можно найти его название и другие характеристики. Можно вообще соединить две таблицы в одну по этим ключам. Говорят, что атрибут «Район» – внешний ключ, ссылающийся на другую таблицу. Колонка ID в той, второй таблице, должна быть обязательно первичным ключом, иначе могут случайно сыскаться два одинаковых кода района в разных строках и система даст сбой, не сумеет однозначно привязаться. Итак, внешний ключ должен ссылаться на первичный ключ другой таблицы. В своей таблице он может быть обычным атрибутом, а может входить в состав первичного ключа, это заранее не известно. Например, если в таблице точек нумерация не сквозная по области, а порайонная, то атрибут «Район» логичным образом войдет в первичный ключ. К его внешней функции это не будет иметь прямого отношения.
Ссылочная целостность (англ. referential integrity) — необходимое качество реляционной базы данных, заключающееся в отсутствии в любом её отношении внешних ключей, ссылающихся на несуществующие кортежи. Определение Связи между данными, хранимыми в разных отношениях, в реляционной БД устанавливаются с помощью использования внешних ключей — для установления связи между кортежем из отношения A с определённым кортежем отношения B в предусмотренные для этого атрибуты кортежа отношения A записывается значение первичного ключа (а в общем случае значение потенциального ключа) целевого кортежа отношения B. Таким образом, всегда имеется возможность выполнить две операции: определить, с каким кортежем в отношении B связан определённый кортеж отношения A; найти все кортежи отношения A, имеющие связи с определённым кортежем отношения B. Благодаря наличию связей в реляционной БД можно хранить факты без избыточного дублирования, то есть в нормализованном виде. Ссылочная целостность может быть проиллюстрирована следующим образом: Дана пара отношений A и B, связанных внешним ключом. Первичный ключ отношения B — атрибут B.key. Внешний ключ отношения A, ссылающийся на B — атрибут A.b. Ссылочная целостность для пары отношений A и B имеет место тогда, когда выполняется условие: для каждого кортежа отношения A существует соответствующий кортеж отношения B, то есть кортеж, у которого (B.key = A.b). База данных обладает свойством ссылочной целостности, когда для любой пары связанных внешним ключом отношений в ней условие ссылочной целостности выполняется. Если вышеприведённое условие не выполняется, говорят, что в базе данных нарушена ссылочная целостность. Такая БД не может нормально эксплуатироваться, так как в ней разорваны логические связи между зависимыми друг от друга фактами. Непосредственным результатом нарушения ссылочной целостности становится то, что корректным запросом не всегда удаётся получить корректный результат.
28. Нормализация баз данных Нормализация — это формальный аппарат ограничений на формирование таблиц (отношений), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых данных и уменьшает трудозатраты на ведение (ввод, корректировку) базы данных. Процесс нормализации заключается в разложении (декомпозиции) исходных отношений БД на более простые отношения. При этом на каждой ступени этого процесса схемы отношений приводятся в нормальные формы. Для каждой ступени нормализации имеются наборы ограничений, которым должны удовлетворять отношения БД. Тем самым удаляется из таблиц базы избыточная неключевая информация. Процесс нормализации основан на понятии функциональной зависимости атрибутов: атрибут А зависит от атрибута В (В -> А), если в любой момент времени каждому значению атрибута В соответствует не более одного значения атрибута А. Зависимость» при которой каждый неключевой атрибут зависит от всего составного ключа и не зависит от его частей, называется полной функциональной зависимостью. Если атрибут А зависит от атрибута 5, а атрибут В зависит от атрибута С (С -> В -> А), но обратная зависимость при этом отсутствует, то зависимость Сот А называется транзитивной. Общее понятие нормализации подразделяется на несколько нормальных форм. Информационный объект (сущность) находится в первой нормальной форме (1НФ), когда все его атрибуты имеют единственное значение. Если в каком-либо атрибуте есть повторяющиеся значения, объект (сущность) не находится в 1НФ, и упущен, по крайней мере, еще один информационный объект (еще одна сущность). Например, задано следующее отношение: ПРЕДМЕТ (Код предмета. Название, Цикл, Объем часов, Преподаватели). Это отношение не находится в 1НФ, так как атрибут Преподаватели подразумевает возможность наличия нескольких фамилий преподавателей в записи, относящейся к какому-то конкретному предмету, что соответствует участию нескольких преподавателей в ведении одной дисциплины. Переведем атрибут с повторяющимися значениями в новую сущность, назначим ей первичный ключ (Код преподавателя) и свяжем с исходной сущностью ссылкой на ее первичный ключ (Код предмета). В результате получим две сущности, причем во вторую сущность добавятся характеризующие ее атрибуты: ПРЕДМЕТ (Код предмета. Название, Цикл, Объем часов); ПРЕПОДАВАТЕЛЬ (Код преподавателя, ФИО, Должность, Оклад, Адрес, Код предмета). Полученные выражения соответствуют случаю, когда несколько преподавателей могут вести один предмет, но каждый преподаватель не может вести более одной дисциплины. А если учесть, что на самом деле один лектор может читать более одной дисциплины, так же как одну и ту же дисциплину могут читать несколько лекторов, необходимо отказаться от жесткой привязки преподавателя к предмету в сущности ПРЕПОДАВАТЕЛЬ, создав дополнительную сущность ИЗУЧЕНИЕ, которая будет показывать, как связаны между собой преподаватели и предметы: ПРЕДМЕТ (Код предмета. Название, Цикл, Объем часов); ПРЕПОДАВАТЕЛЬ (Код преподавателя, ФИО, Должность, Оклад, Адрес); ИЗУЧЕНИЕ (Код предмета. Код преподавателя). Постреляционная модель Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Постреляционная модель представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных. Модель допускает многозначные поля – поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД соответствующих механизмов. Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки. Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Проектирование баз данных — процесс создания схемы базы данных и определения необходимых ограничений целостности. Основные задачи проектирования баз данных Основные задачи: Обеспечение хранения в БД всей необходимой информации. Обеспечение возможности получения данных по всем необходимым запросам. Сокращение избыточности и дублирования данных. Обеспечение целостности данных (правильности их содержания): исключение противоречий в содержании данных, исключение их потери и т.д..
29. Информационная безопасность ИБ — это общее понятие для защиты информационной среды, защита информации представляет собой деятельность по предотвращению утечки защищаемой информации, несанкционированных и непреднамеренных воздействий на защищаемую информацию. Система защиты инф-и – единый комплекс правовых норм, организационных мер, технических, программных и др.средств, обеспечивающих защищенность инф-и в соответствии с принятой политикой. Утечка – процесс неконтролируемого распространения инф-и за пределы круга лиц, имеющих право на работу с ней (прод.) 1. Разглашение – несанкционированное ознакомление с информацией. Раскрытие – опубликование инф-и в СМИ или использование закрытой инф-и во время выступлений. Распространение – открытое исп-е сведений. Доступность – возможность за приемлемое время получить требуемую инф.услугу. Целостность - актуальность и непротиворечивость инф-и, ее защищенность от разрушения и несанкционированного изменения. Конфиденциальность – защита от несанкционированного доступа к инф-и. 2. Направления обеспечения защиты инф-и Защита информации – комплекс мероприятий, направленный на обеспечение ИБ. Существует 4 направления обеспечения защиты инф-и: Правовое – заключается в соблюдении всех нормативно-правовых документов, регулирующих вопросы использования информационных ресурсов. Организационное – заключается в создании в организации комплекса административных мер, позволяющих разрешать или запрещать доступ сотрудников к определенной информации и средствам ее обработки, а также вырабатывающих правила работы с защищаемой информацией и определенной системы наказания за несоблюдение этих правил. Инженерно-техническое – отвечает за обеспечение защиты от технической разведки, за установку в организации технических средств охраны, за принятие мер по обеспечению защиты информации Программно-аппаратное – комплекс мер по защите информации, обрабатываемой на каждом отдельно взятом компьютере или передающейся в сети.
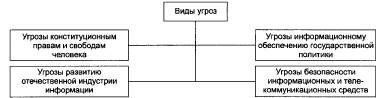
30.Организационно-правовое обеспечение информационной безопасности. Основные функции организационно-правовой базы следующие: □ разработка основных принципов отнесения конфиденциальных сведений к защищаемой информации; Созданием законодательной базы в области информационной безопасности каждое государство стремится защитить свои информационные ресурсы. Информационные ресурсы государства в самом первом приближении могут быть разделены на три большие группы: Угрозами конституционным правам и свободам человека и гражданина в области духовной жизни и информационной деятельности могут являться: □ принятие федеральными органами государственной власти правовых актов,ущемляющих конституционные права и свободы граждан в области духовной жизни и информационной деятельности; □ нерациональное, чрезмерное ограничение доступа к общественно необходимой информации; □ противоправное применение специальных средств воздействия на индивидуальное, групповое и общественное сознание; Угрозами развитию отечественной индустрии информации, включая индустрию средств информатизации, телекоммуникации и связи, могут являться: □ противодействие доступу РФ к новейшим информационным технологиям; □ создание условий для технологической зависимости РФ в области современных информационных технологий; □ закупка органами государственной власти импортных средств информатизации, телекоммуникации и связи при наличии отечественных аналогов; □ вытеснение с отечественного рынка российских производителей средств ин форматизации, телекоммуникации и связи; □ утечка информации по техническим каналам;
|
||||
|
|
Последнее изменение этой страницы: 2016-08-14; просмотров: 259; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.168.68 (0.011 с.) |