Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основні статистичні функції OpenOffice .Содержание книги
Поиск на нашем сайте
Тема Основні статистичні функції OpenOffice. Методи знаходження точкових оцінок. Мета Ознайомитись з основними статистичними функціями в Open Office та методами знаходження точкових оцінок основних розподілів. Теоретичні відомості Опрацювати матеріал Лекції №3. Для створення формул в Open Office є можливість використати наперед підготовані формули, які називаються функціями.
Для створення формули на основі використання функції потрібно виконати такі дії: · в клітинку, в якій обчислюється формула, ввести знак дорівнює =; · ввести ім’я функції; · в дужках ввести аргументи (вхідні значення) функції, які використовуються для виконання обчислень; · натиснути клавішу < Enter >. Аргументи функцій − це числа, адреси клітинок, адреси (назви) діапазонів та їх списки, а також інші функції. В Open Office можна вставити функцію (Paste Function) використовуючи команду, за допомогою якої можна підібрати потрібну функцію та отримати інформацію про те, які потрібні аргументи і в якому порядку вони повинні бути розміщені. Для виконання цієї команди потрібно виконати такі дії: · у меню Insert вибрати пункт Function …; · у діалоговому вікні, яке з’явиться, із списку категорій (Function category) вибираємо ту категорію, до якої відноситься потрібна функція (у даній лабораторній роботі доцільно використовувати функції з категорії Statistical); · із списку функцій (Function Name) вибрати потрібну функцію; · задати аргументи функції, помістивши значення у відповідні поля; · натиснути на кнопку OK. Можна також викликати список категорій за допомогою клавіші f. Статистичні функції Open Office . СРОТКЛ - Обчислює середнє абсолютних значень відхилень точок даних від середнього. СРЗНАЧ - Обчислює середнє арифметичне аргументів. СРЗНАЧА - Обчислює середнє арифметичне аргументів, включаючи числа, текст і логічні значення. БІНОМРАСП - Обчислює окреме значення біноміального розподілу. ХИ2РАСП - Обчислює односторонню вірогідність розподілу хі-квадрат. ХИ2ОБР - Обчислює зворотне значення односторонньої вірогідності розподілу хі-квадрат. ХИ2ТЕСТ - Обчислює значення критерію ДОВЕРИТЬ - Обчислює довірчий (надійний) інтервал для середнього значення за генеральною сукупністю. КОРРЕЛ - Обчислює коефіцієнт кореляції між двома множинами даних. СЧЁТ - Підраховує кількість чисел в списку аргументів. СЧЕТЗ - Підраховує кількість значень в списку аргументів. СЧИТАТЬПУСТОТЫ - Підраховує кількість порожніх клітинок в заданому діапазоні. СЧЁТЕСЛИ - Підраховує кількість непорожніх клітинок, що задовольняють заданій умові усередині діапазону. КОВАР - Обчислює коваріацію, тобто середнє добутків відхилень для кожної пари точок. КРИТБИНОМ - Обчислює найменше значення, для якого функція біномного розподілу менше або рівна заданому значенню. КВАДРОТКЛ - Обчислює суму квадратів відхилень. ЭКСПРАСП - Обчислює експоненціальний розподіл. FРАСП - Обчислює F -розподіл вірогідності. FРАСПОБР - Обчислює зворотне значення для F -розподілу вірогідності. ФИШЕР - Обчислює перетворення Фішера. ФИШЕРОБР - Обчислює зворотне перетворення Фішера. ПРЕДСКАЗ - Обчислює значення лінійного тренда. ЧАСТОТА - Обчислює розподіл частот у вигляді вертикального масиву. ФТЕСТ - Обчислює результат F -тесту. ГАММАРАСП - Обчислює гамма-розподіл. ГАММАОБР - Обчислює зворотне гамма-розподіл. ГАММАНЛОГ - Обчислює натуральний логарифм гамма функції. СРГЕОМ - Обчислює середнє геометричне. РОСТ - Обчислює значення відповідно до експоненціального тренда. СРГАРМ - Обчислює середнє гармонійне. ГИПЕРГЕОМЕТ - Обчислює гіпергеометричний розподіл. ОТРЕЗОК - Обчислює відрізок, що відсікається на осі лінією лінійної регресії. ЭКСЦЕСC - Обчислює ексцес множини даних. НАИБОЛЬШИЙ - Обчислює к - е найбільше значення з множини даних. ЛИНЕЙН - Обчислює параметри лінійного тренда. ЛГРФПРИБЛ - Обчислює параметри експоненціального тренда. ЛОГНОРМОБР - Обчислює зворотний логарифмічний нормальний розподіл. ЛОГНОРМРАСП - Обчислює інтегральний логарифмічний нормальний розподіл. МАКС - Обчислює максимальне значення із списку аргументів. МАКСА - Обчислює максимальне значення із списку аргументів, включаючи числа, текст і логічні значення. МЕДИАНА - Обчислює медіану заданих чисел. МИН - Обчислює мінімальне значення із списку аргументів. МИНА - Обчислює мінімальне значення із списку аргументів, включаючи числа, текст і логічні значення. МОДА - Обчислює значення моди множини даних. ОТРБИНОМРАСП - Обчислює негативний біномний розподіл. НОРМРАСП - Обчислює нормальну функцію розподілу. НОРМОБР - Обчислює зворотний нормальний розподіл. НОРМСТРАСП - Обчислює стандартний нормальний інтегральний розподіл. НОРМСТОБР - Обчислює зворотне значення стандартного нормального розподілу. ПИРСОН - Обчислює коефіцієнт кореляції Пірсона. ПЕРСЕНТИЛЬ - Обчислює к-ий персентиль для значень з інтервалу. ПРОЦЕНТРАНГ - Обчислює процентну норму значення в множини даних. ПЕРЕСТ - Обчислює кількість перестановок для заданого числа об'єктів. ПУАССОН - Обчислює розподіл Пуассона. ВЕРОЯТНОСТЬ - Обчислює вірогідність того, що значення з діапазону знаходиться усередині заданих меж. КВАРТИЛЬ - Обчислює квартиль множини даних. Зауваження
· ДИСП(VAR) – обчислює дисперсію на основі вибірки. Синтаксис: VAR (число1;число2;...) Число1, число2,... – це від 1 до 30 числових аргументів, які відповідають вибірці з генеральної сукупності.
· СТАНДОТКЛОН (STDEV) -обчислює стандартне відхилення на основі вибірки. Синтаксис: STDEV (число1;число2;...) Число1, число2,... – це від 1 до 30 числових аргументів, які відповідають вибірці з генеральної сукупності.
· МЕДИАНА (MEDIAN) – повертає медіану вказаних чисел. Медіана – це число, яке є серединою множини чисел; тобто половина чисел мають значення більші, ніж медіана, а інша половина – менші, ніж медіана. Синтаксис: MEDIAN (число1;число2;...) Число1, число2,... – це від 1 до 30 чисел, для яких визначається медіана.
· МОДА (MODE) – повертає значення в масиві або інтервалі даних, яке найчастіше трапляється або повторюється. Синтаксис: MODE (число1;число2;...) Число1, число2,... – це від 1 до 30 аргументів, для яких обчислюється мода. Можна також використовувати один масив або посилання на масив замість аргументів, які розділяються крапкою з комою.
· Э КСЦЕСС (KURT) – повертає ексцес вказаних чисел. Синтаксис: KURT (число1;число2;...) Число1, число2,... – це від 1 до 30 чисел, для яких визначається ексцес. Можна також використовувати один масив або посилання на масив замість аргументів, які розділяються крапкою з комою.
· СКОС (SKEW) -повертає асиметрію вказаних чисел. Синтаксис: SKEW (число1;число2;...) Число1, число2,... – це від 1 до 30 чисел, для яких визначається асиметрія. Можна також використовувати один масив або посилання на масив замість аргументів, які розділяються крапкою з комою.
Точкові оцінки параметрів основних розподілів:
В лабораторній роботі використовуються функції: · СРЗНАЧ (AVERAGE) — повертає середнє арифметичне аргументів. Синтаксис: AVERAGE (число1;число2;...) Число1, число2,... – це від 1 до 30 аргументів, для яких обчислюється середнє. Зауваження
· СТАНДОТКЛОН (STDEV) -обчислює стандартне відхилення на основі вибірки. Синтаксис: STDEV (число1;число2;...) Число1, число2,... – це від 1 до 30 числових аргументів, які відповідають вибірці з генеральної сукупності.
Хід роботи Типове навчальна завдання.
Відкриється порожня книжка(в іншому випадку створіть нову книжку).
Таблиця 1
Для побудови варіаційного ряду доцільно відсортувати попередньо введені дані (елементи вибірки).Для цього слід виділити фрагмент електронної таблиці – стовпчик А, який підлягає сортуванню і у вікні Sortby задати критерій сортування Ascending (зростаючий порядок). Індивідуальне завдання. Тема Основні статистичні функції OpenOffice.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-26; просмотров: 286; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.15.203.195 (0.006 с.) |

 .
.



 )
)
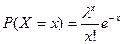
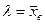
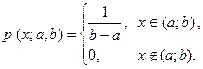
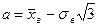 ;
; 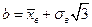
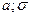 )
)