
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Распознавание алфавитно-цифровых данных
К задачам распознавания лиц (людей) тесно примыкают и задачи компьютерной обработки фотографий (видеоматериалов) с целью выделения на них алфавитноцифровой информации. Таких задач может быть несколько. Самая распространенная — это перевод текста с бумажного носителя в электронный для последующего редактирования. Сканер позволяет получить графический образ документа, который непосредственно может быть отредактирован только графическим редактором, например Paint. Такое редактирование могут применить злоумышленники для фальсификации документа, например изменения некоторых дат или денежных сумм. Возможна и замена фамилии лица, в документе, удостоверяющем какие-либо права. Именно такие возможности требуют обязательного наличия заверительной подписи и печати на ксерокопиях документов. Большую правку текстового документа графическим редактором производить неудобно. Графический образ необходимо преобразовать в текстовый файл. Наиболее распространенной программой для распознавания текстов является FineReader. Это профессиональная, распространяемая на коммерческих условиях программа. Принцип действия программы FineReader следующий: сканируется любой текст, затем картинка текста преобразуется в «обычный электронный текст», такой, как если бы вы его набрали с клавиатуры. Пользователю остается только сохранить текст на диске или скопировать его через буфер обмена в любой текстовый редактор. Программа FineReader предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках, может распознавать смешанные двуязычные тексты. С помощью программы FineReader можно выполнять пакетную обработку многострочных документов, а также программу можно «обучать» для повышения качества распознавания неудачно напечатанных текстов или сложных шрифтов, она позволяет редактировать распознанный текст, проверять его орфографию и сохранять результаты в текстовом редакторе MS Word, MS Excel. Программа позволяет объединять сканирование и распознавание в одну операцию. FineReader автоматически распознает разные участки текста: текст как таковой, картинку (рисунок), таблицу и так называемые «нераспознаваемые» блоки в тексте. Основные операции обработки бумажного документа в программе FineReader выполняются с помощью панели инструментов Scan & Read. На панели инструментов программы находятся соответствующие кнопки: Сканировать, Распознать, Проверить, Сохранить. Можно выполнять указанные операции и через меню Scan & Read в строке команд.
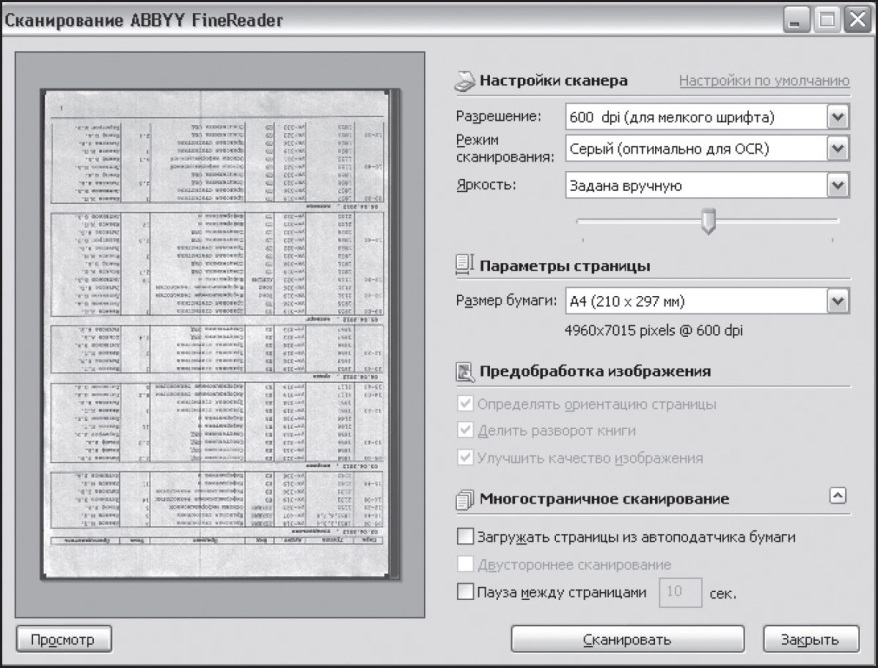
Процесс обработки документа состоит из следующих шагов: · сканирование документа; · распознавание документа; · редактирование и проверка результата; · сохранение документа. Первый этап работы — сканирование. На этом этапе используют сканер. Чтобы начать сканирование, необходимо включить сканер, положить оригинал документа (обычно левой стороной вниз) и раскрыть список кнопки Сканировать. В раскрывающемся меню следует выбрать пункт Опции и установить опции Определять ориентацию страницы, Делить разворот книги (если сканируете одновременно две страницы разворота из книги). Использование данных настроек позволяет получить вместо текста в две колонки две обычные странички, с которыми потом работать значительно легче. Далее необходимо установить настройки сканера: · подбор яркости (рекомендуется автоматический); · режим сканирования (черно-белый режим для документов высокого качества, серый — для большинства документов и цветной — при необходимости сохранения цветных картинок, цвета подложек и букв); · установить нужное разрешение (рекомендуется 300-400 dpi, в зависимости от качества оригинала); · установить паузу между страницами. После установления необходимых опций непосредственно переходим к сканированию. Кнопка Сканировать (Scan) запускает основной процесс сканирования, в результате которого мы видим на экране получившуюся фотографию. Остается сохранить ее на диске для дальнейшего использования. Сам процесс сканирования происходит в автоматическом режиме. Если требуется обработать много страниц, то лучше сначала все их отсканировать, а затем приступать к распознаванию. Это связано с тем, что сканирование требует присутствия пользователя из-за необходимости управления сканером (например, для смены страниц), а процесс распознавания может происходить в автоматическом ре жиме.
Когда процесс сканирования завершается, появляется окно Изображение с графическим текстом. Второй этап работы — разбиение текста на логические блоки. Дело в том, что в бумажном документе, например, на странице книги или журнала, текст не всегда располагается в фиксированном порядке. Он может размещаться в нескольких колонках (столбцах), содержать иллюстрации (и подписи к ним), другие элементы форматирования. Дополнительные врезки и данные, представленные в таблицах, также могут запутать естественный порядок текста. Поэтому, прежде чем включать текст в документ, его разбивают на блоки, содержащие цельные фрагменты. Блоки распознают последовательно. Полученный текст включается в документ в порядке нумерации блоков. Для выделения блоков используются инструменты на панели Изображение: · · · · ПРИМЕЧАНИЕ
|
|||||||
|
|
Последнее изменение этой страницы: 2021-03-09; просмотров: 200; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.224.246.203 (0.008 с.) |
 — удалить выделенные на картинке лишние части блока текста;
— удалить выделенные на картинке лишние части блока текста; — удалить выделенный блок;
— удалить выделенный блок; — выделить табличный блок;
— выделить табличный блок; и
и  — выделить текстовый блок и блок-картинку.
— выделить текстовый блок и блок-картинку.


