Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Понятие фонетической транскрипции и фонетического поискаСодержание книги
Поиск на нашем сайте
Содержание
Введение . Фонетический поиск Понятие фонетической транскрипции и фонетического поиска Выводы . Общие сведения о фонетических алгоритмах Алгоритм Soundex Алгоритм NYSIIS Алгоритм Daitch-Mokotoff Soundex Алгоритм Metaphone Алгоритм Caverphone Выводы . Фонетические алгоритмы для русского языка Описание алгоритма Фонетик Реализация алгоритма Metaphone для русского языка Выводы Заключение Список использованных источников Приложение
Введение
В настоящее время компьютеры содержат огромное количество данных. Однако извлечение текстовой информации затрудняется, когда написано с ошибками или когда неточно известно его написание. Методы и алгоритмы анализа строк находят практическое применение во многих областях науки и информационных технологий: глобальные поисковые системы, сжатие данных, криптография, распознавание речи, компьютерное зрение, генетика и молекулярная биология. Одной из актуальных сфер применения таких алгоритмов являются также задачи сопровождения БД, входящих в состав различных информационных систем. Типичными и часто обсуждаемыми на форумах программистов являются задачи сопоставления и идентификации объектов, сведения о которых хранятся в разных БД. Это могут быть, например, списки клиентов телефонных компаний, покупателей различных товаров и услуг, клиентов банка, сведения о пассажирах различных видов транспорта, которые должны поступать в единую БД, и т.д. В настоящее время известно значительное количество методов и алгоритмов анализа текстовой информации, параметры которых, характеризующие их быстродействие и ресурсоемкость, хорошо исследованы. Вместе с тем при описании алгоритмов анализа текстов редко указываются параметры, характеризующие их релевантность по отношению к конкретной задаче сопоставления записей. Специфика обработки имен физических лиц более полно учтена в известных алгоритмах сравнения двух строк по их звучанию - Soundex и MetaPhone. В данной работе я собираюсь объяснить процедуры, конструирующие фонетические коды для искомого текста, который звучит одинаково, но пишется по-разному. Фонетический поиск
Выводы
Запись устной речи в полном соответствии с ее звучанием не может быть осуществлена обычным орфографическим письмом. При орфографическом письме отсутствует полное соответствие между звуками и буквами, в графике отсутствуют знаки, необходимые для записи всех звуков устной речи. Указанные затруднения устраняются особым видом письма, который называется фонетической транскрипцией. Мы привыкли видеть слова в графической форме, в виде последовательности букв. Это представление кажется нам наиболее естественным, так как мы постоянно с ним сталкиваемся. И поэтому неудивителен первый порыв разработчиков использовать это представление в своих программах обработки текстов. Такое решение вполне оправдано, например, в программах проверки орфографии. Но если мы хотим моделировать словоизменительные и словообразовательные процессы, то наиболее удобным будет фонематическое представление языковой информации, в виде последовательности фонем. Дело в том, что живой язык подчиняется фонетическим законам более, нежели законам орфографическим, и учёт этого факта значительно упрощает алгоритмы морфологического или словообразовательного анализа и синтеза, избавляя их от необходимости учёта орфографических особенностей. Общие сведения о фонетических алгоритмах
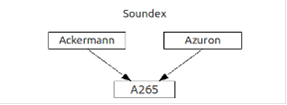
Алгоритм Soundex Одним из первых был алгоритм Soundex, изобретенный еще в 10-x годах прошлого века Робертом Расселом. Этот алгоритм (а точнее, его американская версия) сопоставляет словам численный индекс вида A126. Принцип его работы основан на разбиении согласных букв на группы с порядковыми номерами, из которых затем и составляется результирующее значение. Позднее также был предложен ряд улучшений. Первая буква сохраняется, последующие буквы сопоставляются цифрам по таблице. Символы, не представленные в таблице (а это все гласные и некоторые согласные), игнорируются. Смежные символы, или символы, разделенные буквами H или W, входящие в одну и ту же группу, записываются как один. Результат обрезается до 4 символов. Недостающие позиции заполняются нулями. Несложно заметить, что после всех этих процедур остается всего лишь 7 тысяч различных вариаций такого кода, что влечет за собой множество совершенно ничем не похожих друг на друга слов, имеющих одинаковый Soundex-код. Таким образом, результат в большинстве случаев включает в себя большое количество «ложноположительных» значений.
Рисунок 2.1 - Структура алгоритма Soundex
В улучшенной версии, как можно заметить, буквы разбиты на большее количество групп. Помимо этого, никакого особого внимания буквам H и W не уделяется, они просто игнорируются. Кроме того, никаких операций с длиной результата не производится - код не имеет фиксированной длины и не обрезается. Приведем примеры работы данного алгоритма. Оригинальный Soundex:→ Дедловский, Дедловских, Дидилев, Дителев, Дудалев, Дудолев, Дутлов, Дыдалев, Дятлов, Дятлович.→ Нагимов, Нагмбетов, Назимов, Насимов, Нассонов, Нежнов, Незнаев, Несмеев, Нижневский, Никонов, Никонович, Нисенблат, Нисенбаум, Ниссенбаум, Ногинов, Ножнов. Улучшенный Soundex:→ Насимов, Нассонов, Никонов.→ Нисенбаум, Ниссенбаум.→ Нагимов, Нагонов, Неганов, Ногинов.→ Нагмбетов.→ Назимов, Нежнов, Ножнов Алгоритм NYSIIS Разработанный в 1970 году как часть системы «New York State Identification and Intelligence System», этот алгоритм дает несколько лучшие результаты относительно оригинального Soundex, используя более сложные правила преобразования исходного слова в результирующий код. Этот алгоритм разработан для работы именно с американскими фамилиями. Алгоритм Metaphone
Несколько лучшими характеристиками обладает алгоритм Metaphone (1990 год), отличающийся от предыдущих алгоритмов несколько иным подходом к процессу кодирования: он преобразует исходное слово с учетом правил английского языка, используя заметно более сложные правила, и при этом теряется значительно меньше информации, так как буквы не разбиваются на группы. Итоговый код представляет собой набор символов из множества 0BFHJKLMNPRSTWXY, в начале слова также могут быть гласные из множества AEIOU. Алгоритм Caverphone
Алгоритм фонетического сравнения Каверфон (Caverphone) был создан в рамках Кавершамского проекте в университете Отаго в Новой Зеландии в 2002 году. Алгоритм позволяет акценты присутствующие в изучаемой зоне (южная часть города Дунедин, Новой Зеландия). Новая версия Каверфон 2.0 была предложена для более общего фонетического сравнения. Выводы фонетический транскрипция алгоритм код Большая часть этих алгоритмов реализована на множестве языков, в том числе на C, C++, Java, C# и PHP. Некоторые из них, например Soundex и Metaphone, интегрированы или реализованы в виде плагинов для многих популярных СУБД, а также используются в составе полноценных поисковых движков, например, Apache Lucene <http://lucene.apache.org/>. Область их применения довольно специфична, ведь значительного повышения удобства для пользователей можно добиться лишь при поиске фамилий, но тем не менее грамотное их использование - это плюс для поисковых систем. Описание алгоритма Фонетик
Фонетик получает на вход исходную строку и на основе правил, учитывающих произношение букв и слогов в русском языке, вырабатывает на выходе новую строку, называемую ключом для исходной строки. Ключ имеет переменную длину; из одной строки можно получить только один ключ. Алгоритм включает следующие шаги. . Преобразование строки в верхний регистр (это позволяет уменьшить алфавит в 2 раза и отсечь ошибки, связанные со случайными заглавными буквами в середине слова.) . Удаление непроизносимых букв, а также знаков препинания. . Замена сходных по начертанию латинских букв (A, B, C, E, H, O, P, T X, Y) на русские аналогичного начертания (А, В, С, Е, Н, О, Р, Т, Х, У). . Выработка ключа с использованием имени и отчества либо только инициалов в зависимости от выбранной настройки и полноты исходных данных. . Замена гласных букв на те, которые слышатся на их месте в безударном слоге. Буквы О, Ы, А, Я заменяются на А; Ю, У на У; Е, Е, Э, И на И. Несмотря на то, что в русском языке произношение буквы часто не соответствует написанию, сокращать слова до одних согласных нельзя, поскольку существует ряд парных глухих и звонких. С точки зрения грамматики русского языка такой подход не является абсолютно верным, но на практике показывает хорошие результаты. . Оглушение согласных в соответствии с правилами русского языка. В слабой позиции по звонкости-глухости в области согласных происходит оглушение, при котором все звонкие согласные (кроме сонорных) на конце слова произносятся как парные им глухие, а также два конечных звонких переходят в соответствующие глухие. Алгоритм не оглушает согласные до сонорных звуков. . Замена последовательностей букв, которые не встречаются в русском языке, на необходимые из словаря слогов. . Удаление парных согласных. Частой ошибкой является некорректное написание парных согласных. Для этих ситуаций создаются одинаковые ключи с одной повторяющейся буквой, которые будут найдены независимо от написания. . Замена типовых для русского языка окончаний фамилий на специальные символы. Эта команда сокращает время обработки и экономит место для хранения ключей. Данное преобразование имеет смысл только для фамилий. Пункты 1, 2, 5, 6, 8, 9 с некоторыми изменениями заимствованы из реализации алгоритма MetaPhone [4]. Для повышения качества сравнения алгоритм дополнен следующими этапами. . В большинстве случаев в информационной системе вместе с фамилией присутствуют имя и отчество, тогда имеет смысл привязать их к ключу. Имя и отчество обрабатываются отдельно от фамилии согласно пп. 1-6 алгоритма и дополняют ключ, полученный на основе фамилии. Если в одной системе в данных присутствуют лишь инициалы, то у обеих строк данные для обработки сокращаются до фамилии и первых букв имени и отчества, преобразованных к верхнему регистру. . В связи с тем, что персональные данные нередко получают из источника данных невысокого качества, о чем свидетельствует наличие инициалов вместо полноценных имени и отчества, имеет смысл заменять в ключе символы инициалов на сходные по написанию. Если рассмотреть графическое начертание букв, то И имеет сходство с Н, следовательно, в инициалах они могут быть заменены друг на друга. Остальные буквы остаются без изменений. . Итоговый ключ формируется конкатенацией ключа, полученного из фамилии, и результатов обработки имени и отчества или инициалов. В таблице 3.1 приведен пример списка, подаваемого на вход алгоритма, и соответствующих выходных значений.
Таблица 3.1 - Работа алгоритма фонетик
Таким образом, получается список ключей, на основе которого можно строить таблицу соответствия идентификационных данных лиц из разных БД. Для проверки релевантности алгоритма Фонетик из автоматизированной банковской системы было выгружено 25907 записей о физических лицах. Этот массив данных был получен слиянием нескольких БД и содержал некоторое количество дублирующих записей о физических лицах, которые не были обнаружены средствами СУБД во время слияния. Весь массив данных обработан экспертами, которые выявили в нем 661 дублирующую запись. Анализ сформированного массива данных о физических лицах проведен алгоритмами Фонетик, прямого сравнения, Soundex и алгоритмом, рассчитывающим дистанцию Левенштейна. Алгоритмы запускались на данной выборке по очереди, по принципу сравнения каждой записи с каждой. В алгоритме, вычисляющем дистанцию Левенштейна, записи считались различными, если дистанция редактирования превышала единицу. Перед применением алгоритма Soundex, разработанного для английского языка, записи подвергались транслитерации. В качестве нулевой гипотезы H0 полагалось, что сравниваемые записи соответствуют одному физическому лицу. Типы ошибок в работе алгоритмов определялись по таблице 3.2, в которой символом H1 обозначена гипотеза, противоположная H0.
Таблица 3.2 - Типы ошибок
По итогам работы всех алгоритмов была заполнена результирующая таблица с количеством ошибок для каждого алгоритма. По общему количеству ошибок сравнения наихудшие результаты показал алгоритм, вычисляющий дистанцию Левенштейна. Второе место по общему количеству ошибок после алгоритма Фонетик занимает алгоритм прямого сравнения. Однако в данном случае значимость ошибок первого и второго рода различна. Наиболее критичными являются ошибки первого рода, поскольку сходные объекты, классифицированные как различные, не попадут в итоговую выборку, то есть будут потеряны. Наличие ошибки второго рода не столь критично, так как на практике все объекты, классифицированные как сходные, будут представлены для последующей обработки в ручном режиме, а значит, будут проконтролированы. По количеству ошибок первого рода алгоритм Фонетик на порядок эффективнее алгоритмов, вычисляющих дистанцию Левенштейна, и алгоритма Soundex. Алгоритм прямого сравнения оказался наименее эффективным по количеству ошибок 1-го рода. Алгоритм Фонетик при сравнении строк, содержащих фамилию, имя и отчество физического лица, показывает высокую стабильность и эффективность в работе, отличается хорошей приспособленностью к нормам и правилам русского языка, высокой релевантностью, низкими показателями ошибок первого и второго рода. Использование технологии поиска сходных записей на основе данного алгоритма позволяет снизить избыточность БД, сократить долю ручного труда операторов, в реальном времени отслеживать историю обращений клиента, а также проводить интеллектуальную обработку, например резервирование или репликацию, и прочие операции с данными, требующие больших затрат времени. Фонетик хорошо подходит в качестве инструмента сопровождения автоматизированных банковских систем, систем денежных переводов, иных программных средств, требующих непосредственного взаимодействия оператора системы с физическими лицами, информация о которых вносится в систему. Выводы
Изучив фонетические алгоритмы можно коротко охарактеризовать каждый из них. Алгоритм Фонетик при сравнении строк, содержащих фамилию, имя и отчество физического лица, показывает высокую стабильность и эффективность в работе, отличается хорошей приспособленностью к нормам и правилам русского языка, низкими показателями ошибок. Использование технологии поиска сходных записей на основе данного алгоритма позволяет снизить избыточность БД, сократить долю ручного труда операторов, в реальном времени отслеживать историю обращений клиента, а также проводить интеллектуальную обработку, например резервирование или репликацию, и прочие операции с данными, требующие больших затрат времени.позволяет вам искать похожие по звучанию слова, в частности, фамилии. Он упростит работу кассиров в банке, почтовых служб и облегчит вам решение любых других бизнес-задач, связанных с обработкой личных данных клиентов.
Заключение
Методы и алгоритмы анализа строк находят практическое применение во многих областях науки и информационных технологий: глобальные поисковые системы, сжатие данных, криптография, распознавание речи, компьютерное зрение, генетика и молекулярная биология. Одной из актуальных сфер применения таких алгоритмов являются также задачи сопровождения БД, входящих в состав различных информационных систем (ИС). Типичными и часто обсуждаемыми на форумах программистов являются задачи сопоставления и идентификации объектов, сведения о которых хранятся в разных БД. В частности, к подобным задачам относят поиск, сопоставление и слияние персональных данных о физических лицах. Это могут быть, например, списки клиентов телефонных компаний, покупателей различных товаров и услуг, клиентов банка. Следует отметить, что изначально ни один из алгоритмов изначально не разрабатывался для сравнения данных о физических лицах. Специфика обработки имен физических лиц более полно учтена в известных алгоритмах сравнения двух строк по их звучанию - Soundex и MetaPhone. Описание алгоритма Soundex дано в классическом учебнике по программированию [1], алгоритм MetaPhone адаптирован для русского языка в работе [2]. Эти алгоритмы основаны на построении некоторой хэш-функции, преобразующей исходные строки в хэш-код, одинаковый для схожих строк. Процесс сравнения двух строк сводится к вычислению хэш-кодов этих строк и их последующего строгого сравнения. Строки, имеющие одинаковый хэш-код, считаются похожими. Об эффективности подобных алгоритмов говорит тот факт, что в некоторых языках программирования сравнение подобного рода организовано в качестве стандартной процедуры. Например, в MySQL и PHP функция Soundex является встроенной. Приложение Программа для АЛГОРИТМА METAPHONE
#include <stdio.h> #include <string.h> #include <ctype.h> #define TRUE (1) #define FALSE (0) #define NULLCHAR (char *) 0*VOWELS="AEIOU", *FRONTV="EIY", *VARSON="CSPTG", *DOUBLE=".";*excpPAIR="AGKPW", *nextLTR ="ENNNR";*chrptr, *chrptr1;phonetic(name,metaph,metalen) char *name, *metaph;metalen; {ii, jj, silent, hard, Lng, lastChr;curLtr, prevLtr, nextLtr, nextLtr2, nextLtr3;vowelAfter, vowelBefore, frontvAfter;wname[60];*ename=wname;= 0;(ii=0; name[ii]!= '\0'; ii++) {(isalpha(name[ii])) {[jj] = toupper(name[ii]);++; } }[jj] = '\0';(strlen(ename) == 0) return;((chrptr=strchr(excpPAIR,ename[0]))!= NULLCHAR) {= nextLTR + (chrptr-excpPAIR);(*chrptr1 == ename[1]) strcpy(ename,&ename[1]); }(ename[0] == 'X') ename[0] = 'S'; if (strncmp(ename,"WH",2) == 0) strcpy(&ename[1], &ename[2]);= strlen(ename);= Lng -1;(ename[lastChr] == 'S') {[lastChr] = '\0';= strlen(ename);= Lng -1; } for (ii=0; ((strlen(metaph) < metalen) && (ii < Lng)); ii++) { curLtr = ename[ii];= FALSE; prevLtr = ' ';(ii > 0) {= ename[ii-1];(strchr(VOWELS,prevLtr)!= NULLCHAR) vowelBefore = TRUE; }(ii == 0 && (strchr(VOWELS,curLtr)!= NULLCHAR)) {(metaph,&curLtr,1);; }= FALSE; frontvAfter = FALSE; nextLtr = ' ';(ii < lastChr) {= ename[ii+1];(strchr(VOWELS,nextLtr)!= NULLCHAR) vowelAfter = TRUE;(strchr(FRONTV,nextLtr)!= NULLCHAR) frontvAfter =TRUE;(curLtr == nextLtr && (strchr(DOUBLE,nextLtr) == NULLCHAR)) continue;= ' ';(ii < (lastChr-1)) nextLtr2 = ename[ii+2];= ' ';(ii < (lastChr-2)) nextLtr3 = ename[ii+3];(curLtr) {'B': silent = FALSE;(ii == lastChr && prevLtr == 'M') silent = TRUE;(! silent) strncat(metaph,&curLtr,1);;'C': if (! (ii > 1 && prevLtr == 'S' && frontvAfter))(ii > 0 && nextLtr == 'I' && nextLtr2 == 'A')(metaph,"X",1);(frontvAfter)(metaph,"S",1);(ii > 1 && prevLtr == 'S' && nextLtr == 'H')(metaph,"K",1);(nextLtr == 'H')(ii == 0 && (strchr(VOWELS,nextLtr2) == NULLCHAR))(metaph,"K",1);(metaph,"X",1);(prevLtr == 'C')(metaph,"C",1);(metaph,"K",1);;'D': if (nextLtr == 'G' && (strchr(FRONTV,nextLtr2)!= NULLCHAR))(metaph,"J",1);(metaph,"T",1);;'G': silent=FALSE; /* SILENT -gh- except for -gh and no vowel after h */((ii < (lastChr-1) && nextLtr == 'H') && (strchr(VOWELS,nextLtr2) == NULLCHAR))=TRUE;((ii == (lastChr-3)) && nextLtr == 'N' && nextLtr2 == 'E' && nextLtr3 == 'D')=TRUE;((ii == (lastChr-1)) && nextLtr == 'N') silent=TRUE;(prevLtr == 'D' && frontvAfter) silent=TRUE;(prevLtr == 'G')=TRUE;=FALSE;(!silent)(frontvAfter && (! hard))(metaph,"J",1);(metaph,"K",1);;'H': silent = FALSE;(strchr(VARSON,prevLtr)!= NULLCHAR) silent = TRUE;(vowelBefore &&!vowelAfter) silent = TRUE;(!silent) strncat(metaph,&curLtr,1);;'F':'J':'L':'M':'N':'R': strncat(metaph,&curLtr,1);;'K': if (prevLtr!= 'C') strncat(metaph,&curLtr,1);;'P': if (nextLtr == 'H')(metaph,"F",1);(metaph,"P",1);;'Q': strncat(metaph,"K",1);;'S': if (ii > 1 && nextLtr == 'I' && (nextLtr2 == 'O' || nextLtr2 == 'A'))(metaph,"X",1);(nextLtr == 'H')(metaph,"X",1);(metaph,"S",1);;'T': if (ii > 1 && nextLtr == 'I' && (nextLtr2 == 'O' || nextLtr2 == 'A'))(metaph,"X",1);(nextLtr == 'H')(ii > 0 || (strchr(VOWELS,nextLtr2)!= NULLCHAR))(metaph,"0",1);(metaph,"T",1);(! (ii < (lastChr-2) && nextLtr == 'C' && nextLtr2 == 'H'))(metaph,"T",1);;'V': strncat(metaph,"F",1);;'W':'Y': if (ii < lastChr && vowelAfter) strncat(metaph,&curLtr,1);;'X': strncat(metaph,"KS",2);;'Z': strncat(metaph,"S",1);;; }metaphone(argc)argc; {name[128];metaph[50];(argc!= 1) {(stderr, "metaphone: argc!= 1\n");("");(1); }(name, sizeof(name));[0] = '\0';(name,metaph,20);(metaph);(1); } Содержание
Введение . Фонетический поиск Понятие фонетической транскрипции и фонетического поиска Выводы . Общие сведения о фонетических алгоритмах Алгоритм Soundex Алгоритм NYSIIS Алгоритм Daitch-Mokotoff Soundex Алгоритм Metaphone Алгоритм Caverphone Выводы . Фонетические алгоритмы для русского языка Описание алгоритма Фонетик Реализация алгоритма Metaphone для русского языка Выводы Заключение Список использованных источников Приложение
Введение
В настоящее время компьютеры содержат огромное количество данных. Однако извлечение текстовой информации затрудняется, когда написано с ошибками или когда неточно известно его написание. Методы и алгоритмы анализа строк находят практическое применение во многих областях науки и информационных технологий: глобальные поисковые системы, сжатие данных, криптография, распознавание речи, компьютерное зрение, генетика и молекулярная биология. Одной из актуальных сфер применения таких алгоритмов являются также задачи сопровождения БД, входящих в состав различных информационных систем. Типичными и часто обсуждаемыми на форумах программистов являются задачи сопоставления и идентификации объектов, сведения о которых хранятся в разных БД. Это могут быть, например, списки клиентов телефонных компаний, покупателей различных товаров и услуг, клиентов банка, сведения о пассажирах различных видов транспорта, которые должны поступать в единую БД, и т.д. В настоящее время известно значительное количество методов и алгоритмов анализа текстовой информации, параметры которых, характеризующие их быстродействие и ресурсоемкость, хорошо исследованы. Вместе с тем при описании алгоритмов анализа текстов редко указываются параметры, характеризующие их релевантность по отношению к конкретной задаче сопоставления записей. Специфика обработки имен физических лиц более полно учтена в известных алгоритмах сравнения двух строк по их звучанию - Soundex и MetaPhone. В данной работе я собираюсь объяснить процедуры, конструирующие фонетические коды для искомого текста, который звучит одинаково, но пишется по-разному. Фонетический поиск
Понятие фонетической транскрипции и фонетического поиска
Запись устной речи в полном соответствии с ее звучанием не может быть осуществлена обычным орфографическим письмом. При орфографическом письме отсутствует полное соответствие между звуками и буквами, в графике отсутствуют знаки, необходимые для записи всех звуков устной речи. Указанные затруднения устраняются особым видом письма, который называется фонетической транскрипцией Звуки речи, не обладая собственным значением, являются средством для различения слов. Изучение различительной способности звуков речи является особым аспектом фонетического исследования и носит название фонологии. Фонологический, или функциональный, подход к звукам речи занимает ведущее положение в изучении языка; изучение акустических свойств звуков речи (физический аспект) тесно связано с фонологией. Для обозначения звука, когда он рассматривается со стороны фонологической, пользуются термином фонема. Как правило, звуковые оболочки слов и их форм различны, если исключить омонимы. Слова, имеющие одинаковый звуковой состав, могут различаться местом ударения (муку - муку, муки - муки) или порядком следования одинаковых звуков (кот - ток). Слова могут содержать и такие наименьшие, далее не членимые единицы речевого звучания, которые самостоятельно разграничивают звуковые оболочки слов и их форм, например: бак, бок, бук; в данных словах звуки [а], [о], [у] различают звуковые оболочки этих слов и выступают как фонемы. Слова бачок и бочок различаются на письме, но произносятся одинаково [б?чок]: звуковые оболочки этих слов не различаются, потому что звуки [а] и [о] в приведенных словах оказываются в первом предударном слоге и лишаются той различительной роли, какую они выполняют в словах бак - бок. Следовательно, фонема служит для различения звуковой оболочки слов и их форм. Фонемы дифференцируют не значение слов и форм, а лишь их звуковые оболочки, указывают на различия в значении, но не раскрывают их характера. Различное качество звуков [а] и [о] в словах бак - бок и бачок - бочок объясняется различным местом, которое эти звуки занимают в словах по отношению к словесному ударению. Кроме того, при произнесении слов возможно влияние одного звука на качество другого, и вследствие этого качественный характер звука оказывается обусловленным позицией звука - положением после другого звука или перед ним, между другими звуками. В частности, для качества гласных звуков оказывается важным положение по отношению к ударному слогу, а для согласных - положение в конце слова. Так, в словах рог - рога [рок] - [р?га] согласный звук [г] (на конце слова) оглушается и произносится как [к], а гласный звук [о] (в первом предударном слоге) звучит как а [л]. Следовательно, качество звуков [о] и [г] в данных словах оказывается в той или иной степени зависимым от позиции этих звуков в слове. Понятие фонемы предполагает разграничение самостоятельных и зависимых признаков звуков речи. Самостоятельные и зависимые признаки звуков соотносятся неодинаково у разных звуков и в различных фонетических условиях. Так, например, звук [з] в словах создал и раздел характеризуется двумя самостоятельными признаками: способом образования (щелевой звук) и местом образования (зубной звук). Кроме самостоятельных признаков, звук [з] в слове создал [создъл] имеет один зависимый признак - звонкость (перед звонким [д]), а в слове раздел [р?здел] - два зависимых признака, обусловленных позицией звука: звонкость (перед звонким [д]) и мягкость (перед мягким зубным [д]). Отсюда следует, что в одних фонетических условиях у звуков преобладают признаки самостоятельные, а в других - зависимые. Учет самостоятельных и зависимых признаков уточняет понятие фонемы. Независимые качества образуют самостоятельные фонемы, которые употребляются в одной и той же (тождественной) позиции и различают звуковые оболочки слов. Зависимые качества звука исключают возможность употребления звука в тождественной позиции и лишают звук различительной роли и потому образуют не самостоятельные фонемы, а лишь разновидности одной и той же фонемы. Следовательно, фонемой называется кратчайшая звуковая единица, независимая по своему качеству и потому служащая для различения звуковых оболочек слов и их форм. Качество гласных звуков [а], [о], [у] в словах бак, бок, бук фонетически не обусловлено, не зависит от позиции, а употребление этих звуков тождественно (между одинаковыми согласными, под ударением). Поэтому выделенные звуки обладают различительной функцией и, следовательно, являются фонемами. В словах мать, мята, мять [ма•т', м'•ать, м'aт'] ударный звук [а] различается по качеству, так как употребляется не в тождественной, а в различных позициях (перед мягким, после мягкого, между мягкими согласными). Поэтому звук [а] в словах мать, мята, мять не имеет непосредственно различительной функции и образует не самостоятельные фонемы, а лишь разновидности одной и той же фонемы <а>. Фонетический алгоритм является алгоритмом для индексации <http://en.academic.ru/dic.nsf/enwiki/651716> из слов их произношение. Большинство фонетических алгоритмов были разработаны для использования английского языка, следовательно, применяя правила к словам в других языках не может дать значимый результат. Они обязательно сложные алгоритмы, в них много правил и исключений, потому что английское правописание осложняются историей в произношении слов и заимствованных <http://en.academic.ru/dic.nsf/enwiki/37846> из многих язык. Среди наиболее известных фонетические алгоритмы: саундэкс, который был разработан для кодирования фамилий для использования в переписях, Саундэкс Дэйча-Мокотоффа, который является уточнением саундэкс. Разработан, чтобы лучше соответствовать фамилии славянских и германских происхождения. Метафон и Двойной Метафон, который подходит для использования с большинством английских слов, а не только для названий объектов. Алгоритмы Метафон являются основой для многих популярных проверок правописания. Нью-Йорк государственной идентификации и информационной системы (NYSIIS), который отображает аналогичные фонемы той же буквой.
Выводы
Запись устной речи в полном соответствии с ее звучанием не может быть осуществлена обычным орфографическим письмом. При орфографическом письме отсутствует полное соответствие между звуками и буквами, в графике отсутствуют знаки, необходимые для записи всех звуков устной речи. Указанные затруднения устраняются особым видом письма, который называется фонетической транскрипцией. Мы привыкли видеть слова в графической форме, в виде последовательности букв. Это представление кажется нам наиболее естественным, так как мы постоянно с ним сталкиваемся. И поэтому неудивителен первый порыв разработчиков использовать это представление в своих программах обработки текстов. Такое решение вполне оправдано, например, в программах проверки орфографии. Но если мы хотим моделировать словоизменительные и словообразовательные процессы, то наиболее удобным будет фонематическое представление языковой информации, в виде последовательности фонем. Дело в том, что живой язык подчиняется фонетическим законам более, нежели законам орфографическим, и учёт этого факта значительно упрощает алгоритмы морфологического или словообразовательного анализа и синтеза, избавляя их от необходимости учёта орфографических особенностей.
|
||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-03-02; просмотров: 293; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.137.159.163 (0.01 с.) |
||||||||||||||||||||||||||||||||||||