Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Раздел 5. Информационные Технологии в распределенных системахСодержание книги
Поиск на нашем сайте
Технологии распределенных вычислений (РВ)
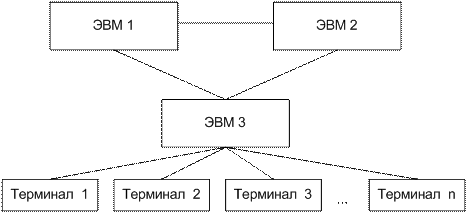
Современное производство требует высоких скоростей обработки информации, удобных форм ее хранения и передачи. Необходимо также иметь динамичные способы обращения к информации, способы поиска данных в заданные временные интервалы, чтобы реализовывать сложную математическую и логическую обработку данных. Управление крупными предприятиями, управление экономикой на уровне страны требуют участия в этом процессе достаточно крупных коллективов. Такие коллективы могут располагаться в различных районах города, в различных регионах страны и даже в различных странах. Для решения задач управления, обеспечивающих реализацию экономической стратегии, становятся важными и актуальными скорость и удобство обмена информацией, а также возможность тесного взаимодействия всех участвующих в процессе выработки управленческих решений. В эпоху централизованного использования ЭВМ с пакетной обработкой информации пользователи вычислительной техники предпочитали приобретать компьютеры, на которых можно было бы решать почти все классы их задач. Однако сложность решаемых задач обратно пропорциональна их количеству, и это приводило к неэффективному использованию вычислительной мощности ЭВМ при значительных материальных затратах. Нельзя не учитывать и тот факт, что доступ к ресурсам компьютеров был затруднен из-за существующей политики централизации вычислительных средств в одном месте. Принцип централизованной обработки данных (рис. 5.1) не отвечал высоким требованиям к надежности процесса обработки, затруднял развитие систем и не мог обеспечить необходимые временные параметры при диалоговой обработке данных в многопользовательском режиме. Кратковременный выход из строя центральной ЭВМ приводил к роковым последствиям для системы в целом.
Рис. 5.1 - Система централизованной обработки данных
Появление персональных компьютеров потребовало нового подхода к организации систем обработки данных, к созданию новых информационных технологий. Возникло логически обоснованное требование перехода от использования отдельных ЭВМ в системах централизованной обработки данных к распределенной обработке данных (рис. 5.2).
Рис. 5.2 - Система распределенной обработки данных
Распределенная обработка данных - обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределенную систему. В основе распределенных вычислений лежат две основные идеи: § много организационно и физически распределенных пользователей, одновременно работающих с общими данными - общей базой данных (пользователи с разными именами, которые могут располагаться на различных вычислительных установках, с различными полномочиями и задачами); § логически и физически распределенные данные, составляющие и образующие тем не менее, общую базу данных (отдельные таблицы, записи и даже поля могут располагаться на различных вычислительных установках или входить в различные локальные базы данных). Дня реализации распределенной обработки данных были созданы многомашинные ассоциации, структура которых разрабатывается по одному из следующих направлений: § многомашинные вычислительные комплексы (МВК); § компьютерные (вычислительные) сети. Многомашинный вычислительный комплекс - группа установленных рядом вычислительных машин, объединенных с помощью специальных средств сопряжения и выполняющих совместно единый информационно-вычислительный процесс. Под процессом понимается некоторая последовательность действий для решения задачи, определяемая программой. Многомашинные вычислительные комплексы могут быть: § локальными, при условии установки компьютеров в одном помещении, не требующих для взаимосвязи специального оборудования и каналов связи; § дистанционными, если некоторые компьютеры комплекса установлены на значительном расстоянии от центральной ЭВМ и для передачи данных используются телефонные каналы связи. Пример 1. Три ЭВМ объединены в комплекс для распределения заданий, поступающих на обработку. Одна из них выполняет диспетчерскую функцию и распределяет задания в зависимости от занятости одной из двух других обрабатывающих ЭВМ. Это локальный многомашинный комплекс. Пример 2. ЭВМ, осуществляющая сбор данных по некоторому региону, выполняет их предварительную обработку и передает для дальнейшего использования на центральную ЭВМ по телефонному каналу связи. Это дистанционный многомашинный комплекс. Компьютерная (вычислительная) сеть - вычислительная система, включающая в себя несколько компьютеров, терминалов и других аппаратных средств, соединенных между собой линиями связи, обеспечивающими передачу данных Терминал - устройство, предназначенное для взаимодействия пользователя с вычислительной системой или сетью ЭВМ. Состоит из устройства ввода (чаще всего это клавиатура) и одного или нескольких устройств вывода (дисплей, принтер и т.д.).
Распределенные базы данных
Системы распределенных вычислений появляются, прежде всего, по той причине, что в крупных автоматизированных информационных системах, построенных на основе корпоративных сетей, не всегда удается организовать централизованное размещение всех баз данных и СУБД на одном узле сети. Поэтому системы распределенных вычислений тесно связаны с системами управления распределенными базами данных. Распределенная база данных - это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети. Система управления распределенной базой данных - это программная система, которая обеспечивает управление распределенной базой данных и прозрачность ее распределенности для пользователей. Распределенная база данных может объединять базы данных, поддерживающие любые модели (иерархические, сетевые, реляционные и объектно-ориентированные базы данных) в рамках единой глобальной схемы. Подобная конфигурация должна обеспечивать для всех приложений прозрачный доступ к любым данным независимо от их местоположения и формата. Основные принципы создания и функционирования распределенных баз данных: § прозрачность расположения данных для пользователя (иначе говоря, для пользователя распределенная база данных должна представляться и выглядеть точно так же, как и нераспределенная); § изолированность пользователей друг от друга (пользователь должен "не чувствовать", "не видеть" работу других пользователей в тот момент, когда он изменяет, обновляет, удаляет данные); § синхронизация и согласованность (непротиворечивость) состояния данных в любой момент времени. Из основных вытекает ряд дополнительных принципов: § локальная автономия (ни одна вычислительная установка для своего успешного функционирования не должна зависеть от любой другой установки); § отсутствие центральной установки (следствие предыдущею пункта); § независимость от местоположения (пользователю все равно, где физически находятся данные, он работает так, как будто они находятся на его локальной установке); § непрерывность функционирования (отсутствие плановых отключений системы в целом, например для подключения новой установки или обновления версии СУБД); § независимость от фрагментации данных (как от горизонтальной фрагментации, когда различные группы записей одной таблицы размещены на различных установках или в различных локальных базах, так и от вертикальной фрагментации, когда различные поля-столбцы одной таблицы размещены на разных установках); § независимость от реплицирования (дублирования) данных (когда какая-либо таблица базы данных (или ее часть) физически может быть представлена несколькими копиями, расположенными на различных установках); § распределенная обработка запросов (оптимизация запросов должна носить распределенный характер - сначала глобальная оптимизация, а далее локальная оптимизация на каждой из задействованных установок); § распределенное управление транзакциями (в распределенной системе отдельная транзакция может требовать выполнения действий на разных установках, транзакция считается завершенной, если она успешно завершена на всех вовлеченных установках); § независимость от аппаратуры (желательно, чтобы система могла функционировать на установках, включающих компьютеры разных типов); § независимость от типа операционной системы (система должна функционировать вне зависимости от возможного различия ОС на различных вычислительных установках); § независимость от коммуникационной сети (возможность функционирования в разных коммуникационных средах); § независимость от СУБД (на разных установках могут функционировать СУБД различного типа, на практике ограничиваемые кругом СУБД, поддерживающих SQL). В обиходе СУБД, на основе которых создаются распределенные информационные системы, также характеризуют термином "распределенные СУБД", и, соответственно, используют термин "распределенные базы данных". Практическая реализация распределенных вычислений осуществляется через отступление от некоторых рассмотренных выше принципов создания и функционирования распределенных систем. В зависимости от того, какой принцип приносится в "жертву" (отсутствие центральной установки, непрерывность функционирования, согласованного состояния данных и др.) выделились несколько самостоятельных направлений в технологиях распределенных систем - технологии "Клиент-сервер", технологии реплицирования, технологии объектного связывания. Реальные распределенные информационные системы, как правило, построены на основе сочетания всех трех технологий, но в методическом плане их целесообразно рассмотреть отдельно.
5.3 Технологии и модели "Клиент-сервер"
Системы на основе технологий "Клиент-сервер" исторически выросли из первых централизованных многопользовательских автоматизированных информационных систем, интенсивно развивавшихся в 70-х годах (системы mainframe), и получили, вероятно, наиболее широкое распространение в сфере информационного обеспечения крупных предприятий и корпораций. В технологиях "Клиент-сервер" отступают от одного из главных принципов создания и функционирования распределенных систем - отсутствия центральной установки. Поэтому можно выделить две основные идеи, лежащие в основе клиент-серверных технологий: § общие для всех пользователей данные на одном или нескольких серверах; § много пользователей (клиентов), на различных вычислительных установках, совместно (параллельно и одновременно) обрабатывающих общие данные. Иначе говоря, системы, основанные на технологиях "Клиент-сервер", распределены только в отношении пользователей, поэтому часто их не относят к "настоящим" распределенным системам, а считают отдельным классом многопользовательских систем. Важное значение в технологиях "Клиент-сервер" имеют понятия сервера и клиента. Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем, производительностью процессора и т. д.). Клиентом называется также любая система, процесс, компьютер, пользователь, запрашивающие у сервера какой-либо ресурс, пользующиеся каким-либо ресурсом или обслуживаемые сервером иным способом. В своем развитии системы "Клиент-сервер" прошли несколько этапов, в ходе которых сформировались различные модели систем "Клиент-сервер". Их реализация и, следовательно, правильное понимание основаны на разделении структуры СУБД на три компонента: § компонент представления, реализующий функции ввода и отображения данных, называемый иногда еще просто как интерфейс пользователя; § прикладной компонент, включающий набор запросов, событий, правил, процедур и других вычислительных функций, реализующий предназначение автоматизированной информационной системы в конкретной предметной области; § компонент доступа к данным, реализующий функции хранения-извлечения, физического обновления и изменения данных. Исходя из особенностей реализации и распределения в системе этих трех компонентов различают четыре модели технологий "Клиент-сервер": § модель файлового сервера (File Server - FS); § модель удаленного доступа к данным (Remote Data Access - RDA); § модель сервера базы данных (DataBase Server - DBS); § модель сервера приложений (Application Server - AS).
Модель файлового сервера
Модель файлового сервера является наиболее простой и характеризует не столько способ образования информационной системы, сколько общий способ взаимодействия компьютеров в локальной сети. Один из компьютеров сети выделяется и определяется файловым сервером, т. е. общим хранилищем любых данных. Суть FS- модели иллюстрируется схемой, приведенной на рис. 5.3.
Рис 5.3 - Модель файлового сервера
В FS-модели все основные компоненты размещаются на клиентской установке. При обращении к данным ядро СУБД, в свою очередь, обращается с запросами на ввод-вывод данных за сервисом к файловой системе. С помощью функций операционной системы в оперативную память клиентской установки полностью или частично на время сеанса работы копируется файл базы данных. Таким образом, сервер в данном случае выполняет чисто пассивную функцию. Достоинством данной модели являются ее простота, отсутствие высоких требований к производительности сервера (главное, требуемый объем дискового пространства). Следует также отметить, что программные компоненты СУБД в данном случае не распределены, т.е. никакая часть СУБД на сервере не инсталлируется и не размещается. Недостатки данной модели - высокий сетевой трафик, достигающий пиковых значений особенно в момент массового вхождения в систему пользователей, например в начале рабочего дня. Однако более существенным недостатком, с точки зрения работы с общей базой данных, является отсутствие специальных механизмов безопасности файла (файлов) базы данных со стороны СУБД. Иначе говоря, разделение данных между пользователями (параллельная работа с одним файлом данных) осуществляется только средствами файловой системы ОС для одновременной работы нескольких прикладных программ с одним файлом. Несмотря на очевидные недостатки, модель файлового сервера является естественным средством расширения возможностей персональных (настольных) СУБД в направлении поддержки многопользовательского режима и, очевидно, в этом плане еще будет сохранять свое значение.
|
||||
|
|
Последнее изменение этой страницы: 2017-02-22; просмотров: 311; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.112.23 (0.009 с.) |

 I
I