Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Алгоритмы обмена маршрутной информациейСодержание книги
Поиск на нашем сайте
Протокол RIP (Routing Information Protocol — протокол обмена маршрутной информации) является внутренним протоколом маршрутизации дистанционно-векторного типа. Будучи простым в реализации, этот протокол чаще всего используется в небольших сетях. Для IP имеются две версии RIP – RIPvl и RIPv2. Протокол RIPvl не поддерживает масок. Протокол RIPv2 передает информацию о масках сетей. Построение таблиц маршрутизации по этому протоколу включает следующие этапы:. Этап 1 – создание минимальной таблицы Первоначально минимальная таблица маршрутизации каждого маршрутизатора включает в себя маршруты только для тех подсетей, что физически подсоединены к маршрутизатору(т.е. первых двух источников). Этап 2 —рассылка минимальной таблицы соседям. После инициализации каждый маршрутизатор начинает посылать своим соседям сообщения протокола RIP, в которых содержится его минимальная таблица. RIP-сообщения передаются в дейтаграммах протокола UDP и включают два параметра для каждой сети: ее IP-адрес и расстояние до нее от передающего сообщение маршрутизатора. По отношению к любому маршрутизатору соседями являются те маршрутизаторы, которым данный маршрутизатор может передать IP-пакет по какой-либо своей сети, не пользуясь услугами промежуточных маршрутизаторов. Этап 3 — получение RIP-сообщений от соседей и обработка полученной информации. RIP версии 1 использует для передачи объявлений широковещательные IP-пакеты. RIP версии 2 позволяет использовать для объявлений также пакеты группового вещания. Получив сообщения от соседей, каждый маршрутизатор корректирует свою таблицу. В таблице остаются записи соответствующие, оптимальной метрике(например, минимальному расстоянию до соседей). Этап 4 — рассылка обновленной таблицы соседям. Каждый маршрутизатор отсылает новое RIP-сообщение всем своим соседям. В этом сообщении он помещает данные обо всех известных ему сетях: как непосредственно подключенных, так и удаленных, о которых маршрутизатор узнал из RIP-сообщений. Этап 5 — получение RIP-сообщений от соседей и обработка полученной информации. Этап 5 повторяет этап 3 — маршрутизаторы принимают RIP-сообщения, обрабатывают содержащуюся в них информацию и на ее основании корректируют свои таблицы маршрутизации. В результате на каждом конкретном маршрутизаторе создается таблица маршрутов, где каждой сети данной RIP-системы соответствует минимальное расстояние до этой сети, выраженное посредством метрики (например, в хопах), а также адрес следующего маршрутизатора, на который необходимо направлять пакеты для достижения ими заданного адреса. Каждый маршрутизатор рассылает подобные объявления периодически с интервалом в 30 секунд. Маршрутизаторы, использующие протокол RIP, могут также сообщать информацию о маршрутизации при помощи триггерных обновлений. Триггерные обновления возникают, когда происходит изменение топологии сети. Триггерные обновления происходят немедленно, следовательно, информация о маршрутизации обновится раньше, чем произойдет следующее периодическое объявление. Каждый маршрутизатор, получающий триггерное обновление, изменяет собственную таблицу маршрутизации и распространяет изменение. Основное преимущество R1P заключается в простоте развертывания и конфигурирования. Недостатки: · наличие жесткого ограничения на размер сети. Протокол RIP может быть использован в сети, в которой два хоста разделены не более чем 15 маршрутизаторами. Подсети, расположенные на расстоянии 16 или более пересылок, считаются недостижимыми. Протокол хорошо работают только в небольших сетях · RIP-маршрутизаторы при выборе маршрута обычно используют самую простую метрику — количество промежуточных маршрутизаторов между сетями, то есть хопов что не позволяет создавать оптимальные маршруты. · в сетях, использующих RIP могут возникать петлевидные маршруты и как следствие периоды нестабильной работы, когда пакеты «зацикливаются» в маршрутных петлях и не доходят до адресатов. · периодическая рассылка обновленных таблиц маршрутизации занимает сетевой трафик. Протокол OSPF Протокол OSPF (Open Shortest Path First — выбор кратчайшего пути первым). Основан на алгоритме состояния связей, и обладает многими особенностями, ориентированными на применение в больших сетях. Работа протокола: 1. Маршрутизаторы обмениваются hello-пакетами через все интерфейсы, на которых активирован OSPF. Маршрутизаторы, разделяющие общий канал передачи данных, становятся соседями, когда они приходят к договоренности об определённых параметрах, указанных в их hello-пакетах. 2. На следующем этапе работы протокола маршрутизаторы будут пытаться перейти в состояние смежности со своими соседями. Пара маршрутизаторов, находящихся в состоянии смежности, синхронизирует между собой базу данных состояния каналов. 3. Каждый маршрутизатор посылает LSA(link-state advertisement, – описывает топологию связей портов маршрутизатора, и их состояние)объявления о состоянии канала маршрутизаторам, с которыми он находится в состоянии смежности. В отличие от таблиц маршрутизации, рассылаемых маршрутизаторам по протоколом RIP эти объявления имеют меньший размер. 4. Каждый маршрутизатор, получивший объявление от смежного маршрутизатора, записывает копию объявления в базу данных состояния каналов маршрутизатора и рассылает объявление всем другим смежным с ним маршрутизаторам. 5. Рассылая объявления, маршрутизаторы не изменяют их. В результате каждый маршрутизатор строит идентичную базу данных топологии сети. 6. Когда база данных построена, каждый маршрутизатор использует алгоритм «кратчайший путь первым» для вычисления графа без петель, который будет описывать кратчайший путь к каждому известному пункту назначения с собой в качестве корня. Этот граф – дерево кратчайших путей. 7. Каждый маршрутизатор строит таблицу маршрутизациииз своего дерева кратчайших путей по алгоритму SPF. 8. В ходе дальнейшей работы OSPF-маршрутизаторы периодически обмениваются сообщениями hello каждые 10 секунд, контролируя тем самым состояния связей. При возникновении каких-либо изменений в топологии сети маршрутизатор, обнаруживший эти изменения, также рассылает сообщение «обновление состояния связей», оповещая тем самым все остальные маршрутизаторы. К сожалению, вычислительная сложность протокола OSPF быстро растет с увеличением размера сети. Для преодоления этого недостатка в протоколе OSPF вводится понятие области сети. Маршрутизаторы, принадлежащие некоторой области, строят граф связей только для этой области, что упрощает задачу. В каждой области назначается выделенный маршрутизатор (designated router, DR) который управляет процессом рассылки LSA в сети. Каждый маршрутизатор сети устанавливает отношения смежности с DR. Информация об изменениях в сети отправляется не всем маршрутизаторм, а только маршрутизатору DR, который отвечает за то, чтобы эта информация была отправлена остальным маршрутизаторам сети. Между областями информация о связях не передается, а пограничные для областей маршрутизаторы обмениваются только информацией об адресах сетей, имеющихся в каждой из областей, и расстоянием от пограничного маршрутизатора до каждой сети Недостатки: сложность алгоритма. Достоинства: · позволяет избежать петель маршрутизации; · в процессе своего функционирования протокол OSPF генерирует значительно меньший сетевой трафик, чем протокол RIP. · протокол OSPF для рассылки служебных сообщений использует только групповое вещание (в отличие от протокола версии RIP 1); · протокол OSPF предусматривает возможность разбиения корпоративной сети на области. Области могут, с одной стороны, рассматриваться как домены маршрутизации, с другой стороны, облегчают процесс администрирования подсистемы маршрутизации; · протокол OSPF не имеет ограничений на количество переходов между маршрутизаторами, что позволяет его использовать в корпоративных сетях любого масштаба; · реконфигурация таблиц маршрутизации, вызванная изменениями в структуре сети, происходит за очень короткий период (значительно быстрее, нежели в случае использования протокола RIP)
5.6. Протокол ICMP Протокол межсетевых управляющих сообщений (Internet Control Message Protocol ,) является вспомогательным протоколом и служит для повышения надежности протокола IP. Как было отмечено ранее протокол IP является протоколом без подтверждения надежной доставки пакетов Функцию оповещения о надежной доставке берут на себя протоколы верхних уровней., например протокол TCP на транспортном уровне. Он обеспечивает надежную доставку, применяя такие известные приемы, как нумерация сообщений, подтверждение доставки, повторная посылка данных. Протокол ICMP служит только дополнением, к протоколу IP. Протокол не дает гарантий, что пакет достигает своего адресата.Он не предназначен для исправления возникших при передаче пакета проблем: если пакет потерян, ICMP не может послать его заново. Задача ICMP- сообщений другая – они является средством оповещения отправителя о проблемах, возникающих в комминикационном оборудовании.« Чтобы проблемы с передачей сообщений не вызывали появление новых сообщений и это не привело к лавинообразному росту количества сообщений, циркулирующих в сети, констатируется, что нельзя посылать сообщения о сообщениях. Формат ICMP – пакета приведен на рис. 76
Рис. 75. Формат пакета ICMP.
Определены следующие основные типы сообщений:
Если, например, протокол IP, работающий на каком-либо маршрутизаторе, обнаружил, что пакет для дальнейшей передачи по маршруту необходимо фрагментировать, но в пакете установлен признак DF (не фрагментировать), то он не может передать IP-пакет далее по сети. Прежде чем отбросить пакет, IP-протокол обращается к протоколу ICMP, который должен отправить диагностическое ICMP-сообщение «Проблемы с параметрами» конечному узлу-источнику. Для передачи по сети ICMP-сообщение инкапсулируется в поле данных IP-пакета. IP-адрес узла-источника определяется из заголовка пакета, вызвавшего проблему. Сообщение, прибывшее в узел-источник, может быть обработано там либо ядром операционной системы, либо протоколами транспортного и прикладного уровней, либо приложениями, либо просто проигнорированы. Важно, что обработка ICMP-сообщений не входит в обязанности протоколов IP и ICMP. Следует отметить, что основная команда системного администратора ping, работает на базе протокола ICMP.
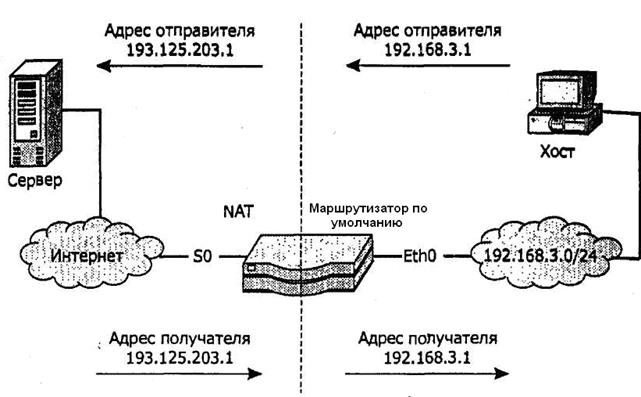
5.7.Трансляция сетевых адресов NAT NAT(Network Address Translation) выполняет три важных функции. 1. Позволяет сэкономить IP-адреса(только в случае использования NAT в режиме PAT), транслируя несколько внутренних IP-адресов в один внешний публичный IP-адрес (или в несколько, но меньшим количеством, чем внутренних). По такому принципу построено большинство сетей в мире: на небольшой район домашней сети местного провайдера или на офис выделяется 1 публичный (внешний) IP-адрес, за которым работают и получают доступ интерфейсы с приватными (внутренними) IP-адресами. 2. Позволяет предотвратить или ограничить обращение снаружи ко внутренним хостам, оставляя возможность обращения изнутри наружу. При инициации соединения изнутри сети создаётся трансляция. Ответные пакеты, поступающие снаружи, соответствуют созданной трансляции и поэтому пропускаются. Если для пакетов, поступающих снаружи, соответствующей трансляции не существует (а она может быть созданной при инициации соединения или статической), они не пропускаются. 3. Позволяет скрыть определённые внутренние сервисы внутренних хостов/серверов. Возможно, подменить внутренний порт официально зарегистрированной службы (например, 80-й порт (HTTP-сервер) на внешний 54055-й). Тем самым, снаружи, на внешнем IP-адресе после трансляции адресов на HTTP-сервер для можно попасть через:порт 54055, но из внутренней сети, находящемся за NAT, он будет работать на обычном 80-м порту. Повышение безопасности и скрытие «непубличных» ресурсов.
Рис. 76. Общая схема работы NAT
Общая схема работы: 1. Хост передает трафик (рис.76), адресованный находящемуся в Интернете серверу. Так как хост не знает маршрута к серверу, трафик посылается маршрутизатору по Умолчанию (он один в этом примере). На данном этапе адрес отправителя трафика - 192.168.3.1, и он является частным адресом в сети 192.168.3.0 /24. 2. Маршрутизатор, получая пакеты от хоста, обнаруживает, что хост принадлежит частной сети и, следовательно, необходима трансляция адресов. Для этого маршрутизатор просматривает настроенный пул открытых адресов и выбирает доступный адрес (193.125.203.1), который заменит собой адрес отправителя. 3..После замены адресов маршрутизатор передает пакеты в Интернет. Эти кеты маршрутизируются до получения пакета сервером. 4. Сервер после обработки пакетов отвечает по адресу 193.125.203.1, не заду ваясь о том, что действительный адрес хоста, работающего с ним, совершенно другой. Ответы сервера маршрутизируются в Интернете и в финале поступают на граничный маршрутизатор, который хранит в своей памяти информацию о выполненном преобразовании. 5..Граничный маршрутизатор после получения пакетов с адресом получателя 193.125.203.1 вновь выполняет трансляцию адресов, но теперь уже меняет адрес получателя на 192.168.3.1, и передает пакеты далее во внутреннюю сеть. Различают: · Статический NAT – Отображение незарегистрированного IP-адреса на зарегистрированный IP-адрес на основании один к одному. Особенно · Динамический NAT – Отображает незарегистрированный IP-адрес на зарегистрированный адрес от группы зарегистрированных IP-адресов. Динамический NAT также устанавливает непосредственное отображение между незарегистрированным и зарегистрированным адресом, но отображение может меняться в зависимости от зарегистрированного адреса, доступного в пуле адресов, во время коммуникации. · Перегруженный NAT (NAPT, NAT Overload, PAT, маскарадинг) — форма динамического NAT, который отображает несколько незарегистрированных адресов в единственный зарегистрированный IP-адрес, используя различные порты. Известен также как PAT (Port Address Translation). При перегрузке каждый компьютер в частной сети транслируется в тот же самый адрес, но с различным номером порта. Сетевой шлюз Компьютеры одной подсети связываются с компьютерами другой через сетевой узел, который называется шлюзом. Таким образом, у двух, связанных между собой подсетей, два шлюза, по одному у каждой. Иными словами шлюз –это крайняя точка подсети. Так как каждый шлюз имеет свой IP-адрес, то можно сказать, что каждый порт маршрутизатора является шлюзом для своей подсети. Шлюзы могут связывать сети как с одинаковыми так и с различными протоколами 5.8. Протокол IPv6 В начале 90-х годов стек протоколов TCP/IP столкнулся с серьезными проблемами. Именно в это время началось активное промышленное использование Интернета. Это привело к резкому росту числа сетей и узлов сетях, что стало приводить к дефициту IP-адресов и перегрузке маршругизаторов. которые должны обрабатывать таблицы маршрутизации большого объема. Исходя из этого, было решено разработать новую версию протокола IP.
|
||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-10; просмотров: 353; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.233.198 (0.013 с.) |