
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Кодирование с целью повышения верности передачи ⇐ ПредыдущаяСтр 4 из 4
Перейдем к рассмотрению кодов, которые используются в системах передачи данных для борьбы с помехами. Такие коды называются помехоустойчивыми или корректирующими. Рассмотрим общие принципы помехоустойчивого кодирования, на которых базируются все алгоритмы такого кодирования. Пусть для передачи сообщений используется равномерный двоичный код с длиной кодового слова (кодовых комбинаций) k бит. Тогда общее число кодовых слов равно N0=2 k. Предположим, что для передачи сообщений используются все возможные кодовые слова N = N 0. Здесь N – число кодовых слов, используемых для передачи сообщений. Такой код называется простым или примитивным. Если при приеме произошла ошибка в одном или нескольких символах, приемник заменит переданное кодовое слово другим. И в пункте приема нет оснований сомневаться в правильности решения, так как передатчик имеет право использовать любое слово кода. Таким образом, при использовании простого кода невозможно обнаружить ошибку по принимаемым кодовым словам. Увеличим длину кодовых слов до значения n. Тогда общее число кодовых слов N0=2 n будет больше числа слов, используемых для передачи сообщений N =2 k. N 0 > N Выбранные для передачи кодовые слова называются разрешенными. Остальные кодовые слова, которые не используются и в точке приема появляться не должны, называются запрещенными. В этом случае ошибки могут привести к появлению в приемнике либо разрешенного кодового слова (ошибка не обнаружена), либо запрещенного кодового слова (обнаружено наличие ошибок). Рассмотрим несколько примеров. 1. Для передачи сообщений используется простой код.
Наименьшее расстояние Хэмминга для данного кода называется кодовым расстоянием dmin. Для данного кода расстояние Хэмминга d=1 или 2, а dmin=1. Любая одиночная или двойная ошибка приводит к замене одного разрешенного кодового слова другим, и факт ошибки в приемнике обнаружить невозможно. 2. Для передачи того же набора сообщений используется код с длиной кодового слова n=3:
Действие ошибок большего веса (большей кратности) на данный код выражается в следующем: · Код не обнаруживает двойные ошибки, любая двойная ошибка переводит одно разрешенное кодовое слово в другое разрешенное слово. · Код обнаруживает тройную ошибку e=(111), так как она всегда приводит к появлению запрещенного слова. Итак, для обнаружения ошибок в код должна быть внесена избыточность, то есть длина кодового слова должна быть больше минимально необходимой. В общем случае, способность кода обнаруживать ошибки определяется следующим образом: · Если кодовые слова отличаются друг от друга не менее чем на · Ошибки веса равного или больше dmin обнаруживаются частично, то есть одни ошибки обнаруживаются, а другие – нет.
Рассмотрим код, который позволяет не только обнаружить, но и исправить ошибки. 3. Построим код, который может исправить одиночную ошибку t =1. Чтобы код мог исправлять одиночные ошибки, то есть определять, какое кодовое слово было передано в действительности, разрешенные слова должны различаться, по крайней мере, в трех символах
В этом случае любая одиночная ошибка переведет переданное кодовое слово в одну из запрещенных комбинаций и, следовательно, будет обнаружена. Полученная запрещенная комбинация будет отличаться от переданного кодового слова только одним символом, а от остальных разрешенных слов не менее чем в двух символах. Другими словами, принятая комбинация ближе к переданному слову и менее похожа на остальные разрешенные слова. Это позволяет нам выбрать среди разрешенных слов действительно переданное, а значит исправить ошибку. Пусть передавалось кодовое слово 00000. Было принята комбинация 01000. Она является запрещенной. Обнаружено наличие ошибок. Чтобы определить, какое из слов было передано, приемник сравнивает принятую комбинацию со всеми разрешенными. Из четырех разрешенных слов ближе всего к принятой комбинации 00000. Ошибка исправлена.
В общем случае, способность кода исправлять ошибки определяется следующим образом: · Если код имеет кодовое расстояние · Ошибки большего веса могут исправляться частично. Формулы, выражающие связь между кодовым расстоянием и весом ошибок, которые гарантированно обнаруживаются или исправляются, обычно записываются в виде
|
||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-05-27; просмотров: 29; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.149.213.209 (0.006 с.) |
 символов, то все ошибки веса
символов, то все ошибки веса  будут обнаружены.
будут обнаружены.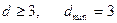 .
. , и используется декодирование с исправлением ошибок по ближайшему разрешенному слову, то все ошибки веса t < dmin /2 исправляются.
, и используется декодирование с исправлением ошибок по ближайшему разрешенному слову, то все ошибки веса t < dmin /2 исправляются.



