
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Три уровня анализа информации. Информация и данныеСтр 1 из 15Следующая ⇒
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ
Электронное учебное пособие по дисциплине «Интеллектуальный анализ данных» направлено на формирование универсальных компетенций в соответствии с федеральным государственным образовательным стандартом (ФГОС ВО 3++) по уровню магистратуры:
ОК-6 Способность самостоятельно приобретать с помощью информационных технологий и использовать в практической деятельности новые знания и умения, в том числе в новых областях знаний, непосредственно не связанных со сферой деятельности ОПК-1 Способность воспринимать математические, естественнонаучные, социально-экономические и профессиональные знания, умением самостоятельно приобретать, развивать и применять их для решения нестандартных задач, в том числе в новой или незнакомой среде и в междисциплинарном контексте; ПК-9 Умение проводить разработку и исследование методик анализа, синтеза, оптимизации и прогнозирования качества процессов функционирования информационных систем и технологий; Электронное учебное пособие предназначено для обучающихся по направлению подготовки магистратуры 09.04.02 «Информационные системы и технологии», может быть использовано при изучении других дисциплин, направленных на формирование универсальных компетенций. В электронном учебном пособии содержится систематическое изложение основ современных методов анализа данных. Рассмотрены вопросы исследования и обнаружения машиной (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, Цель электронного учебного пособия – сформировать у обучающихся системные знания в области теории и практики анализа многомерных данных, развить коммуникативные компетенции, которые позволят и в будущем осуществлять профессиональную деятельность. Содержание данного электронного учебного пособия соответствует рабочей программе дисциплины и основано на материалах отечественных и зарубежных исследований в области анализа многомерных данных, включая современные публикации. Каждый раздел электронного учебного пособия включает контрольные вопросы и тестовые задания.
АННОТАЦИЯ ДИСЦИПЛИНЫ 1. Место дисциплины в структуре образовательной программы Дисциплина «Интеллектуальный анализ данных» относится к вариативной части программы (дисциплины по выбору) и изучается в 3-ем семестре 2-го курса. Изучение дисциплины основано на принципах дальнейшего развития математических дисциплин базовой части программы, в том числе дисциплин «Специальные главы математики», «Методы исследования и моделирования информационных процессов и технологий». В качестве «входных» знаний, умений и готовностей требуется владение основными понятиями теории вероятностей, математической статистики, конечномерного линейного анализа, прежде всего операциями с матрицами и квадратичными формами, освоенными при получении высшего образования по программам бакалавриата (специалитета). Освоение данной дисциплины как предшествующей необходимо для последующего овладения дисциплиной «Распределенные системы, компьютерные сети и параллельные вычисления» и для выполнения диссертационных исследований.
2. Планируемые результаты обучения по дисциплине В результате освоения дисциплины обучающийся должен: Знать:
Уметь:
Владеть:
3. Объем дисциплины по видам учебных занятий Объем дисциплины составляет 4 зачетных единицы, всего 144 часа, из которых 48 часов составляет контактная работа обучающегося с преподавателем (12 часов занятий лекционного типа, 36 часов практических занятий), 60 часов составляет самостоятельная работа обучающегося). В конце 3-го семестра предусмотрен экзамен (36 часов)
ГЛОССАРИЙ Алгоритм (algorithm). Формальная процедура, гарантирующая получение оптимального или корректного решения. Анализ данных (data analysis) – система подходов и методов, ориентированная на выявление механизма порождения представленных данных в рамках имеющейся априорной модели этого механизма. База данных (data base). Совокупность данных, организованных по определенным правилам, устанавливающим общие принципы описания, хранения и манипулирования данными. База знаний (knowledge base). Совокупность знаний о некоторой предметной области, на основе которой можно проводить рассуждения. Обычно представляет собой набор фактов и правил, формализующих опыт специалистов в конкретной предметной области и позволяющих давать ответы, которые не содержатся в БЗ в явном виде. Банк данных (data bank). Информационная система централизованного хранения и коллективного использования данных. Содержит совокупность баз данных, СУБД и комплекс прикладных программ. Данные (datum, pl. data). 1. Зарегистрированные факты, описания явлений реального мира или идей, которые представляются достаточно ценными для того, чтобы их сформулировать и точно зафиксировать (ГОСТ 15971-90. Системы обработки данных. Термины и определения. - 1992). 2. факты, понятия или команды, представленные в формализованном виде, позволяющем осуществить их передачу, интерпретацию или обработку (Обработка данных. Словарь. Основные термины. – 1992).
Информатика — наука, изучающая свойства, структуру и функции информационных систем, основы их проектирования, создания, использования и оценки, а также информационные процессы, в них происходящие. Информационные технологии – система процедур преобразования информации с целью ее формирования, организации, обработки, распространения и использования. Интеллектуальный анализ данных (ИАД) – исследование данных, использующее методы искусственного интеллекта и ориентированное на придание системе свойств искусственного интеллекта. Информация (information). 1. Совокупность знаний о фактических данных и зависимостях между ними. 2. Сведения, являющиеся объектом некоторых операций: передачи, распределения, преобразования, хранения или непосредственного использования. 3. Содержание, присваиваемое данным посредством соглашений, распространяющихся на эти данные. Искусственный интеллект (artificial intelligence). Общее понятие, описывающее способность вычислительной машины моделировать процесс мышления за счет выполнения функций, которые обычно связывают с человеческим интеллектом: построение и использование экспертных систем, логический вывод, понимание естественных языков, зрительное и слуховое восприятие. Слот (slot). Атрибут, связанный с узлом (объектом, понятием, событием) в системе, основанной на фреймах. Фрейм (frame). Метод представления знаний, который связывает свойства с узлами, представляющими понятия и объекты. Свойства описываются атрибутами (слотами) и их значениями. Эвристика (heuristic). Эмпирическое правило, упрощающее или ограничивающее поиск решения в предметной области, которая является сложной или недоступной ясному пониманию. Экспертная система (expert system). Система искусственного интеллекта, включающая базу знаний с набором правил и машину вывода (inference engine), позволяющую на основании правил и предоставляемых пользователем фактов распознать ситуацию, сформулировать решение или дать рекомендацию. Data Mining – исследование и обнаружение машиной (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интерпретации человеком. Хранилище данных (ХД, Data Warehouse) – предметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию набор данных, организованный для целей поддержки принятия решений. ХД может быть как физическим, так и виртуальным. Обычно данные для ХД копируются критически, очищаются и обогащаются новыми атрибутами. Витрина данных (ВД, Data Mart) – упрощенный вариант ХД, содержащий только тематически объединенные данные. ВД часто формируют как надстройки над более общим ХД. ИНФОРМАЦИЯ, ДАННЫЕ, ЗНАНИЯ
Кибернетика способствовала тому, что классическое представление о мире, состоящем из материи и энергии, уступило место представлению о мире, состоящем из трех составляющих: материи, энергии и информации, ибо без информации немыслимы организованные системы. Информация – это сведения, воспринимаемые человеком или специальными устройствами как отражение фактов материального или духовного мира в процессе коммуникации (ГОСТ 7.0 – 99). Информация есть отражение реального мира: это сведения, которые один реальный объект содержит о другом реальном объекте. Сама по себе информация может быть отнесена к категории абстрактных понятий типа математических, но ряд особенностей приближает ее к материальным объектам. Так, информацию можно получить, записать, удалить, передать; информация не может возникнуть из ничего. Однако при распространении информации проявляется такое ее свойство, которое не присуще материальным объектам: при передаче информации из одной системы в другую количество информации в передающей системе не уменьшится, хотя в принимающей системе оно обычно увеличивается. Если бы информация не обладала этим свойством, то, например, преподаватель, читая лекцию студентам, терял бы информацию и становился неучем. Бернард Шоу сказал: «Если мы с вами обменяемся яблоками, у каждого будет по одному яблоку; если обменяемся идеями – у каждого будет по две идеи». Первичная информация – это факты, текст, графики, картинки, звуки, аналоговые или цифровые видео-сегменты. Она может быть получена в результате наблюдений, измерений, экспериментов, арифметических и логических операций. Целью анализа информации является получение знаний, т.е. фактов и правил, формализующих опыт специалистов в конкретной предметной области и позволяющих давать ответы (решения), которые не содержатся в исходной информации в явном виде. За 2002 год, согласно оценке, сделанной в калифорнийском университете Berkeley, объем информации в мире увеличился на 5*1018 байт и удваивается каждые 2 года. Будем считать в укрупненных величинах: Мегабайты: 1 Мбт = 106 бт; Гигабайты: 1 Гбт = 109 бт; Терабайты: 1 Тбт = 1012 бт; Петабайты: 1 Пбт = 1015 бт; Эксобайты: 1 Эбт = 1018 бт; Зеттабайты: 1 Збт = 1021 бт. Самые большие базы данных в 2003 году:
Задача: оценить по этим данным объем всей информации, находящейся сейчас в распоряжении человечества. Решение. Предположим, что накопление информации происходит в геометрической прогрессии со знаменателем q = exp (α): У нас k = 2001, так что спустя 9 лет, в 2010 году, объем этой информации должен был составить 12.1* exp (9α)=274.3 Этб, а «добавка» за один 2010 год должна была составить 274.3*(1- exp (-α)) Если предположить, что один байт соответствует песчинке, количество песчинок в зеттабайте соответствует по объему числу песчинок в плотинах 500 самых крупных в мире гидроэлектростанций. Одна электронная книга объемом в 1000 страниц – это примерно 3 мегабайта, так что библиотека, содержащая все эти 2.7 Зтб информации, должна содержать примерно один квадриллион томов. В то же время, известно, что сейчас в мире имеется примерно 130 миллионов книг. Оценить их информационную емкость чрезвычайно трудно. Предположительно имеется около 10 миллионов томов, действительно содержащих полезные сведения. При записи в электронной форме они займут 30 Птб, т.е. в миллион раз меньше всей накопленной информации. Это иллюстрирует разницу между первичной информацией и результатом ее перевода в концентрированную форму – знаниями. Интеллектуальный анализ данных (ИАД) Анализ данных – это система подходов и методов, ориентированная на выявление механизма порождения представленных данных в рамках имеющейся априорной модели этого механизма. Современный анализ данных – новая парадигма процесса исследования данных, основанная напринципах, предложенных Джоном Тьюки:
Искусственный интеллект (artificial intelligence)– это общее понятие, описывающее «способность вычислительной машины моделировать процесс мышления за счет выполнения функций, которые обычно связывают с человеческим интеллектом»: построение и использование экспертных систем, логический вывод, понимание естественных языков, зрительное и слуховое восприятие (ГОСТ 15971 – 90. Системы обработки данных. Термины и определения). Экспертная система (expert system) – это система искусственного интеллекта, включающая базу знаний с набором правил и машину вывода (inference engine), позволяющую на основании правил и предоставляемых пользователем фактов распознать ситуацию, сформулировать решение или дать рекомендацию. Экспертная система – это компьютерная система, которая эмулирует способности эксперта к принятию решения. Интеллектуальный анализ данных (ИАД) – исследование данных, использующее методы искусственного интеллекта и ориентированное на придание системе свойств искусственного интеллекта. Вычислительная техника создавалась прежде всего для обработки данных. Рутинную часть анализа данных стараются переложить на системы поддержки принятия решений (СППР, DSS) – системы, обладающие средствами ввода, хранения и анализа данных из конкретной предметной области с целью поиска решения. Такие системы не генерируют правильные решения, а предоставляют специалисту – аналитику данные в форме, удобной для изучения и анализа. Интеллектуальные СППР содержат функции, основанные на методах искусственного интеллекта. Data Mining Машинная форма хранения данных содержит полезную информацию в скрытом виде, для ее извлечения и представления в удобном виде приходится использовать специальные методы. Технология Data Mining изучает именно процессы нахождения новых знаний в базах данных. В ее основе лежат
Data Mining переводится как «добыча» или «раскопка данных». Нередко рядом с Data Mining встречаются слова «обнаружение знаний в базах данных» (knowledge discovery in databases). Наиболее известная реализация технологий Data Mining – это поисковые системы в Интернете. В сфере бизнеса известны сообщения об экономическом эффекте от внедрения таких технологий, в 10-70 раз превысившем первоначальные затраты. Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование. Ассоциация – это выделение различных типов связей между событиями: корреляционные связи, if-then правила и т.п. Последовательность – это ассоциация между событиями, сдвинутыми во времени. С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил. Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных. Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем. Примеры
Задачи хранения, оперативной модификации, информационно-поискового анализа в условиях одновременного обращения многих пользователей решают системы OLTP (On - Line Transactions Proceeding). Однако практика использования таких систем показала, что они плохо приспособлены к решению задач собственно анализа данных. Выход нашелся в создании специализированных подсистем – хранилищ данных (У. Инмон, 1992). Хранилище данных(ХД, Data Warehouse) – предметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию набор данных, организованный для целей поддержки принятия решений. ХД может быть как физическим, так и виртуальным. Обычно данные для ХД копируются критически, очищаются и обогащаются новыми атрибутами. Витрина данных (ВД, Data Mart) – упрощенный вариант ХД, содержащий только тематически объединенные данные. ВД часто формируют как надстройки над более общим ХД. В 1993 г. Е. Кодд – основоположник реляционной модели БД – предложил представление данных в виде многомерной модели, гиперкуба, ребрами которого являются измерения. Эту технологию назвали OLAP (On - Line analytical processing), ее полное определение задается 18 правилами Кодда. Data Mining – исследование и обнаружение машиной (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интерпретации человеком. Решаемые задачи разделяются на описательные (Descriptive) и предсказательные (Predictive). Для описательных задач ключевой момент – прозрачность результатов для восприятия человеком. В предсказательных задачах строится модель, которая затем тестируется на новом массиве данных. К описательным относятся регрессионные модели, модели кластеров, модели исключений, ассоциативные модели и итоговые модели (выявление ограничений). К предсказательным относятся модели классификации и модели последовательностей. По постановке задачи разделяют на обучение с учителем (Supervised Learning) и обучение без учителя (Unsupervised Learning). Для управления полученными в результате анализа знаниями используются технологии Knowledge Management. Подсистемы Data Mining Визуальный анализ данных (Vizual Mining) – специальные технологии представления данных в форме, удобной для восприятия человеком. Анализ текстовой информации (Text Mining) – технологии обнаружения новых, потенциально полезных и понятных шаблонов в неструктурированных текстовых данных. Отдельно стоят технологии извлечения знаний из Web (Web Mining). Data Mining в реальном времени (Real - Time Data Mining) – технологии накапливаемого обучения с использованием обратной связи от прогноза. МЕТОДЫ МАТРИЧНОГО АНАЛИЗА Задание на лабораторную работу Решить приведенные ниже задачи. Привести вычисления и иллюстрации в ИМС MatLab. Контрольные вопросы 2.1. Решить уравнение cos(x -1)= x и исследовать зоны притяжения двух его корней. 2.2. Решить систему уравнений Найти и исследовать экстремумы следующих функций двух переменных: 2.3. z = xy 2(1- x - y); 2.4. z = x 3+ y 3-15 xy; 2.5. Найти и исследовать экстремумы следующих функций двух переменных: 2.3. z = xy 2(1- x - y); 2.4. z = x 3+ y 3-15 xy; 2.5. 2.9. Пусть a =[ a 1,…, a n] T – постоянный вектор, X – переменный вектор той же размерности. Найти производную скалярных функций aTX и XTa по X. 2.10. Пусть A – постоянная матрица размерности < n × n >, X – вектор-столбец длины n. Найти производную по X квадратичной формы XTAX. Проверить результат прямым вычислением при n =2. 3. МОДЕЛИРОВАНИЕ МНОГОМЕРНЫХ ДАННЫХ Множественная регрессия Пусть теперь имеется случайный вектор Z = [ x 1,…, xk, y 1,…, yr ] T, который подчиняется (k + r) – мерному нормальному закону Nk+r (a, Σ) с известными вектором средних a и ковариационной матрицей Σ. Рассмотрим случай, когда первые k компонент x 1,…, xk вектора Z наблюдаются в эксперименте, а оставшиеся компоненты y 1,…, yr являются ненаблюдаемыми. Требуется получить оценки ненаблюдаемых компонент. Пример 4.3. В лабораторных условиях текущее состояние смазочных материалов контролируется по 16 параметрам и имеется достаточная база данных для оценки их средних и их ковариационной матрицы. В полевых условиях экспресс-анализ позволяет проконтролировать только 7 параметров. На основе знания значений этих 7 параметров требуется оценить оставшиеся 9 показателей. Пример 4.4. Для технологической установки имеется база данных, содержащая значения выходных параметров (продукта) при различных комбинациях входных и управляющих параметров. Предположим, что эта база достаточна для оценивания средних и ковариационной матрицы всего вектора контролируемых показателей. А) Заданы текущие значения входных (сырья) и управляющих параметров. Требуется получить прогноз вектора выходных параметров установки (продукта). Б) Заданы требуемые значения выходных параметров и используемые в настоящий момент значения управляющих параметров. Требуется сформировать требования к входным параметрам (сырью). В) Заданы текущие значения входных параметров (свойства сырья). Требуется найти комбинацию управляющих параметров, оптимизирующих целевую функцию, которая отражает свойства выходных показателей (например, в единицах стоимости). Согласно условиям приведенных задач, средние и ковариационная матрица вектора Z имеют блочную структуру:
Будем сразу рассматривать центрированные величины:
Требуется определить матрицу C размерности
В проведенных преобразованиях использован тот факт, что если оба матричных произведения AB и BA имеют смысл, то tr (AB) = tr (BA). Функция матричного аргумента G (C) является выпуклой и имеет единственный экстремум – минимум. Вычислим ее производную по матрице С и приравняем ее нулю, используя очевидное соотношение
Возвращаясь к исходным величинам X, Y, получаем уравнение множественной линейной регрессии Y на X:
(сравни с формулой (4.5)). Ковариационную матрицу ошибок прогноза в компактной форме представить не удается, но можно вычислить ее след (упрощение достигается за счет того, что tr (AB) = tr (BA)):
(сравни с формулой (4.6)). На формуле (4.9) основаны различные определения множественного коэффициента корреляции. Аналогичная техника позволяет решить, например, такую задачу. Имеется одна ненаблюдаемая компонента. Требуется построить линейную комбинацию наблюдаемых компонент, в максимальной степени коррелированную с данной ненаблюдаемой. Пример 4.5. Требуется спрогнозировать биржевой курс акций данной компании по известным курсам ряда других компаний с некоторым отставанием во времени. Задание на лабораторную работу 1. Решить задачи из примеров 4.1- 4.2 2. Решить эти же задачи для данных, сформированных ранее в работе 1. 3. Привести вычисления и иллюстрации в ИМС MatLab. Контрольные вопросы
Задание на лабораторную работу
· В виде 3-мерных облаков точек; · На плоскости 2 главных факторов; · На плоскости 2 главных дискриминантных факторов. Контрольные вопросы
Задание на лабораторную работу 1. Повторить расчеты, взяв в качестве X, Y две случайные реализации Х из программы, приведенной в работе 5. 2. В условиях задачи 6.1 найти минимальное расстояние между теоретическими средними, при котором выборки на уровне 0.9 перестают различаться. 3. Модифицировать программу из Документа 6.2 и проверить правильность аппроксимаций (6.5) и (6.10) для нескольких сочетаний k, m, n. Контрольные вопросы 1. Знать основные определения теории проверки гипотез, статистики основных критериев нормальной теории в одномерном и многомерном случаях. 2. Знать алгоритм получения законов распределения на основе техники Монте-Карло
КЛАСТЕРНЫЙ АНАЛИЗ Кластерный анализ (автоматическая классификация, распознавание образов без учителя, таксономия, кластер-анализ) – это совокупность методов, подходов и процедур, предназначенных для разбиения исследуемой совокупности на подмножества относительно сходных между собой объектов (кластеры, таксоны, классы). В основе лежит неформальное предположение о том, что объекты, относимые к одному кластеру, должны иметь большее сходство между собой, чем с объектами других кластеров.
Clear; clc; X=[3 1.7; 1 1; 2 3; 2 2.5; 1.2 1; 1.1 1.5; 3 1 ]; Y=pdist(X,'euclid'); W = squareform (Y); Disp(W); |
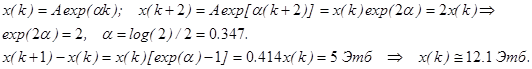
 80 Этб. Реально в 2010 году объем информации, сгенерированной во всем мире, впервые превысил 1 зеттабайт, т.е оказался в 12 раз больше; в 2012 году этот показатель достиг 2.7 зеттабайтов. Это значит, что сам коэффициент α в рассмотренной модели растет с ростом k.
80 Этб. Реально в 2010 году объем информации, сгенерированной во всем мире, впервые превысил 1 зеттабайт, т.е оказался в 12 раз больше; в 2012 году этот показатель достиг 2.7 зеттабайтов. Это значит, что сам коэффициент α в рассмотренной модели растет с ростом k.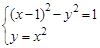 по формулам (2.3), а затем свести ее к одному уравнению 4-й степени и решить его по формуле (2.2).
по формулам (2.3), а затем свести ее к одному уравнению 4-й степени и решить его по формуле (2.2).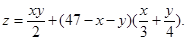 2.6.
2.6. 
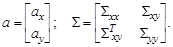
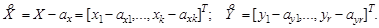
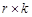 , доставляющую минимум функции потерь G (C), которая представляет собой сумму дисперсий погрешностей прогноза:
, доставляющую минимум функции потерь G (C), которая представляет собой сумму дисперсий погрешностей прогноза: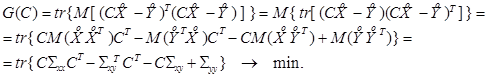 (4.7)
(4.7)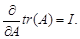 При дифференцировании нужно все время иметь в виду, что производная матричной функции по матрице С размерности
При дифференцировании нужно все время иметь в виду, что производная матричной функции по матрице С размерности 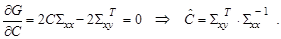
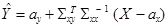 (4.8)
(4.8)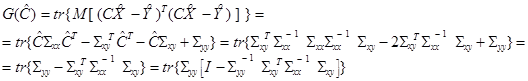 (4.9)
(4.9)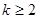 ) найти коэффициенты двух главных факторов и определить долю информации, объясняемую этими факторами.
) найти коэффициенты двух главных факторов и определить долю информации, объясняемую этими факторами.



