
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Обработка экспериментальных данных
Корреляционный анализ предназначен для выявления статистической зависимости между двумя переменными, каждая из которых представляет собой случайную величину. Корреляционный анализ позволяет выявить наличие или тесноту линейной (или близкой к линейной) зависимостимежду двумя величинами. Корреляционный анализ при использовании парной корреляции не позволяет: · выявить, какая из переменных является независимой (фактором), а какая – зависимой (параметром оптимизации); · отличить тесную связь по существенно нелинейной зависимости отслабой связи (или вообще отсутствии таковой) по линейной зависимости; · исследовать влияние нескольких независимых переменных на одну зависимую (в этом случае применяют множественную корреляцию). В этом методе взаимную зависимость проверяют по значению коэффициента корреляции:
где sx и sy – среднеквадратические отклонения x и y как случайных величин; sxy – ковариация между двумя величинами.
где Mx, My и Mxy – математические ожидания x, y и их произведения n – число точке (пар x и y). Таким образом,
Коэффициент корреляции стремится к 1 при наличии теснойпрямой линейной зависимости между величинами вида Y=ax+b (a>0); к –1 – при наличии тесной линейной зависимостиY=ax+b (a<0),к 0 – при отсутствии зависимости или её существенной нелинейности. На рисунке 4.1 представлены различные варианты графиков зависимостей и значений коэффициента корреляции. Рисунок 4.1 - Различные варианты зависимостей и коэффициента корреляции.
В множественной корреляции можно оценить тесноту связи между одной зависимой и несколькими независимыми переменными. Для оценки такой тесноты используют коэффициент множественной корреляции R, рассчитываемый по формуле:
где D y – дисперсия зависимой переменной y D ост – остаточная дисперсия по линейной модели (yp=a+bx1+с x2+…), равная
Квадрат коэффициента множественной корреляции называют коэффициентом детерминации. Для оценки влияния отдельных переменных используют коэффициент частной корреляции, характеризующий влияние на y только x i:
Регрессионный анализ – это статистический метод исследования влияния одной или нескольких независимых переменных на зависимую. Регрессионный анализ предполагает анализ предварительно заданной модели (уравнения регрессии), включая подбор коэффициентов, оценку адекватности модели и значимости коэффициентов регрессии. Регрессию можно классифицировать:
§ По числу факторов – на парную (только один фактор) и множественную § По характеру модели – на линейную и нелинейную. В общем случае задача регрессии имеет вид:
Задачей регрессионного анализа является определение коэффициентов регрессии ai при наличии k наборов значений y и xj. Для корректного решения задачи необходимо, чтобы k>m, причём число степеней свободы будет f=k-m. Наиболее распространённым методом является метод наименьших квадратов (МНК), в котором ставится следующая задача:
где ypl – расчётное значение y для набора данных № l.
Для линейных и близких к линейным (относительно коэффициентов регрессии a i) моделей существует только один экстремум вышеприведённого выражения, он же будет минимумом. Для его нахождения надо решить систему уравнений, получаемых дифференцированием этого выражения по каждому коэффициенту регрессии и приравниваемых к 0. В итоге получается m уравнений с m неизвестными, которые легко решить. В случае существенной нелинейности относительно коэффициентов регрессии необходима дополнительная проверка полученного решения на минимальность. Возможно также применение численных методов нахождения экстремума для существенно нелинейных моделей регрессии. Подбор наилучших значений коэффициентов регрессии не гарантирует наилучший выбор модели – он лишь позволяет максимально возможно «подогнать» модель под исходные данные.Задача проверки адекватности модели – это задача опровержения «нуль-гипотезы»: «Модель описывает изменение y от xi не лучше, чем случайная ошибка». Для проверки гипотезы используют F-статистику (критерий Фишера) с двумя выборками: y как случайная величина и разность y – yp. Дисперсии этих величин соответственно называют дисперсией воспроизводимости S2y и дисперсией адекватности (остаточной дисперсией) S2ост. Первую считают при числе степеней свободы k–1 (k – число измерений), вторую – при k–m. Соотношение этих дисперсий даёт критерий Фишера, равный таким образом:
Полученный критерий Фишера сравнивают с табличным или оценивают по нему вероятность неадекватности модели. Большее значение F свидетельствует о большейадекватности уравнения регрессии.
5. Теория планирования эксперимента
Методика планирования эксперимента позволяет получить максимальную информацию при минимуме опытов.Экспериментальный план представляет из себя таблицу, в которой перечисляются значения факторов (на определённых уровнях варьирования). При выполнении эксперимента по плану заполняют соответствующие значения параметра(ов) оптимизации. Основой теории планирования эксперимента является полный факторный эксперимент, обозначаемый mn, где n – число факторов, m– число уровней варьирования каждого фактора. Если рассматривать это обозначение как математическое выражение, то результатом этого выражения будет число опытов в плане. Для анализа линейных и близких к линейным зависимостей достаточно двух уровней варьирования факторов – эксперимент вида 2n.Уровни варьирования факторов нормируются до –1 … +1 (иногда обозначают «–» и «+»).По этой схеме однофакторный эксперимент будет представлять собой только два опыта: +1 и –1. Двухфакторный и трёхфакторный эксперименты получают путём комбинации факторов, они приведены в таблицах 5.1 и 5.2. Таблица 5.1 – План эксперимента 22
Таблица 5.2 – План эксперимента 23
Полный факторный эксперимент (ПФЭ) позволяет ответить на вопрос, влияет ли фактор на параметр оптимизации, а также (в предположении нулевой или ничтожно малой ошибки опытов) о наличии или отсутствии «эффектов взаимодействия». Под эффектами взаимодействия понимают нелинейные эффекты, проявляющиеся при одновременном изменении двух (или более) факторов. Например, факторы Х1 и Х2 каждый сам по себе прямо пропорционально влияют на параметр оптимизации Y, то есть, увеличение Х1 в 2 раза приведёт к двукратному росту Y, равно и двукратное увеличение Х2. А двукратное увеличение и Х1, и Х2 может привести либо к четырёхкратному росту Y (тогда говорят об отсутствии эффектов взаимодействия), либо к меньшему росту Y, например, в 3 раза (антагонистическое влияние факторов), либо к ещё большему росту Y, например, в 6 раз (синергетическое влияние факторов). Исследовать существенно нелинейные зависимости (в том числе экстремальные) полный факторный эксперимент 2n не позволяет. Полный факторный эксперимент вполне подходит для двух факторов; несложно его реализовать и для трёх факторов – но при этом для базового анализа потребуется 8 опытов, что иногда может быть затруднительно. Эксперименты с четырьмя и более факторами требуютещё большего количества опытов (от 16), что для базового анализа явно избыточно. Решением проблемы будет отказ от некоторых эффектов взаимодействия, что позволит получить дробный факторный эксперимент. В предположении отсутствия эффектов взаимодействия между Х1 и Х2 можно составить план эксперимента, в котором Х3= Х1Х2. Такой план называют полурепликой, обозначая 23–1. Он представлен в таблице 5.3.
Таблица 5.3 – Полуреплика 23–1
При большем количестве факторов возможно ещё большее «урезание» плана, могут быть четверть–реплики и ещё меньшие варианты. Предельным вариантом плана дробного факторного эксперимента является план Плакетта-Бермана, который предлагается для 7, 11, 15 и более факторов. Пример плана Плакетта-Бермана для 7 факторов (8 опытов) представлен в таблице 5.4 (для простоты уровни варьирования обозначены просто «+» и «–»).
Таблица 5.4 – План Плакетта–Бермана
В первой строке положительных уровней на 1 больше, чем отрицательных. Каждая последующая строка представляет собой циклический сдвиг предыдущей влево. Восьмая строка, построенная таким образом, была бы идентичной первой, но вместо этого в неё ставят все недостающие отрицательные уровни. Для n=11 первая строка выглядит следующим образом: ++–+++––+– для n=15: ++++–+–++––+––– для n=23: ––––+–+–+++–++–––+++++– Недостатком таких планов является отсутствие степеней свободы с точки зрения статистики. То есть, при нулевой погрешности эксперимента и при идеально линейном характере зависимости они позволяют получить вполне приемлемые результаты, однако на практике такое невозможно. При наличии (или предположении возможности) погрешности дать статистическую оценку полученным результатам не представляется возможным. Существует два подхода к решению этой проблемы: во-первых, каждый опыт можно делать в двух повторностях (но это удваивает количество опытов и зачастую сводит на нет урезание плана эксперимента), во-вторых, можно использовать меньшее количество опытов, чем предусмотрено планом. Таким образом, план Плакетта-Бермана для 7 факторов удобно использовать с 5 или 6 факторами. С его помощью можно установить значимость влияния каждого из факторов и выбрать наиболее значимые (или отбросить наименее значимые). Также с его помощью можно установить направление влияния каждого из факторов.Например, при разработке рецептур многокомпонентных продуктов или блюд в общественном питании на первом этапе может проводиться подбор ингредиентов. В плане Плакетта-Бермана при этом под знаком «минус» будет пониматься полное отсутствие ингредиента, а под знаком «плюс» - его присутствие на обычном для данного компонента уровне (или на несколько более низком).В этом случае целесообразно отбросить как явно не влияющие на качество ингредиенты, так и ингредиенты, безусловно, влияющие на него, но негативно.
Таким образом, дробные факторные эксперименты целесообразно использовать для первичного анализа возможных факторов и удаления неудачно выбранных факторов. Полный факторный эксперимент желательно использовать на узком диапазоне варьирования, он способен показать направление оптимизации. Но анализ данных вблизи экстремума следует проводить с помощью более сложных планов, в которые, помимо полного факторного эксперимента 22 (или 23), включены дополнительные точки. Такие планы получили название композиционных планов. В композиционные планы, как правило, всегда включают эксперимент в центре плана («нулевые» уровни варьирования всех факторов); иногда такой эксперимент делают в нескольких повторностях. Если такой план является симметричным относительно центра, его называют центральным композиционным планом (ЦКП). Если же сумма произведений элементов матрицы планирования равна нулю, то план называют ортогональным. В большинстве случаев требованию ортогональности предпочитают требование ротатабельности, то есть, все точки плана (кроме центральных) лежат на одной окружности (при n=2), сфере (n=3) или гиперсфере (n≥4). При этом отдельные точки будут выпадать за пределы первоначального интервала варьирования (–1≤Х≤+1), такие точки получили название «звёздных точек». В «звёздных точках» в центральном композиционном ротатабельном плане (ЦКРП) значение одного из факторов устанавливается на уровне Таблица 5.5 – Центральный композиционный ротатабельный план двухфакторного эксперимента
Таблица 5.6 – Центральный композиционный ротатабельный план трёхфакторного эксперимента
Обработка результатов ЦКП позволит получить нелинейную зависимость, на которой может быть экстремум.
Практическая работа № 4 Планирование двухфакторного эксперимента и обработка данных
Цель работы: научиться составлять центральный композиционный ротатабельный план, проводить эксперимент и обрабатывать данные методом линейной регрессии.
Задачи: 1. Получить задание в виде наименования технологического процесса, факторов и параметра оптимизации, а также имитационную модель (программу) для получения экспериментальных данных. 2. Выбрать уровни варьирования факторов и составить центральный композиционный ротатабельный план. 3. Провести рандомизацию составленного плана 4. Провести модельный эксперимент (последовательно ввести данные в программу) 5. С использованием средств Excel (LOCalc) провести регрессионный анализ по линейной и сведённой к линейной квадратичной моделям. 6. Сделать вывод о результатах
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-01-08; просмотров: 130; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.133.12.172 (0.028 с.) |
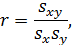
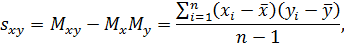
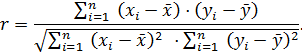
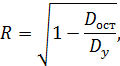
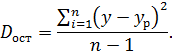
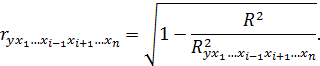
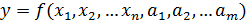 .
.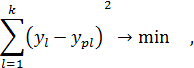
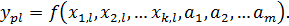
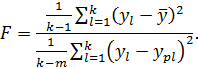
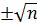 , а все остальные фиксируются на нулевом уровне. Таким образом, при n=2ЦКРП содержит не менее 9 опытов, из них 4 – ПФЭ, 4 – «звёздные» точки, не менее 1 – эксперимент в центре плана. Примеры ЦКРП для n=2 и n=3 приведены в таблицах 5.5 и 5.6 соответственно.
, а все остальные фиксируются на нулевом уровне. Таким образом, при n=2ЦКРП содержит не менее 9 опытов, из них 4 – ПФЭ, 4 – «звёздные» точки, не менее 1 – эксперимент в центре плана. Примеры ЦКРП для n=2 и n=3 приведены в таблицах 5.5 и 5.6 соответственно.


