Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Комп’ютеризовані системи цифрової обробки сигналівСтр 1 из 22Следующая ⇒ Комп’ютеризовані системи цифрової обробки сигналів
Лекція для базового напрямку:8.080401- Інформаційні управляючі системи та технології
Львів 2008 р. Комп’ютеризовані системи цифрової обробки сигналів: конспект лекцій для студентів базового для базового напрямку: 8.080401- Інформаційні управляючі системи та технології. Розглянуто галузі застосування, методи, алгоритми цифрової обробки сигналів і виділено операційний базис комп’ютерних систем цифрової обробки сигналів. Проаналізовано сучасну елементну базу, структурну організацію пам’яті, інтерфейсів та значну увагу приділено базовим структурам комп’ютерних систем цифрової обробки сигналів. Розкрито принципи побудови та методи оцінки основних параметрів комп’ютерних систем цифрової обробки сигналів.
Укладач: доц. каф. АСУ, д.т.н., доц. Цмоць І.Г. Відповідальний за випуск: доц. каф. АСУ, к.т.н., доц. Шпак З.Я. Рецензенти: директор Державного НДІ інформаційної інфраструктури, член-кор. НАН України, д.т.н., проф. Грицик В.В.; проф. каф. АСУ, д.т.н., проф. Ткаченко Р.О.
ВСТУП
Розвиток комп’ютерних систем цифрової обробки сигналів (ЦОС) характеризується розширенням галузей їх застосування, у значній частині з яких вимагається обробка у реальному часі інтенсивних потоків даних за складними алгоритмами на апаратних засобах, що задовольняють жорстким умовам експлуатації та обмеженням у частині габаритів і споживаної потужності. Комп’ютерні системи ЦОС – це системи реального часу, які призначені для розв’язання задач приймання, обробки, зменшення надлишковості та передавання інформації в реальному часі. Методи, алгоритми і апаратно-програмні засоби ЦОС викликають підвищення зацікавленості учених і спеціалістів, працюючих в різних галузях науки і техніки, таких як зв'язок і системи управління, радіотехніка і електроніка, акустика і сейсмологія, телебачення радіомовлення, вимірювання техніка в приладобудування. Сучасний етап розвитку теорії ЦОС тісно зв’язаний з інтенсивним провадженням методів цифрових сигналів, які орієнтовані на застосування однокристальних мікропроцесорів ЦОС, архітектурно перепрограмованих надвеликих інтегральних схем (НВІС) на базі програмованих логічних інтегральних схем (ПЛІС)і багатопроцесорних систем, побудованих на їх основі. ПЛІС, завдяки великій ємності логічних вентилів на кристалі і високій робочій тактовій частоті, міцно займають свою нішу між спеціалізованими НВІС і універсальними мікропроцесорами ЦОС. Комп’ютерні системи ЦОС, які проектуються на базі ПЛІС мають високу продуктивністю як у замовних НВІС і забезпечують високу гнучкість за рахунок архітектурної адаптації перепрограмованих НВІС до структури алгоритмів розв’язання задачі, а також можливість розміщення на кристалі всієї системи, разом з нестандартною периферією. В тих випадках, коли комп’ютерна система орієнтована на розв’язання складних задач з значною кількістю переходів і логічних операцій над вхідними потоками з різною інтенсивністю надходження даних, найбільша ефективність використання обладнання досягається при спільному використанні ПЛІС і мікропроцесорів ЦОС. Сучасна концепція побудови комп’ютерних систем ЦОС базується на використанні потенційних можливостей сучасної елементної бази (мікропроцесорів ЦОС, спеціалізованих і перепрограмованих НВІС) і використанні методів розпаралелювання та конвеєризації при розв’язанні конкретних задач. У паралельно-конвеєрних комп’ютерних системах ЦОС висока продуктивність та ефективність використання обладнання досягається тільки в тих випадках, коли їх архітектура адаптується до інтенсивності надходження потоків даних і адекватно відображає структуру алгоритму розв’язання задачі. Паралелізм обробки даних у комп’ютерних системах ЦОС висуває свої вимоги до організації пам’яті, які в першу чергу пов’язані з необхідністю забезпечення паралельного доступу до множини даних і підтримкою швидкісного обміну з операційними пристроями, процесорними елементами та багатоканальними пристроями введення-виведення, тобто пам’ять повинна бути швидкодіючою та паралельною. У паралельній пам'яті висока швидкодія та ефективність використання обладнання досягається шляхом адаптації її архітектури до структур даних і алгоритмів розв’язання задачі. Зменшення енергоспоживання, габаритів, часу та вартості розробки комп’ютерних систем ЦОС досягається у випадку коли архітектура є регулярною, модульною та орієнтованою на НВІС-реалізацію. Для створення високоефективних комп’ютерних системи ЦОС доцільно використовувати інтегрований підхід, який охоплює архітектуру, сучасну елементну базу, методи та алгоритми ЦОС та враховує інтенсивності надходження даних і вимоги конкретних застосувань. Метою викладання дисципліни комп’ютеризовані системи цифрової обробки сигналів – вивчення методів і алгоритмів ЦОС, елементної бази, архітектури та методів проектування комп’ютерних систем ЦОС у реальному часі. Цифрова фільтрація
Цифрова фільтрація – процедура, що використовується для приглушення завад зі спектром, що не перетинається зі спектром сигналу. Фільтрація є загальним випадком лінійного перетворення [1]. Вона дозволяє виділити в чистому вигляді функцію, що лежить в основі спостережуваного явища. Цифрова система, яка використовується для фільтрації цифрових сигналів називається цифровим фільтром. Такі фільтри можуть реалізовуватися програмним або апаратним шляхом. Цифрові фільтри в порівнянні з аналоговими мають такі переваги: · висока точність, передатна функція не залежить від дрейфа характеристик елементів; · гнучкість налаштування та легкість зміни; · компактність – аналоговий фільтр на дуже низьку частоту вимагає конденсаторів великої ємності або індуктивності. Недоліки цифрових фільтрів у порівнянні з аналоговими такі: · складність роботи з високочастотними сигналами; · трудність забезпечення роботи у реальному часі.
Медіанна фільтрація
Медіанний фільтр — один із видів цифрових фільтрів, які широко використовуються при ЦОС і зображень для приглушення нерегулярних завад. Медіанна фільтрація є нелінійним способом обробки одномірних і двомірних послідовностей вибірок [9]. В порівнянні з лінійною медіанна фільтрація має важливі переваги: зберігає різкі перепади сигналу; добре згладжує імпульсний шум. Алгоритми медіанної фільтраціії базуються на повному або частковому сортуванні чисел-елементів зображень у “вікні” розміром N=2m+1 та виділенні у просортованій послідовності центрального елементу, тобто елементу з номером m+1.
Кореляція
Коли необхідно визначити подібність між сигналами в різні моменти часу або виділити сигнал на фоні шуму, то здійснюють кореляційну обробку, важливе місце в якій займає обчислення функцій взаємної кореляції. Взаємна кореляційна функція двох часових послідовностей X і Y, кожна з яких містить N відліків записується у вигляді
Згідно цього виразу взаємна кореляційна функція двох сигналів обчислюється з відносною затримкою r одного сигналу по відношенню до другого. Кореляційна функція записується у вигляді
Обчислення кореляційної і взаємнокореляційної функції двох сигналів складається з трьох основних операцій: часової затримки, множення і підсумовування.
Сортування
Серед всієї сукупності алгоритмів, що реалізують логічну обробку сигналів в системах ЦОС, найчастіше використовуються алгоритми сортування. Задача сортування формулюється наступним чином: для заданої послідовності {x(i)} необхідно отримати нову послідовність {m(i)}, яка складається із елементів {x(i)}, переставлених в необхідному порядку. В основі реалізації алгоритмів сортування лежать дві операції: порівняння і пересилання даних. Для організації сортування в програмованих процесорах є в наявності достатньо велике число алгоритмів, кожний з яких має свої переваги і недоліки. Виконання сортування програмним шляхом є часомістким. З розвитком технології НВІС в системах ЦОС для реалізації сортування все більше використовуються спеціалізовані апаратні засоби, які дозволяють суттєво зменшити час виконання даної операції.
Операційний базис КСЦОС
Аналіз задач, методів і алгоритмів ЦОС і зображень дозволив виділити наступні характерні особливості: · великий об’єм обчислень з перевагою обчислювальних операцій над логічними; · регулярність і рекурсивність алгоритмів; · структура даних дозволяє застосувати векторну обробку з використанням обох видів паралелізму (просторового і часового); · велику інтенсивність і постійність потоків даних; · широкий динамічний і частотний діапазон сигналів, що обробляються; · багатоканальне введення та виведення даних з виконанням функцій переставляння і затримки даних на необхідну кількість тактів; · можливості розпаралелювання як в часі, так і в просторі; · розв’язання поряд з прямою, оберненої задачі; · постійне ускладнення нових алгоритмів і підвищення вимог до точності результатів. Для визначення операційного базису комп’ютерних систем обробки сигналів і зображень необхідно виділити базові операції алгоритмів ЦОС і зображень [9]. Операції затримки, додавання, віднімання, множення та обчислення сум парних добутків є БО для алгоритмів цифрової фільтрації, обчислення кореляційної і взаємнокореляційної функцій. Складнішими є БО швидких алгоритмів ортогональних тригонометричних перетворень дійсної та комплексної послідовності, які зводяться до табличного обчислення коефіцієнтів
Рис.8.1 Операційний базис комп’ютерних систем обробки сигналів Окрім перерахованих БО, при розв’язанні задач ЦОС і зображень великий об’єм обчислень займають операції обчислення тригонометричних функцій, добування квадратного кореня, піднесення до степені, ділення, сортування, переставляння елементів вхідних, вихідних масивів даних і генерації необхідних послідовностей адрес при звертанні до пам’яті. Окрім перерахованих БО, при розв’язанні задач ЦОС і зображень великий об’єм обчислень займають операції обчислення тригонометричних функцій, добування квадратного кореня, піднесення до степені, ділення, сортування, переставляння елементів вхідних, вихідних масивів даних і генерації необхідних послідовностей адрес при звертанні до пам’яті. На рис.8.1 наведений операційний базис комп’ютерних систем обробки сигналів і зображень, де MAC – множення з підсумовуванням; ШОТП – швидкі ортогональні тригонометричні перетворення; ШКПФ–ШСПФ - швидке косинус-синус перетворення Фур’є; УШТП – універсальні швидкі тригонометричні перетворення, які забезпечують реалізацію Фур’є, Хартлі, косинусного та синусного перетворень дійсної послідовності. Необхідно зауважити, що операційні можливості сучасних мікропроцесорів, на базі яких реалізуються комп’ютерні системи обробки сигналів і зображень, обмежені в частині команд обробки. Більшість сучасних мікропроцесорів апаратно реалізують тільки операції множення. Складніші операції реалізуються програмним способом, який є відносно повільним і вимагає значної кількості пересилань між операційними пристроями та пам’яттю. Для досягнення високої швидкодії в комп’ютерних систем обробки сигналів і зображень пропонується виділені БО і малоточкові ШОТП реалізувати апаратно.
Мікропроцесори ЦОС
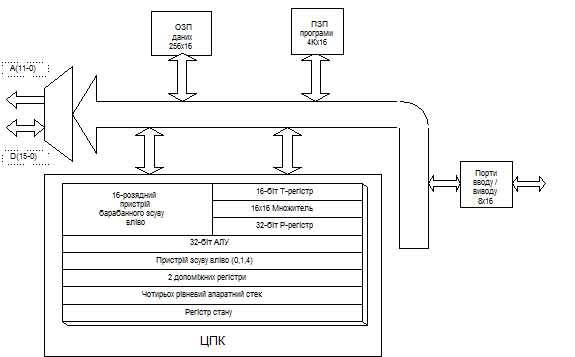
Мікропроцесори ЦОС (МЦОС) мають високу ступінь спеціалізації. В них широко використовуються методи скорочення тривалості командного циклу, характерні і для універсальних RISC-процесорів, такі як конвеєризація на рівні окремих мікроінструкцій та інструкцій, розміщення операндів більшості команд у регістрах, використання тіньових регістрів для зберігання стану обчислень при переключенні контексту, поділ шин команд і даних (гарвардська архітектура). У той же час для МЦОС характерною є наявність апаратного перемножувача, що дозволяє виконувати множення двох чисел за один командний такт. В універсальних мікропроцесорах множення звичайно реалізується за декілька тактів, як послідовність операцій зсуву і додавання. Іншою особливістю МЦОС є включення в систему команд таких операцій, як множення з підсумовуванням MAC ( За обробкою даних МЦОС діляться на два класи: з фіксованою та з плаваючою крапкою. Використання МЦОС з плаваючою крапкою обумовлено декількома причинами. Для багатьох задач, пов'язаних із виконанням інтегральних і диференціальних перетворень, особливе значення має точність обчислень, забезпечити яку дозволяє експоненційний формат представлення даних. Алгоритми компресії, декомпресії, адаптивної фільтрації в ЦОС пов'язані з визначенням логарифмічних залежностей і дуже чутливі до точності представлення даних у широкому динамічному діапазоні. Робота з даними у форматі з плаваючою крапкою істотно спрощує і прискорює обробку, підвищує надійність програми, оскільки не потребує виконання операцій округлення і нормалізації даних, відслідковування ситуацій втрати значимості і переповнення. Платою за ці додаткові "комфорт і швидкість" є висока складність функціональних пристроїв, що виконують обробку даних у форматі з плаваючою крапкою, необхідність використання більш складних технологій виробництва мікросхем, більший відсоток відбракування виробів і як наслідок висока ціна мікропроцесорів. Найпоширеніші МЦОС виготовляють такі фірми як Motorola (56002,96002), Intel (i960), Texas Instruments (TMS320Cxx), Analog Devices (21xx, 210xx) [2,6,7]. Порівняльний аналіз основних характеристик МЦОС одного покоління різних фірм показав відсутність суттєвих відмінностей, що пояснюється близькістю архітектури та технології виготовлення. За повнотою сімейства, за наявністю інструментальних технологічних засобів і розробленого програмного забезпечення МЦОС із сімейства TMS320 переважають МЦОС інших фірм. Принципи проектування та особливості архітектури МЦОС із сімейства TMS320 є характерними і для всіх інших МЦОС. Тому архітектуру мікропроцесорів TMS320, можна розглядати як базову. В основу проектування мікропроцесорів TMS320 покладені наступні принципи: застосування модифікованої гарвардської архітектури, широке використання конвеєрного режиму роботи, наявність спеціалізованого пристрою множення, існування спеціальних команд ЦОС, короткий командний цикл. Для мікропроцесорів серії TMS320 характерне використання апаратної реалізації ряду функцій, які звичайно виконуються програмно. Наприклад, апаратний перемножувач, який забезпечує множення двох чисел за один командний цикл. Є також апаратні паралельні зсувачі, які здійснюють зсув даних і результатів обчислень, індексні регістри, які забезпечують непряму адресацію даних в ОЗП та режим автоінкременту (декременту) при одноциклових маніпуляціях з таблицями даних. Системи команд сімейства мікропроцесорів TMS320 є комплексними та сумісними знизу до верху. Вони містять інструкції різного функціонального призначення: універсальні - арифметичні, логічні і керуючі команди; спеціальні - призначені для розв’язання задач ЦОС. Наявність комплексної системи команд розширює області застосування МЦОС і спрощує розробку програм. МЦОС з фіксованою крапкою. МЦОС TMS320C1x, C2x, C5x призначені для обробки чисел у форматі з фіксованою крапкою. Перше покоління мікропроцесорів TMS320С1х побудоване на базовій архітектурі мікропроцесора TMS320С10 [2,3,9], структура якого наведена на рис.9.1.
Рис.9.1 Структура мікропроцесора TMS320С10
Його адресний простір складає 4К´16-розрядних слів пам'яті програм і 144´16-розрядних слів пам'яті даних. Тривалість командного такту процесора складає 160-200 нс. Арифметичні функції в процесорі реалізовані апаратно. З зовнішніми пристроями процесор взаємодіє через 8-м 16-розрядних портів вводу/виводу. Передбачено можливість обробки зовнішнього переривання. Інші мікропроцесори даного сімейства (С14 – С17) мають аналогічну архітектуру і відрізняються тривалістю командного такту, конфігурацією пам'яті, наявністю (або відсутністю) додаткових периферійних пристроїв. Мікропроцесори сімейства TMS320C2x мають підвищену продуктивність і ширші функціональні можливості. Всі мікропроцесори сімейства можуть використовувати пам'яті програм і даних ємністю 64К слів, послідовний порт та шістнадцять паралельних портів введення/виведення. Мікропроцесори сімейства TMS320C2x мають можливість використання зовнішнього контролера прямого доступу до пам'яті (ПДП). Пристрої множення мікропроцесорів, крім операцій множення, дозволяє виконувати за один такт піднесення до квадрату. У мікропроцесори включена апаратна підтримка кратного виконання команди, реалізований режим двійкової інверсно-непрямої адресації, призначений для ефективної реалізації швидкого перетворення Фур'є. Мікропроцесори сімейства TMS320C5x, забезпечуючи сумісність за системою команд і наслідуючи загальні архітектурні особливості побудови мікропроцесорів попереднього покоління, відрізняються більшими функціональними можливостями, підвищеною тактовою частотою, меншим енергоспоживанням. У МЦОС реалізована апаратна підтримка кільцевих буферів, є можливість одночасного створення в пам'яті даних двох незалежних кільцевих буферів. Існує можливість кратного виконання блока програми. Мікропроцесор містить одинадцять тіньових регістрів, що використовуються для швидкого зберігання/відновлення стану основних регістрів у випадку виникнення програмних або апаратних переривань. Паралельний логічний пристрій мікропроцесора дозволяє виконувати бітові і логічні операції над операндами, що утримуються в пам'яті і різних регістрах. Мікропроцесор TMS320C5x може використовувати 244К слів пам'яті, у тому числі: 64К – пам'ять програм, 64К – пам'ять даних, 64К – 16-розрядні порти вводу/виводу, 32К – глобальна пам'ять. Для можливості роботи з повільною пам'яттю в мікропроцесор включений програмований генератор тактів чекання. При створенні мультипроцесорних систем виникає необхідність спільного використання єдиної області пам'яті. Для цього в процесорі передбачені сигнали запиту і готовності при звертанні до глобальної пам'яті, доступ до якої регулює спеціальний арбітр пам'яті. Різниці між мікропроцесорами – представниками сімейства TMS320C5x полягають, в основному, у конфігурації внутрішньокристальної пам'яті. Крім 16-розрядних портів вводу/виводу, мікропроцесори сімейства мають 2 послідовних порти (у TMS320C52 – один), таймер, інтерфейс тестування і налагодження JTAG. МЦОС з плаваючою крапкою. Першим представником класу мікропроцесорів із плаваючою крапкою є TMS320C30, він має гнучку систему команд, апаратну підтримку операцій із плаваючою крапкою, потужну систему адресації, розширений адресний простір і підтримку мови високого рівня – Сі [3]. Мікропроцесор виготовляється за 0,7 мікронною КМОН технологією з 3-ма рівнями металізації. Всі операції в мікропроцесорі виконуються за один такт. При тривалості такту 60 нс процесор TMS320C30 має швидкодію біля 33 млн. операцій із плаваючою крапкою в секунду. Висока продуктивність мікропроцесора на алгоритмах ЦОС забезпечується завдяки апаратному виконанню ряду специфічних функцій, що в інших мікропроцесорах реалізуються програмно або мікропрограмно. Мікропроцесор має конвеєрну регістро-орієнтовану архітектуру і може паралельно виконувати в одному такті множення і арифметико-логічні операції з числами у форматі з фіксованою або плаваючою крапкою. Структура мікропроцесора TMS320C30 наведена на рис.9.2.
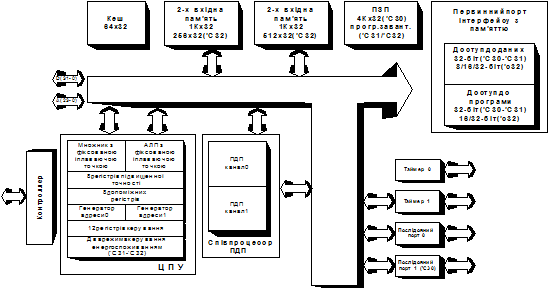
Рис.9.2 Структура мікропроцесора TMS320C30
В склад мікропроцесора TMS320C30 входить: 32-розрядна шина команд і даних; 24-розрядна шина адреси; 2-а блоки ОЗП; 32-розрядний перемножувач із плаваючою крапкою; кеш-пам’ять команд ємністю 64-и слова; 8-м регістрів для операцій із підвищеною точністю; два генератори адреси; регістровий файл; 40-розрядний АЛП, який працює як із цілими числами, так і з числами у форматі з плаваючою крапкою. Вмонтований контролер ПДП дозволяє поєднувати в часі виконання обмінів даними з пам'яттю і обчислення. Наявність у TMS320C30 мультипроцесорного інтерфейсу, двох зовнішніх інтерфейсних портів, двох послідовних портів, розширеної системи переривань спрощує конструювання систем на його основі. Завдяки своїй високій продуктивності і простоті використання в обчислювальних системах TMS320C30 може застосовуватися як у якості головного процесора, так і в якості спеціалізованого співпроцесора. Наступними представниками МЦОС із плаваючою точкою є мікропроцесори сімейства TMS320C4x. Завдяки своїй унікальній архітектурі мікропроцесори TMS320C40 одержали широке поширення в мультипроцесорних системах і практично витіснули раніше пануюче в цій технологічній ніші сімейство трансп’ютерів. Процесори TMS320C4x сумісні по системі команд із TMS320C3x, проте мають більшу продуктивність і кращі комунікаційні можливості. У сімейство TMS320C4x входять процесори TMS320C40, TMS320C44, TMS320LC40. TMS320C40 має продуктивність 30MIPS/60MFLOPS і максимальну пропускну спроможність підсистеми вводу/виводу 384 Мбайт/с. TMS320C40 містить на кристалі шість високошвидкісних (20 Мбайт/с) комунікаційних портів і шість каналів ПДП, 2K слів пам'яті, 128-м слів програмного кеша. Дві зовнішні шини забезпечують доступ до 4Г слів. Висока продуктивність і хороші комунікаційні властивості процесора дозволяють ефективно використовувати його для розв’яння задач обробки зображень, моделювання віртуальної реальності, розпізнавання мови, моніторингу. Мультипроцесорні МЦОС. Подальшим розвитком сімейства МЦОС Texas Instruments є мікропроцесори принципово нової архітектури – TMS320C8х [9]. Мікропроцесори орієнтовані на ужитки, пов'язані з високопродуктивною цифровою обробкою сигналу в самих широких областях науки і техніки. Друга назва процесорів – MVP (Multimedia Video Processor) – характеризує їх високу ефективність на задачах обробки зображень, 2- і 3-вимірній графіці, у системах віртуальної реальності, компресії і декомпресії відео- і аудіоданих і ін.
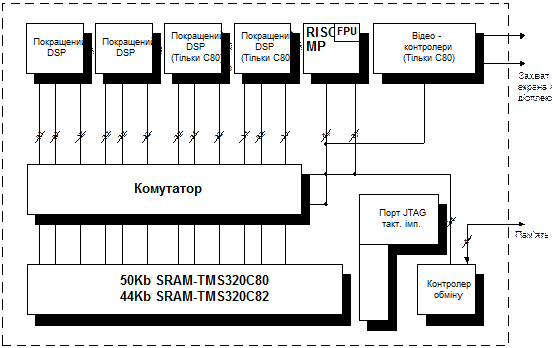
Рис.9.3 Структура мікропроцесора TMS320C80
Базовим МЦОС сімейства TMS320C8х є TMS320C80 (рис. 9.3), який об'єднує в одній мікросхемі п'ять повнофункціональних процесорів, чотири з яких – покращені процесори ЦОС (Advanced Digital Signal Processor). Кожний із ADSP дозволяє виконати за один командний такт декілька RISC-подібних операцій. П'ятий процесор, головний (Master Processor (MP)), являє собою 32-розрядний RISC-процесор із високопродуктивним обчислювачем із плаваючою крапкою, сумісним із стандартом IEEE 754. Крім процесорного ядра на кристалі розміщені: контролер обміну (Transfer Controller (TC)) – інтелектуальний контролер ПДП, що підтримує інтерфейс із DRAM і SRAM, відеоконтролер (Video Controller (VC)), система контролю і налагодження – порт JTAG (IEЕE 1149.1), 50Кб SRAM. Випускається також спрощений варіант мікропроцесора TMS320C82, що відрізняється меншим обсягом пам'яті, кількістю сигнальних процесорів ADSP (2), відсутністю відеоконтролера і відповідно меншою вартістю. Сумарна продуктивність TMS320C80 на регістрових операціях досягає 2 млрд. RISC-подібних команд в секунду. Завдяки високій продуктивності TMS320C80 може замінити при реалізації ряду ужитків більш 10 високопродуктивних МЦОС або мікропроцесорів загального призначення. Пропускна здатність шини TMS320C80 досягає 2,4 Гбайт/с – у потоці даних і 1,8 Гбайт/с – у потоці інструкцій. TMS320C80 забезпечує високу ступінь гнучкості й адаптивності системи, побудованої на його базі, що досягається за рахунок наявності на кристалі паралельно функціонуючих процесорів ЦОС і головного RISC-процесора. Архітектура процесора TMS320C80 відноситься до класу MIMD-множинний потік даних, множинний потік команд. Процесори, що входять до складу TMS320C80 програмуються незалежно один від іншого і можуть виконувати як різні, так і одну загальну задачу. Обмін даними між процесорами здійснюється через спільну внутрішньокристальну пам'ять. Доступ до розподіленої внутрішньокристальної пам'яті забезпечує матричний комутатор (Crossbar), що виконує також функції монітора при звертанні декількох процесорів до одного сегмента пам'яті.
Спеціалізовані НВІС
За способом проектування і виготовленням, тобто налаштуванням на виконання конкретного алгоритму, спеціалізовані НВІС поділяються на два класи: замовні і напівзамовні (рис.9.6).
Рис.9.6 Класифікація спеціалізованих НВІС
Замовні НВІС - це мікросхеми, розроблені на основі стандартних або спеціально створених елементів і вузлів за схемою замовника. Всі топологічні шари замовних НВІС проектуються і виготовляються індивідуально. Існують повністю замовні (ПЗ) НВІС, схеми яких оптимізовані на рівні окремих компонентів, та НВІС побудовані на основі стандартних елементів (СЕ), які вибираються із раніше спроектованої і перевіреної бібліотеки елементів. В склад бібліотеки можуть входити прості логічні елементи типу І-НЕ, АБО-НЕ, тригери, а також складніші типу суматори, регістри, комутатори та інші. Особливістю замовних НВІС є оптимізація елементів і зв'язків на реалізацію алгоритмів, що дозволяє досягнути граничних значень параметрів для кожного рівня технології. Напівзамовні НВІС - це мікросхеми, що складаються з двох частин: наперед спроектованої постійної та змінної - замовної, структура якої визначається замовником. До напівзамовних НВІС відносяться мікросхеми на основі базових кристалів (БК) та програмовані користувачем логічні інтегральні схеми (ПЛІС). Проектування пристроїв на БК здійснюється за рахунок нанесення відповідних шарів з'єднань. Основними елементами БК є базові комірки, що складаються з набору некомутованих елементів-транзисторів і резисторів. На базі таких елементів реалізуються функціонально завершені вузли, які виконують елементарні функції. В порівнянні з БК, технологія ПЛІС забезпечує рекордно малий проектно-технологічний цикл (від декількох годин до декількох днів), мінімальні витрати на проектування, максимальну гнучкість при необхідності модифікації апаратури. На даний час на світовому ринку можна виділити декілька компаній-виробників – ПЛІС-XILINX, ALTERA, LATTICE, AT&T, INTEL, які виготовляють мікросхеми з архітектурою EPLD (EPROM technology bazed complex Programmable Logic Device) – з можливістю багаторазового перепрограмування, і FPGA (Field Programmable Gate Array) – з можливістю багаторазового реконфігурування. В якості пам’яті для зберігання конфігурації в ПЛІС EPLD використовується ППЗП з ультрафіолетовим стиранням, а у ПЛІС FРGA – статичний ОЗП. Мікросхема FPGA являє собою матрицю логічних комірок, що з’єднані між собою логічними ключами. Статична пам’ять, яка є в мікросхемах FPGA при заповненні деякою бітовою послідовністю діє на логічні комірки і з’єднує їх через ключі, що дозволяє отримати необхідні електричні схеми (регістри, лічильники, логічні схеми і ін., що з’єднані в необхідній послідовності). Кожна мікросхема FPGA має вхід для запису бітової послідовності, яка заповнює статичну пам’ять, а також елементи “вхід/вихід” для зв’язку з іншими мікросхемами. Таким чином, на основі однієї чи декількох мікросхем FPGA можна створювати реконфігурований процесор з перевагами спеціалізованого процесора на “жорсткій” логіці, але з можливістю шляхом зміни вмісту статичної пам’яті. Відмінною особливістю ПЛІС архітектури FPGA різновидів XILINX XC3000, XC3100, XC4000 є наявність поля логічних блоків і блоків введення/виведення, які зв’язані між собою через комутаційні блоки. Логічні блоки, блоки введення/виведення і комутаційні поля конфігуруються при завантаженні в ПЛІС бітової послідовності, що отримана в результаті розробки схеми. В залежності від різновиду ПЛІС логічні блоки, блоки введення/виведення, комутаційні блоки мають різну ступінь складності і володіють різними функціональними можливостями. Логічний блок – один з базових елементів архітектури ПЛІС FPGA, може виконувати будь-яку логічну функцію в залежності від заданої бітової послідовності. Шляхом завантаження іншої бітової послідовності можна змінювати виконувану функцію необмежену кількість разів. Блок введення/виведення, так само як і логічний блок, може бути налаштований на виконання будь-якого електричного з’єднання реалізованої в середині ПЛІС схеми з зовнішніми пристроями через відповідний контакт мікросхеми.
Багатомодульна пам’ять Одномодульна структура пам’яті з однією шиною адреси і даних характерна для процесорів з архітектурою фон Неймана. Особливістю даної структури є можливість забезпечення тільки одного звертання до пам’яті протягом одного циклу команди. Збільшити кількість звертань до пам’яті на протязі одного циклу виконання команди дозволяє багатомодульна структура пам’яті з двома або більше шинами адреси і даних. Така організація пам’яті характерна для більшості ПЦОС [2,3,6,7]. Основною перевагою даної архітектури є можливість виконання двох звертань до пам’яті протягом одного циклу виконання команди. Крім цього, таке розділення пам’яті дозволяє сумістити в часі виклик команд і їх виконання. Подальшим розвитком даної архітектури є модифікована гарвардська архітектура, яка дозволяє обмін інформацією між пам’яттю даних і пам’яттю команд. Ця модифікація забезпечує можливість зчитування в пам’ять даних коефіцієнтів і констант, записаних в пам’яті програм і тим самим виключає використання спеціальних постійних запам’ятовуючих пристроїв. Вона також забезпечує можливість використання команд з безпосередньою адресацією та звертання до підпрограм за результатами обчислень. З метою скорочення довжини командного циклу ПЦОС гарвардська архітектура доповнюється конвеєрним режимом роботи. В залежності від типу ПЦОС конвеєр може мати від двох до чотирьох сходинок. Це означає, що процесор може одночасно опрацьовувати від двох до чотирьох команд, при чому кожна з команд буде знаходитись на різних етапах виконання. Прикладом двохмодульної організації пам’яті є гарвардська архітектура (рис. 10.1), де пам’ять розділена на два незалежні блоки (пам’ять програм і пам’ять даних), які під’єднані до процесора за допомогою двох пар шин.
Рис. 10.1 Структура пам'яті процесора з гарвардською архітектурою
Модифікована гарвардська архітектура з двома модулями пам’яті використовується в ПЦОС фірми Texas Instruments (TMS320C1x), Analog Devices (ADSP-21xx) i AT&T (DSP16xx). Подальшого збільшення кількості звертань до пам’яті можна досягнути шляхом використання тримодульної модифікованої гарвардської архітектури. В ПЦОС з такою архітектурою пам’ять розділена на три незалежні модулі пам’яті, причому кожен з модулів має свою власну множину шин. Один з модулів пам’яті можна використовувати для зберігання команд і даних, а два інші лише для зберігання даних. Архітектура з тримодульною пам’яттю дозволяє процесору виконувати три незалежні звертання до пам’яті за один цикл команди. Одне звертання до модуля пам’яті для отримання команди, а два інші модулі - для отримання даних. Для забезпечення високої швидкодії потоки даних і команд в такій архітектурі розділені. Модифікована гарвардська архітектура з трьохмодульною пам’яттю використовується у швидкодіючих ПЦОС фірм Zilog (Z893xx), Motorola (DSP560xx, 563xx i 96008), Texas Instruments (TMS320C2x-TMS320C5x). Велику роль в забезпеченні високої швидкодії перерахованих вище структур ПЦОС відіграє кількість внутрішніх шин і їх зв’язок з модулями пам’яті, розміщеними на кристалі і поза ним. Розподіл внутрішніх шин в ПЦОС дозволяє здійснювати паралельні виклики програм, доступ до даних і прямий доступ до пам’яті. Розглянемо організацію внутрішньокристальної пам’яті і зв’язок з шинами на прикладі ПЦОС TMS320C40 (рис. 10.2).
Рис. 10.2 Організація пам'яті процесора TMS320C40
Даний процесор має сім шин, одна з яких є шиною команд (PDATA), дві - шинами даних (DDATA, DMADATA) і чотири - шинами адрес (PADDR, DADDR1,DADDR2 i DMAADDR). Шина адреси пам’яті програм PADDR пов’язана з лічильником адреси програм, а шина команд PDATA - з регістром команд. Ці шини дозволяють вибирати одне слово команди в кожному циклі. Шини адреси - DADDR1 і DADDR2 та шина даних DDATA можуть забезпечувати два доступи до пам’яті в кожному циклі роботи. Прямий доступ до пам’яті підтримується адресною шиною DMAADDR і шиною даних DMADATA. Ці шини дозволяють здійснювати прямий доступ до пам’яті одночасно з доступом, що може здійснюватись з шин програм і даних. Особливістю ПЦОС з двома і трьома модулями пам’яті на кристалі є відносно мала ємність їхньої пам’яті. Розширення ємності пам’яті однокристальних ПЦОС досягається шляхом під’єднання зовнішньої пам’яті. Оскільки розміщення декількох множин шин поза кристалом вимагає великої кількості виводів і додаткових апаратних витрат, то більшість однокристальних ПЦОС використовують одну множину шин (адреси, даних і управління) поза кристалом. Зовнішня пам’ять, під’єднана до однієї множини, дозволяє лише одне звертання протягом одного командного циклу. Тому команди, які вимагають декількох звертань до зовнішньої пам’яті, виконують за декілька циклів, що значно зменшує швидкодію процесора. Серед інших шляхів збільшення кількості звертань до пам’яті, є використання швидкодіючої пам’яті, яка підтримує декілька послідовних звертань за один командний цикл. Використання швидкої пам’яті в ПЦОС з гарвардською архітектурою дозволяє отримати більшу швидкодію ніж при використанні її окремо. Прикладом такого використання є процесор ZR3800x фірми Zoran, який поряд з модулем пам’яті з одиночним доступом використовує модуль швидкодіючої пам’яті з подвійним доступом. В даному процесорі за один командний цикл може виконуватися одне звертання до пам’яті програм і два звертання до пам’яті даних. В ПЦОС з гарвардською архітектурою збільшення кількості звертань до пам’яті за один командний цикл можливе при використанні в якості пам’яті програм і даних двох модулів швидкодіючої пам’яті. Така пам’ять дозволяє виконання чотирьох звертань за один командний цикл при умові, що звертання впорядковані таким чином, що кожен модуль обслуговує два звертання. Широке використання швидкодіючої пам’яті на кристалі стримується значним зростанням потужності споживання та його вартості. При переміщенні швидкої пам’яті або її частини за межі кристалу, необхідно вирішити питання мінімізації затримок та усунення завад, що виникатимуть при такому обміні.
Алгоритмічні процесори ЦОС Структури алгоритмічних процесорів (АП) ЦОС мають повною мірою використовувати мо
|
||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 487; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.139.107.241 (0.005 с.) |



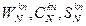 та виконання послідовності операцій множення, додавання, віднімання дійсних і комплексних. Для ефективної реалізації швидких алгоритмів ортогональних тригонометричних перетворень дійсної та комплексної послідовності в склад комп’ютерних систем обробки сигналів і зображень доцільно включити багатооперандні операційні пристрої для обчислення БО та малоточкові процесори швидких дискретних тригонометричних перетворень.
та виконання послідовності операцій множення, додавання, віднімання дійсних і комплексних. Для ефективної реалізації швидких алгоритмів ортогональних тригонометричних перетворень дійсної та комплексної послідовності в склад комп’ютерних систем обробки сигналів і зображень доцільно включити багатооперандні операційні пристрої для обчислення БО та малоточкові процесори швидких дискретних тригонометричних перетворень.
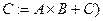 з зазначеним у команді числом виконань у циклі та з правилом зміни індексів використовуваних елементів масивів А і В), інверсія біту адреси, різноманітні бітові операції. У МЦОС реалізується апаратна підтримка програмних циклів, кільцевих буферів і вибір з пам'яті за цикл виконання команди декількох операндів.
з зазначеним у команді числом виконань у циклі та з правилом зміни індексів використовуваних елементів масивів А і В), інверсія біту адреси, різноманітні бітові операції. У МЦОС реалізується апаратна підтримка програмних циклів, кільцевих буферів і вибір з пам'яті за цикл виконання команди декількох операндів.