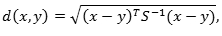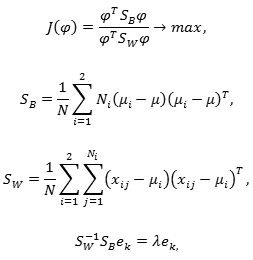Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Взвешенное расстояние Кульбака-Лейблера
В качестве меры различия двух гистограмм использовалось взвешенное расстояние Кульбака-Лейблера в симметричной форме:
При этом задача идентификации решалась с использованием классификатора по методу ближайшего соседа, а задача верификации – путем пороговой классификации. Расстояние Махаланобиса
Корреляционная матрица S может быть получена с использованием обучающей выборки изображений. Определяя расстояние Кульбака-Лейблера (4.1) для каждой из подобластей изображений, мы можем получить вектор различий двух изображений. Вычисляя такие вектора для каждой пары изображений обучающей выборки, мы получим два набора векторов различий изображений, соответствующих двум классам – классу «своих» и классу «чужих». После этого мы можем вычислить средние значения векторов, представляющих каждый из классов, а также две корреляционные матрицы. На практике, для любых двух изображений мы можем вычислить их вектор различий, а затем определить расстояния Махаланобиса d 1 и d 2 между этим вектором и средними векторами классов «свой» и «чужой» соответственно. Идентификация и верификация могут быть произведены путем сравнения двух полученных расстояний либо с использованием дискриминирующей функции f (d 1, d 2) = d 2⁄(d 1+ d 2) и некоторого порогового значения.
4.3. Применение линейного дискриминанта Фишера
Пусть имеется два набора векторов, соответствующих двум классам. Собственный вектор, соответствующий наибольшему собственному значению матрицы Sw -1 Sb задает преобразование в пространство размерности 1. Задача идентификации и верификации может быть решена способом, аналогичным предыдущему (путем построения векторов различий изображений с использованием расстояния Кульбака-Лейблера). При этом вместо расстояния Махаланобиса используется отображение вектора в одномерное пространство.
Предобработка изображений
Метод Виолы-Джонса Метод был разработан и представлен в 2001 году Полом Виолой и Майклом Джонсом, он до сих пор является основополагающим для поиска объектов на изображении в реальном времени. Метод использует технологию скользящего окна. То есть рамка, размером, меньшим, чем исходное изображение, двигается с некоторым шагом по изображению, и с помощью каскада слабых классификаторов определяет, есть ли в рассматриваемом окне лицо. Метод скользящего окно эффективно используется в различных задачах компьютерного зрения и распознавания объектов. Метод состоит из 2-х под алгоритмов: алгоритм обучения и алгоритм распознавания. На практике скорость работы алгоритма обучения не важна. Крайне важна скорость работы алгоритма распознавания. По введенной ранее классификации можно отнести к структурным, статистическим и нейронным методам. Метод имеет следующие преимущества:
Основные принципы, на которых основан метод, таковы:
Принцип сканирующего окна
|
||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 645; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.19.27.178 (0.005 с.) |